【DataSphereStudio - 1.1.0 安装介绍】
【DataSphereStudio - 1.1.0 安装介绍】
DataSphere Studio & Linkis
- 【DataSphereStudio - 1.1.0 安装介绍】
- 1. DataSphere Studio 介绍
- 2. DataSphere Studio 安装
-
- 2.1 基础软件安装
-
- 2.1.1 注意事项
- 2.1.2 软件版本
- 2.1.3 需要的命令工具
- 2.1.4 创建用户配置权限及免密
- 2.1.5 Hadoop 2.7.2 安装
- 2.1.6 Hive 2.3.3 安装
- 2.1.7 Spark 2.4.0 安装
- 2.1.8 DataSphere Studio & Linkis 一键部署
-
- 2.1.8.1 安装前提
- 2.1.8.2 安装步骤
- 3. 补充
- 4. 参考
1. DataSphere Studio 介绍

DataSphere Studio(简称 DSS)是微众银行自研的数据应用开发管理集成框架。
基于插拔式的集成框架设计,及计算中间件 Linkis ,可轻松接入上层各种数据应用系统,让数据开发变得简洁又易用。
在统一的 UI 下,DataSphere Studio 以工作流式的图形化拖拽开发体验,将满足从数据交换、脱敏清洗、分析挖掘、质量检测、可视化展现、定时调度到数据输出应用等,数据应用开发全流程场景需求。
DSS 通过插拔式的集成框架设计,让用户可以根据需要,简单快速替换 DSS 已集成的各种功能组件,或新增功能组件。
借助于 Linkis 计算中间件的连接、复用与简化能力,DSS 天生便具备了金融级高并发、高可用、多租户隔离和资源管控等执行与调度能力。
界面预览
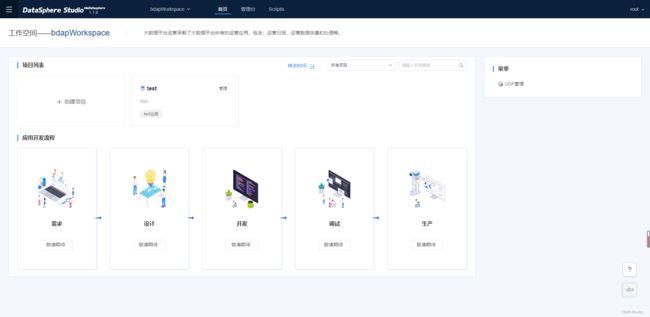
2. DataSphere Studio 安装
2.1 基础软件安装
2.1.1 注意事项
检查服务器存在多网卡问题
首先通过命令ifconfig命令查看服务器激活状态的网卡,若激活状态的网卡数大于1,那么用户就需要通过命令 ifconfig [NIC_NAME] down([NIC_NAME] 为网卡名称)来关闭多余的网卡,以确保激活的网卡数只有1个
网卡多IP问题
在确保服务器只存在一个网卡是激活状态的情况下,通过命令 echo $(hostname -I) 查看网卡对应的IP数,若大于1,那么就需要去掉网卡中指定的IP,采用动态获取IP的方式,具体命令如下:
//刷新
ip addr flush dev [网卡名称]
//关闭网卡
ifdown [网卡名称]
//启动网卡
ifup [网卡名称]
hostname配置
在安装前用户需要配置 hostname 到 ip 的映射
配置文件位于 /etc/hosts
2.1.2 软件版本
| Version |
|---|
| CentOS 7 |
| Jdk 8 |
| MySQL 5.7 |
| Hadoop 2.7.2 |
| Hive 2.3.3 |
| Spark 2.4.0 |
| DataSphere Studio 1.1.0 |
| Linkis 1.1.1 |
2.1.3 需要的命令工具
在正式安装前,脚本会自动检测这些命令是否可用,如果不存在会尝试自动安装,安装失败则需用户手动安装以下基础shell命令工具 (建议提前安装好)
~
telnet; tar; sed; dos2unix; mysql; yum; java; unzip; zip; expect
安装所需命令工具( jdk 、 mysql 、 nginx 单独安装)
// An highlighted block
yum install -y telnet tar sed dos2unix unzip expect
2.1.4 创建用户配置权限及免密
创建用户(可以不是hadoop用户,本案例安装使用测试环境root用户进行)
sudo useradd hadoop
Linkis的服务是以 sudo -u ${linux-user} 方式来切换引擎执行作业,所以部署用户需要有 sudo 权限,而且是免密的,按下面步骤修改部署用户权限
编辑/etc/sudoers文件:
vi /etc/sudoers
在/etc/sudoers文件中添加下面内容:
hadoop ALL=(ALL) NOPASSWD: NOPASSWD: ALL
配置免密登录
ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub 用户名@127.0.0.1
ssh localhost
2.1.5 Hadoop 2.7.2 安装
a.下载Hadoop,解压后创建所需目录 添加环境变量
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.2/hadoop-2.7.2.tar.gz
tar xvf hadoop-2.7.2.tar.gz
vim /etc/profile
export HADOOP_HOME=/root/Hadoop/hadoop-2.7.2/
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
b.修改Hadoop配置
vim /root/Hadoop/hadoop-2.7.2/etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
c.修改Hadoop的hdfs目录配置
vim /root/Hadoop/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/root/Hadoop/hadoop-2.7.2/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/Hadoop/hadoop-2.7.2/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
d.修改Hadoop的yarn配置
vim /root/Hadoop/hadoop-2.7.2/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
cp /root/Hadoop/hadoop-2.7.2/etc/hadoop/mapred-site.xml.template /root/Hadoop/hadoop-2.7.2/etc/hadoop/mapred-site.xml
vim /root/Hadoop/hadoop-2.7.2/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
e.修改Hadoop环境配置文件
vim /root/Hadoop/hadoop-2.7.2/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/root/jdk/jdk1.8.0_202/
f.启动hadoop
hdfs namenode -format
start-dfs.sh
start-yarn.sh
# 若重置太多次会导致clusterID不匹配,datanode起不来,删除版本后在初始化启动
rm -rf /root/Hadoop/hadoop-2.7.2/hadoopinfra/hdfs/datanode/current/VERSION
hadoop namenode -format
hdfs namenode -format
start-dfs.sh
start-yarn.sh
默认ui地址
hadoop ip:50070
yarn ip:8088
2.1.6 Hive 2.3.3 安装
a.下载解压Hive
mkdir hive
cd hive
wget https://archive.apache.org/dist/hive/hive-2.3.3/apache-hive-2.3.3-bin.tar.gz
tar xvf apache-hive-2.3.3-bin.tar.gz
b.创建hadoop目录并设置权限、修改hive配置
cd /root/hive/apache-hive-2.3.3-bin/conf/
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
hadoop fs -mkdir -p /data/hive/warehouse
hadoop fs -mkdir /data/hive/tmp
hadoop fs -mkdir /data/hive/log
hadoop fs -chmod -R 777 /data/hive/warehouse
hadoop fs -chmod -R 777 /data/hive/tmp
hadoop fs -chmod -R 777 /data/hive/log
vim hive-site.xml
<!--hive 配置入下:-->
<property>
<name>hive.exec.scratchdir</name>
<value>hdfs://127.0.0.1:9000/data/hive/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://127.0.0.1:9000/data/hive/warehouse</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>hdfs://127.0.0.1:9000/data/hive/log</value>
</property>
<!--该配置是关闭hive元数据版本认证,否则会在启动spark程序时报错-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--配置mysql IP 端口以及放元数据的库名称-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<!--配置mysql启动器名称 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--配置连接mysql用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--配置连接mysql用户名登录密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Cby123..</value>
</property>
c.修改配置文件中 system:java.io.tmpdir 和 system:user.name 相关信息,改为实际目录和用户名,或者加入如下配置
<property>
<name>system:java.io.tmpdir</name>
<value>/tmp/hive/java</value>
</property>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/root/hive/apache-hive-2.3.3-bin/tmp/${system:user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/root/hive/apache-hive-2.3.3-bin/tmp/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/root/hive/apache-hive-2.3.3-bin/tmp/root/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
d.配置hive中jdbc的MySQL驱动
cd /root/hive/apache-hive-2.3.3-bin/lib/
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.49.tar.gz
tar xvf mysql-connector-java-5.1.49.tar.gz
cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49.jar .
vim /root/hive/apache-hive-2.3.3-bin/conf/hive-env.sh
#配置文件内容
export HADOOP_HOME=/root/Hadoop/hadoop-2.7.2/
export HIVE_CONF_DIR=/root/hive/apache-hive-2.3.3-bin/conf
export HIVE_AUX_JARS_PATH=/root/hive/apache-hive-2.3.3-bin/lib
e.配置hive环境变量
vim /etc/profile
#配置文件内容
export HADOOP_HOME=/root/Hadoop/hadoop-2.7.2/
export HIVE_CONF_DIR=/root/hive/apache-hive-2.3.3-bin/conf
export HIVE_AUX_JARS_PATH=/root/hive/apache-hive-2.3.3-bin/lib
export HIVE_PATH=/root/hive/apache-hive-2.3.3-bin/
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HIVE_PATH/bin
#初始化
./schematool -dbType mysql -initSchema
f.初始化完成后修改MySQL链接信息
vim hive-site.xml
#配置文件内容 注意 & 分割
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive?characterEncoding=utf8&useSSL=false</value>
</property>
#后台nohup启动hive (日志在执行命令位置)
nohup hive --service metastore &
nohup hive --service hiveserver2 &
2.1.7 Spark 2.4.0 安装
a.创建spark目录并下载所需文件
mkdir spark
cd spark
wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
tar xvf spark-2.4.0-bin-hadoop2.7.tgz
b.配置spark环境变量以及备份配置文件
vim /etc/profile
#配置文件内容
export SPARK_HOME=/root/spark/spark-2.4.0-bin-hadoop2.7/
export PATH=$PATH:$SPARK_HOME/bin
cd /root/spark/spark-2.4.0-bin-hadoop2.7/conf/
cp spark-env.sh.template spark-env.sh
cp spark-defaults.conf.template spark-defaults.conf
cp metrics.properties.template metrics.properties
c.配置程序的环境变量
cp slaves.template slaves
vim spark-env.sh
#配置文件内容
export JAVA_HOME=/root/jdk/jdk1.8.0_202
export HADOOP_HOME=/root/Hadoop/hadoop-2.7.2
export HADOOP_CONF_DIR=/root/Hadoop/hadoop-2.7.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/root/Hadoop/hadoop-2.7.2/bin/hadoop classpath)
export SPARK_MASTER_HOST=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -
Dspark.history.retainedApplications=50 -
Dspark.history.fs.logDirectory=hdfs://127.0.0.1:9000/spark-eventlog"
d.修改默认的配置文件
vim spark-defaults.conf
#配置文件内容
spark.master spark://127.0.0.1:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://127.0.0.1:9000/spark-eventlog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 3g
spark.eventLog.enabled true
spark.eventLog.dir hdfs://127.0.0.1:9000/spark-eventlog
spark.eventLog.compress true
e.配置工作节点
vim slaves
#配置文件内容
127.0.0.1
f. 验证应用程序
sbin/start-all.sh
默认ui地址
master ip:8080
worker ip:8081
修改master端口地址(master端口未被占用可以忽略)
xx/sbin/start-master.sh

2.1.8 DataSphere Studio & Linkis 一键部署
2.1.8.1 安装前提
安装 dss 前机器必须支持以下命令
Hadoop(2.7.2,Hadoop其他版本需自行编译Linkis) ,安装的机器必须支持执行 hdfs dfs -ls / 命令
Hive(2.3.3,Hive其他版本需自行编译Linkis),安装的机器必须支持执行hive -e "show databases"命令
Spark(支持2.0以上所有版本) ,安装的机器必须支持执行spark-sql -e “show databases” 命令
2.1.8.2 安装步骤
a.下载官方一键部署包
https://osp-1257653870.cos.ap-guangzhou.myqcloud.com/WeDatasphere/DataSphereStudio/dss_linkis_one-click_install_20220704.zip
b.解压zip包,安装 pip 和 matplotlib (安装启动前会进行检查)
// 解压安装包
unzip -d dss dss_linkis_one-click_install_20220704.zip
// 替换yum镜像源、安装pip
sudo yum -y install epel-release
sudo yum install -y python-pip
// 安装matplotlib
python -m pip install matplotlib
c.用户需要对 xx/dss_linkis/conf 目录下的 config.sh 和 db.sh 进行修改
打开 config.sh,按需修改相关配置参数,参数说明如下:
#################### 一键安装部署的基本配置 ####################
### deploy user(部署用户,默认为当前登录用户)
deployUser=hadoop
### Linkis_VERSION
LINKIS_VERSION=1.1.1
### DSS Web(本机安装一般无需修改,但需确认此端口是否占用,若被占用,修改一个可用端口即可)
DSS_NGINX_IP=127.0.0.1
DSS_WEB_PORT=8085
### DSS VERSION
DSS_VERSION=1.1.0
############## linkis的其他默认配置信息 start ##############
### Specifies the user workspace, which is used to store the user's script files and log files.
### Generally local directory
##file:// required. 指定用户使用的目录路径,一般用于存储用户的脚本文件和日志文件等,是用户的工作空间
WORKSPACE_USER_ROOT_PATH=file:///tmp/linkis/
### User's root hdfs path
##hdfs:// required. 结果集日志等文件路径,用于存储Job的结果集文件
HDFS_USER_ROOT_PATH=hdfs:///tmp/linkis
### Path to store job ResultSet:file or hdfs path
##hdfs:// required. 结果集日志等文件路径,用于存储Job的结果集文件,如果未配置 使用HDFS_USER_ROOT_PATH的配置
RESULT_SET_ROOT_PATH=hdfs:///tmp/linkis
### Path to store started engines and engine logs, must be local. 存放执行引擎的工作路径,需要部署用户有写权限的本地目录
ENGINECONN_ROOT_PATH=/appcom/tmp
### 基础组件环境信息
###HADOOP CONF DIR #/appcom/config/hadoop-config(用户根据实际情况修改)
HADOOP_CONF_DIR=/appcom/config/hadoop-config
###HIVE CONF DIR #/appcom/config/hive-config(用户根据实际情况修改)
HIVE_CONF_DIR=/appcom/config/hive-config
###SPARK CONF DIR #/appcom/config/spark-config(用户根据实际情况修改)
SPARK_CONF_DIR=/appcom/config/spark-config
###for install (用户根据实际情况修改)
LINKIS_PUBLIC_MODULE=lib/linkis-commons/public-module
##YARN REST URL spark engine required(根据实际情况修改IP和端口)
YARN_RESTFUL_URL=http://127.0.0.1:8088
## Engine version
#SPARK_VERSION(根据实际版本情况修改版本号)
SPARK_VERSION=2.4.0
##HIVE_VERSION(根据实际版本情况修改版本号)
HIVE_VERSION=2.3.3
##PYTHON_VERSION(根据实际版本情况修改版本号)
PYTHON_VERSION=python2
## LDAP is for enterprise authorization, if you just want to have a try, ignore it.
#LDAP_URL=ldap://localhost:1389/
#LDAP_BASEDN=dc=webank,dc=com
#LDAP_USER_NAME_FORMAT=cn=%s@xxx.com,OU=xxx,DC=xxx,DC=com
############## linkis的其他默认配置信息 end ##############
################### The install Configuration of all Linkis's Micro-Services #####################
################### 用户可以根据实际情况修改IP和端口 ###################
#
# NOTICE:
# 1. If you just wanna try, the following micro-service configuration can be set without any settings.
# These services will be installed by default on this machine.
# 2. In order to get the most complete enterprise-level features, we strongly recommend that you install
# the following microservice parameters
#
### EUREKA install information
### You can access it in your browser at the address below:http://${EUREKA_INSTALL_IP}:${EUREKA_PORT}
### Microservices Service Registration Discovery Center
LINKIS_EUREKA_INSTALL_IP=127.0.0.1
LINKIS_EUREKA_PORT=9600
#LINKIS_EUREKA_PREFER_IP=true
### Gateway install information
#LINKIS_GATEWAY_INSTALL_IP=127.0.0.1
LINKIS_GATEWAY_PORT=9001
### ApplicationManager
#LINKIS_MANAGER_INSTALL_IP=127.0.0.1
LINKIS_MANAGER_PORT=9101
### EngineManager
#LINKIS_ENGINECONNMANAGER_INSTALL_IP=127.0.0.1
LINKIS_ENGINECONNMANAGER_PORT=9102
### EnginePluginServer
#LINKIS_ENGINECONN_PLUGIN_SERVER_INSTALL_IP=127.0.0.1
LINKIS_ENGINECONN_PLUGIN_SERVER_PORT=9103
### LinkisEntrance
#LINKIS_ENTRANCE_INSTALL_IP=127.0.0.1
LINKIS_ENTRANCE_PORT=9104
### publicservice
#LINKIS_PUBLICSERVICE_INSTALL_IP=127.0.0.1
LINKIS_PUBLICSERVICE_PORT=9105
### cs
#LINKIS_CS_INSTALL_IP=127.0.0.1
LINKIS_CS_PORT=9108
########## Linkis微服务配置完毕 ##########
################### The install Configuration of all DataSphereStudio's Micro-Services #####################
#################### 非注释的参数必须配置,注释掉的参数可按需修改 ####################
# NOTICE:
# 1. If you just wanna try, the following micro-service configuration can be set without any settings.
# These services will be installed by default on this machine.
# 2. In order to get the most complete enterprise-level features, we strongly recommend that you install
# the following microservice parameters
#
# 用于存储发布到 Schedulis 的临时ZIP包文件
WDS_SCHEDULER_PATH=file:///appcom/tmp/wds/scheduler
### DSS_SERVER
### This service is used to provide dss-server capability.
### project-server
#DSS_FRAMEWORK_PROJECT_SERVER_INSTALL_IP=127.0.0.1
#DSS_FRAMEWORK_PROJECT_SERVER_PORT=9002
### orchestrator-server
#DSS_FRAMEWORK_ORCHESTRATOR_SERVER_INSTALL_IP=127.0.0.1
#DSS_FRAMEWORK_ORCHESTRATOR_SERVER_PORT=9003
### apiservice-server
#DSS_APISERVICE_SERVER_INSTALL_IP=127.0.0.1
#DSS_APISERVICE_SERVER_PORT=9004
### dss-workflow-server
#DSS_WORKFLOW_SERVER_INSTALL_IP=127.0.0.1
#DSS_WORKFLOW_SERVER_PORT=9005
### dss-flow-execution-server
#DSS_FLOW_EXECUTION_SERVER_INSTALL_IP=127.0.0.1
#DSS_FLOW_EXECUTION_SERVER_PORT=9006
###dss-scriptis-server
#DSS_SCRIPTIS_SERVER_INSTALL_IP=127.0.0.1
#DSS_SCRIPTIS_SERVER_PORT=9008
########## DSS微服务配置完毕#####
############## other default configuration 其他默认配置信息 ##############
## java application default jvm memory(Java应用的堆栈大小。如果部署机器的内存少于8G,推荐128M;
## 达到16G时,推荐至少256M;如果想拥有非常良好的用户使用体验,推荐部署机器的内存至少达到32G)
export SERVER_HEAP_SIZE="128M"
##sendemail配置,只影响DSS工作流中发邮件功能
EMAIL_HOST=smtp.163.com
EMAIL_PORT=25
EMAIL_USERNAME=xxx@163.com
EMAIL_PASSWORD=xxxxx
EMAIL_PROTOCOL=smtp
### Save the file path exported by the orchestrator service
ORCHESTRATOR_FILE_PATH=/appcom/tmp/dss
### Save DSS flow execution service log path
EXECUTION_LOG_PATH=/appcom/tmp/dss
############## other default configuration 其他默认配置信息 ##############
配置db.sh
配置DSS数据库
MYSQL_HOST=127.0.0.1
MYSQL_PORT=3306
MYSQL_DB=dss
MYSQL_USER=xxx
MYSQL_PASSWORD=xxx
Hive metastore的数据库配置,用于Linkis访问Hive的元数据信息
HIVE_HOST=127.0.0.1
HIVE_PORT=3306
HIVE_DB=xxx
HIVE_USER=xxx
HIVE_PASSWORD=xxx
d.切换目录执行安装脚本
cd xx/dss_linkis/bin
sh install.sh
e.等待安装脚本执行完毕,再进到linkis目录里修改对应的配置文件
修改linkis-ps-publicservice.properties配置,否则hive数据库刷新不出来表
linkis.metadata.hive.permission.with-login-user-enabled=false
拷贝缺少的jar(修改为相应组件安装位置)
cp /opt/hive/apache-hive-2.3.3-bin/lib/datanucleus-* ~/dss/linkis/lib/linkis-engineconn-plugins/hive/dist/v2.3.3/lib
cp /opt/hive/apache-hive-2.3.3-bin/lib/*jdo* ~/dss/linkis/lib/linkis-engineconn-plugins/hive/dist/v2.3.3/lib
f.安装完成后启动
sh start-all.sh
g.修改默认密码
#切换到Linkis配置文件目录
cd xx/dss_linkis/linkis/conf/
#打开配置文件linkis-mg-gateway.properties
vi linkis-mg-gateway.properties
#修改密码
wds.linkis.admin.password=hadoop
检查eureka服务
在Eureka界面查看 Linkis & DSS 后台各微服务的启动情况,默认情况下DSS有7个微服务,Linkis有10个微服务(包括启用数据源管理功能后的两个微服务,此安装方式数据源管理默认开启)
eureka服务地址配置在config.sh中的:
~
LINKIS_EUREKA_INSTALL_IP=127.0.0.1
LINKIS_EUREKA_PORT=9600

查看 DataSphereStudio ui
此处配置的地址为 ip:8085
默认账号:config.sh中用户名
默认密码:hadoop
3. 补充
nginx端口占用更改
#查看端口号是否被占用
netstat -tunlp | grep 端口号
#查找配置文件位置
whereis nginx.conf
#修改文件内容

4. 参考
官方安装文档:
https://github.com/WeBankFinTech/DataSphereStudio-Doc/blob/main/zh_CN/%E5%AE%89%E8%A3%85%E9%83%A8%E7%BD%B2/DSS%26Linkis%E4%B8%80%E9%94%AE%E9%83%A8%E7%BD%B2%E6%96%87%E6%A1%A3%E5%8D%95%E6%9C%BA%E7%89%88.md
博客:
https://zhuanlan.zhihu.com/p/555062985