Hive 存储格式详解
存储格式
Hive支持的存储数的格式主要有:TEXTFILE(行式存储) 、SEQUENCEFILE(行式存储)、ORC(列式存储)、PARQUET(列式存储)。
1 行式存储和列式存储
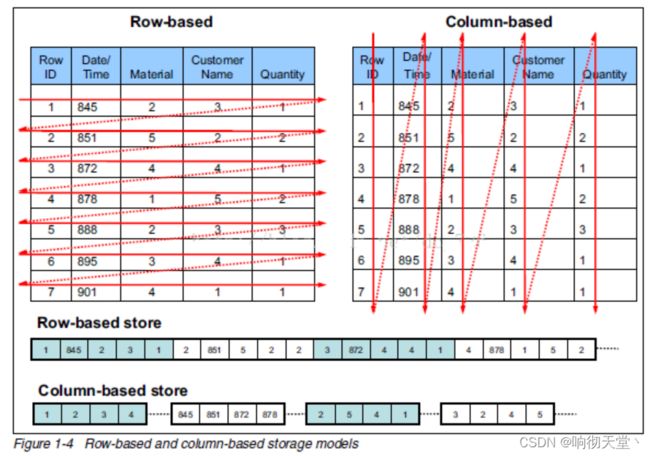
行存储的特点: 查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
相比于行式存储,列式存储在分析场景下有着许多优良的特性:
1)分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO开销,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存储往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的数据空间,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
2 主流文件存储格式对比实验
从存储文件的压缩比和查询速度两个角度对比。存储文件的压缩比测试:
2.1 TextFile
create table log_text (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE ;
load data local inpath '/usr/local/rosh/data/log.data' into table log_text ;
hadoop fs -du -h /hive/warehouse/log_text;

2.2 ORC
create table log_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc ;
insert into table log_orc select * from log_text;
hadoop fs -du -h /hive/warehouse/log_orc;

2.3 Parquet
create table log_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS PARQUET ;
insert into table log_parquet select * from log_text;
hadoop fs -du -h /hive/warehouse/log_parquet;

2.4 结论
存储文件的压缩比总结:ORC > Parquet > textFile
3 压缩
ORC的压缩方式:
| Key | Default | Notes |
|---|---|---|
| orc.compress(OCR默认压缩方式) | ZLIB | high level compression (one of NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk |
| orc.stripe.size | 67,108,864 | number of bytes in each stripe |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
| orc.bloom.filter.columns | “” | comma separated list of column names for which bloom filter should be created |
| orc.bloom.filter.fpp | 0.05 | false positive probability for bloom filter (must >0.0 and <1.0) |
3.1 不使用压缩方式
create table log_orc_none(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="NONE");
insert into table log_orc_none select * from log_text ;
hadoop fs -du -h /hive/warehouse/log_orc_none;

3.2 采用SNAPPY
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");
insert into table log_orc_snappy select * from log_text ;
hadoop fs -du -h /hive/warehouse/log_orc_snappy ;
