flink-sql大量使用案例
1. 介绍
本章节主要说明各类型flink sql的先后编写执行顺序,另外简单写一些实际可用的案例。
推荐大家使用 StreamPark 进行 flink sql 任务的开发和上线,官网地址:https://streampark.apache.org/
2. 编写顺序
- set
- 该语句主要是设置本次提交任务环境的一些参数,因此必须写到所有语句的开头,在其他语句执行之前必须先设置参数,之后的语句执行才能使用到设置好的参数。
- 特殊设置:
sql 方言,默认情况下,flink 使用的是自己的方言,但如果想要迁移之前一些hive sql语句,可能想直接使用flink sql引擎直接执行语句,以减少迁移的成本。
此时就可以将设置sql方言的set语句放到insert语句之前,而不是放到最开头。 倘若是直接将设置sql方言的set语句放到最开头,则下面的建表、创建函数之类的语句可能会出错。
- create
- 如果需要用到 hive ,比如读写 hive 表,或者是将创建的虚拟表的信息放到 hive 元数据,就需要有创建 hive catalog 的语句。
- 创建虚拟表来连接外部系统。
- 其他
- 创建自定义函数。
- 创建数据库。
- 创建视图
- load
- 如果想要用到 hive 模块,比如使用 hive 的一些函数,则需要加载 hive 模块,加载完 hive 模块之后,平台就自动拥有了 hive 和 core(flink) 这两个模块,默认解析顺序为
core->hive。
- 如果想要用到 hive 模块,比如使用 hive 的一些函数,则需要加载 hive 模块,加载完 hive 模块之后,平台就自动拥有了 hive 和 core(flink) 这两个模块,默认解析顺序为
- use
- 创建了 hive 的 catalog 之后,必须写
use catalog语句来使用创建的 hive catalog,否则无法连接 hive 元数据。 - 加载了 hive 模块之后,可以通过
use modules hive, core语句来调整模块解析顺序。
- 创建了 hive 的 catalog 之后,必须写
- insert
insert语句是真正的flink sql任务。
3. 写在前面
以下所有的案例中涉及到的各组件版本如下:
- java:1.8
- scala:2.12.15
- flink:1.15.x
- kafka:1.1.1
- hadoop:2.8.3
- hive:2.3.6
- mysql:5.7.30
- hbase:1.4.9
4. kafka source
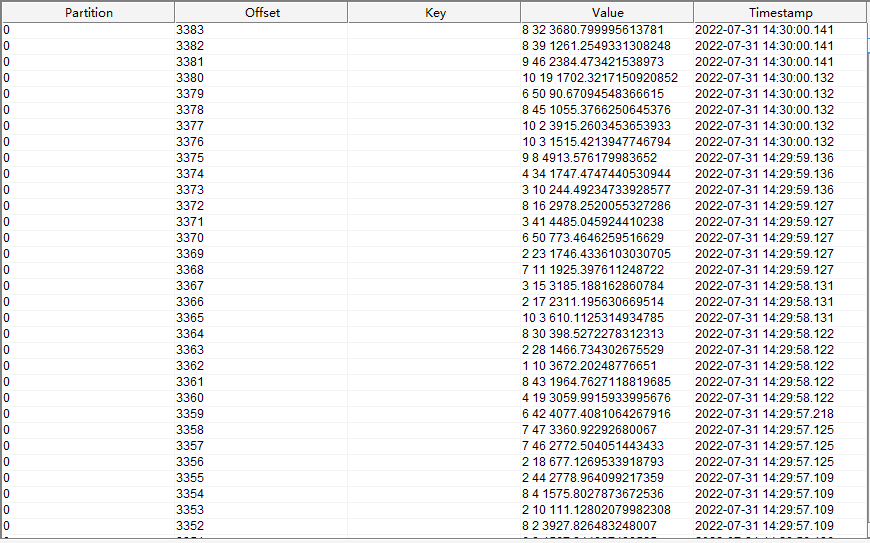
案例中的 kafka 主题 data_gen_source 中的数据来源于 flink sql 连接器 datagen 生成的随机数据,频率为1秒一条,该主题将作为后面其他案例的 source 使用。
-- 生成随机内容的 source 表
create table data_gen (
id integer comment '订单id',
product_count integer comment '购买商品数量',
one_price double comment '单个商品价格'
) with (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.id.kind' = 'random',
'fields.id.min' = '1',
'fields.id.max' = '10',
'fields.product_count.kind' = 'random',
'fields.product_count.min' = '1',
'fields.product_count.max' = '50',
'fields.one_price.kind' = 'random',
'fields.one_price.min' = '1.0',
'fields.one_price.max' = '5000'
)
;
-- kafka sink 表
create table kafka_sink (
id integer comment '订单id',
product_count integer comment '购买商品数量',
one_price double comment '单个商品价格'
) with (
'connector' = 'kafka',
'topic' = 'data_gen_source',
'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
insert into kafka_sink
select id, product_count, one_price
from data_gen
;
kafka 中 data_gen_source 主题的数据如下图所示:
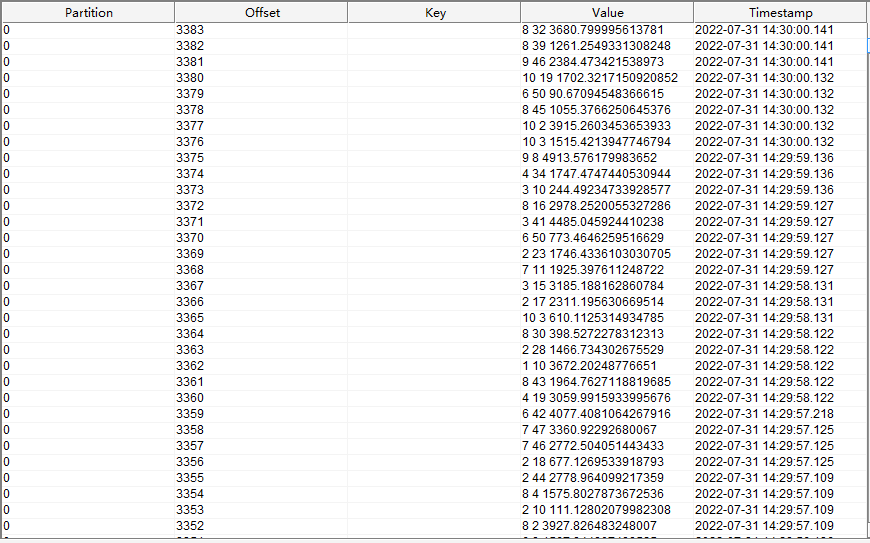
5. kafka -> kafka
kafka 作为 source 和 sink 的案例。
-- 创建连接 kafka 的虚拟表作为 source
CREATE TABLE source_kafka(
id integer comment '订单id',
product_count integer comment '购买商品数量',
one_price double comment '单个商品价格'
) WITH (
'connector' = 'kafka',
'topic' = 'data_gen_source',
'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
'properties.group.id' = 'for_source_test',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
-- 创建连接 kafka 的虚拟表作为 sink
create table sink_kafka(
id integer comment '订单id',
total_price double comment '总价格'
) with (
'connector' = 'kafka',
'topic' = 'for_sink',
'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
-- 真正要执行的任务,计算每个订单的总价
insert into sink_kafka
select id, product_count * one_price as total_price
from source_kafka
;
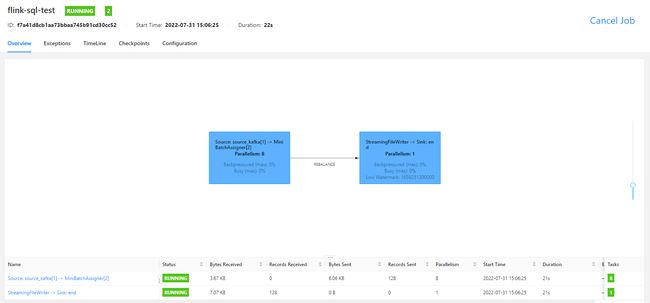
运行之后,flink UI 界面如下
sink 端的 kafka 接收到以下数据
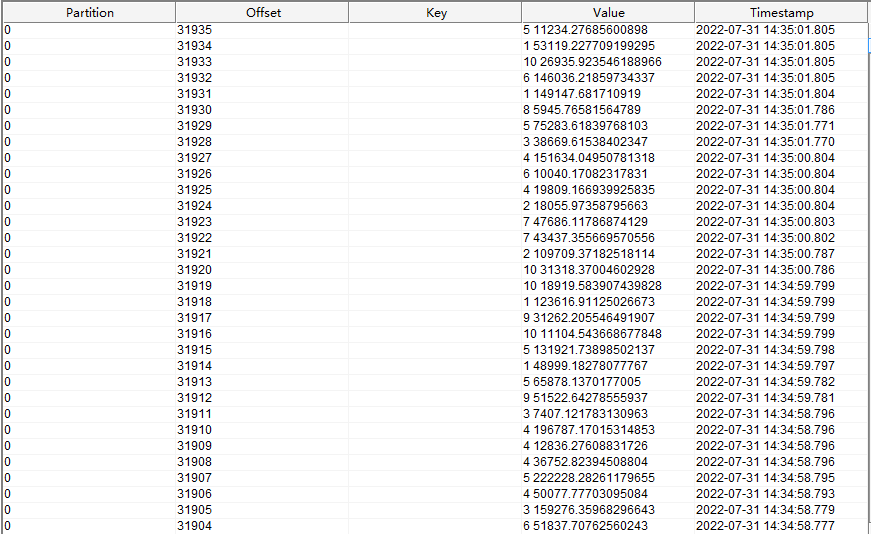
可以看到,value 中两个数字使用空格分隔,分别是订单的 id 和 订单总价。
6. kafka -> hive
6.1. 写入无分区表
下面的案例演示的是将 kafka 表中的数据,经过处理之后,直接写入 hive 无分区表,具体 hive 表中的数据什么时候可见,具体请查看 insert 语句中对 hive 表使用的 sql 提示。
hive 表信息
CREATE TABLE `test.order_info`(
`id` int COMMENT '订单id',
`product_count` int COMMENT '购买商品数量',
`one_price` double COMMENT '单个商品价格')
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/order_info'
TBLPROPERTIES (
'transient_lastDdlTime'='1659250044')
;
flink sql 语句
-- 如果是 flink-1.13.x ,则需要手动设置该参数
set 'table.dynamic-table-options.enabled' = 'true';
-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
-- 创建catalog
create catalog hive with (
'type' = 'hive',
'hive-conf-dir' = 'hdfs:///hadoop-conf'
)
;
use catalog hive;
-- 创建连接 kafka 的虚拟表作为 source,此处使用 temporary ,是为了不让创建的虚拟表元数据保存到 hive,可以让任务重启是不出错。
-- 如果想让虚拟表元数据保存到 hive ,则可以在创建语句中加入 if not exist 语句。
CREATE temporary TABLE source_kafka(
id integer comment '订单id',
product_count integer comment '购买商品数量',
one_price double comment '单个商品价格'
) WITH (
'connector' = 'kafka',
'topic' = 'data_gen_source',
'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
'properties.group.id' = 'for_source_test',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
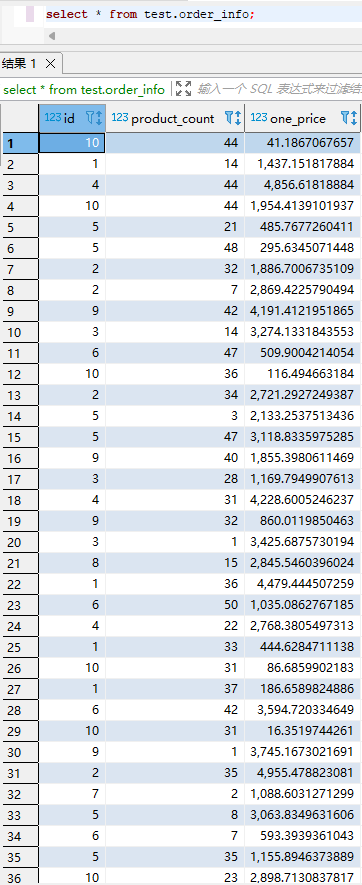
insert into test.order_info
-- 下面的语法是 flink sql 提示,用于在语句中使用到表时手动设置一些临时的参数
/*+
OPTIONS(
-- 设置写入的文件滚动时间间隔
'sink.rolling-policy.rollover-interval' = '10 s',
-- 设置检查文件是否需要滚动的时间间隔
'sink.rolling-policy.check-interval' = '1 s',
-- sink 并行度
'sink.parallelism' = '1'
)
*/
select id, product_count, one_price
from source_kafka
;
任务运行之后,就可以看到如下的 fink ui 界面了

本案例使用 streaming 方式运行, checkpoint 时间为 10 s,文件滚动时间为 10 s,在配置的时间过后,就可以看到 hive 中的数据了
从 hdfs 上查看 hive 表对应文件的数据,如下图所示
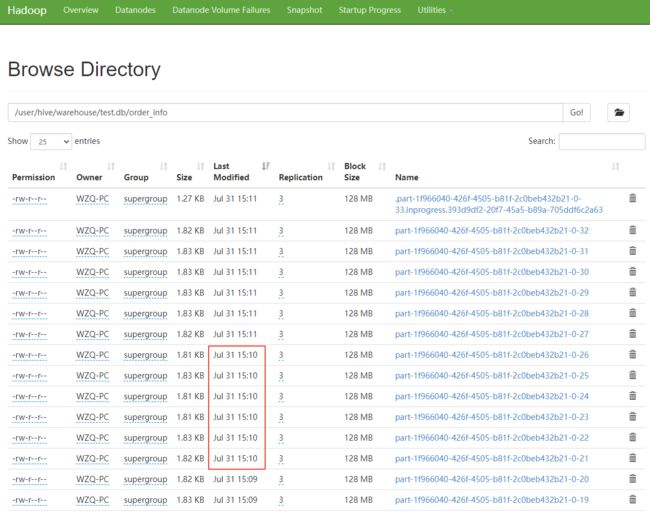
可以看到,1 分钟滚动生成了 6 个文件,最新文件为 .part 开头的文件,在 hdfs 中,以 . 开头的文件,是不可见的,说明这个文件是由于我关闭了 flink sql 任务,然后文件无法滚动造成的。
有关读写 hive 的一些配置和读写 hive 表时其数据的可见性,可以看考读写hive页面。
6.2. 写入分区表
hive 表信息如下
CREATE TABLE `test.order_info_have_partition`(
`product_count` int COMMENT '购买商品数量',
`one_price` double COMMENT '单个商品价格')
PARTITIONED BY (
`minute` string COMMENT '订单时间,分钟级别',
`order_id` int COMMENT '订单id')
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/order_info_have_partition'
TBLPROPERTIES (
'transient_lastDdlTime'='1659254559')
;
flink sql 语句
-- 如果是 flink-1.13.x ,则需要手动设置该参数
set 'table.dynamic-table-options.enabled' = 'true';
-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
-- 创建catalog
create catalog hive with (
'type' = 'hive',
'hive-conf-dir' = 'hdfs:///hadoop-conf'
)
;
use catalog hive;
-- 创建连接 kafka 的虚拟表作为 source,此处使用 temporary ,是为了不让创建的虚拟表元数据保存到 hive,可以让任务重启是不出错。
-- 如果想让虚拟表元数据保存到 hive ,则可以在创建语句中加入 if not exist 语句。
CREATE temporary TABLE source_kafka(
event_time TIMESTAMP(3) METADATA FROM 'timestamp',
id integer comment '订单id',
product_count integer comment '购买商品数量',
one_price double comment '单个商品价格'
) WITH (
'connector' = 'kafka',
'topic' = 'data_gen_source',
'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
'properties.group.id' = 'for_source_test',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
insert into test.order_info_have_partition
-- 下面的语法是 flink sql 提示,用于在语句中使用到表时手动设置一些临时的参数
/*+
OPTIONS(
-- 设置分区提交触发器为分区时间
'sink.partition-commit.trigger' = 'partition-time',
-- 'partition.time-extractor.timestamp-pattern' = '$year-$month-$day $hour:$minute',
-- 设置时间提取器的时间格式,要和分区字段值的格式保持一直
'partition.time-extractor.timestamp-formatter' = 'yyyy-MM-dd_HH:mm',
-- 设置分区提交延迟时间,这儿设置 1 分钟,是因为分区时间为 1 分钟间隔
'sink.partition-commit.delay' = '1 m',
-- 设置水印时区
'sink.partition-commit.watermark-time-zone' = 'GMT+08:00',
-- 设置分区提交策略,这儿是将分区提交到元数据存储,并且在分区目录下生成 success 文件
'sink.partition-commit.policy.kind' = 'metastore,success-file',
-- sink 并行度
'sink.parallelism' = '1'
)
*/
select
product_count,
one_price,
-- 不要让分区值中带有空格,分区值最后会变成目录名,有空格的话,可能会有一些未知问题
date_format(event_time, 'yyyy-MM-dd_HH:mm') as `minute`,
id as order_id
from source_kafka
;
flink sql 任务运行的 UI 界面如下
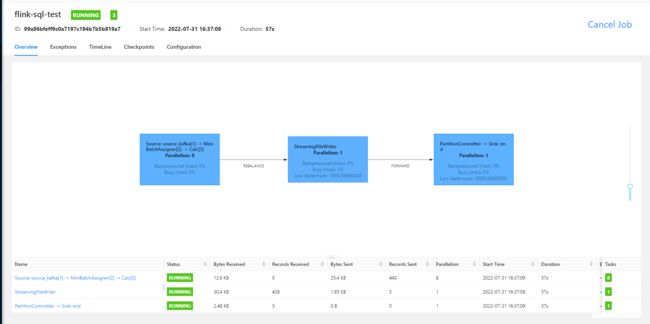
1 分钟之后查看 hive 表中数据,如下

查看 hive 表对应 hdfs 上的文件,可以看到

从上图可以看到,具体的分区目录下生成了 _SUCCESS 文件,表示该分区提交成功。
7. hive -> hive
source,source_table表信息和数据
CREATE TABLE `test.source_table`(
`col1` string,
`col2` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/source_table'
TBLPROPERTIES (
'transient_lastDdlTime'='1659260162')
;
source_table 表中的数据如下
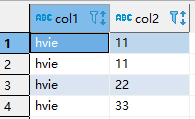
sink,sink_table表信息如下
CREATE TABLE `test.sink_table`(
`col1` string,
`col2` array<string> comment '保存 collect_list 函数的结果',
`col3` array<string> comment '保存 collect_set 函数的结果')
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/sink_table'
TBLPROPERTIES (
'transient_lastDdlTime'='1659260374')
;
sink_table 表数据如下
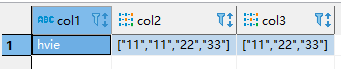
下面将演示两种 sql 方言,将 source_table 表数据,写入 sink_table 表,并且呈现上面图示的结果
7.1. 使用 flink 方言
set 'table.local-time-zone' = 'GMT+08:00';
-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
-- 创建catalog
create catalog hive with (
'type' = 'hive',
'hive-conf-dir' = 'hdfs:///hadoop-conf'
)
;
use catalog hive;
-- 加载 hive module 之后,flink 就会将 hive 模块放到模块解析顺序的最后。
-- 之后flink 引擎会自动使用 hive 模块来解析 flink 模块解析不了的函数,如果想改变模块解析顺序,则可以使用 use modules hive, core; 语句来改变模块解析顺序。
load module hive;
insert overwrite test.sink_table
select col1, collect_list(col2) as col2, collect_set(col2) as col3
from test.source_table
group by col1
;
7.2. 使用hive方言
set 'table.local-time-zone' = 'GMT+08:00';
-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
-- 创建catalog
create catalog hive with (
'type' = 'hive',
'hive-conf-dir' = 'hdfs:///hadoop-conf'
)
;
use catalog hive;
-- 加载 hive module 之后,flink 就会将 hive 模块放到模块解析顺序的最后。
-- 之后flink 引擎会自动使用 hive 模块来解析 flink 模块解析不了的函数,如果想改变模块解析顺序,则可以使用 use modules hive, core; 语句来改变模块解析顺序。
load module hive;
-- 切记,设置方言之后,之后所有的语句将使用你手动设置的方言进行解析运行
-- 这儿设置了使用 hive 方言,因此下面的 insert 语句就可以直接使用 hive sql 方言了,也就是说,下面可以直接运行 hive sql 语句。
set 'table.sql-dialect' = 'hive';
-- insert overwrite `table_name` 是 flink sql 方言语法
-- insert overwrite table `table_name` 是 hive sql 方言语法
insert overwrite table test.sink_table
select col1, collect_list(col2) as col2, collect_set(col2) as col3
from test.source_table
group by col1
;
8. temporal join(时态连接)
该案例中,将 upsert kafka 主题 order_info 中的数据作为维表数据,然后去关联订单流水表,最后输出完整的订单流水信息数据到 kafka。
订单流水表读取的是 kafka data_gen_source 主题中的数据,数据内容如下
订单信息维表读取的是 kafka order_info 主题中的数据,数据内容如下

实际执行的 flink sql 为
set 'table.local-time-zone' = 'GMT+08:00';
-- 如果 source kafka 主题中有些分区没有数据,就会导致水印无法向下游传播,此时需要手动设置空闲时间
set 'table.exec.source.idle-timeout' = '1 s';
-- 订单流水
CREATE temporary TABLE order_flow(
id int comment '订单id',
product_count int comment '购买商品数量',
one_price double comment '单个商品价格',
-- 定义订单时间为数据写入 kafka 的时间
order_time TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL,
WATERMARK FOR order_time AS order_time
) WITH (
'connector' = 'kafka',
'topic' = 'data_gen_source',
'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
'properties.group.id' = 'for_source_test',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
-- 订单信息
create table order_info (
id int PRIMARY KEY NOT ENFORCED comment '订单id',
user_name string comment '订单所属用户',
order_source string comment '订单所属来源',
update_time TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL,
WATERMARK FOR update_time AS update_time
) with (
'connector' = 'upsert-kafka',
'topic' = 'order_info',
'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
'key.format' = 'csv',
'value.format' = 'csv',
'value.csv.field-delimiter' = ' '
)
;
-- 创建连接 kafka 的虚拟表作为 sink
create table sink_kafka(
id int PRIMARY KEY NOT ENFORCED comment '订单id',
user_name string comment '订单所属用户',
order_source string comment '订单所属来源',
product_count int comment '购买商品数量',
one_price double comment '单个商品价格',
total_price double comment '总价格'
) with (
'connector' = 'upsert-kafka',
'topic' = 'for_sink',
'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
'key.format' = 'csv',
'value.format' = 'csv',
'value.csv.field-delimiter' = ' '
)
;
-- 真正要执行的任务
insert into sink_kafka
select
order_flow.id,
order_info.user_name,
order_info.order_source,
order_flow.product_count,
order_flow.one_price,
order_flow.product_count * order_flow.one_price as total_price
from order_flow
left join order_info FOR SYSTEM_TIME AS OF order_flow.order_time
on order_flow.id = order_info.id
;
flink sql 任务运行的 flink UI 界面如下

查看结果写入的 kafka for_sink 主题的数据为

此时新增数据到 kafka 维表主题 order_info 中,新增的数据如下

再查看结果写入的 kafka for_sink 主题的数据为
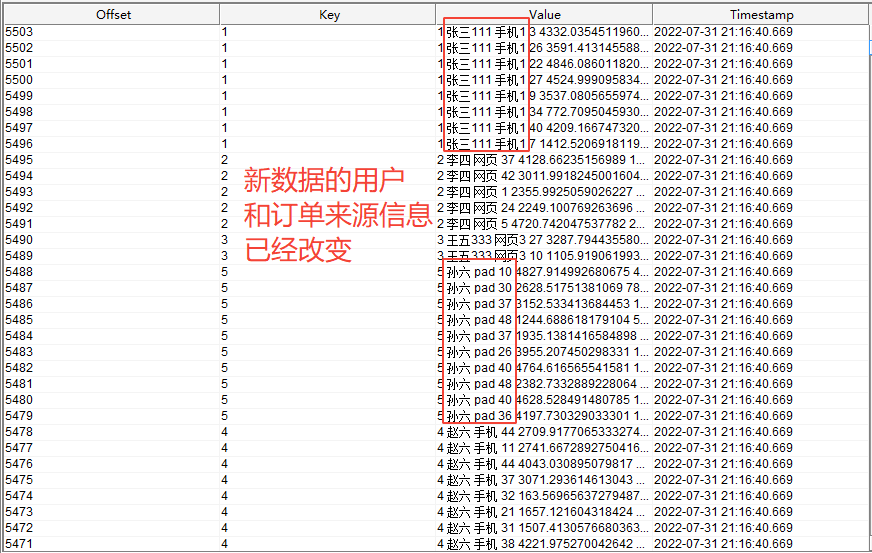
注意
经过测试发现,当将 upsert kafka 作为 source 时,主题中的数据必须有 key,否则会抛出无法反序列化数据的错误,具体如下
[INFO] [2022-07-31 21:18:22][org.apache.flink.runtime.executiongraph.ExecutionGraph]Source: order_info[5] (2/8) (f8b093cf4f7159f9511058eb4b100b2e) switched from RUNNING to FAILED on bbc9c6a6-0a76-4efe-a7ea-0c00a19ab400 @ 127.0.0.1 (dataPort=-1).
java.io.IOException: Failed to deserialize consumer record due to
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:56) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:33) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:143) ~[flink-connector-base-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:385) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:519) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:804) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:753) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:948) ~[flink-runtime-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:927) ~[flink-runtime-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:741) ~[flink-runtime-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563) ~[flink-runtime-1.15.1.jar:1.15.1]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_311]
Caused by: java.io.IOException: Failed to deserialize consumer record ConsumerRecord(topic = order_info, partition = 0, leaderEpoch = 0, offset = 7, CreateTime = 1659273502239, serialized key size = 0, serialized value size = 18, headers = RecordHeaders(headers = [], isReadOnly = false), key = [B@2add8ff2, value = [B@2a633689).
at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:57) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
... 14 more
Caused by: java.io.IOException: Failed to deserialize CSV row ''.
at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:162) ~[flink-csv-1.15.1.jar:1.15.1]
at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:47) ~[flink-csv-1.15.1.jar:1.15.1]
at org.apache.flink.api.common.serialization.DeserializationSchema.deserialize(DeserializationSchema.java:82) ~[flink-core-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.connectors.kafka.table.DynamicKafkaDeserializationSchema.deserialize(DynamicKafkaDeserializationSchema.java:119) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:54) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
... 14 more
Caused by: org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.exc.MismatchedInputException: No content to map due to end-of-input
at [Source: UNKNOWN; line: -1, column: -1]
at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.exc.MismatchedInputException.from(MismatchedInputException.java:59) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.DeserializationContext.reportInputMismatch(DeserializationContext.java:1601) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectReader._initForReading(ObjectReader.java:358) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectReader._bindAndClose(ObjectReader.java:2023) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectReader.readValue(ObjectReader.java:1528) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:155) ~[flink-csv-1.15.1.jar:1.15.1]
at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:47) ~[flink-csv-1.15.1.jar:1.15.1]
at org.apache.flink.api.common.serialization.DeserializationSchema.deserialize(DeserializationSchema.java:82) ~[flink-core-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.connectors.kafka.table.DynamicKafkaDeserializationSchema.deserialize(DynamicKafkaDeserializationSchema.java:119) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:54) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
... 14 more
9. 一些特殊语法
9.1. 列转行
也就是将数组展开,一行变多行,使用到 cross join unnest() 语句。
读取 hive 表数据,然后写入 hive 表。
source,source_table表信息如下
CREATE TABLE `test.source_table`(
`col1` string,
`col2` array<string> COMMENT '数组类型的字段')
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/source_table'
TBLPROPERTIES (
'transient_lastDdlTime'='1659261419')
;
source_table表数据如下

sink_table表信息如下
CREATE TABLE `test.sink_table`(
`col1` string,
`col2` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/sink_table'
TBLPROPERTIES (
'transient_lastDdlTime'='1659261915')
;
sink_table表数据如下

下面将使用两种方言演示如何将数组中的数据展开
9.1.1. 使用flink方言
set 'table.local-time-zone' = 'GMT+08:00';
-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
-- 创建catalog
create catalog hive with (
'type' = 'hive',
'hive-conf-dir' = 'hdfs:///hadoop-conf'
)
;
use catalog hive;
insert overwrite test.sink_table
select col1, a.col
from test.source_table
cross join unnest(col2) as a (col)
;
9.1.2. 使用hive方言
set 'table.local-time-zone' = 'GMT+08:00';
-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
-- 创建catalog
create catalog hive with (
'type' = 'hive',
'hive-conf-dir' = 'hdfs:///hadoop-conf'
)
;
use catalog hive;
load module hive;
set 'table.sql-dialect' = 'hive';
insert overwrite table test.sink_table
select col1, a.col
from test.source_table
lateral view explode(col2) a as col
;
10. kafka join JDBC
10.1. 常规 join
create table source (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_count integer comment '购买商品数量',
price_total double comment '总价'
) with (
'connector' = 'kafka',
'topic' = 'source1',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'scan.startup.mode' = 'latest-offset',
'properties.group.id' = 'test',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
create table dim_goods (
goods_id integer comment '商品id',
goods_name string comment '商品名称'
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop01:3306/test',
'username' = 'test',
'password' = 'test',
'table-name' = 'dim_goods'
)
;
create table sink (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_name string comment '商品名称',
goods_count integer comment '购买商品数量',
price_total double comment '总价'
) with (
'connector' = 'kafka',
'topic' = 'sink1',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
insert into sink
select id, a.goods_id, b.goods_name, a.goods_count, a.price_total
from source as a
join dim_goods as b
on a.goods_id = b.goods_id
;
直接使用常规 join ,发现任务运行之后,JDBC 对应的 source,会直接运行一次,加载完 mysql 表中的所有数据,然后 task 完成。
Flink UI 界面:
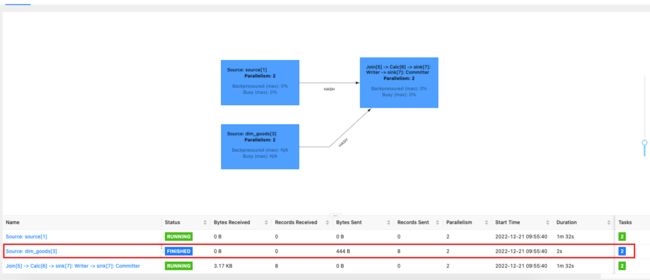
可以看到,MySql 表中的所有数据只会被完全加载一次,然后缓存到 Flink 内存中,之后对 MySql 表中的数据的更改,并不会影响运行中 flink 任务的结果。
通过不断往 kafka 中发送数据,可以证明这一点:
- 发送维表中有对应 id 的数据,维表中找到多条,则会产生多条结果。
- 发送维表中没有对应 id 的数据,则不会发送结果,和 join 的预期结果一致。
10.2. lookup join
set pipeline.operator-chaining = false;
create table source (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_count integer comment '购买商品数量',
price_total double comment '总价',
proctime as proctime()
) with (
'connector' = 'kafka',
'topic' = 'source1',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'scan.startup.mode' = 'latest-offset',
'properties.group.id' = 'test',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
create table dim_goods (
goods_id integer comment '商品id',
goods_name string comment '商品名称'
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop01:3306/test',
'username' = 'test',
'password' = 'test',
'table-name' = 'dim_goods'
)
;
create table sink (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_name string comment '商品名称',
goods_count integer comment '购买商品数量',
price_total double comment '总价'
) with (
'connector' = 'kafka',
'topic' = 'sink1',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
insert into sink
select id, a.goods_id, b.goods_name, a.goods_count, a.price_total
from source as a
join dim_goods FOR SYSTEM_TIME AS OF a.proctime as b
on a.goods_id = b.goods_id
;
flink 任务运行的 Flink UI 界面:

可以看到,在没有接收到 kafka 数据时,并没有去 mysql 维表中加载维表数据,而且任务执行图中也显示出现在执行的是 LookupJoin。
往 kafka 中发送数据,会出现以下情况:
- kafka 中的数据可以在在维表中找到对应 id 的数据,也就是可以关联上,则会进行一次处理,而且所有执行节点处理的数据量均为 1.
- kafka 中的数据在维表中找不到对应 id 的数据,也就是说关联不上,则只有 soruce 执行节点接收到了数据,后面的 LookupJoin 执行节点没有接收到数据,也就是说没有找到对应 id 的数据,后续也不进行处理,如下图:

注:lookup join 方式并不会缓存维表中的数据。
不够 JDBC 给 lookup join 提供了 lookup cache 功能,可以通过下面这两个 JCBC 参数开启:
'lookup.cache.max-rows' = '10000',
'lookup.cache.ttl' = '1 min'
上面参数二选一即可,也可同时设置,缓存的数据满足其中一个条件,就会过期,然后被清除。
注:如果在关联维表时还有一些对维表数据的过滤,则可以直接将条件写到 on 条件之后,使用 and 关键字连接即可。不推荐创建为表的视图,在视图里面提前对数据进行过滤,这会涉及到 primary key 相关的问题。示例如下:
from source as a
join dim_goods FOR SYSTEM_TIME AS OF a.proctime as b
on a.goods_id = b.goods_id and dt in (2)
其中,dt 字段是维表中的字段。
11. kafka 开窗
11.1. 单流开窗统计
由于该案例涉及到了维表关联,所以先创建了一个视图,用来完成维表关联,之后在视图的基础上进行开窗累加统计。
-- set pipeline.operator-chaining = false;
create table source (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_count integer comment '购买商品数量',
price_total double comment '总价',
proctime as proctime()
) with (
'connector' = 'kafka',
'topic' = 'source1',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'scan.startup.mode' = 'latest-offset',
'properties.group.id' = 'test',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
create table dim_goods (
goods_id integer comment '商品id',
goods_name string comment '商品名称',
dt integer comment '分区'
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop01:3306/test',
'username' = 'test',
'password' = 'test',
'table-name' = 'dim_goods',
'lookup.cache.max-rows' = '10000',
'lookup.cache.ttl' = '1 min'
)
;
create table sink (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_name string comment '商品名称',
goods_count integer comment '购买商品数量',
price_total double comment '总价',
window_start timestamp(3) comment '窗口开始时间',
window_end timestamp(3) comment '窗口结束时间',
primary key(id, goods_id, goods_name, window_start, window_end) not enforced
) with (
'connector' = 'upsert-kafka',
'topic' = 'sink1',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'key.format' = 'csv',
'value.format' = 'csv',
'value.csv.field-delimiter' = ' '
)
;
create view middle as
select id, a.goods_id, b.goods_name, a.goods_count, a.price_total, a.proctime
from source as a
join dim_goods FOR SYSTEM_TIME AS OF a.proctime as b
on a.goods_id = b.goods_id and dt in (1)
;
insert into sink
select id, goods_id, goods_name, sum(goods_count) as goods_count, sum(price_total) as price_total, window_start, window_end
from
table(
cumulate(table middle, descriptor(proctime), interval '1' minutes, interval '1' day)
)
group by id, goods_id, goods_name, window_start, window_end
;
注:该案例使用的渐进式窗口,在 group by 进行累加时,必须将窗口开始时间和结束时间字段都添加上,否则渐进式窗口会在每次接收到实时数据后做结果输出,而且会输出后续所有窗口的结果。如果最终结果不需要窗口时间字段,可以在外面再包一层,只挑选自己需要的字段。
如果聚合条件只写了 window_end ,而没有写 window_start,则结果输出为

可以看到,后续所有涉及到的窗口结果,都被输出了,而且是每接收到 kafka 一条数据,就会触发计算并输出结果。
如果聚合条件中把窗口开始时间和结束时间都写上的话,则会输出理想的结果,如下图所示
![]()
每次到达窗口结束时间时,不管上游 kafka 是否有新数据,会触发对应窗口计算,并且输出对应窗口的结果。
11.2. 多流合并开窗统计
11.2.1. 将多源合并之后开窗
这种方式的结果是正确的。
-- set pipeline.operator-chaining = false;
create table source1 (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_count integer comment '购买商品数量',
price_total double comment '总价',
proctime as proctime()
) with (
'connector' = 'kafka',
'topic' = 'source1',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'scan.startup.mode' = 'latest-offset',
'properties.group.id' = 'test',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
create table source2 (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_count integer comment '购买商品数量',
price_total double comment '总价',
proctime as proctime()
) with (
'connector' = 'kafka',
'topic' = 'source2',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'scan.startup.mode' = 'latest-offset',
'properties.group.id' = 'test',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
create table dim_goods (
goods_id integer comment '商品id',
goods_name string comment '商品名称',
dt integer comment '分区'
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop01:3306/test',
'username' = 'test',
'password' = 'test',
'table-name' = 'dim_goods',
'lookup.cache.max-rows' = '10000',
'lookup.cache.ttl' = '1 min'
)
;
create table sink (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_name string comment '商品名称',
goods_count integer comment '购买商品数量',
price_total double comment '总价',
window_start timestamp(3) comment '窗口开始时间',
window_end timestamp(3) comment '窗口结束时间',
primary key(id, goods_id, goods_name, window_start, window_end) not enforced
) with (
'connector' = 'upsert-kafka',
'topic' = 'sink1',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'key.format' = 'csv',
'value.format' = 'csv',
'value.csv.field-delimiter' = ' '
)
;
create view middle as
select id, a.goods_id, b.goods_name, a.goods_count, a.price_total, a.proctime
from source1 as a
join dim_goods FOR SYSTEM_TIME AS OF a.proctime as b
on a.goods_id = b.goods_id and dt in (1)
union all
select id, a.goods_id, b.goods_name, a.goods_count, a.price_total, a.proctime
from source2 as a
join dim_goods FOR SYSTEM_TIME AS OF a.proctime as b
on a.goods_id = b.goods_id and dt in (1)
;
insert into sink
select id, goods_id, goods_name, sum(goods_count) as goods_count, sum(price_total) as price_total, window_start, window_end
from
table(
cumulate(table middle, descriptor(proctime), interval '1' minutes, interval '1' day)
)
group by id, goods_id, goods_name, window_start, window_end
;
上面的 sql 中,首先将两个 source 流中的数据进行各自维表关联打宽,然后合并到一起,合并必须使用 union all,否则 porctime 时间属性特性会丢失,下面的开窗会无法使用。
之后对合并之后的视图进行开窗统计,经过测试,发现是理想的结果。上面 flink sql 任务对应 flink UI 界面为:

不管上游 kafka 是否会继续发送数据,每次到达小窗口触发时间,都会输出正确的计算结果,结果如下:

从结果中可以看到,每次小窗口触发计算之后,都会输出对应窗口的结果,而且是正确的结果。
11.2.2. 分别开窗之后再合并开窗-错误结果
这种方式的结果是错误的。
-- set pipeline.operator-chaining = false;
create table source1 (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_count integer comment '购买商品数量',
price_total double comment '总价',
proctime as proctime()
) with (
'connector' = 'kafka',
'topic' = 'source1',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'scan.startup.mode' = 'latest-offset',
'properties.group.id' = 'test',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
create table source2 (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_count integer comment '购买商品数量',
price_total double comment '总价',
proctime as proctime()
) with (
'connector' = 'kafka',
'topic' = 'source2',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'scan.startup.mode' = 'latest-offset',
'properties.group.id' = 'test',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
create table dim_goods (
goods_id integer comment '商品id',
goods_name string comment '商品名称',
dt integer comment '分区'
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop01:3306/test',
'username' = 'test',
'password' = 'test',
'table-name' = 'dim_goods',
'lookup.cache.max-rows' = '10000',
'lookup.cache.ttl' = '1 min'
)
;
create table sink (
id integer comment '订单id',
goods_id integer comment '商品id',
goods_name string comment '商品名称',
goods_count integer comment '购买商品数量',
price_total double comment '总价',
window_start timestamp(3) comment '窗口开始时间',
window_end timestamp(3) comment '窗口结束时间',
primary key(id, goods_id, goods_name, window_start, window_end) not enforced
) with (
'connector' = 'upsert-kafka',
'topic' = 'sink1',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'key.format' = 'csv',
'value.format' = 'csv',
'value.csv.field-delimiter' = ' '
)
;
create view middle1 as
select id, a.goods_id, b.goods_name, a.goods_count, a.price_total, a.proctime
from source1 as a
join dim_goods FOR SYSTEM_TIME AS OF a.proctime as b
on a.goods_id = b.goods_id
;
create view middle2 as
select id, a.goods_id, b.goods_name, a.goods_count, a.price_total, a.proctime
from source2 as a
join dim_goods FOR SYSTEM_TIME AS OF a.proctime as b
on a.goods_id = b.goods_id
;
create view result1 as
select id, goods_id, goods_name, sum(goods_count) as goods_count, sum(price_total) as price_total, max(proctime) as proctime, window_start, window_end
from
table(
cumulate(table middle1, descriptor(proctime), interval '1' minutes, interval '1' day)
)
group by id, goods_id, goods_name, window_start, window_end
;
create view result2 as
select id, goods_id, goods_name, sum(goods_count) as goods_count, sum(price_total) as price_total, max(proctime) as proctime, window_start, window_end
from
table(
cumulate(table middle2, descriptor(proctime), interval '1' minutes, interval '1' day)
)
group by id, goods_id, goods_name, window_start, window_end
;
-- 需要重新注册处理时间,上面的处理时间属性字段已经不可用了
create view result_union as
select id, goods_id, goods_name, goods_count, price_total, proctime() as proctime
from result1
union all
select id, goods_id, goods_name, goods_count, price_total, proctime() as proctime
from result2
;
insert into sink
select id, goods_id, goods_name, sum(goods_count) as goods_count, sum(price_total) as price_total, window_start, window_end
from
table(
cumulate(table result_union, descriptor(proctime), interval '1' minutes, interval '1' day)
)
group by id, goods_id, goods_name, window_start, window_end
;
由于第一次开窗使用了源中的 proctime 这个处理时间属性字段,所以下面再次开窗时,这个字段的时间属性已经丢失了,所以在 union all 两个源开窗合并的结果时,需要重新注册处理时间属性字段,之后使用该字段进行二次开窗统计。但是由于第一次开窗之后的结果对应的处理时间已经超过了对应的窗口结束时间,因此新注册的处理时间已经超过了上一个窗口的结束时间,下面再次开窗统计时,数据将会再下一次窗口内统计,所以最终的结果时间,已经是下一个窗口的时间了,时间明显滞后一个窗口时间。
另一个错误是:我上面使用的是渐进式窗口,因此第一个窗口会在每个小窗口结束时发送最新计算结果,而且不管上游的 kafka 有没有新数据,都会发送结果。如此一次,第二次的开窗,会不断的接收到第一次开窗的结果数据,所以第二次开窗中,除了第一个窗口,后面的窗口计算结果都错了,他们一直在累加。
我只往两个 kafka 源中发送了一次数据,之后再也没发送过数据,但是每次小窗口被触发之后,都会进行累加,具体结果如下:

Flink UI 界面两次窗口时间处理数据量如下:


从两张图中可以看出,在两次窗口触发时间中,第一次开窗对应的两个计算节点的输入数据都是 3,没有变化,但是输出数据量都从 1 变成 2,而且最后那个计算节点,也就是第二次开窗,接收的数据从 2 变成了 4,因此最终的结果输出,第二次的结果就是第一次结果的二倍。这一点,大家在具体使用中一定要注意,不可以将多个数据源第一次开窗的结果合并之后再次进行开窗。我上面使用的是渐进式窗口,滚动窗口理论上应该不会出现重复累加的问题,但是最终的结果在窗口时间上应该会滞后一个窗口时间。
12. WITH 子句
with 子句只能在一个 select 语句上面使用,不可单独编写,并且添加英文分号,将其作为一个单独的公共表达式,然后在多个 select 语句中使用。如果想实现在多个 select 语句中使用同一个公共表达式,可以通过创建临时视图来解决。
示例:
create temporary table source(
s1 string,
s2 string
) with (
'connector' = 'kafka',
'topic' = 'wzq_source',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'properties.group.id' = 'test-1',
'scan.startup.mode' = 'latest-offset',
'scan.topic-partition-discovery.interval' = '1 h',
'format' = 'csv'
);
create temporary table sink(
s1 string
) with (
'connector' = 'kafka',
'topic' = 'wzq_sink',
'properties.bootstrap.servers' = '${kafka-bootstrapserver}',
'format' = 'csv'
);
insert into sink
with with1 as (
select concat(s1, '|', s2) as w1
from source
),
with2 as (
select concat(w1, '-', 'w2') as w2
from with1
)
select w2
from with2
;