【Flink】各种窗口的使用(处理时间窗口、事件时间窗口、窗口聚合窗口)
文章目录
- 一 Flink 中的 Window
-
- 1 Window
-
- (1)Window概述
- (2) Window类型
-
- a 滚动窗口(Tumbling Windows)
- b 滑动窗口(Sliding Windows)
- c 会话窗口(Session Windows)
- 2 Window API
-
- (1)处理时间窗口
-
- a 滚动窗口
- b 滑动窗口
- c 会话窗口
- (2)事件时间窗口
-
- a 滚动窗口
- b 滑动窗口
- c 会话窗口
- (3)窗口聚合函数
-
- a 全窗口聚合函数
- b 增量聚合函数
- c 增量聚合和全窗口聚合结合使用 【推荐】
- (4)使用KeyedProcessFunction模拟滚动窗口
- (5)其他可选API
- (6)基于 Key 的窗口
- (7)不分流直接开窗口
- 3 总结
一 Flink 中的 Window
1 Window
(1)Window概述

streaming流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而window是一种切割无限数据为有限块进行处理的手段。
Window是无限数据流处理的核心,Window将一个无限的stream拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
(2) Window类型
Window可以分成两类:
-
CountWindow:计数窗口,按照指定的数据条数生成一个Window,与时间无关。
-
TimeWindow:时间窗口,按照时间生成Window。
对于TimeWindow,可以根据窗口实现原理的不同分成三类:
- 滚动窗口(Tumbling Window):是滑动窗口的特殊形式,是窗口大小和滑动距离相同的滑动窗口。
- 滑动窗口(Sliding Window):窗口间可以重叠。
- 会话窗口(Session Window):只有 Flink 支持。
a 滚动窗口(Tumbling Windows)
将数据依据固定的窗口长度对数据进行切片。
特点:时间对齐,窗口长度固定,没有重叠。
滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。例如:如果指定了一个5分钟大小的滚动窗口,窗口的创建如下图所示:
注意:先分流再开窗,在每个支流上开窗口,每个支流上的窗口之间没有关系。

适用场景:适合做BI统计等(做每个时间段的聚合计算)。
b 滑动窗口(Sliding Windows)
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
特点:时间对齐,窗口长度固定,可以有重叠。
滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
在Flink底层,其将处于不同窗口中的元素进行复制处理,然后分发到不同窗口中,所以需要合理分配窗口大小和滑动距离,若窗口大小为一天,滑动距离为一秒,同一份数据可能存在于几千个窗口中,内存可能会崩溃。
例如假如有10分钟的窗口和5分钟的滑动,那么每个窗口中5分钟的窗口里包含着上个10分钟产生的数据,如下图所示:

适用场景:对最近一个时间段内的数据进行统计(求某接口最近5min的失败率来决定是否要报警)。
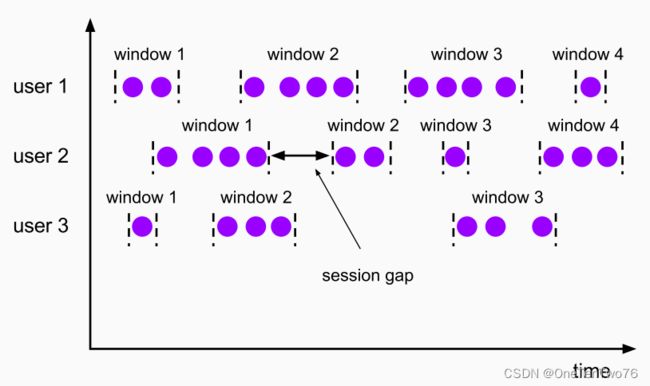
c 会话窗口(Session Windows)
由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
特点:时间无对齐。
session窗口分配器通过session活动来对元素进行分组,session窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。
一个session窗口通过一个session间隔来配置,这个session间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的session将关闭并且后续的元素将被分配到新的session窗口中去。
只有 Flink 支持会话窗口。
在某些场景下,使用会话窗口可以更加精确的刻画用户行为,如刷抖音。
2 Window API
窗口分配器——window() 方法
可以用.window() 来定义一个窗口,然后基于这个window 去做一些聚合或者其它处理操作。
(1)处理时间窗口
a 滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(5))):默认开的第一个窗口是在1970-01-01 00:00:00 - 1970-01-01 00:00:05,在这种情况下窗口不会开在3s - 8s时间段。
使用处理时间窗口中的滚动窗口实现求每个用户的pv:
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.addSource(new ClickSource())
.keyBy(r -> r.user)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new WindowResult())
.print();
env.execute();
}
// 泛型依次为:输入的泛型,输出的泛型,key的泛型,窗口的泛型
public static class WindowResult extends ProcessWindowFunction<Event,String,String, TimeWindow>{
// 在窗口关闭的时候,触发调用,只会调用一次
// 对于机器时间,运行到窗口结束时间就会关闭窗口
@Override
// 迭代器参数中包含了窗口中的全部元素
public void process(String key, Context context, Iterable<Event> iterable, Collector<String> collector) throws Exception {
long windowStart = context.window().getStart();
long windowEnd = context.window().getEnd();
// 获取迭代器里面的元素个数
long count = iterable.spliterator().getExactSizeIfKnown();
collector.collect("用户【" + key +"】在窗口" + new Timestamp(windowStart) +
" -- " + new Timestamp(windowEnd) + "中的pv次数是" + count);
}
}
b 滑动窗口
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
c 会话窗口
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
(2)事件时间窗口
a 滚动窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
b 滑动窗口
.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)))
c 会话窗口
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
(3)窗口聚合函数
窗口聚合函数定义了要对窗口中收集的数据做的计算操作可以分为两类
- 全窗口聚合函数。
- 增量聚合函数。
a 全窗口聚合函数
先把窗口所有数据收集起来,等到计算的时候会遍历所有数据,ProcessWindowFunction,优点在于可以访问窗口信息,如窗口的开始时间,结束时间,但问题是其需要将窗口里面的所有数据收集起来再做计算,对存储系统来说是比较大的压力。
2 (1)中用户的pv实现使用的就是就是全窗口聚合函数。

b 增量聚合函数
- 每条数据到来就进行计算,只保存一个简单的状态(累加器),极大的节省内存,缺点就是无法访问窗口的信息。窗口中的所有元素就是一个状态,在底层使用列表状态变量实现。
- 增量聚合函数有 ReduceFunction 和 AggregateFunction,AggregateFunction比前者更加底层,更加灵活。
- 当窗口闭合的时候,增量聚合完成。
- 处理时间:当机器时间超过窗口结束时间的时候,窗口闭合。
- 来一条数据计算一次。

使用增量聚合函数实现每个窗口的pv:
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.addSource(new day02.Example1.ClickSource())
.keyBy(r -> r.user)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(new CountAgg())
.print();
env.execute();
}
public static class CountAgg implements AggregateFunction<day02.Example1.Event,Integer,Integer>{
// 创建累加器
@Override
public Integer createAccumulator() {
return 0;
}
// 定义累加规则,将返回值作为新的累加器
@Override
public Integer add(day02.Example1.Event value, Integer accumulator) {
return accumulator + 1;
}
// 在窗口关闭时,返回结果
@Override
public Integer getResult(Integer accumulator) {
return accumulator;
}
// 实现窗口的合并操作
@Override
public Integer merge(Integer a, Integer b) {
return null;
}
}
c 增量聚合和全窗口聚合结合使用 【推荐】
- 全窗口聚合函数的作用就是给增量聚合函数包裹一层窗口的信息。
- 不需要收集窗口中的所有元素,只需要维护一个累加器,节省内存。

当窗口闭合时,增量聚合函数会将其输出发送给全窗口聚合函数,这时全窗口聚合函数输入的泛型变成了增量函数输出的类型integer,见以下代码:
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.addSource(new day02.Example1.ClickSource())
.keyBy(r -> r.user)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(new CountAgg(),new WindowResult())
.print();
env.execute();
}
public static class WindowResult extends ProcessWindowFunction<Integer,String,String, TimeWindow>{
@Override
public void process(String key, Context context, Iterable<Integer> iterable, Collector<String> collector) throws Exception {
// 迭代器参数中只包含一个元素,就是增量聚合函数发送过来的聚合结果
long windowStart = context.window().getStart();
long windowEnd = context.window().getEnd();
// 获取迭代器里面的元素个数
long count = iterable.iterator().next();
collector.collect("用户【" + key +"】在窗口" + new Timestamp(windowStart) +
" -- " + new Timestamp(windowEnd) + "中的pv次数是" + count);
}
}
(4)使用KeyedProcessFunction模拟滚动窗口
模拟5s的滚动窗口,模拟的是增量聚合函数和全窗口聚合函数结合使用的情况。
注意:滚动窗口为左闭右开,使用哈希表模拟窗口。
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.addSource(new Example1.ClickSource())
.keyBy(r -> r.user)
.process(new FakeWindow())
.print();
env.execute();
}
public static class FakeWindow extends KeyedProcessFunction<String, Example1.Event,String>{
// key是窗口的开始时间,value是窗口中的pv值,也是一个累加器
private MapState<Long,Integer> mapState;
// 窗口大小
private Long windowSize = 5000L;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
mapState = getRuntimeContext().getMapState(new MapStateDescriptor<Long, Integer>("windowStare-pvCount", Types.LONG,Types.INT));
}
@Override
public void processElement(Example1.Event event, Context context, Collector<String> collector) throws Exception {
// 计算当前元素所属的窗口开始时间
long currTime = context.timerService().currentProcessingTime();
long windowStart = currTime - currTime % windowSize;
long windowEnd = windowStart + windowSize;
if (mapState.contains(windowStart)){
mapState.put(windowStart,mapState.get(windowStart) + 1);
}else{
mapState.put(windowStart,1);
}
// 注册一个窗口结束时间前一毫秒的定时器(左闭右开),用来触发窗口函数的计算
// 同一个时间戳只能定义一个定时器,即同一个窗口中,只有一个定时器
context.timerService().registerProcessingTimeTimer(windowEnd - 1L);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
super.onTimer(timestamp, ctx, out);
long windowEnd = timestamp + 1L;
long windowStart = windowEnd - windowSize;
int count = mapState.get(windowStart);
// 向下游发送数据
out.collect("用户【" + ctx.getCurrentKey() +"】在窗口" + new Timestamp(windowStart) +
" -- " + new Timestamp(windowEnd) + "中的pv次数是" + count);
mapState.remove(windowStart);
}
}
总结:在keyBy以后针对不同的key又新开了一个mapState,其作用域范围就是当前的key,同时,(3)c中的增量聚合初始化了一个累加器,这个累加器在模拟窗口实现时等于MapState的value;如果想要模拟一个全窗口聚合,只需要将value由Integer换成列表,将所有元素存储下来。
在生产环境中不太可能用到此种写法。
(5)其他可选API
.trigger() ——触发器 定义窗口什么时候关闭,触发计算并输出结果
.evictor() ——移除器 定义移除某些数据的逻辑
.allowedLateness() ——允许处理迟到的数据
.sideOutputLateData() ——将迟到的数据放入侧输出流
.getSideOutput() ——获取侧输出流
(6)基于 Key 的窗口
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
(7)不分流直接开窗口
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
其中,windowAll的底层实现就是先将流存放到同一个插槽中,再开窗.keyBy(r -> true)
3 总结
目前已经使用了Flink 提供的 4 个 Process Function:
- ProcessFunction:不分流直接聚合,不可以使用定时器和状态变量,因为其没有经过keyBy,定时器和状态变量都是针对key的,只有processElement。
- KeyedProcessFunction:分流以后聚合。
- ProcessWindowFunction:分流后再开窗。
- ProcessAllWindowFunction:不分流,直接开窗。