最新!基于Transformer的自动驾驶传感器融合研究综述
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【多传感器融合】技术交流群
后台回复【多传感器融合综述】获取图像/激光雷达/毫米波雷达融合综述等干货资料!
https://arxiv.org/pdf/2302.11481.pdf
传感器融合是许多感知系统中的一个重要课题,例如自动驾驶和机器人。在许多数据集上的排行榜,基于transformer的检测头和基于CNN的特征编码器(从原始传感器数据中提取特征),已成为性能最高的3D检测多传感器融合框架之一。本文提供了最近基于transformer的3D目标检测任务的文献综述,主要集中于传感器融合,介绍了视觉transformer(ViT)的基础知识,还简要论述了用于自动驾驶的传感器融合的几种非transformer式较少占主导地位的方法。最后总结了transformer在传感器融合领域中的作用,并提出了该领域的未来研究方向。
更多内容可以参考:https://github.com/ApoorvRoboticist/Transformers-SensorFusion
传感器融合是整合来自不同信息源的感知数据,利用不同传感器捕获的互补信息,融合有助于减少状态估计的不确定性,并使3D目标检测任务更加稳健。目标属性在不同的模式中不具有同等的可识别性,因此需要利用不同的模式并从中提取补充信息。例如,激光雷达可以更好地定位潜在物体,radar可以更好地估计场景中物体的速度,最后但并非最不重要的是,相机可以通过密集的像素信息对物体进行分类。
为什么传感器融合困难?
不同模态的传感器数据除了在每个传感器的坐标空间的差异之外,通常在数据分布上存在较大差异。例如,LiDAR在笛卡尔坐标空间中,Radar位于极坐标空间,图像位于透视空间。不同坐标系引入的空间失准使得难以将这些模态合并在一起。多模态输入的另一个问题是,当ML网络可以使用camera和LiDAR送入时,会出现异步时间线的问题。

现有的传感器融合模型的总体架构图如上所示,基于transformer的Head(绿色),基于CNN的特征提取器(蓝色),用于预测3D鸟瞰图(BEV)边界框(黄色块),每个传感器具有中间BEV特征(紫色块),该传感器融合设置为从多视图相机、激光雷达和雷达接收输入。
虽然CNNs可用于在单个模态内捕获全局上下文,但将其扩展到多个模态并精确地建模成对特征之间的交互是非常重要的。为了克服这一限制,使用transformer的注意力机制将关于2D场景的全局上下文推理直接集成到模态的特征提取层中。序列建模和视听融合的最新进展表明,基于Transformer的体系结构在序列或跨模态数据的信息交互建模方面非常有效!
领域背景
融合level:最近,多传感器融合在3D检测界引起了越来越多的兴趣。现有方法可分为detection-level、proposal-level、point-level 融合方法,这取决于融合不同模态(即相机、雷达、激光雷达等)的早期或后期程度!
detection-level即后期融合已经成为最简单的融合形式,因为每个模态都可以单独处理自己的BEV检测,然后可以使用匈牙利匹配算法和卡尔曼滤波进行后处理,以聚合和删除重复检测。然而,这种方法不能利用这样一个事实,即每个传感器也可以对单个边界框预测中的不同属性做出贡献。CLOCS可以融合基于lidar的3D目标检测和2D检测任务的结果,它在非最大值抑制之前对两个输出候选进行操作,并使用两组预测之间的几何一致性来消除假阳性(FP),因为在不同的模式下很可能同时检测到相同的FP。
point-level又称早期融合,利用相机功能增强了LiDAR点云,在该方法中,使用变换矩阵找到LiDAR点和图像之间的硬关联。然而,由于融合质量受到点稀疏性、甚至有时当两个传感器的标定参数中存在轻微误差时,这种方法都会受到影响。
proposal-level即深度融合是目前文献中研究最多的方法,transformer[5,6,7]的进展解锁了中间特征如何交互的可能性,尽管它们来自不同的传感器。MV3D提出的代表性工作从LiDAR特征中提取初始边界框,并使用图像特征对其进行迭代优化。BEVFusion生成基于相机的BEV特征,如[10,11,12,13]中所强调的。Camera和激光雷达模态在BEV空间中连接,BEV解码器用于预测3D box作为最终输出。在TransFuser中,单视图图像和LiDAR的BEV表示由编码器中的transformer在各种中间特征图上融合。这导致编码器的512维特征向量输出,其构成局部和全局上下文的紧凑表示。此外,本文将输出反馈给GRU(门控递归单元),并使用L1回归损失预测可微自车路线点。4D网络[16]除了是多模态的,还将时间维度作为第四维度添加到问题中。首先单独提取相机和激光雷达的时间特征[17],添加图像表示的不同上下文,论文收集了三个层次的图像特征,即高分辨率图像、低分辨率图像和视频。然后,使用变换矩阵融合交叉模态信息,以获取给定3D pillar中心的2D上下文,该中心由BEV网格单元的中心点(xo,yo,zo)定义!
基于transformer的融合网络背景
该方法可分为三个步骤:
1.应用基于神经网络的主干从所有模态中单独提取空间特征;
2.在transformer模块中迭代细化一小组学习嵌入(目标Query/proposal),以生成一组3D box的预测;
3.计算loss;
该架构如图1所示!
(1)Backbone
Camera:多camera图像被馈送到backbone(例如,ResNet-101)和FPN,并获得特征;
LiDAR:通常使用0.1m体素大小的voxelnet或0.2m pillar大小的PointPill对点进行编码,在3D主干和FPN之后,获得了多尺度BEV特征图;
Radar:通过MLP将location、intensity、 speed转换为特征!
(2) Query Initialization
在开创性工作[5]中,稀疏Query 被学习为一个网络参数,并且是整个训练数据的代表。这种类型的Query 需要更长的时间,即更多的顺序解码器层(通常为6个)来迭代收敛到场景中的实际3d目标。然而,最近依赖于输入的Query [20]被认为是一种更好的初始化策略。这种策略可以将6层转换器解码器降到甚至单层解码器层, Transfusion使用中心热图作为Query,BEVFormer引入了密集Query作为等距BEV网格!
(3)Transformers Decoder
为了细化目标proposal,在ViT模型中顺序使用Transformer解码器的重复模块,其中每个块由自关注层和交叉关注层组成。目标Query 之间的自关注在不同的目标候选之间进行成对推理。基于学习注意力机制,目标Query和特征图之间的交叉注意力将相关上下文聚合到目标Query中。由于巨大的特征尺寸,交叉注意力是链条中最慢的一步,但已经提出了减少注意力窗口的技术[24]。在这些顺序解码器之后,d维细化Query 被独立解码,FFN层如下 [14]. FFN预测与Query位置的中心偏移δx,δy,边界框高度为z,尺寸l,w,h为log(l),log(w),log(h),偏航角α为sin(α)和cos(α),速度为vx,vy,最后,针对K个语义类预测每类概率,.
(4)损失计算
通过匈牙利算法,使用基于set的预测和GT之间的匹配,其中匹配cost定义为:
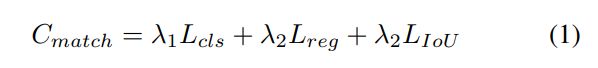
基于transformer的传感器融合
TransFusion:通过特征的软关联解决了模态未对准问题,第一解码器层构成从LiDAR BEV特征生成稀疏Query,第二解码器层通过利用仅在从Query解码的边界框周围具有交叉关注的局部感应偏差,利用具有软关联的图像特征丰富LiDAR Query,它们还具有图像引导的Query初始化层!
FUTR3D:与[6]密切相关,它对任何数量的传感器模态都是鲁棒的。MAFS(模态不可知特征采样器)接受3D Query,并从多视图相机、高分辨率激光雷达、低分辨率激光雷达和雷达收集特征。具体来说,它首先对Query进行解码以获得3D coordinate,然后将其用作锚点,以迭代方式从所有模态中收集特征。BEV特征用于激光雷达和相机,但对于雷达,在MAFS中选择了前k个最近的雷达点。对于每个Query i,所有这些特征F都连接如下,其中Φ是MLP层:
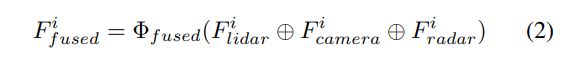
CMT:跨模态transformer通过坐标编码将3D坐标编码为多模态token,来自位置引导Query生成器的Query用于与transformer解码器中的多模态token交互,然后预目标参数。进一步引入基于点的Query去噪,通过引入局部先验来加速训练收敛。
UVTR: Unifying Voxel based Representation with Transformer统一了体素空间中的多模态表示,以实现准确和稳健的单模态或跨模态3D检测。模态特定空间首先被设计为表示体素空间中的不同输入,而无需高度压缩,以减轻语义模糊并实现空间连接。与其它BEV方法相比,这是一种更复杂、信息更密集的表示。对于图像体素空间,透视图特征通过视图变换变换到预定义空间,基于CNN的体素编码器被引入用于多视图特征交互。对于点体素空间,3D点可以自然地转换为体素。在这些体素特征上使用稀疏卷积来聚集空间信息。与图像相比,通过在点云中的精确位置,z方向上的语义模糊性大大降低!
LIFT: LiDAR图像融合transformer能够对齐4D时空交叉传感器信息。与[16]相反,它利用了顺序多模态数据的综合利用。对于顺序数据处理,使用车辆姿态的先验来消除时间数据之间自我运动的影响。论文将激光雷达帧和相机图像编码为稀疏的BEV网格特征,并提出了一个传感器时间4D注意力模块来捕捉相互关联!
与其它相比,DeepInteraction采用了稍微不同的方法,由于其固有的局限性,由于大量不完善的信息融合到统一表示中,可能会降低很大一部分模态特定表示强度,因此先前的方法在结构上受到限制,如[3,9]所示。它们不是推导融合的单一BEV表示,而是学习并保持两种模态特定表示,以实现模态间的交互,从而可以自发地实现信息交换和模态特定优势。作者将其称为多输入多输出(MIMO)结构,将其作为输入,并产生两个细化的表示作为输出。本文包括从LiDAR和视觉特征中顺序更新的类似DETR3D的Query,在基于transformer的解码器层中具有顺序交叉关注层。
Autoalign:论文使用可学习的对齐图来建模图像和点云之间的映射关系,而不是像其它方法那样为传感器投影矩阵建立确定性对应关系。该映射使模型能够以动态数据驱动的方式自动对齐非均匀特征,它们利用交叉关注模块自适应地聚合每个体素的像素级图像特征。
定量分析
在这里,本文比较了之前讨论的nuScenes方法,这是一个大型多模态数据集,由表1中的6台摄像机、1台激光雷达和5台雷达的数据组成。该数据集共有1000个场景,训练/验证/测试集分为700/150/150个场景。
相机:每个场景有20帧视频,12 FPS。3D边界框标注为0.5秒,每个示例包括6个相机。
激光雷达:具有20FPS的32光束激光雷达也每0.5秒进行一次注释。
指标:遵循nuScene的官方指标。关键指标如下:nuScenes检测分数(NDS)、平均精度(mAP)、平均平移误差(mATE)、平均尺度误差(mASE)、平均方位误差(mAOE)、平均速度误差(mAVE)和平均属性误差(mAAE)。

一些调研结论
对于自动驾驶汽车的感知可靠性,准确的3D目标检测是需要解决的关键挑战之一,传感器融合有助于利用平台上所有传感器的优势,使这些预测更加准确。transformer已成为建模这些跨模态交互的最重要方法之一,特别是当传感器在不同的坐标空间中运行时,这使得无法完美对齐!
参考
[1] TRANSFORMER-BASED SENSOR FUSION FOR AUTONOMOUS DRIVING: A SURVEY
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称