标签分配PAA(ECCV 2020)原理与代码解析
paper:Probabilistic Anchor Assignment with IoU Prediction for Object Detection
code1:https://github.com/kkhoot/PAA
code2:https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/dense_heads/paa_head.py
本文提出了一种新的标签分配策略,根据模型的学习状态自适应的将anchor划分为正负样本,从而能够以概率的方式解释正负样本的划分。为此首先基于模型计算anchor的得分,然后用一个概率分布拟合这些分数,然后根据anchor的概率将其划分正负样本。此外作者还研究了训练和测试目标之间的差距,并提出预测检测框的IoU作为定位质量的评估来减少这种差距。将分类得分和定位质量的联合作为NMS中过滤的阈值,和提出的标签分配结合使用,可以显著提高模型的性能。
存在的问题
根据anchor与GT box之间IoU的大小进行正负样本的划分是目前应用最广泛的方法,但这种方法有一个明显的局限即它忽略了交叉区域的实际内容,其中可能有背景噪声、附近的其它对象或只包含待检测对象的很少部分有意义的区域。
本文的创新点
一个灵活的分配方法不应该只考虑和GT之间的IoU,还要考虑模型有多大的概率可以解释这种分配。因此,模型也需要参与分配过程,根据模型状态的不同分配的正样本也应该不同。
本文提出了一种新的标签分配方法,该方法根据模型的学习状态自适应的将一组anchor划分为正负样本,其中正样本的数量不是固定的,标签分配不仅依赖于anchor和GT box之间的IoU,而且还考虑到模型有多大的概率可以推理出正负样本的划分。因此模型需要参与标签分配的过程,并且正样本也随着模型的变化而变化。需要对一个anchor划分为正样本的质量进行评估以反映模型当前的学习状态。
此外作者还观察到了大多数检测模型训练和推理过程的不一致,训练时同时最小化分类和定位损失,推理时NMS只考虑分类得分。因此提出预测一个检测框的IoU作为定位质量的评估,并且在NMS中用预测的IoU和分类得分的乘积代替原本的分类得分。
最后,还提出了得分投票作为一种额外的后处理来进一步提升模型性能。
方法介绍
Probabilistic Anchor Assignment Algorithm
本文的目标是设计一种标签分配方法,它需要考虑三个关键因素:首先,评价一个anchor的质量应该依赖于当这个anchor作为正样本时模型有大多的概率可以根据这个anchor准确度识别目标对象。其次,正负样本的划分应该是自适应的,因此不需要一个超参比如IoU阈值。第三,分配策略应该被表述为一个概率分布的最大似然以便模型能够以一种概率的方式推理这种分配。
对于一个anchor需要定义一个得分来反映它对于最近的GT预测的bounding box的质量,直觉上计算一个分类得分和一个定位得分并相乘非常合适,如下
其中 \(S_{cls},S_{loc},\lambda\) 别是给定ground truth \(g\) 和anchor \(a\) 的分类得分和定位得分以及可调权重。\(x\) 是输入图片,\(\theta\) 是是模型参数。可以看出,这个得分依赖于模型的参数。对于 \(S_{cls}\) 可以从模型的分类head得到,\(S_{loc}\) 定义为predicted box和GT box之间的IoU,如下
对得分取负对数,得到
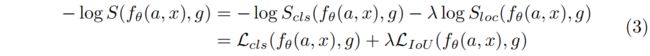
其中 \(\mathcal{L}_{cls}\) 和 \(\mathcal{L}_{IoU}\) 分别表示交叉熵损失和IoU损失,也可以换成更高级的损失比如Focal Loss和GIoU Loss。
为了让模型可以预测一个anchor有多大的概率是一个正样本,将对于某个GT的anchor得分建模为从一个概率分布的采样,并且最大化anchor得分相对于这个分布参数的似然。然后就可以根据某个anchor是正负样本的概率进行划分,因为目标是将一组anchor划分为两组(正负样本),任何可以建模样本multi-modality的概率分布都可以使用,本文使用two-modality的高斯混合模型(Gaussian Mixture Model, GMM)来建模anchor的得分分布
其中 \(w_{1},m_{1},p_{1}\) 和 \(w_{2},m_{2},p_{2}\) 分别表示两个高斯分布的weight, mean和precision。给定一组anchor的得分,可以使用Expectation-Maximization (EM)算法来优化GMM的似然。
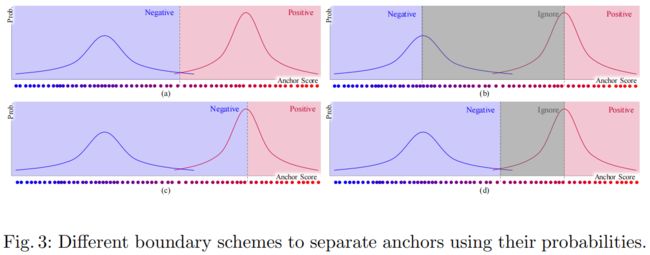
利用EM估计的GMM参数,就可以确定每个anchor作为正负样本的概率,然后就可以不同的方法将anchor划分为两组。下图是几个不同的划分方法
完整的算法流程如下所示

为了计算anchor得分,首先将其分配给IoU最大的GT(第3行)。为了提高EM的效率,从每个金字塔层(第5-11行)收集top \(K\) 个anchor并应用EM算法(第12行)。其余的anchor作为负样本(第16行)。最终的训练目标如下,其中省略了输入图片 \(x\)。

其中 \(P_{pos}(a,\theta,g)\) 和 \(P_{neg}(a,\theta,g)\) 表示anchor是正样本或负样本的概率并可以通过本文提出的PAA得到。\(\varnothing\) 表示背景类别。
IoU Prediction as Localization Quality
PAA中anchor得分是由分类和定位两个任务的联合损失推导出的,因此标签分配可以和损失的优化很好的对齐。但在推理过程中确不是这样,因为在NMS中只考虑分类得分。为了解决这个问题,可以将定位质量引入NMS,这样就可以使用式(1)中得分。但GT的信息仅在训练阶段可用,推理时无法计算预测的bounding box和对应的GT box之间的IoU。针对这个问题,本文提出了一个简单的解决方法,即让模型来预测predicted box和对应GT之间的IoU,实际操作很简单,只需要一层额外的卷积作为预测头针对每个anchor输出一个标量,然后通过Sigmoid函数得到预测的IoU值。训练目标变为如下
其中 \(L_{IoUP}\) 是IoU的预测损失,定义为预测的IoU和实际IoU之间的交叉熵损失。有了预测的IoU,推理时就可以按式(1)得到的得分作为NMS中的ranking metric。
Score Voting
此外,本文还提出了一种简单有效的后处理方法score voting,在NMS后,score voting作用于剩下的每个box。
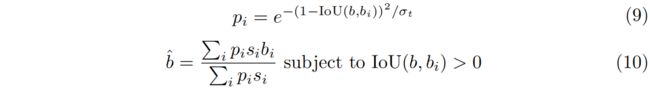
其中 \(\hat{b},s_{i},\sigma_{t}\) 分别为更新后的box、按式(1)计算得到的分数以及一个用于调整相邻box \(b_{i}\) 的超参。
实验结果
表1左边上半部分比较了图(3)中四种不同正负样本边界划分方法的效果,可以看出(c)的效果最好。下半部分是两种常见标签分配方法的性能,其中FNP是fixed numbers of positives固定正样本的个数即选择得分最好的固定个数的anchor作为正样本,FSR是fixed positive score ranges固定得分范围即固定得分阈值,选择得分大于设定阈值的anchor作为正样本。可以看出两者的效果都不如本文提出的PAA。其中当采样FSR(>0.3)时模型训练失败这是因为在训练的早期模型找不到得分大于0.3的anchor。

表(1)右侧是分析了本文提出的PAA中单个模块的效果,与采用IoU阈值的baseline相比,标签分配方法换成PAA性能提高了5.3%,当引入IoU预测分支后AP又提高了1%,最后再加上score voting,AP又提高了0.2%。
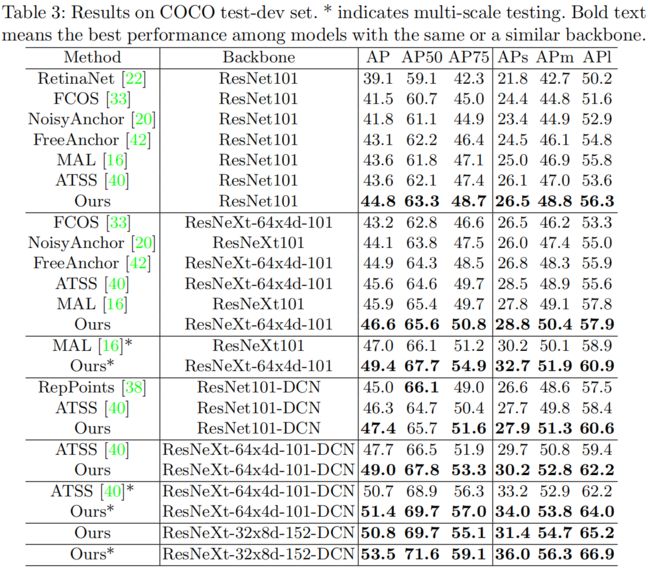
下表是和其它SOTA方法的对比,可以看出在相同的backbone和训练配置下,PAA取得了最优的效果。
代码解析
这里以mmdetection中的实现为例,介绍下具体实现。代码主要在head中即mmdet/models/dense_heads/paa_head.py文件中。
在损失函数def loss()中,首先通过self.get_targets进行第一步的标签分配并得到分类和回归的targets,这里是按常用的max IoU的方法,mmdet中通过assigner实现,配置如下
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.1,
neg_iou_thr=0.1,
min_pos_iou=0,
ignore_iof_thr=-1)然后按式(1)计算anchor的得分,通过取负对数转换为求分类和回归损失的加权和,即式(3),代码如下
def get_pos_loss(self, anchors, cls_score, bbox_pred, label, label_weight,
bbox_target, bbox_weight, pos_inds):
"""Calculate loss of all potential positive samples obtained from first
match process.
Args:
anchors (list[Tensor]): Anchors of each scale.
cls_score (Tensor): Box scores of single image with shape
(num_anchors, num_classes)
bbox_pred (Tensor): Box energies / deltas of single image
with shape (num_anchors, 4)
label (Tensor): classification target of each anchor with
shape (num_anchors,)
label_weight (Tensor): Classification loss weight of each
anchor with shape (num_anchors).
bbox_target (dict): Regression target of each anchor with
shape (num_anchors, 4).
bbox_weight (Tensor): Bbox weight of each anchor with shape
(num_anchors, 4).
pos_inds (Tensor): Index of all positive samples got from
first assign process.
Returns:
Tensor: Losses of all positive samples in single image.
"""
if not len(pos_inds):
return cls_score.new([]),
anchors_all_level = torch.cat(anchors, 0)
pos_scores = cls_score[pos_inds]
pos_bbox_pred = bbox_pred[pos_inds]
pos_label = label[pos_inds]
pos_label_weight = label_weight[pos_inds]
pos_bbox_target = bbox_target[pos_inds]
pos_bbox_weight = bbox_weight[pos_inds]
pos_anchors = anchors_all_level[pos_inds]
pos_bbox_pred = self.bbox_coder.decode(pos_anchors, pos_bbox_pred)
# to keep loss dimension
loss_cls = self.loss_cls(
pos_scores,
pos_label,
pos_label_weight,
avg_factor=1.0,
reduction_override='none')
loss_bbox = self.loss_bbox(
pos_bbox_pred,
pos_bbox_target,
pos_bbox_weight,
avg_factor=1.0, # keep same loss weight before reassign
reduction_override='none')
loss_cls = loss_cls.sum(-1)
pos_loss = loss_bbox + loss_cls
return pos_loss,然后根据计算的anchor得分,用高斯混合模型进行拟合,用本文提出的PAA方法进行二次标签分配,代码如下
def paa_reassign(self, pos_losses, label, label_weight, bbox_weight,
pos_inds, pos_gt_inds, anchors):
"""Fit loss to GMM distribution and separate positive, ignore, negative
samples again with GMM model.
Args:
pos_losses (Tensor): Losses of all positive samples in
single image.
label (Tensor): classification target of each anchor with
shape (num_anchors,)
label_weight (Tensor): Classification loss weight of each
anchor with shape (num_anchors).
bbox_weight (Tensor): Bbox weight of each anchor with shape
(num_anchors, 4).
pos_inds (Tensor): Index of all positive samples got from
first assign process.
pos_gt_inds (Tensor): Gt_index of all positive samples got
from first assign process.
anchors (list[Tensor]): Anchors of each scale.
Returns:
tuple: Usually returns a tuple containing learning targets.
- label (Tensor): classification target of each anchor after
paa assign, with shape (num_anchors,)
- label_weight (Tensor): Classification loss weight of each
anchor after paa assign, with shape (num_anchors).
- bbox_weight (Tensor): Bbox weight of each anchor with shape
(num_anchors, 4).
- num_pos (int): The number of positive samples after paa
assign.
"""
if not len(pos_inds):
return label, label_weight, bbox_weight, 0
label = label.clone()
label_weight = label_weight.clone()
bbox_weight = bbox_weight.clone()
num_gt = pos_gt_inds.max() + 1 # 2
num_level = len(anchors) # 5
num_anchors_each_level = [item.size(0) for item in anchors] # [1444, 361, 100, 25, 9]
num_anchors_each_level.insert(0, 0) # [0, 1444, 361, 100, 25, 9]
inds_level_interval = np.cumsum(num_anchors_each_level) # [0 1444 1805 1905 1930 1939]
pos_level_mask = []
for i in range(num_level):
mask = (pos_inds >= inds_level_interval[i]) & (
pos_inds < inds_level_interval[i + 1])
pos_level_mask.append(mask)
pos_inds_after_paa = [label.new_tensor([])]
ignore_inds_after_paa = [label.new_tensor([])]
for gt_ind in range(num_gt):
pos_inds_gmm = []
pos_loss_gmm = []
gt_mask = pos_gt_inds == gt_ind
for level in range(num_level):
level_mask = pos_level_mask[level]
level_gt_mask = level_mask & gt_mask
value, topk_inds = pos_losses[level_gt_mask].topk(
min(level_gt_mask.sum(), self.topk), largest=False)
pos_inds_gmm.append(pos_inds[level_gt_mask][topk_inds])
pos_loss_gmm.append(value)
pos_inds_gmm = torch.cat(pos_inds_gmm)
pos_loss_gmm = torch.cat(pos_loss_gmm) # 一共5层,每层取9个最大的pos_loss,最多45个
# fix gmm need at least two sample
if len(pos_inds_gmm) < 2:
continue
device = pos_inds_gmm.device
pos_loss_gmm, sort_inds = pos_loss_gmm.sort()
pos_inds_gmm = pos_inds_gmm[sort_inds]
pos_loss_gmm = pos_loss_gmm.view(-1, 1).cpu().numpy()
min_loss, max_loss = pos_loss_gmm.min(), pos_loss_gmm.max()
means_init = np.array([min_loss, max_loss]).reshape(2, 1)
weights_init = np.array([0.5, 0.5])
precisions_init = np.array([1.0, 1.0]).reshape(2, 1, 1) # full
if self.covariance_type == 'spherical':
precisions_init = precisions_init.reshape(2)
elif self.covariance_type == 'diag':
precisions_init = precisions_init.reshape(2, 1)
elif self.covariance_type == 'tied':
precisions_init = np.array([[1.0]])
if skm is None:
raise ImportError('Please run "pip install sklearn" '
'to install sklearn first.')
gmm = skm.GaussianMixture(
2,
weights_init=weights_init,
means_init=means_init,
precisions_init=precisions_init,
covariance_type=self.covariance_type)
gmm.fit(pos_loss_gmm)
gmm_assignment = gmm.predict(pos_loss_gmm)
scores = gmm.score_samples(pos_loss_gmm)
gmm_assignment = torch.from_numpy(gmm_assignment).to(device)
scores = torch.from_numpy(scores).to(device)
pos_inds_temp, ignore_inds_temp = self.gmm_separation_scheme(
gmm_assignment, scores, pos_inds_gmm)
pos_inds_after_paa.append(pos_inds_temp)
ignore_inds_after_paa.append(ignore_inds_temp)
pos_inds_after_paa = torch.cat(pos_inds_after_paa)
ignore_inds_after_paa = torch.cat(ignore_inds_after_paa)
reassign_mask = (pos_inds.unsqueeze(1) != pos_inds_after_paa).all(1)
reassign_ids = pos_inds[reassign_mask]
label[reassign_ids] = self.num_classes
label_weight[ignore_inds_after_paa] = 0
bbox_weight[reassign_ids] = 0
num_pos = len(pos_inds_after_paa)
return label, label_weight, bbox_weight, num_pos其中用到了第三方库sklearn import sklearn.mixture as skm。首先从FPN每层取得分最大的 \(K\) 个anchor作为候选,文中 \(K=9\)。然后用高斯混合模型进行拟合skm.GaussianMixture,接着根据边界划分正负样本,实现中用的是图(3)(c),代码如下
def gmm_separation_scheme(self, gmm_assignment, scores, pos_inds_gmm):
"""A general separation scheme for gmm model.
It separates a GMM distribution of candidate samples into three
parts, 0 1 and uncertain areas, and you can implement other
separation schemes by rewriting this function.
Args:
gmm_assignment (Tensor): The prediction of GMM which is of shape
(num_samples,). The 0/1 value indicates the distribution
that each sample comes from.
scores (Tensor): The probability of sample coming from the
fit GMM distribution. The tensor is of shape (num_samples,).
pos_inds_gmm (Tensor): All the indexes of samples which are used
to fit GMM model. The tensor is of shape (num_samples,)
Returns:
tuple[Tensor]: The indices of positive and ignored samples.
- pos_inds_temp (Tensor): Indices of positive samples.
- ignore_inds_temp (Tensor): Indices of ignore samples.
"""
# The implementation is (c) in Fig.3 in origin paper instead of (b).
# You can refer to issues such as
# https://github.com/kkhoot/PAA/issues/8 and
# https://github.com/kkhoot/PAA/issues/9.
fgs = gmm_assignment == 0
pos_inds_temp = fgs.new_tensor([], dtype=torch.long)
ignore_inds_temp = fgs.new_tensor([], dtype=torch.long)
if fgs.nonzero().numel():
_, pos_thr_ind = scores[fgs].topk(1)
pos_inds_temp = pos_inds_gmm[fgs][:pos_thr_ind + 1]
ignore_inds_temp = pos_inds_gmm.new_tensor([])
return pos_inds_temp, ignore_inds_temp注意,因为取了负对数,真实的图是将图(3)(c)沿x轴反转,因此取前pos_thr_ind个anchor作为正样本。
在重新划分了正负样本后,就可以计算损失了,分类损失Focal Loss,回归损失GIoU Loss,以及本文新加的IoU损失Cross Entropy Loss。
此外本文还提出了一种新的后处理方法score voting作用于NMS之后,代码如下
def score_voting(self, det_bboxes, det_labels, mlvl_bboxes,
mlvl_nms_scores, score_thr):
"""Implementation of score voting method works on each remaining boxes
after NMS procedure.
Args:
det_bboxes (Tensor): Remaining boxes after NMS procedure,
with shape (k, 5), each dimension means
(x1, y1, x2, y2, score).
det_labels (Tensor): The label of remaining boxes, with shape
(k, 1),Labels are 0-based.
mlvl_bboxes (Tensor): All boxes before the NMS procedure,
with shape (num_anchors,4).
mlvl_nms_scores (Tensor): The scores of all boxes which is used
in the NMS procedure, with shape (num_anchors, num_class)
score_thr (float): The score threshold of bboxes.
Returns:
tuple: Usually returns a tuple containing voting results.
- det_bboxes_voted (Tensor): Remaining boxes after
score voting procedure, with shape (k, 5), each
dimension means (x1, y1, x2, y2, score).
- det_labels_voted (Tensor): Label of remaining bboxes
after voting, with shape (num_anchors,).
"""
candidate_mask = mlvl_nms_scores > score_thr
candidate_mask_nonzeros = candidate_mask.nonzero(as_tuple=False)
candidate_inds = candidate_mask_nonzeros[:, 0]
candidate_labels = candidate_mask_nonzeros[:, 1]
candidate_bboxes = mlvl_bboxes[candidate_inds]
candidate_scores = mlvl_nms_scores[candidate_mask]
det_bboxes_voted = []
det_labels_voted = []
for cls in range(self.cls_out_channels):
candidate_cls_mask = candidate_labels == cls
if not candidate_cls_mask.any():
continue
candidate_cls_scores = candidate_scores[candidate_cls_mask]
candidate_cls_bboxes = candidate_bboxes[candidate_cls_mask]
det_cls_mask = det_labels == cls
det_cls_bboxes = det_bboxes[det_cls_mask].view(
-1, det_bboxes.size(-1))
det_candidate_ious = bbox_overlaps(det_cls_bboxes[:, :4],
candidate_cls_bboxes)
for det_ind in range(len(det_cls_bboxes)):
single_det_ious = det_candidate_ious[det_ind]
pos_ious_mask = single_det_ious > 0.01
pos_ious = single_det_ious[pos_ious_mask]
pos_bboxes = candidate_cls_bboxes[pos_ious_mask]
pos_scores = candidate_cls_scores[pos_ious_mask]
pis = (torch.exp(-(1 - pos_ious) ** 2 / 0.025) *
pos_scores)[:, None]
voted_box = torch.sum(
pis * pos_bboxes, dim=0) / torch.sum(
pis, dim=0)
voted_score = det_cls_bboxes[det_ind][-1:][None, :]
det_bboxes_voted.append(
torch.cat((voted_box[None, :], voted_score), dim=1))
det_labels_voted.append(cls)
det_bboxes_voted = torch.cat(det_bboxes_voted, dim=0)
det_labels_voted = det_labels.new_tensor(det_labels_voted)
return det_bboxes_voted, det_labels_voted