注意力(Attention)机制的数学建模_总结
导读:注意力机制在认知神经科学中有系统的介绍,所以在深度学习为代表的计算机系统中应用兴起之时就引起笔者的持续关注。笔者相信注意力建模思想及现有的建模方法一定可以在更广泛的领域中借鉴和应用,所以有必要系统学习和总结,如果你也认为如此,本文的内容对你是有帮助的,建议先订阅和收藏。
本文目录
-
- 1 引言
-
- 1.1 注意力的本质
- 1.2 注意力的分类
- 2 起源
- 3 最早的Attention机制
-
- 3.1 思路
- 3.2 总结
- 4 Attention机制的一般结构
-
- 4.1 第一阶段
- 4.2 第二阶段
- 4.3 第三阶段
- 4.4 一些可改进的方向
- 5 关于Attention的各种改进建模方法
-
- 5.1 Hard Attention 与 Soft Attention
- 5.2 Global Attention 与 Local Attention
- 5.3 Scaled Dot-Product Attention 与 Multi-Head Attention
- 6 Attention机制的应用
- 7 参考资料
1 引言
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
如下图1形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。

图1 人类视觉的注意力 (图片来自参考文献[1])
1.1 注意力的本质
由关注输入信息的全部变为选择性关注一部分,作为一种资源分配方案,将有限的信息处理能力用在更重要的信息上,是解决信息超载问题的主要手段。注意力网络在人脑的所有脑叶及很多皮质结构中普遍存在。
1.2 注意力的分类
认知神经科学中将注意力分为以下两种,这种机制处于一种动态竞争中,争夺着对注意焦点的控制:
- 目标驱动的注意力,即自上而下的,依赖于预定目的、任务,主动有意识地聚焦于输入信息中的某一对象;
- 刺激驱动的注意力,即自下而上的,不需要主动干预,任务无关,由刺激显著性引起对输入信息中某一对象的关注。
近年来在深度学习中流行的注意力机制从本质上讲是人类的选择性视觉注意力机制的模仿与简化(人类注意力机制更加复杂),核心目标也是从众多信息中选择出对当前任务目标更关键的信息,已被广泛使用在自然语言处理、图像识别及语音识别等各种不同类型的任务中并且起到了非常显著的作用。
2 起源
注意力模型/Attention Model(AM)首先是在机器翻译(原始论文:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE,2015)中引入的,为了解决如下图所示的Encoder-Decoder框架中语义编码C长度固定可能成为Encoder-Decoder框架性能瓶颈的问题,在机器翻译任务中取得SOTA效果。当前已经成为神经网络中的一个重要概念。

图2 Encoder-Decoder基础框架 (图片来自参考文献[1],自己懒得画了)
注意力机制在AI领域的建模中迅速发展的原因主要有三个:第一,现在这些模型已经成为机器翻译、问答、情感分析、词性标注、选区解析和对话系统等多项任务的最新技术;第二,除了在主要任务上提高性能之外,它们还提供了其它一些优势,比如它们被广泛用于提高神经网络的可解释性(神经网络又被认为是黑箱模型),主要是因为人们对影响人类生活的应用程序中机器学习模型的公平性、问责制和透明度越来越感兴趣;第三,它们有助于克服递归神经网络(RNN)存在的一些问题:(1)对于比较长的句子,很难用一个定长的向量 c 完全表示其意义;(2)RNN 存在长序列梯度消失的问题,只使用最后一个神经元得到的向量 c 效果不理想;(3)与人类的注意力方式不同,即人类在阅读文章的时候,会把注意力放在当前的句子上。
3 最早的Attention机制
Attention机制由ICLR2015的论文“NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE”提出用于法语-英语的机器翻译任务中作为对输入X的soft-research结构。
参考该论文附录2中关于模型的细节。
3.1 思路
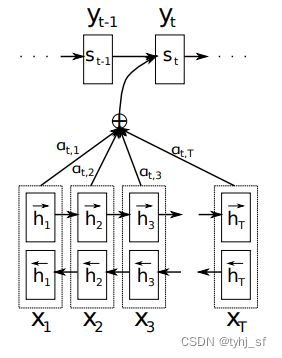
图3 生成第t个目标词 y t y_t yt的过程
Encoder使用双向RNN(BiRNN),方便捕获句子中一个词对其前置词和后置词的依赖信息。
h j → \overrightarrow{h_j} hj表示前向RNN的隐藏层状态, h j ← \overleftarrow{h_j} hj表示反向RNN的隐藏层状态; h j h_j hj状态是将两者拼接起来,即 h j = [ h j → , h j ← ] h_j=[\overrightarrow{h_j},\overleftarrow{h_j}] hj=[hj,hj]
Decoder每一时刻i的输出由三个要素决定:时刻i的隐状态 s i s_i si,attention计算得到的context向量 c i c_i ci,上一时刻i−1的输出 y i − 1 y_{i−1} yi−1,即:
p ( y i ∣ y 1 , . . . , y i − 1 , X ) = y i = g ( y i − 1 , s i , c i ) \begin{align} p(y_i|y_1,...,y_{i−1},X)=y_i=g(y_{i−1},s_i,c_i) \end{align} p(yi∣y1,...,yi−1,X)=yi=g(yi−1,si,ci)
其中 s i s_i si由三个要素决定:时刻 i − 1 i-1 i−1的隐状态 s i − 1 s_{i-1} si−1,attention计算得到的context向量 c i c_i ci,上一时刻i−1输出 y i − 1 y_{i−1} yi−1
s i = f ( s i − 1 , y i − 1 , c i ) \begin{align} s_i=f(s_{i−1},y_{i−1},c_i) \end{align} si=f(si−1,yi−1,ci)
其中 c i c_i ci由以下公式得到
c i = ∑ j = 1 T x α i j h j , α i j = exp ( e i j ) ∑ k = 1 T x exp ( e i k ) , e i j = a ( s i − 1 , h j ) \begin{align} c_i&=\sum_{j=1}^{T_x} α_{ij} h_j,\\ α_{ij}&=\frac{\exp(e_{ij})}{\sum^{T_x}_{k=1} \exp(e_{ik})},\\ e_{ij}&=a(s_{i−1},h_j) \end{align} ciαijeij=j=1∑Txαijhj,=∑k=1Txexp(eik)exp(eij),=a(si−1,hj)
其中,
c i c_i ci是输入序列全部隐状态的 h 1 , h 2 , . . . , h T h_1,h_2,...,h_T h1,h2,...,hT的加权和。
α i j α_{ij} αij代表权重参数,它并不是一个固定权重,而是由非线性函数a计算得到,该论文中作者使用一个反馈神经网络结构代表a,a作为整个神经网络结构的一部分并参与训练。
3.2 总结
- context向量 c i c_i ci通过计算输入中的每个单词的权重,加权求和得到,而不是基础Encoder-Decoder框架中的使用Encoder输出的最终隐状态 h j h_j hj。
- 权重 α i j α_{ij} αij即Decoder的上一时刻i−1隐状态 s i − 1 s_{i−1} si−1和Encoder的最终隐状态 h j h_j hj通过非线性函数(采用前馈神经网络,跟随整个网络一起训练)得到。
4 Attention机制的一般结构
把Attention机制从Encoder-Decoder框架中剥离,并进一步做抽象可以得到Attention机制更一般的结构,帮助我们看清Attention机制的本质。
我们将Source中的构成元素想象成是由一系列的
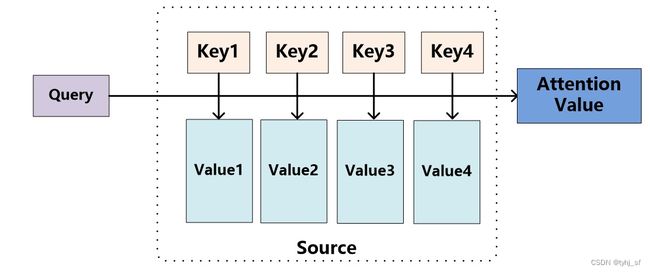
根据上述,可以将Attention一般结构写为如下三个公式:
e i j = a ( Q i , K j ) , α i j = exp ( e i j ) ∑ k = 1 T x exp ( e i k ) , A t t e n t i o n ( Q i , K , V ) = ∑ j = 1 T x α i j ∗ V j \begin{align} e_{ij}&=a(Q_i,K_j), \\ α_{ij}&=\frac{\exp(e_{ij})}{\sum^{T_x}_{k=1} \exp(e_{ik})},\\ Attention(Q_i, K, V) &= \sum_{j=1}^{T_x} α_{ij}*V_j \end{align} eijαijAttention(Qi,K,V)=a(Qi,Kj),=∑k=1Txexp(eik)exp(eij),=j=1∑Txαij∗Vj
其中,
Q i , K j , V j Q_i, K_j, V_j Qi,Kj,Vj均为向量;
Q i Q_i Qi为Target中第i个输出元素对应的Query值;
K为Source中所有元素的Key, K j K_j Kj为Source中第j个构成元素的Key值;
V为Source中所有元素的Value, V j V_j Vj为Source中第j个构成元素的 K j K_j Kj值对应的Value值;
T x T_x Tx为Source的长度;
α \alpha α为Q和某个 K j K_j Kj的相关性(或相似性)计算函数。
公式6-8也对应着Attention计算的三个阶段。
4.1 第一阶段
即公式6,根据Target中第i个输出元素对应的Query值 Q i Q_i Qi和某个 K j K_j Kj,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量余弦相似性或者通过再引入额外的神经网络来求值,即如下方式:
- 向量加性: e i j = β t a n h ( W T Q i + U T K j ) e_{ij}=\beta tanh(W^TQ_i + U^TK_j) eij=βtanh(WTQi+UTKj), 其中 β , W T , U T \beta,W^T,U^T β,WT,UT为可学习参数;
- 向量空间线性变换: e i j = Q i T W K j e_{ij}=Q^T_i W K_j eij=QiTWKj, 其中 W W W为可学习参数用于向量空间变换以解决 Q i , K j Q_i,K_j Qi,Kj向量空间不一致的场景;
- 向量点积: e i j = Q i ⋅ K j e_{ij}=Q_i \cdot K_j eij=Qi⋅Kj;
- 缩放向量点积: e i j = Q i ⋅ K j d x e_{ij}=\frac{Q_i \cdot K_j}{\sqrt{\smash[b]{d_x}}} eij=dxQi⋅Kj, 其中 d x d_x dx为输入Source元素的维度,使用 d x d_x dx进行缩放是为了远离下述第二阶段softmax函数的饱和区,获取更大的梯度;
- 余弦相似性: e i j = Q i ⋅ K j ∣ ∣ Q i ∣ ∣ ∣ ∣ K j ∣ ∣ e_{ij}=\frac{Q_i \cdot K_j}{||Q_i||\ ||K_j||} eij=∣∣Qi∣∣ ∣∣Kj∣∣Qi⋅Kj;
- MLP神经网络: e i j = MLP ( Q i , K j ) e_{ij}=\text{MLP}(Q_i,K_j) eij=MLP(Qi,Kj);
4.2 第二阶段
即公式7,由于第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入值缩放计算函数,比如常选用SoftMax的计算方式对第一阶段的得分进行数值转换,用途有二个:(1)可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布,加快神经网络训练的收敛速度;(2)SoftMax具有放大差异的作用,可以更加突出重要元素的权重。
第二阶段的计算结果 α i j α_{ij} αij 即为 V j V_j Vj对应的权重系数。
4.3 第三阶段
即公式8,这里需要注意的是,公式8计算的是Target中第i个输出元素对应的Query值 Q i Q_i Qi。Target是多个元素的序列,因此每一个Target输出元素都要计算一次公式8,产生出对应的注意力向量。
目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
套用公式6-8可得知,在3.1节的机器翻译文论文中,Source的 K j K_j Kj和 V j V_j Vj值均为同一个向量,即输入句子中每个单词对应输出的隐变量 h j h_j hj。
4.4 一些可改进的方向
- 计算复杂度高,Target中每个 Q i Q_i Qi都要与Source中的 T x T_x Tx个元素 K j K_j Kj计算相关性。可以经过某种机制筛选,只用部分元素 K j K_j Kj参与相关性计算?
- 第一阶段计算相关性得分值的计算方法可以根据实际任务特点设计成多种多样的。
- 第二阶段输出的权重系数是(0, 1)范围内的值,也许可以设置一个阈值控制进入注意力范围内的 V j V_j Vj值,只有满足阈值条件的 V j V_j Vj值才参与计算注意力值?
- Q,K,V向量的来源和更新也应该是能够优化?
- 如果Q也来自Source,即Target=Source, 这就是经典的自注意力(Self-Attention)?
围绕以上可改进点,目前已有较多论文提出了各种改进Attention模型。
5 关于Attention的各种改进建模方法
5.1 Hard Attention 与 Soft Attention
由论文《Show, Attend and Tell: Neural Image Caption Generation withVisual Attention》,2015 提出。
Soft Atttention是参数化的,是可导的可嵌入到模型中直接训练,上述最早提出的Attention即是Soft Attention;Hard Attention是一个随机的过程,为了实现梯度的反向传播,需要采用蒙特卡洛采样的方法来估计模块的梯度,目前更多的研究和应用还是更倾向于使用Soft Attention,因为其可以直接求导,进行梯度反向传播。
5.2 Global Attention 与 Local Attention
由论文《Effective Approaches to Attention-based Neural Machine Translation》, 2015 提出。
 左图是Global Attention,右图是Local Attention
左图是Global Attention,右图是Local Attention
Global Attention在计算上下文向量 c t c_t ct时考虑Encoder所有的隐层状态,Attention向量是通过比较当前目标隐藏状态 h t h_t ht和每个源隐藏状态 h s h_s hs得到。
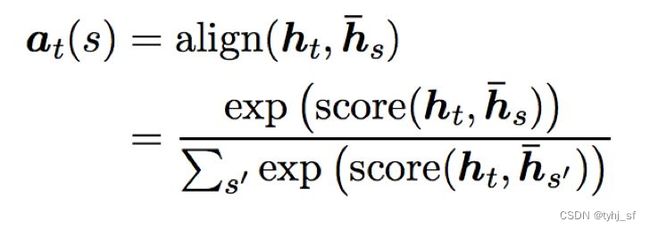
h t h_t ht和 h s h_s hs之间的计算方式可以采用如下几种:

Local Attention的思想是对每个目标单词只选择一部分源单词进行预测上下文向量 c t c_t ct,具体来说,在时刻t 模型首先为每个目标单词生成一个对齐位置 p t p_t pt。上下文向量 c t c_t ct 通过窗口 [ p t − D , p t + D ] [p_t -D,p_t +D] [pt−D,pt+D]内的源隐藏状态集合加权平均计算得到,D 根据经验选择。与Global Attention不同,局部对齐向量 a t a_t at是固定维度的,即 a t ∈ R 2 D + 1 a_t∈ℝ^{2D+1} at∈R2D+1,比Global Attention的计算量更小。
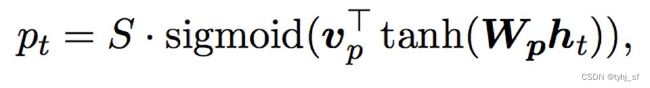
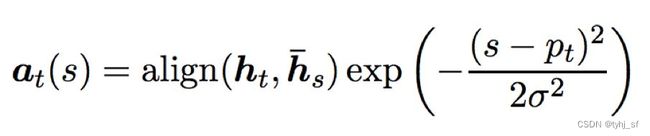
5.3 Scaled Dot-Product Attention 与 Multi-Head Attention
由Transformer经典论文《Attention is all you need》,2017 提出。这里我们只简述Attention的设计,该论文提出的Transformer模型结构及其后续改进型已在CV、NLP等领域大放异彩,后续会单独开一篇博文进行全面地剖析和总结。
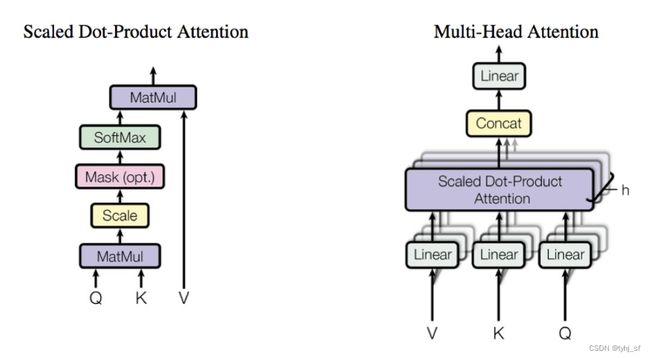 ScaledDot-Product Attention:通过Q,K矩阵计算矩阵V的权重系数。
ScaledDot-Product Attention:通过Q,K矩阵计算矩阵V的权重系数。
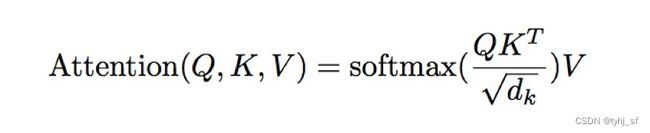
Multi-Head Attention:多头注意力是将Q,K,V通过一个线性映射成h个Q,K,V,然后每个都计算Scaled Dot-Product Attention,最后再合起来,Multi-Head Attention目的还是对特征进行更全面的抽取。
6 Attention机制的应用
Attention机制在深度学习的各种应用领域都有广泛的使用场景。
- 机器翻译任务,前文有介绍,不赘述;
- 图像到文本的生成任务,即输入一张图片,人工智能系统输出一句描述句子,语义等价地描述图片所示内容。加入Attention机制能够明显改善系统输出效果,Attention模型在这里起到了类似人类视觉选择性注意的机制,在输出某个实体单词的时候会将注意力焦点聚焦在图片中相应的区域上。
- 语言识别任务,目标是将语音流信号转换成文字,所以也是Encoder-Decoder的典型应用场景。Encoder部分的Source输入是语音流信号,Decoder部分输出语音对应的字符串流,加入Attention机制后可将将输出字符和输入语音信号进行对齐。
7 参考资料
[1] 深度学习中的注意力机制, 张俊林, 2015.
[2] Neural Turing Machines, Google DeepMind, 2014.
[3] Attention is all you need, Google Brain&Research, 2017.
[4] https://cloud.tencent.com/developer/article/1480510#:~:text=Attentio,ttention