一、背景
近期版本上线后收到不少用户反馈(大多是华为用户)崩溃,日志上总体表现为 pthread_create (1040KB stack) failed: XXX。
java.lang.OutOfMemoryError
pthread_create (1040KB stack) failed: Out of memory
1 java.lang.Thread.nativeCreate(Native Method)
2 java.lang.Thread.start(Thread.java:743)
3 java.util.concurrent.ThreadPoolExecutor.addWorker(ThreadPoolExecutor.java:941)
4 java.util.concurrent.ThreadPoolExecutor.processWorkerExit(ThreadPoolExecutor.java:1009)
5 java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1151)
6 java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:607)
7 java.lang.Thread.run(Thread.java:774)
java.lang.OutOfMemoryError
pthread_create (1040KB stack) failed: Try again
1 java.lang.Thread.nativeCreate(Native Method)
2 java.lang.Thread.start(Thread.java:733)
3 java.util.concurrent.ThreadPoolExecutor.addWorker(ThreadPoolExecutor.java:975)
4 java.util.concurrent.ThreadPoolExecutor.processWorkerExit(ThreadPoolExecutor.java:1043)
5 java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1185)
6 java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641)
7 java.lang.Thread.run(Thread.java:764)
二、问题分析
2.1 初步推断
Android的内存管理策略
OOM 并不等于 RAM 不足,这和 Android 的内存管理策略有关。
我们知道,内存分为虚拟地址和物理地址。通过 malloc 或 new 分配的内存都是虚拟地址空间的内存。虚拟地址空间比物理的地址空间要大的多。在较多进程同时运行时,物理地址空间有可能不够,这该怎么办?
Linux 采用的是 “进程内存最大化” 的分配策略,用 Swap 机制来保证物理内存不被消耗殆尽,把最近最少使用的空间腾到外部存储空间上,假装还是存储在 RAM 里。
虽然 Android 基于 Linux,但是在内存策略上有自己的套路 —— 没有交换区。
Android 的进程分配策略是每个进程都有一个内存占用限制,这个具体大小由手机具体配置决定。目的就是为了让更多的进程都保留在 RAM 中,这样每个进程被唤起的时候可以避免外部存储到内部存储的数据读写的消耗,加快更多的 App 恢复的响应速度,也避免了流氓 App 抢占所有内存。随之而然,Android 采用了自己的 LowMemoryKill 策略来控制RAM中的进程。如果 RAM 真的不足,MemoryKiller 就会杀死一些优先级比较低的进程来释放物理内存。
所以触发OOM,只可能是使用的虚拟内存地址空间超过分配的阈值。
那 Android 为每个应用分配多少内存呢?这个因手机而异,以手头的测试机举例,系统正常分配的内存最多为 192 M;当设置 largeHeap 时,最多可申请 512M。
2.2 代码分析
那这个溢出是怎么被系统抛出的?通过 Android 源码可以看到,是由 runtime/thread.cc内抛出的异常。
void Thread::CreateNativeThread(JNIEnv* env, jobject java_peer, size_t stack_size, bool is_daemon)
线程创建有以下两个关键的步骤:
- 第一列中的创建线程私有的结构体JNIENV(JNI执行环境,用于C层调用Java层代码)
- 第二列中的调用posix C库的函数pthread_create进行线程创建工作
而这两步均有可能抛出OOM,基本定位 —— 创建线程导致了OOM。
Android 创建线程源码与OOM分析
该文分析了创建线程的原理,其实就是调用mmap分配栈内存(虚拟内存),再通过 Linux 的 mmap 调用映射到用户态虚拟内存地址空间。创建线程过程中发生OOM是因为进程内的虚拟内存地址空间耗尽了。
那什么时候会虚拟内存地址空间不足呢 ?
方向一:fd 过多
Linux 系统中一切皆文件,网络是文件,打开文件、新建 tcp 连接也是文件,都会占用 fd。fd是一种资源,是资源就会有限制。每个进程最大打开文件的数目有一个上限。
而fd的增加的时机有:
- 创建socket网络连接
- 打开文件
- 创建HandlerThread
- 创建NIO的Channel(读写各占用一个fd)
- 通过命令:ls -l /proc/
/fd/ 来查看某个进程打开了哪些文件 cat /proc/命令查看进程的fd限制,或其它限制 如Max open files/limits lsof -p查看进程所有的fd总数|wc -l
如上图,Max open files表示每个进程最大打开文件的数目,进程每打开一个文件就会产生一个文件描述符fd(记录在/proc/pid/fd中)
验证也很简单,通过触发大量的网络连接或者文件打开,每打开一个 socket 都会增加一个 fd。
private Runnable increaseFDRunnable = new Runnable() {
@Override
public void run() {
try {
for (int i = 0; i < 1000; i++) {
new BufferedReader(new FileReader("/proc/" + Process.myPid() + "/status"));
}
Thread.sleep(Long.MAX_VALUE);
} catch (InterruptedException e) {
//
} catch (FileNotFoundException e) {
//
}
}
};
方向二:线程过多
已用逻辑空间地址可以查看 /proc/
/status 中的 VmPeak / VmSize
无非两个原因:
1、进程的栈内存超过了虚拟机的最大内存数;
2、线程数达到了系统最大限制数;
排查工具
profilter CPU 查看当前所有线程列表
使用CPU分析器监视CPU使用情况和线程活动使用太重了?无法分类统计?可以使用 adb shell ps -T -p
,还可以使用 | grep xxx 过滤,使用 wc -l来统计线程数量。-
直接dump进程内存,来查看内存情况:
adb shell dumpsys meminfo [pacakgename] -
也可以查看线程等汇总数据:
adb shell cat /proc/19468/status
Linux在 /proc/sys/kernel/threads-max 中有描述线程限制,可以通过命令cat /proc/sys/kernel/threads-max 查看,华为在线程限制上非常严苛,在 7.0+ 手机上已将最大线程数修改成了 500。
那么是哪里代码导致了线程爆发呢?我们使用 watch每1s打印一下当前的线程数再通过页面交互来定位问题,观察看看哪类的线程名字在增多。
watch -n 1 -d 'adb shell ps -T | grep XXX | wc -l'
观察后发现,线程总数在进入直播间时,轻而易举就达到了 290多,而且有大量 RxCachedThreadSchedule 线程(也就是 Rx 的Scheduler.io调度器)被创建,IO线程数暴涨到 46。停留在直播间一段时间,线程数只增不减,并不会过期清理。
2.3 验证推断,定位原因
写个demo来验证,用 Kotlin 协程和 RxJava IO 调度器,模拟密集并发IO的环境
for (i in 0..100) {
GlobalScope.launch(Dispatchers.IO) {
delay(100)
Log.e("IOExecute", "协程 - 当前线程:"
+ Thread.currentThread().name)
}
}
for (i in 0..100) {
ThreadExecutor.IO.execute {
Thread.sleep(100)
Log.e("IOExecute", "RxJava IO - 当前线程:"
+ Thread.currentThread().name)
}
}
看起来 IO 线程没有复用,有点奇怪,我们知道 Rx 的调度器其实就是封装的线程池,我们也早已对线程池的流程滚瓜烂熟。如下图:
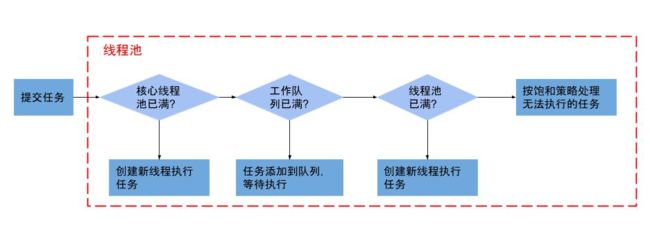
难道是工作队列满了?难道是线程无上限?难道是饱和策略有问题?
疑点
初进直播间,密集IO,没有复用,线程突增
停留超过 keepAliveTime,IO线程没有销毁
源码探寻
那到底哪里出了问题呢?本着挖掘机专业毕业的精神,我们来看看Scheduler.io的源码定位原因,看源码前,我们先提出疑问和设想,带着问题看源码才不容易迷失方向:
疑问
- 工作队列是怎么管理的,容量多大?
- 线程池策略是什么?什么时候新建线程?什么时候销毁?
我们先来看看 RxJava 线程模型图,理清楚类之间的关系:Scheduler 是 RxJava 的线程任务调度器,Worker 是线程任务的具体执行者。不同的Scheduler类会有不同的Worker实现,因为Scheduler类最终是交到Worker中去执行调度的。
可以看到,Schedulers.io()中使用了静态内部类的方式来创建出了一个单例IoScheduler对象出来,这个IoScheduler是继承自Scheduler的。
@NonNull
static final Scheduler IO;
@NonNull
public static Scheduler io() {
//1.直接返回一个名为IO的Scheduler对象
return RxJavaPlugins.onIoScheduler(IO);
}
static {
//省略无关代码
//2.IO对象是在静态代码块中实例化的,这里会创建按一个IOTask()
IO = RxJavaPlugins.initIoScheduler(new IOTask());
}
static final class IOTask implements Callable {
@Override
public Scheduler call() throws Exception {
//3.IOTask中会返回一个IoHolder对象
return IoHolder.DEFAULT;
}
}
static final class IoHolder {
//4.IoHolder中会就是new一个IoScheduler对象出来
static final Scheduler DEFAULT = new IoScheduler();
}
IoScheduler 的父类 Scheduler 在 scheduleDirect()、schedulePeriodicallyDirect() 方法中创建了 Worker,然后会分别调用 worker 的 schedule()、schedulePeriodically() 来执行任务。
public abstract class Scheduler {
//检索或创建一个代表操作串行执行的新{@link Scheduler.Worker}。工作完成后,应使用{@link Scheduler.Worker#dispose()}取消订阅。 return一个Worker,它代表要执行的一系列动作。
@NonNull
public abstract Worker createWorker();
@NonNull
public Disposable scheduleDirect(@NonNull Runnable run, long delay, @NonNull TimeUnit unit) {
final Worker w = createWorker();
final Runnable decoratedRun = RxJavaPlugins.onSchedule(run);
DisposeTask task = new DisposeTask(decoratedRun, w);
w.schedule(task, delay, unit);
return task;
}
@NonNull
public Disposable schedulePeriodicallyDirect(@NonNull Runnable run, long initialDelay, long period, @NonNull TimeUnit unit) {
final Worker w = createWorker();
//省略无关代码
Disposable d = w.schedulePeriodically(periodicTask, initialDelay, period, unit);
//省略无关代码
}
}
前面我们说到,不同的Scheduler类会有不同的Worker实现,我们看看 IoScheduler 这个实现类对应的 Worker 是什么:
final AtomicReference pool;
public Worker createWorker() {
//就是new一个EventLoopWorker,传一个 CachedWorkerPool 对象(Worker缓存池)
return new EventLoopWorker(pool.get());
}
static final class EventLoopWorker extends Scheduler.Worker {
private final CompositeDisposable tasks;
private final CachedWorkerPool pool;
private final ThreadWorker threadWorker;
final AtomicBoolean once = new AtomicBoolean();
//构造方法
EventLoopWorker(CachedWorkerPool pool) {
this.pool = pool;
this.tasks = new CompositeDisposable();
//从缓存Worker池中取一个Worker出来
this.threadWorker = pool.get();
}
@NonNull
@Override
public Disposable schedule(@NonNull Runnable action, long delayTime, @NonNull TimeUnit unit) {
//省略无关代码
//Runnable交给threadWorker去执行
return threadWorker.scheduleActual(action, delayTime, unit, tasks);
}
}
接下来是Worker缓存池的操作:
CachedWorkerPool的get()
static final class CachedWorkerPool implements Runnable {
ThreadWorker get() {
if (allWorkers.isDisposed()) {
return SHUTDOWN_THREAD_WORKER;
}
while (!expiringWorkerQueue.isEmpty()) {
//如果缓冲池不为空,就从缓冲池中取threadWorker
ThreadWorker threadWorker = expiringWorkerQueue.poll();
if (threadWorker != null) {
return threadWorker;
}
}
//如果缓冲池中为空,就创建一个并返回。
ThreadWorker w = new ThreadWorker(threadFactory);
allWorkers.add(w);
return w;
}
}
那ThreadWorker到底做了什么呢?追进去父类NewThreadWorker:
NewThreadWorker 的构造函数
public class NewThreadWorker extends Scheduler.Worker implements Disposable {
private final ScheduledExecutorService executor;
volatile boolean disposed;
public NewThreadWorker(ThreadFactory threadFactory) {
//构造方法中创建一个ScheduledExecutorService对象,可以通过ScheduledExecutorService来使用线程池
executor = SchedulerPoolFactory.create(threadFactory);
}
}
SchedulerPoolFactory.create
public final class SchedulerPoolFactory {
/**
* Creates a ScheduledExecutorService with the given factory.
* @param factory the thread factory
* @return the ScheduledExecutorService
*/
public static ScheduledExecutorService create(ThreadFactory factory) {
// 此处创建了线程!!
final ScheduledExecutorService exec = Executors.newScheduledThreadPool(1, factory);
if (PURGE_ENABLED && exec instanceof ScheduledThreadPoolExecutor) {
ScheduledThreadPoolExecutor e = (ScheduledThreadPoolExecutor) exec;
POOLS.put(e, exec);
}
return exec;
}
}
所以,IoScheduler 使用 CachedWorkerPool 作为线程池,其内部维护了一个阻塞队列,用于记录所有可用线程,当有新的任务需求时,线程池会查询阻塞队列中是否有可用线程,没有的话就新建一个。
我们想要知道为什么线程突增没有复用,就要看看所有使用过的那些空闲线程什么时机会被回收到阻塞队列中去。
CachedWorkerPool 的 release()
void release(ThreadWorker threadWorker) {
// Refresh expire time before putting worker back in pool
// 刷新线程的到期时间 将执行完毕的 Worker 放入缓存池中
threadWorker.setExpirationTime(now() + keepAliveTime);
expiringWorkerQueue.offer(threadWorker);
}
调用此处代码只有一处:
@Override
public void dispose() {
if (once.compareAndSet(false, true)) {
tasks.dispose();
pool.release(threadWorker);
}
}
对于这一处的调用,可以简单理解为线程内部维护了一个状态列表,当线程内的任务完成之后,会调用 dispose 来解除订阅,释放线程的占用。
那什么时候销毁呢?可以看到 CachedWorkerPool 构造函数中创建了清理定时任务:
static final class CachedWorkerPool implements Runnable {
CachedWorkerPool(long keepAliveTime, TimeUnit unit, ThreadFactory threadFactory) {
//...
// 创建一个线程,该线程默认会每60s执行一次,来清除已到期的线程
evictor = Executors.newScheduledThreadPool(1, EVICTOR_THREAD_FACTORY);
// 设置定时任务
task = evictor.scheduleWithFixedDelay(this, this.keepAliveTime, this.keepAliveTime, TimeUnit.NANOSECONDS);
//...
}
@Override
public void run() {
evictExpiredWorkers();
}
}
CachedWorkerPool 的 evictExpiredWorkers()
void evictExpiredWorkers() {
if (!expiringWorkerQueue.isEmpty()) {
long currentTimestamp = now();
for (ThreadWorker threadWorker : expiringWorkerQueue) {
if (threadWorker.getExpirationTime() <= currentTimestamp) {
if (expiringWorkerQueue.remove(threadWorker)) {
allWorkers.remove(threadWorker);
}
} else {
// 队列是根据失效时间排序的,所以一旦当我们找到未失效的Worker就可以停止清理了
break;
}
}
}
}
这个IO调度器不像计算调度器,计算调度器用一个数组来保存一组线程,然后根据索引将任务分配给每个线程,多余的任务放在队列中等待执行,所以每个线程后面任务的执行需要等待前面的任务执行完毕。
而IO调度器里的线程池是一个可以自增、无上限的线程池,且60s 保活。也就是说:如果在 60s 内密集请求 IO 调度,超过了复用阈值,调度器不会约束线程数且会不断开新线程。
这样子就解释了疑点 1 为什么进直播间时线程暴涨,是因为没有任务队列,直接来一个任务,能复用就复用 Worker,不能就新建。
那疑点 2 呢?为什么停留超过了 60s 突涨的线程没有被回收?
我们推测:
清理线程是否在正常工作?
有没有可能存在订阅泄露?有的地方 Observable 没有及时结束,所以一直占用着线程呢?
斋看源码无法模拟真实生产环境,那如何在无法改动源码的情况下,做动态观察?
3种方式:
- 动态hook
- 静态插桩
- 非阻塞式断点,打 log
观察点整理
任务的入口 —— 到底有多频繁,谁在提交任务?
工作的逻辑 —— 这个任务被分配了哪个线程?
复用的逻辑 —— 满的时候触发 new Thread,此时复用的情况怎么样,为什么会新建这么多?
释放的逻辑 —— 解除订阅和订阅数量的比对,是否存在订阅泄漏?
过期清除的逻辑 —— 清理线程是否在正常工作?每个线程都在做什么,为什么停留在直播间没有被销毁掉
好,具体观察结果的log就不贴了,因为斋看日志体验很差,我画了一张图总结下整个流程:
看出什么问题了吗?
在直播间内一直停留,超过 keepAliveTime,之所以没有清理线程,是因为线程都没过期,没错,前面的 46 个 IO 线程都没有过期,IoScheduler 使用 ConcurrentLinkedQueue 维护使用完毕的Worker,按插入顺序(也就是释放顺序)排序,所以会优先使用最早过期的 Worker 提供给新任务。
我们来算一下,算 2s 一个轮询,直播间只有 1 个轮询协议(实际上不止), 那 60s 已经足够让 30 个 Work 更新一遍过期时间了,n 个轮询可以更新 60 / 2 * n 个 worker 的过期时间。
果然源码面前,了无秘密。
结论
直播间这种业务场景的特点:进房时,短期内大量任务要并行;存在多轮询;
RxJava 的 IO 调度策略,并不适合用于并发多 IO + 轮询的情况,没有任务排队队列、线程可自增、无上限、优先使用快过期的线程;
另外,业务中存在 Rx 不合理使用(前面我们拦截了入口,所以可以直观看到哪里在使用 IO 调度),如 timer 、打点、jsBridge 都使用了 IO 调度,嵌套调度(重复 new 了 Worker 任务),没有跟随生命周期取消订阅等等等等。
三、解决
找到问题的根源,问题便已经解决了一半,基本 3 个解决方向:
优化不合理的调度器创建释放
-
线程收敛,不是阻塞就一定要用 IO 调度
其实 IO 没必要使用多线程,改为 IO 多路复用或者协程更合理。
减少并发IO,分块加载
四、思考
4.1 如何快速分类并定位线程?如何拿到NativeThread?
用前面的方式去分析,有几个缺点:
- 因为前面我们拿到堆栈是用了断点 log 的方式,所以我们拿不到没有通过指定方法创建的任务信息;
- 我们没法约束开发小伙伴和三方 SDK 为每个线程起自定义名称,无法快速分类线程,例如 thread-1,我们就很难定位到是哪个类发起的调用;
- 我们只能拿到 Java 层与其对接的 native 层 thread 总数,拿不到没有 attach 到 java 层的 native thread,也就是直接在 native 层创建的线程,比如 Futter engine 中的native thread。
有什么骚操作呢?
-
ASM字节码修改
思路很简单,你既然要创建线程,就肯定是通过以下几种方式:
-
Thread及其子类 -
TheadPoolExecutor及其子类、Executors、ThreadFactory实现类 AsyncTask-
Timer及其子类
滴滴团队开源库booster就是这么个思路 —— 利用ASM对字节码修改,将所有创建线程的指令在编译期间替换成自定义的方法调用,为线程名加上调用者的类名前缀,实现了追踪线程创建来源。
除了支持线程重命名,还可以把Executors 的方法调用替换成 ShadowExecutors 中对应的优化方法,达到全局暴力收敛的效果。
和这篇文章的思路有异曲同工之处 —— 直接把线程池的总数给定义死,相当于在水龙头给你卡一道,详细见 Thread也会OOM吗?
咕咚团队的线程监控工具也是这么干的
备注:如果采用 booster ,尽量多做一些测试和降级方案。例如:ShadowExecutors.newOptimizedFixedThreadPool方法中使用了 LinkedBlockingQueue 队列,没有指定队列大小,默认为 Integer.MAX_VALUE,无界的LinkedBlockingQueue 作为阻塞队列,当任务耗时较长时可能会导致大量新任务在队列中堆积, CPU 和内存飙升,最终导致 OOM。
-
NativeHook
那问题来了,ASM字节码修改,只 hook 到了 Java 层与其对接的 native 层 thread ,怎么拿到直接在 native 层创建的线程呢?诶,我们前面不是看了线程创建的 C++ 代码吗?基本思路就是找到 pthread_create 相关的函数,拦截它。
第一步:寻找Hook点
这需要对线程的启动流程有一定的了解,可以参考这篇文章Android线程的创建过程
java_lang_Thread.cc:Thread_nativeCreate
static void Thread_nativeCreate(JNIEnv* env, jclass, jobject java_thread, jlong stack_size, jboolean daemon) {
Thread::CreateNativeThread(env, java_thread, stack_size, daemon == JNI_TRUE);
}
thread.cc 中的CreateNativeThread函数
void Thread::CreateNativeThread(JNIEnv* env, jobject java_peer, size_t stack_size, bool is_daemon) {
...
pthread_create_result = pthread_create(&new_pthread,
&attr,
Thread::CreateCallback,
child_thread);
...
}
第二步:查找Hook的So
上面Thread_nativeCreate、CreateNativeThread和pthread_create函数分别编译在哪个 library 中呢?
很简单,我们看看编译脚本Android.bp就知道了。
art_cc_library {
name: "libart",
defaults: ["libart_defaults"],
}
cc_defaults {
name: "libart_defaults",
defaults: ["art_defaults"],
host_supported: true,
srcs: [
thread.cc",
]
}
可以看到是在"libart.so"中。
第三步:查找Hook函数的符号
C++ 的函数名会 Name Mangling,我们需要看看导出符号。
readelf -a libart.so
pthread_create函数的确是在libc.so中,而且因为c编译的不需要deMangling
001048a0 0007fc16 R_ARM_JUMP_SLOT 00000000 pthread_create@LIBC
第四步:实现
考虑到性能问题,我们只 hook 指定的so。
hook_plt_method("libart.so", "pthread_create", (hook_func) &pthread_create_hook);
如果你想监控其他so库的 pthread_create,可以自己加上。Facebook 的 profilo 中有一种做法是把目前已经加载的所有so都统一hook了。
至于 pthread_create 的参数直接查看pthread.h就可以了。
int pthread_create(pthread_t* __pthread_ptr, pthread_attr_t const* __attr, void* (*__start_routine)(void*), void*);
获取堆栈就是在 native 反射 Java 的方法
jstring java_stack = static_cast(jniEnv->CallStaticObjectMethod(kJavaClass, kMethodGetStack));
Profilo :Facebook 的性能分析工具,黑科技很多
epic:该库已经支持拦截
Thread类以及Thread类所有子类的run方法,更进一步,我们可以结合 Systrace 等工具,来生成整个过程的执行流程图。注:对于 app 上的 hook,不要再像以前那样去依赖反射、动态代理了,关注下 lancet、epic,真的是为所欲为。
4.2 排查痛点
非常可惜的是没能保留一手现场,只能靠猜,靠复现。
卡顿、崩溃都需要“现场信息”。因为 bug 产生也是依赖很多因素,比如用户的系统版本、CPU 负载、网络环境、应用数据、线程数、利用率、崩溃发生时所有的线程栈,而不只是崩溃的线程栈……
脱离这个现场,我们本地难以复现,也就很难去解决问题。那我们应该如何去监控线上,并且保留足够多的现场信息协助我们排查解决问题呢?
这里要么我们可以自己研发一套崩溃收集系统,要么可以接入现有的方案
- https://get.fabric.io
- koom
4.3 异步的本质?协程、NIO、fiber、loom 解决了什么?
回到本质上,思考下,为什么我们需要多线程?多线程真的有必要吗?
因为顺序代码结构是阻塞式的,每一行代码的执行都会使线程阻塞在那里,也就决定了所有的耗时操作不能在主线程中执行,所以就需要多线程来执行。
所以目的是非阻塞,方式是异步。
但许多异步库被引入,根本原因是当前线程实现的不足,而并非说明异步的代码更好。我们不要理所当然觉得,异步就是正常不过的事情。实际上是 Java 的设计问题,让我们一直默默忍受到现在,异步带来的一系列问题:回调地狱、不方便调试分析……
长期以来,Java 的线程是与操作系统的线程一一对应的,这种模式直接限制了 Java 平台并发能力的提升:任务阻塞意味着线程阻塞,线程状态切换又带来开销,阻塞线程对系统资源的浪费…… 从 Quasar 项目、Alibaba JDK 的协程特性,到 Kotlin 协程和 OpenJDK 的 Project Loom, Java 社区已经越来越多地认识到:目前 Java 的线程模型越来越难以满足整个行业对高并发应用开发的需求。
解决方式很多,其中一个流派 —— 语言层:
其中的代表 —— 协程,虽然在不同语言中,协程的实现方法各有不同,但本质是一致的,是一种任务封装的思想:调度任务代替了调度线程,从而减少线程阻塞,用尽量少的线程执行尽量多的任务。
比如 Kotlin 协程,因为 Kotlin 的运行依赖于 JVM,因此没办法在底层支持协程。同时,Kotlin 是一门编程语言,需要在语言层面支持协程,而不是像框架那样在语言层面之上支持。因此,Kotlin-JVM 协程最核心的部分是在编译器中,基于各种 Callback 技术达到看起来像同步代码的效果,本质上还是异步,调用各种阻塞 API 还是无解,比如 synchronized、 Native 方法中线程挂起,该阻塞线程还是会阻塞。
为了使 Java 并发能力在更大范围上得到提升,从底层进行改进便是必然。这就是 Project Loom 项目发起的原因,也就是另外一个流派 —— JVM 层。
[译]loom项目提案
代表项目是 Project Loom 和 AJDK(Alibaba JDK),从 Erlang 和 Go 语言中得到了启发,从 JVM 层面着手,把之前阻塞线程的,统统改为阻塞“纤程(fiber)”、“轻量级线程”或者“虚拟线程”,这么做的优点是更能彻底解决问题,不需要靠 async / await 这种语法糖了,在JVM 和类库层面做支持,能使整个 JVM 生态上的其他语言都收益。
但缺点或者说难点同样明显,那就是如何与现有的代码兼容,这个改造,意味着很多 native 方法也要改,大概要等到 JDK20 才能出预览版本吧,再看看我们 Android 现在仅支持到 Java8,emmm,还是早日使用 Kotlin 吧。
如果后面 JVM 开发团队完成这个项目,看看 Kotlin coroutine 对此会有什么反应,需要怎么调整,在最好的情况下,Kotlin coroutine 将来只是简单映射到 “纤程” 上。其实蛮有意思的,社区上关于异步的讨论,还有对Java、JVM的设计反思。感兴趣的小伙伴可以去研究研究。
参考:
- 不可思议的OOM
- android java process stack OOM
- 【Android】OOM问题分析
- booster线程池优化
- 一次线程OOM排查看线程使用注意事项
- Probe:Android线上OOM问题定位组件
我是 FeelsChaotic,一个写得了代码 p 得了图,剪得了视频画得了画的程序媛,致力于追求代码优雅、架构设计和T 型成长。
欢迎关注 FeelsChaotic 的和掘金,如果我的文章对你哪怕有一点点帮助,欢迎 ❤️! 你的鼓励是我写作的最大动力!
最最重要的,请给出你的建议或意见,有错误请多多指正!