二叉搜索树与Mysql索引的亲密关系
欢迎关注公众号:【离心计划】,一起逃离技术舒适圈
二叉搜索树
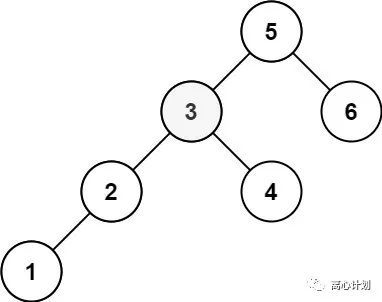
二叉搜索树大家应该多多少少听过,它有一个很重要的特征,就是父节点左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的值,这个特征引出来的重要信息就是,它的中序遍历是有序的!有序的特征在搜索查询里面可太重要了,为此我特地找了一道leetcode让大家感受一下:
https://leetcode.cn/problems/kth-smallest-element-in-a-bst/
大家可以动手做一下,由于其特性,我们寻找第k小只需要在中序遍历递归的位置记录一个索引表示第几大就行了,当这个索引值和题目给出的k相等时就是我们要的答案,我这边直接给出答案,读者可以自行理解一下,做完后可以思考下,如果题目是第k大又要怎么变动呢?
class Solution {
int res;
int k;
public int kthSmallest(TreeNode root, int k) {
this.k = k;
reverse(root);
return res;
}
int index = 0;
private void reverse(TreeNode root){
if(root==null){
return;
}
reverse(root.left);
this.index++;
if(this.index==this.k){
this.res = root.val;
return;
}
reverse(root.right);
}
}二叉搜索树提供了O(logn)的查询和写入效率,但是如果仅仅是内存查找,完全可以容忍,但是数据库往往将数据存入磁盘,如果是O(logN)的查询,那么意味着就需要logN次磁盘IO,这对数据库来说无疑是失败的查询模型,因此在二叉搜索树的基础上,引出了B树、B-树和B+树等多插搜索树,而关于这些不同树的解释不是这次的重点,接下来我们看一下,我们一直说的Mysql中InnoDB是以B+树的形式存储索引的,到底是怎么组织的?
Buffer Pool
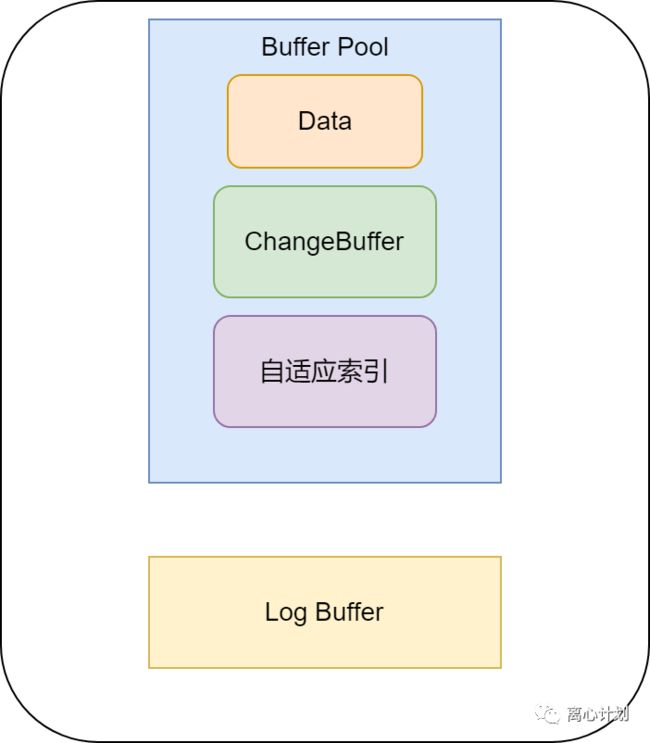
在此之前我们先了解一下InnoDB的内存模型,所谓内存模型就是内存的职责划分,目的是为了更高效的资源利用与回收。而Buffer Pool就是InnoDB的内存模型,其中Data区就是存放读取的行数据的,也是我们这次重点讨论的一块位置;ChangeBuffer是一块特殊的空间,主要用于如果update的行不在Data中,那么就先写到ChangeBuffer中去,避免了先读取数据到Data再修改的耗时耗资源操作;自适应索引则是InnoDB为了优化索引而存在的;Log Buffer则是针对redo log的io优化。
欢迎关注公众号:【离心计划】,一起逃离技术舒适圈
数据页和索引页
在了解B+树是怎么在InnoDB发挥前,咱们先了解一下mysql表是怎么存储,这边就不卖关子了,mysql表由表数据和索引组成。我们先看表数据,也就是我们存进去一行一行的数据,最终都要落到磁盘中,而这些一行行的数据,需要被InnoDB读取出来才能做crud,肯定不可能一行一行查,要记住,数据库的瓶颈是IO,所以InnoDB以页为单位读取和存储这些行数据,默认16kb,当然行数据只是页的一部分,这些工业级产品当然会设计更多的“元数据”帮助更好的crud啦,因此InnoDB的页结构大概是这样的:
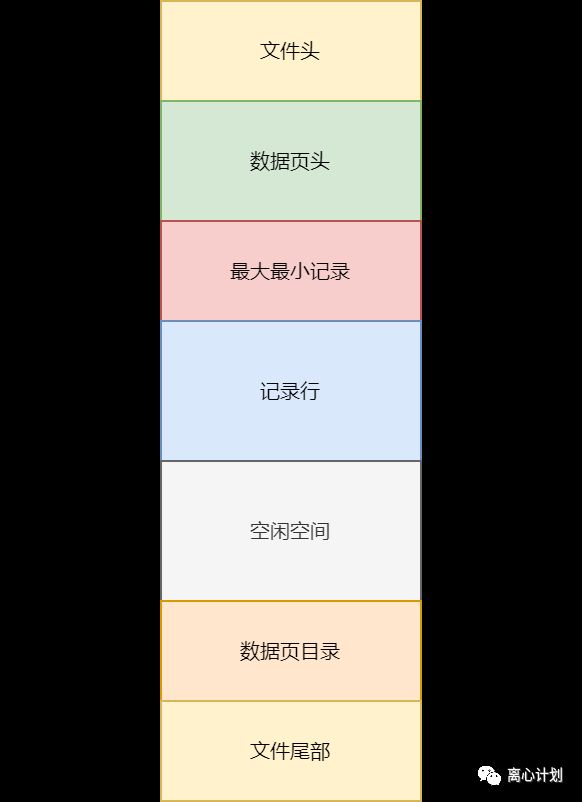
InnoDB管存储数据的页叫做数据页,其中空闲空间就是用来存放数据行的,不断往里面塞直到空闲空间被用完。一个页肯定放不下所有数据,因此会有好多的数据页,这些数据页会以双向链表的形式串联起来,这个双向就需要上一页的地址和下一页的地址,对的,这个信息就是存在文件头中(可见啥东西的头都是用来存这些基本信息的,记住要考的),而每个页中的每一条行数据之间也以单链表的形式按照主键大小顺序关联着,因此这些许许多多的数据页就以这样的形式亲密着:
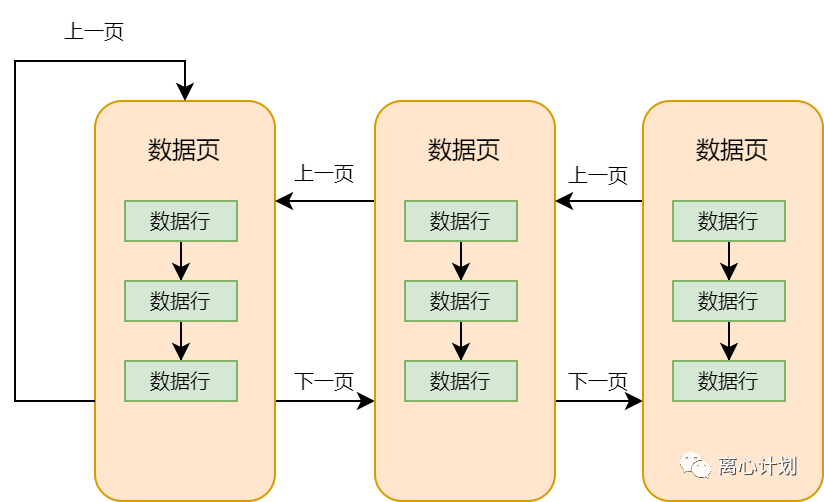
现在为止其实已经可以查到我们想要的数据了,先找到第一个数据页,然后遍历其中的行数据,没找到往下一页找,但就是太慢了,所以需要优化,先从单数据页中进行优化,如果行数据小的话,一页也可以存下很多行,如果以O(N)的复杂度去遍历,是低效的,行数据是有序链表,有序的数据优化查询我们可熟悉啊,什么二分查找、跳表等,InnoDB也是差不多的想法,利用了上面页结构图中的数据页目录提供一个查询优化,做法就是按照一定规则将行数据分成多个组,以每个组最小的主键id作为槽值放到目录中,而目录其实就是一个key/value形式的数据,存储槽值和行偏移地址的关系,形成一个粗略索引,这个思想和调表就很像了,这样我们就可以借助目录,加速单页中的行数据查询。
欢迎关注公众号:【离心计划】,一起逃离技术舒适圈
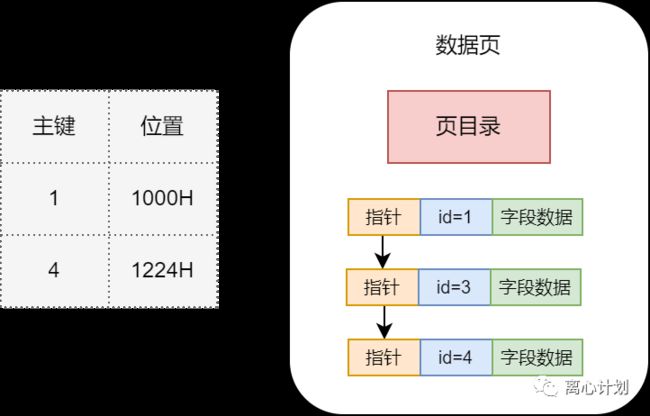
单页的查询是优化了,但是数据页和数据页之间还是得遍历查找,能不能把数据页目录的思想继续放大呢,也就是我们有个大的全局数据页目录,记录了页号和这个页最小主键id的对应关系,像这样:
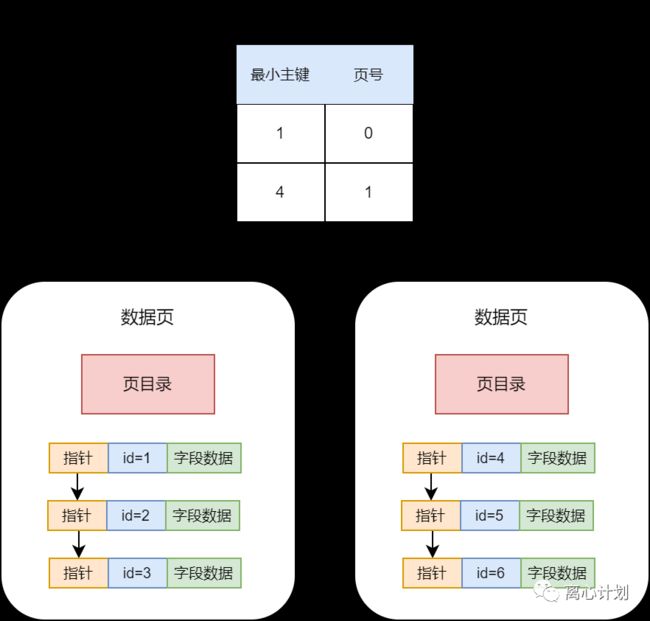
这样我们就能在数据页上做一个目录,可以快速查找需要找的数据了。但是数据量一大的话,这个全局目录也会很大,查询效率会随着数据量增大下降,因此InnoDB将这个全局的大目录也以页为单位拆分了出来,这个页叫做索引页。索引页之间为了保持高效查询与IO,就会以B+树的形式存储,最下层的索引页节点存储的目录信息是数据页号,这样索引页和数据页就关联了起来,像下图这样,这也是我们为什么说InnoDB的非叶子节点只存储索引信息,叶子节点才存储具体数据信息。

如上图所示,如果我们查找id为3的,那么顺序就是先找到跟索引页根据目录找到页号34,然后3在1和5之间,所以找到页号10,然后找到对应的数据。
数据页和索引页都是在磁盘上都是文件,涉及到文件都是IO,页之间虽然有连接但是只是逻辑顺序的,而不能保证物理顺序,所以相邻的页有可能是在磁盘不同分区,这就会造成随机IO,因此InnoDB为了保证顺序IO,会在给表以区的方式存储,一个区是连续的页,这样就能保证大部分的页都是物理顺序的。
而这是主键索引的组织方式,InnoDB中我们根据索引是否为主键,分为主键索引和非主键索引(也叫二级索引),而二级索引和主键索引的区别,就在于其数据页存储的是主键id信息,不会存储完成的行数据,如果根据二级索引查询的列信息只包含索引列,这个叫做索引覆盖,如果需要查询其他列数据,就需要查询到对应主键id后回到主键索引树中查询行数据,这个叫做回表。
小结
我们从二叉搜索树的特性引出了B+树等多叉树,然后从InnoDB的内存分布分析了索引和数据是如何组织成B+树的,所以我们现在不只是粗浅地知道了“mysql索引底层是B+树”的表面含义,也理解了其深层含义。
这边也推荐《高性能Mysql》这本书,可以让大家深入了解Mysql,链接给到:《高性能mysql第三版》
推荐阅读:
【专栏】核心篇09| 怎么保证缓存与DB的数据一致性
【专栏】RPC系列(番外)-IO模型与线程模型