说一下Glide缓存的大概流程
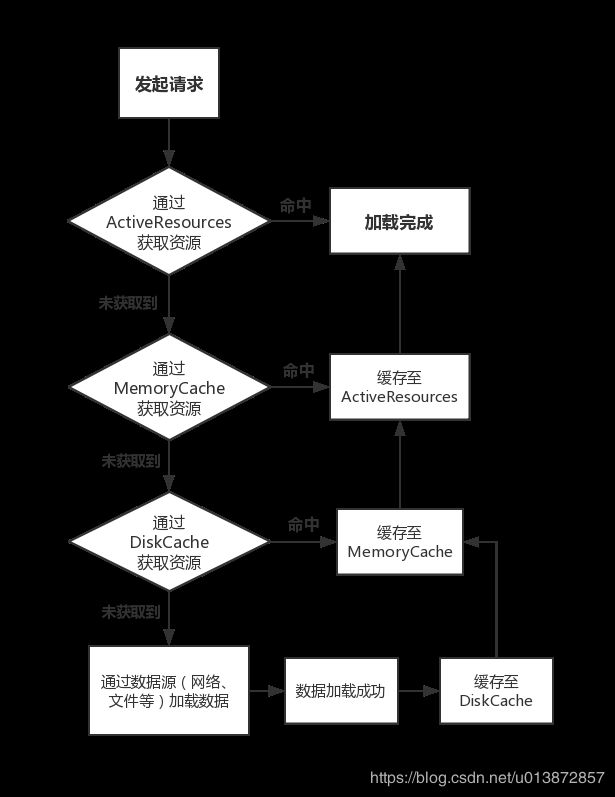
Glide会在开始一个新的图片请求之前检查以下多级缓存:
Active Resources: this image displayed in another View right now(该图片正在被其它view展示)
Memory Cache: this image recently loaded and still in memory(该图片最近被加载到内存中并且还未释放)
Resource: this image been decoded, transformed, and written to the disk cache before(该图片已经被解码,转换过,并且写到了磁盘缓存中)
Data: the data this image was obtained from written to the disk cache before(该图片的原始数据已经被写入磁盘缓存中)
ActiveResources
ActiveResources是第一级缓存。当资源加载成功或者通过其它缓存命中,都会加到ActiveResources 中,当资源释放时再移除。ActiveResources 用一个 Map 来保存资源的 WeakReference:
final Map activeEngineResources = new HashMap<>();
使用 WeakReference 的原因是防止内存泄漏。但由于是 WeakReference,因此随时有可能被系统GC,因此ActiveResources还有一个 ReferenceQueue 来跟踪资源被 GC 的情况:
private final ReferenceQueue> resourceReferenceQueue = new ReferenceQueue<>();
每当 activeEngineResources 中添加一个 WeakReference 都会把它和这个 ReferenceQueue 关联起来,这个体现在 ActiveResources#activate 方法中:
synchronized void activate(Key key, EngineResource resource) {
ResourceWeakReference toPut =
new ResourceWeakReference(
key, resource, resourceReferenceQueue, isActiveResourceRetentionAllowed);
ResourceWeakReference removed = activeEngineResources.put(key, toPut);
if (removed != null) {
removed.reset();
}
}
相关问题:
1. 具体说一下 ActiveResources 是怎样利用 ReferenceQueue 去跟踪 WeakReference 是否被GC 的?
先说一下为什么ReferenceQueue 可以跟踪 WeakReference 的GC情况。
WeakReference 有一个包含2个参数的构造方法:
/**
* Creates a new weak reference that refers to the given object and is
* registered with the given queue.
*
* @param referent object the new weak reference will refer to
* @param q the queue with which the reference is to be registered,
* or null if registration is not required
*/
public WeakReference(T referent, ReferenceQueue q) {
super(referent, q);
}
其中一个就是 ReferenceQueue。这个 ReferenceQueue 的作用在 WeakReference 这个类顶部的注释中有描述:
/**
* Weak reference objects, which do not prevent their referents from being
* made finalizable, finalized, and then reclaimed. Weak references are most
* often used to implement canonicalizing mappings.
*
* Suppose that the garbage collector determines at a certain point in time
* that an object is weakly
* reachable. At that time it will atomically clear all weak references to
* that object and all weak references to any other weakly-reachable objects
* from which that object is reachable through a chain of strong and soft
* references. At the same time it will declare all of the formerly
* weakly-reachable objects to be finalizable. At the same time or at some
* later time it will enqueue those newly-cleared weak references that are
* registered with reference queues.
*
* @author Mark Reinhold
* @since 1.2
*/
第二段中提到,在发生GC的时候,garbage collector 会把该对象的所有 weak reference 清除,而这些被清除的 WeakReference 对象在GC的同时或者稍晚一点的时间点被加入到他们注册的ReferenceQueue 中,也就是上面那个构造函数中传入的第二个参数。我们只需要遍历 ReferenceQueue 就可以知道哪些WeakReference 已经被GC了,然后从 activeEngineResources 中移除这些资源。
那么 ActiveResources 是在什么时机去检查ReferenceQueue 的呢?实际上在ActiveResources 对象被创建的时候,会起一个线程专门去检测是否有资源被GC:
ActiveResources(
boolean isActiveResourceRetentionAllowed, Executor monitorClearedResourcesExecutor) {
this.isActiveResourceRetentionAllowed = isActiveResourceRetentionAllowed;
this.monitorClearedResourcesExecutor = monitorClearedResourcesExecutor;
monitorClearedResourcesExecutor.execute(
new Runnable() {
@Override
public void run() {
cleanReferenceQueue();
}
});
}
@Synthetic
void cleanReferenceQueue() {
while (!isShutdown) {
try {
ResourceWeakReference ref = (ResourceWeakReference) resourceReferenceQueue.remove();
cleanupActiveReference(ref);
// This section for testing only.
DequeuedResourceCallback current = cb;
if (current != null) {
current.onResourceDequeued();
}
// End for testing only.
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
@Synthetic
void cleanupActiveReference(@NonNull ResourceWeakReference ref) {
// Fixes a deadlock where we normally acquire the Engine lock and then the ActiveResources lock
// but reverse that order in this one particular test. This is definitely a bit of a hack...
synchronized (listener) {
synchronized (this) {
activeEngineResources.remove(ref.key);
if (!ref.isCacheable || ref.resource == null) {
return;
}
EngineResource newResource =
new EngineResource<>(ref.resource, /*isCacheable=*/ true, /*isRecyclable=*/ false);
newResource.setResourceListener(ref.key, listener);
listener.onResourceReleased(ref.key, newResource);
}
}
}
这个线程中会调用 cleanReferenceQueue 方法,在这个方法中又调用了 cleanupActiveReference,就是在这个方法中,activeEngineResources 删除已经被GC 的资源。
2. Reference 的种类有哪些?各自的使用场景是什么?
- Java引用详解
LruBitmapPool
/**
* An {@link com.bumptech.glide.load.engine.bitmap_recycle.BitmapPool} implementation that uses an
* {@link com.bumptech.glide.load.engine.bitmap_recycle.LruPoolStrategy} to bucket {@link Bitmap}s
* and then uses an LRU eviction policy to evict {@link android.graphics.Bitmap}s from the least
* recently used bucket in order to keep the pool below a given maximum size limit.
*/
Glide 自己定义了一个 LruBitmapPool 对象来管理缓存的 Bitmap 对象。但是具体实现LRU算法的是 SizeConfigStrategy,它实现了 LruPoolStrategy 接口。
SizeConfigStrategy
/**
* Keys {@link android.graphics.Bitmap Bitmaps} using both
* {@link android.graphics.Bitmap#getAllocationByteCount()} and the
* {@link android.graphics.Bitmap.Config} returned from
* {@link android.graphics.Bitmap#getConfig()}.
*
* Using both the config and the byte size allows us to safely re-use a greater variety of
* {@link android.graphics.Bitmap Bitmaps}, which increases the hit rate of the pool and therefore
* the performance of applications. This class works around #301 by only allowing re-use of
* {@link android.graphics.Bitmap Bitmaps} with a matching number of bytes per pixel.
*/
SizeConfigStrategy 利用一个 GroupedLinkedMap 来存储 bitmap,这是一个Glide 自定义的类似 LinkedHashMap 的数据结构:
/**
* Similar to {@link java.util.LinkedHashMap} when access ordered except that it is access ordered
* on groups of bitmaps rather than individual objects. The idea is to be able to find the LRU
* bitmap size, rather than the LRU bitmap object. We can then remove bitmaps from the least
* recently used size of bitmap when we need to reduce our cache size.
*
* For the purposes of the LRU, we count gets for a particular size of bitmap as an access, even if
* no bitmaps of that size are present. We do not count addition or removal of bitmaps as an
* access.
*/
private final GroupedLinkedMap groupedMap = new GroupedLinkedMap<>();
groupMap 的key的类型是 Key,是通过 Bitmap 的 size 和 config 组合生成的,这也是 SizeConfigStrategy 这个类名的由来。
GroupedLinkedMap 具体实现如下图:
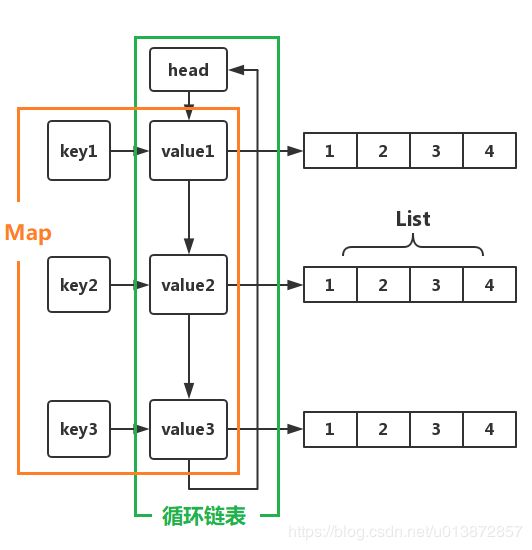
内部实现主要包括3中数据结构:
- List,用于存储每个LinkedEntry中的数据
- LinkedEntry,本质是循环双链表,用于记录数据的顺序
- HashMap,用于快速找到对应的 Entry
总结一下,BitmapPool 需要注意的有以下几点:
- BitmapPool 大小通过 MemorySizeCalculator 设置;
- 使用 LRU 算法维护 BitmapPool ;
- Glide 会根据 Bitmap 的 size 和 Config 生成一个 Key;
- Key 也有自己对应的对象池,使用 Queue 实现;
- 数据最终存储在 GroupedLinkedMap 中;
- GroupedLinkedMap 使用哈希表、循环链表、List 来存储数据。
MemoryCache
在最上面的 Glide 缓存层级中提到过,MemoryCache 中存储的是最近被加载到内存中并且还未被释放的资源。
MemoryCache 接口的实现类是 LruResourceCache,和 ActiveResources 的缓存策略一样,也是采用LRU cache。具体实现就不赘述了。
磁盘缓存
磁盘缓存同样采用LRU策略,它的实现类是 DiskLruCacheWrapper,看名字就知道这是一个包装类,包装的是 DiskLruCache。
DiskLruCache
首先想一个问题,磁盘缓存同样采用LRU,那么Glide怎样在APP启动的时候知道资源的使用频率并给资源排序呢?
其实Glide 的做法是创建一个日志清单文件来保存这个顺序。DiskLruCache 在 APP 第一次安装时会在缓存文件夹下创建一个 journal 日志文件来记录图片的添加、删除、读取等等操作,后面每次打开 APP 都会读取这个文件,把其中记录下来的缓存文件名读取到 LinkedHashMap 中,后面每次对图片的操作不仅是操作这个 LinkedHashMap 还要记录在 journal 文件中。
DiskLruCache 里有很多IO操作,就是因为它除了管理缓存之外还要把对资源的操作记录到日志清单文件中。
磁盘缓存的策略
Glide中定义的磁盘缓存策略有下面五种:
- DiskCacheStrategy.ALL:原始图片和转换过的图片都缓存
- DiskCacheStrategy.RESOURCE:只缓存原始图片
- DiskCacheStrategy.NONE:不缓存
- DiskCacheStrategy.DATA:只缓存使用过的图片
- DiskCacheStrategy.AUTOMATIC: 默认策略,尝试自动为本地和远程图片使用最佳的缓存策略。当你加载远程数据(比如,从URL下载)时,AUTOMATIC 策略仅会存储未被你的加载过程修改过(比如,变换,裁剪–译者注)的原始数据,因为下载远程数据相比调整磁盘上已经存在的数据要昂贵得多。对于本地数据,AUTOMATIC 策略则会仅存储变换过的缩略图,因为即使你需要再次生成另一个尺寸或类型的图片,取回原始数据也很容易。