Java多线程案例及其代码实现
目录
案例一:单例模式
1.饿汉模式的代码实现
2.懒汉模式
案例二:阻塞队列
1.线程安全
2.产生阻塞效果
1.如果队列为空,尝试出队列,就会出现阻塞现象,阻塞到队列不为空为止。
2.如果队列未满,尝试入队列,也会出现阻塞,阻塞到队列不为满为止。
案例三:定时器
1.描述任务
2.组织任务(使用一定的数据结构把这些任务给放到一起)
3.执行时间到了的任务
案例四:线程池
案例一:单例模式
线程安全的单例模式有两种典型实现:
1.饿汉模式。
2.懒汉模式。
什么是饿汉模式什么是懒汉模式呢,打个比方来说,饿汉模式就像我们有四个碗,每次用完四个碗,就洗干净,懒汉呢就是我吃完后这四个碗我不喜欢,需要的时候呢,要几个我在去洗几个(但这样反而是更加高效的)
总结:
饿汉模式的单例模式:直接去创建实例。
懒汉模式的单例模式:是不太着急的去创建实例,只有在用的时候,才真正创建。
1.饿汉模式的代码实现

在类中,我们直接使用static 创建一个势力,并且立即进行还是实例化,因为实现的是单例模式,所以将他的构造方法设为private,防止我们在其他地方不小心new这个Singleton,这样,这个instance就是Singleton的唯一实例 ,创建一个方法,让外界可以拿到这个唯一的实例。那么这个是线程安全的吗? 当然是,因为饿汉模式中的getInstance,仅仅只是读取变量内容,如果多个线程只是读同一个内容,不进行修改,此时,线程任然是安全的。
2.懒汉模式
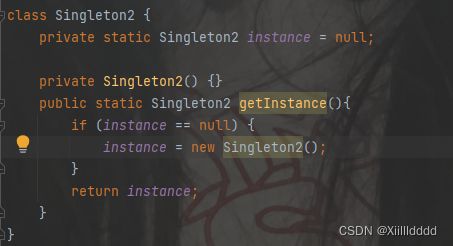
同饿汉模式不同的是,并不是一开始就创建出实例,只有当外界真正使用到getInstance的时候进入判断,如果这个实例不存在的话才会创建,但这个还是存在问题的,我们发现,这个和饿汉模式不同的是他的getInstance方法不仅仅进行了读操作,还包含了修改操作,不是原子性的,所以,存在着线程安全问题,就像我们之前讲到的,两个线程对一个变量进行增值,这里就有可能会创建出多个实例。那么如何保证懒汉模式的线程安全呢?这里我们就想到了加锁
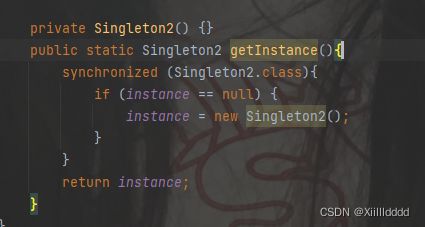
虽然现在我们加锁了,但是还是存在问题,出现线程安全是因为没有初始化,多个线程读写操作一起,可能会创建很多事例,但是当我们已经将instance初始化之后,这个方法就只剩下了读操作,此时是线程安全的,那么这样加锁的话,无论代码是初始化之后还是之前,调用getInstance都会进行加锁,这样就可能会产生所得竞争,但是这样的竞争其实是没有必要的,这样只会降低程序的运行速度,所以,我们就要对他进行优化
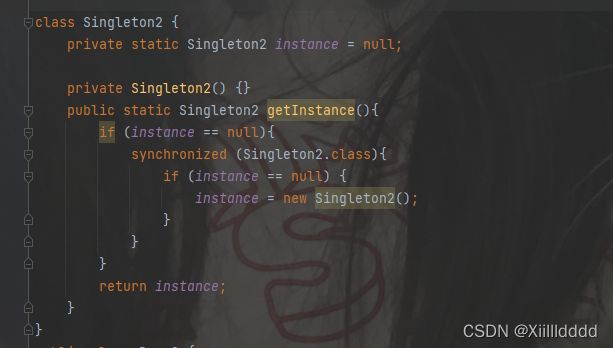
只有当instance没有创建实例的时候才会给它加锁,当他已经初始化了,我们就只需要读即可。我们发现内外两个判定条件一模一样,但是他们的作用却大不相同,外面的条件判定,是在判断是不是要加锁,内层的是判断是否要创建实例,只是刚好这两个目的就是判断instance是否为null。经过一顿整改,结果还有一个问题,就是内存可见性问题,当我们如果多个线程,都去调用这里的getInstance,就会造成大量的读操作,然后编译期就会自己优化,把合格读内存操作优化成读寄存器操作,当触发这个优化后,后续如果已经完成了对instance的修改,那么后面的线程感知不到,有人会想,不是加了synchronized吗?是的,这个内存可见性问题,可能会引起第一个if判定失效,但是对于第二个并没有多大影响,因此只是引起了第一层的误判,也及时导致不该加锁的加锁。解决的方法只需要给instance加上volatile即可。

这样,完全体的线程安全单例模式的懒汉模式就完成了。
总结一下:我们写饿汉模式就是直接创建实例,懒汉模式呢,使用在创建,懒汉模式要注意三点:1.正确的加锁位置
2.双重if判定
3.内存可视化问题
案例二:阻塞队列
既然是队列,那就同样也是先进先出,相比于普通队列,阻塞队列又有一些其他方面的功能。
1.线程安全
2.产生阻塞效果
1.如果队列为空,尝试出队列,就会出现阻塞现象,阻塞到队列不为空为止。
2.如果队列未满,尝试入队列,也会出现阻塞,阻塞到队列不为满为止。
基于上面的这些特性,我们就可以实现“生产者消费者模型”
生产者消费者模型
生产者消费者模型,是实际开发中非常有用的一种多线程开发手段,它具有一下几个有点
优点1:能够让多个服务器程序之间更充分的解耦合
如果不使用生产者消费者模型,两个服务器之间的耦合性是比较强的,在开发A服务器的时候就得充分了解B提供的一些接口,开发B的时候也得充分了解A是怎么调用的,一旦换成别的,服务器代码需要有很大的改动,而使用生产者消费者模型,就可以降低这里的耦合性。
优点2:能够对于请求进行“削峰填谷”
当不使用生产者消费者模型的时候,如果请求量突然暴涨,那么会进而导致另一个服务器请求量暴涨,虽然这个服务器为入口服务器,计算量很低,暴涨问题也不大,但是对于应用服务器,计算量就会很大,需要的需同资源也会很多,如果主机的硬件不够好的话,就有可能导致程序挂了。
这时,使用阻塞队列,请求量暴涨的时候,会导致阻塞队列的请求暴涨,由于阻塞队列没啥计算量,只是单纯的存储数据,所以能抗住很大的压力,应用服务器还是按照原来的速度来消费数据,不会因为,入口服务器暴涨而暴涨,被保护的很好,就不会引起程序的崩溃。
首先,我们先来了解先Java标准库中的阻塞队列的用法
在Java中我们用到的是

接下来,我们来自己实现一个阻塞队列
首先,我们先来实现一个普通的队列,再加上线程安全,再加上阻塞,那么就成了一个阻塞队列,数组我们可以基于链表实现,也可以基于数组实现,相对来说,数组更加方便,这里我们就用数组来实现,队列的话需要是循环队列,但是要想实现循环队列,我们要面对一个重要的问题,如何判断队列是满是空,我们定义一个tail,定义一个head,开始的时候,head和tail都只想首位置,当入队列时八元素放到tail位置上,然后tail++,出队列时把head位置的元素返回出去,并且head++;当hend或者tail到达对位的时候,就重新从头开始,循环。当head和tail相遇的时候就代表空或者满,但是如果不加额外的限制,此时队列空或者满都一样,于是,我们就有了两种方法:
1.浪费一个格子,当head == tail认为是空,当head == tail+1 认为是满。
2.额外创建一个变量;size,记录元素的个数
方法1 不直观,开销大,所以我们选择方法2
接下来我们要完成完整的生产者消费者模型,并简单实现下
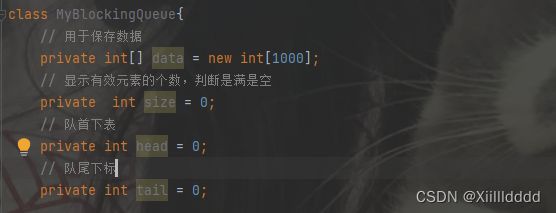
class MyBlockingQueue{
// 用于保存数据
private int[] data = new int[1000];
// 显示有效元素的个数,判断是满是空
private int size = 0;
// 队首下表
private int head = 0;
// 队尾下标
private int tail = 0;
// 专门的锁对象
private Object locker = new Object();
// 入队列
public void put(int value) throws InterruptedException {
synchronized (locker) {
// 队列满了
if (size == data.length) {
// 满了,等待不为满
locker.wait();
}
// 把元素放到tail下标处,tail++
data[tail] = value;
tail++;
// 当tail到最后了,将tail置位0,循环
if (tail >= data.length) {
tail = 0;
}
// 添加完后,长度要+1;
size++;
// 用于唤醒空队列时候阻塞等待
locker.notify();
}
}
// 出队列
public Integer take() throws InterruptedException {
synchronized (locker) {
if (size == 0) {
// 如果队列为空, 就返回一个非法值.
// return null;
locker.wait();
}
// 取出 head 位置的元素
int ret = data[head];
head++;
if (head >= data.length) {
head = 0;
}
size--;
// take 成功之后, 就唤醒 put 中的等待.
locker.notify();
return ret;
}
}
}
public class Demo3 {
private static MyBlockingQueue queue = new MyBlockingQueue();
public static void main(String[] args) {
Thread producer = new Thread(() ->{
int num = 0;
while (true) {
try {
System.out.println("产生了:" +num);
queue.put(num);
num++;
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
Thread customer = new Thread(() ->{
while (true) {
try {
int num = queue.take();
System.out.println("消费了:" + num);
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
customer.start();
}
}
为了方便观察我们每次打印停0.5秒,观察结果

而当我们只将消费线程停止0.5秒,这时我们就可以发现阻塞队列的作用

瞬间产生了1000,但是满了就会进入等待,只有通过take中的notify来唤醒
案例三:定时器
定时器就像是一个闹钟,进行定时,在一定时间后,被唤醒并且执行某个之前设定好的任务,提到这,我们就会想起前面说的join和sleep,join是可以指定等待时间,sleep可以指定休眠时间,这两个都是基于系统内部的定时器来实现的,接下来,我们来看看标准库中的定时器,在自己来实现一个定时器
java下的util包中的Timer类核心方法就一个schedule,参数有两个一个是用来描述任务是什么,一个是来指定多久后执行

要自己实现定时器,那我们需要想想Timer里面实现了什么,需要什么东西呢?
1.描述任务
创建一个专门的类来描述定时器中的任务(TimerTask)
布置完任务后下一步就是组织任务了
2.组织任务(使用一定的数据结构把这些任务给放到一起)
我们安排任务执行先后,需要判断谁先 ,快速找到所有任务中,时间最小的,所以,这里我们就要使用到优先级队列,在标准库中,有一个专门的数据结构 PriorityQueue ,这里因为是多线程,所以我们要考虑到线程安全问题所以我们将用到PriorityBlockingQueue,及带有优先级,又带有阻塞队列
![]()
3.执行时间到了的任务
需要先执行时间最靠前的任务,就需要有一个线程,不停地去检查当前优先队列的队首元素,看看说当前最靠前的任务是不是已经到该执行的时间了
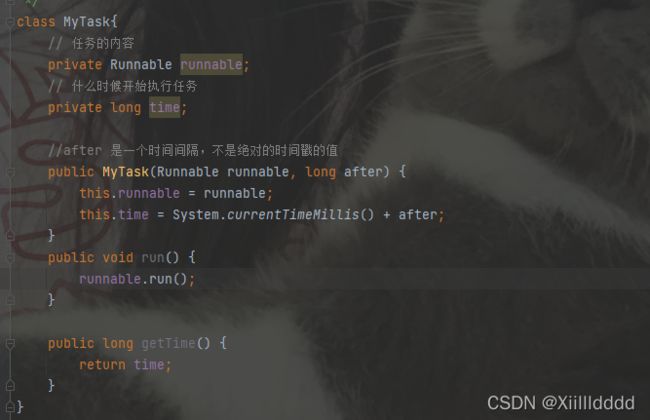
class MyTask implements Comparable{
// 任务的内容
private Runnable runnable;
// 什么时候开始执行任务
private long time;
//after 是一个时间间隔,不是绝对的时间戳的值
public MyTask(Runnable runnable, long after) {
this.runnable = runnable;
this.time = System.currentTimeMillis() + after;
}
public void run() {
runnable.run();
}
public long getTime() {
return time;
}
@Override
public int compareTo(MyTask o) {
return (int) (this.time - o.time);
}
// 比较
}
class MyTimer {
// 定时器内部要存放多个任务
// 创建一个优先级队列,用来存放任务
private PriorityBlockingQueue queue = new PriorityBlockingQueue<>();
// 准备
public void schedule(Runnable runnable, long delay) {
// 相对列中插入任务
MyTask task = new MyTask(runnable,delay);
queue.put(task);
synchronized (locker) {
locker.notify();
}
}
// 添加锁对象
private Object locker = new Object();
public MyTimer () {
Thread t = new Thread(() -> {
while(true) {
try {
// 先取出队首任务元素
MyTask task =queue.take();
long curTime = System.currentTimeMillis();
// 判断时间到没,没到放回去,到了执行
if (curTime < task.getTime()) {
queue.put(task);
synchronized (locker) {
locker.wait(task.getTime() - curTime);
}
} else {
task.run();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
} 这就是完成后的代码,其中有两点我们要值得注意,1.MyTask要有指定的比较任务先后的规则,需要我们手动指定,按照时间大小来比较。2.在检查比较当前任务到没到时间的时候,我们需要增加一个限制,如果不增加任何限制,这个循环就会执行的非常快,就会出现忙等现象,非常浪费CPU,所以,我们就要基于wait来制定等待时间,算出时间差,等待改时间,当然,在等待时候可能会加入新的任务,而且这个任务可能更接近执行时间,所以,要在schedule操作中,需要加上一个notify操作来唤醒。
总结:
1.描述一个任务,runnable+time;
2.使用优先队列来组织若干任务,PriorityBlockingQueue
3.实现schedule方法来注册任务到队列中
4.创建一个扫描线程,这个扫描线程不停地获取到队首元素,并且判定时间是否到达
还有上面提到的两点注意
案例四:线程池
线程池和进程池类似,就是把线程提前创建好,放到池子里,后面需要用到线程时,直接从池子里取出,就不必在系统这边申请了,线程用完了,也不是还给系统,而是放回到池子里,以备下次使用。
一样的,我们先来看看Java标准库中,线程池的使用,然后在自己实现一个线程池,在标准库中线程池叫做ThreadPoolExecutor 在java.util.concurrent 中,Java中很多和多线程相关的组件都在concurrent 包中
一共有四种构造方法,参数十分复杂,大家下去自己了解下了,虽然他参数很多,但是最重要的是第一组参数,线程池中线程的个数,标准库中还有一个简单版本的线程池Executors,本质上就是针对ThreadPoolExecutor进行了封装,提供了写默认参数,接下来我们仿照这个实现一个线程池
线程池里有啥呢:
1.先能够描述任务(直接使用Runnable)
2.需要组织任务(直接使用Blockingqueue)
3.能够描述工作线程
4.还需要组织这些线程。
5.需要实现往线程池里添加任务
class myThreadPool {
private BlockingQueue queue = new LinkedBlockingQueue<>();
static class Worker extends Thread {
private BlockingQueue queue = null;
public Worker(BlockingQueue queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
Runnable runnable = queue.take();
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
private List workers = new ArrayList<>();
public myThreadPool(int n) {
for (int i = 0; i < n; i++) {
Worker worker = new Worker(queue);
worker.start();
workers.add(worker);
}
}
public void submit(Runnable runnable) {
try {
queue.put(runnable);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}