四大常用集成算法(Xgboost,CatBoost,Lightbm,DeepForest)
机器学习结构化数据领域内,有四大常用的集成学习算法,学习能力强,并且均具备一定的抗过拟合能力。分别是Xgboost,CatBoost,Lightbm,DeepForest。
本篇文章直接略过原理部分,直接上保姆级原始算法库参数详解以及调参通用代码总结,非常适合只是拿来用用的小伙伴。(欢迎有相关需求的小伙伴私信联系我可咸鱼,价格美丽,质量效率高)
本篇文章分为四个部分:
1 xgboost
2 lightgbm
3 catboost
4 deepforest
一 xgboost
对于上述算法,其原生库需要将数据包装为一个DMtrix对象中,转成该格式后才能对数据进行训练,并且该格式的数据一旦被转化,便无法查看数据样式。
1 转换数据格式
import xgboost as xgb
import pandas as pd
X_train = pd.read_csv('./train.csv')
y_train = pd.read_csv('./y_train.csv')
x_val = pd.read_csv('./val.csv')
y_val = pd.read_csv('./y_val.csv')
# 转化数据格式
xgb_train =xgb.DMatrix(data=X_train,label=y_train['ret'],enable_categorical=True)
xgb_val = xgb.DMatrix(data=X_val,label=y_val['ret'])
xgb_test = xgb.DMatrix(data=test_for_pre)
2 定义超参数空间
构建超参数空间需要用字典进行构建,key为参数名称,value为值。首先需要确定两个参数
‘objective' 以及’eval_metric‘
object即损失函数声明,对于回归算法主要有两个可选(’reg':'squarederror','reg':'squaredlogerror')
对于分类主要分为二分类还是多分类:
binary:logistic:二元分类的逻辑回归,输出概率
binary:logitraw:用于二进制分类的逻辑回归,逻辑转换之前的输出得分
binary:hinge:二进制分类的铰链损失。这使预测为0或1,而不是产生概率。
count:poisson –计数数据的泊松回归,泊松分布的输出平均值
对于eval_metric:
rmse:均方根误差
rmsle:均方根对数误差:reg:squaredlogerror目标的默认指标。此指标可减少数据集中异常值所产生的错误。但是由于log采用功能,rmsle可能nan在预测值小于-1时输出。
reg:squaredlogerror
mae:平均绝对误差
logloss:负对数似然
error:二进制分类错误率。计算公式为。对于预测,评估会将预测值大于0.5的实例视为肯定实例,而将其他实例视为否定实例。#(wrong cases)/#(all cases)
error@t:可以通过提供’t’的数值来指定不同于0.5的二进制分类阈值。
merror:多类分类错误率。计算公式为。#(wrong cases)/#(all cases)
mlogloss:多类logloss。
auc:曲线下面积
(tips:对于选择多分类作为评估指标一定要指定上num_class参数,否则报错)
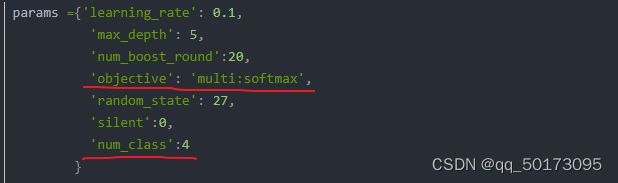
确定完上述两个参数后,主要就是算法的相关参数:
T0 梯队参数:
eta:该参数为学习率,即每轮迭代该棵树预测结果需要×一个学习率,学习率大一点可以适当调小一点迭代轮数,小一点可以适当调大一点迭代轮数,默认值0.3 取值范围【0,1】
num_boost_round:该参数含义明显,即boosting算法迭代的轮数。
T1梯队参数:
lambda:L2权重正则化参数,由于该参数在xgboost目标函数里面定义,作为结构风险的一部分,默认为1,越大越往抗过拟合方向控制
’gamma‘ 正则化参数,gamma越大树生长的越浅
’booster‘:可以gbtree,gblinear或者dart; gbtree并dart使用基于树的模型,同时gblinear使用线性函数。默认gbtree,gbdart 引入dropout思想对于抑制过拟合更强劲
colsample_bytree,colsample_bylevel,colsample_bynode[默认= 1]
colsample_bytree是构造每棵树时列的子采样率。对每一个构造的树进行一次二次采样。
colsample_bylevel是每个级别的列的子样本比率。对于树中达到的每个新深度级别,都会进行一次二次采样。从为当前树选择的一组列中对列进行子采样。
colsample_bynode是每个节点(拆分)的列的子样本比率。每次评估新的分割时,都会进行一次二次采样。列是从为当前级别选择的一组列中进行子采样的。
tree,level,node 是递进的关系,一般tree 不要设置过大
max_child_weight:如果树分区步骤导致叶节点的实例二阶导数之和,小于min_child_weight,则构建过程将放弃进一步的分区。在线性回归任务中,这仅对应于每个节点中需要的最少实例数。越大min_child_weight,算法将越保守。范围:[0,∞]
T2梯队参数:
alpha : L1权重正则化参数
max_depth:树的最大深度,默认为6
sub_samples:样本的抽样比例,类似于oob过程。
booster选择为gbdart 时独有的参数:
rate_drop:在每轮迭代过程中,会随机丢弃该轮迭代的结果。
skip_drop [默认值= 0.0] 在增强迭代过程中跳过退出过程的可能性。如果跳过了退出,则以与相同的方式添加新树gbtree。请注意,非零的skip_drop优先级高于rate_drop或one_drop。范围:[0.0,1.0]
其他xgboost参数使用注意事项:
evals参数是一个列表嵌套元组:可以在训练过程中监视结果
格式如下:
evals=[(xgb_train,'train'),(xgb_val,'val')]
seed: 随机数种子,方便复现
nthread:线程数
tree_method: 可选’gup_hist‘ 如果gpu可用的话。
xgboost常用参数就这么多,下面进行实战吧:
3 实战
xgb_params_class = {'objective':'binary:logistic'
,'eval_metric':'error'
,'seed':20
,'tree_method':'gpu_hist'
,'nthread':-1
,'eta':0.3
,'gamma':5
,'lambda':5
,'colsample_bytree':0.9
,'colsample_bylevel':0.8
,'colsample_bynode':0.9
,'min_child_weight':0.1
,'max_depth':7
,'booster':'gbtree'
,'sub_samples':0.8}
xgb_model1 = xgb.train(params=xgb_params_class,dtrain=xgb_train,num_boost_round=1500,early_stopping_rounds=200,
evals=[(xgb_train,'train'),(xgb_val,'val')])结果如下:
[0] train-error:0.00646 val-error:0.00502
[1] train-error:0.00646 val-error:0.00501
[2] train-error:0.00645 val-error:0.00497
[3] train-error:0.00644 val-error:0.00498
[4] train-error:0.00643 val-error:0.00498
[5] train-error:0.00644 val-error:0.00497
[6] train-error:0.00644 val-error:0.00498
[7] train-error:0.00643 val-error:0.00497
[8] train-error:0.00642 val-error:0.00499
[9] train-error:0.00641 val-error:0.00499
[10] train-error:0.00640 val-error:0.00498
[11] train-error:0.00641 val-error:0.00498
[12] train-error:0.00640 val-error:0.00498
[13] train-error:0.00640 val-error:0.00498
[14] train-error:0.00640 val-error:0.00498
[15] train-error:0.00641 val-error:0.00498
[16] train-error:0.00640 val-error:0.00498对于回归任务定义如下:
xgb_params_regre = {'objective':'reg:squarederror'
,'eval_metric':'rmse'
,'seed':10
,'tree_method':'gpu_hist'
,'eta':0.02
,'gamma':5
,'lambda':5
,'colsample_bytree':0.9
,'colsample_bylevel':0.8
,'colsample_bynode':0.9
,'min_child_weight':0.1
,'max_depth':7
,'booster':'gbtree'
,'sub_samples':0.8}
dtrain_regression = xgb.DMatrix(X_train[train_['ret']==1],
label=train_['target'][train_['ret']==1])
xgb_model2 = xgb.train(xgb_params_regre,dtrain=dtrain_regression,num_boost_round=1500,early_stopping_rounds=200,
evals=[(dtrain_regression,'train'),(xgb_val,'val')])部分结果如下
[181] train-rmse:3.10120 val-rmse:0.72774
[182] train-rmse:3.09797 val-rmse:0.72742
[183] train-rmse:3.09435 val-rmse:0.72722
[184] train-rmse:3.09169 val-rmse:0.72615
[185] train-rmse:3.08969 val-rmse:0.72663
[186] train-rmse:3.08773 val-rmse:0.72734
[187] train-rmse:3.08555 val-rmse:0.72787
[188] train-rmse:3.08304 val-rmse:0.72796
[189] train-rmse:3.08113 val-rmse:0.72846
利用两个模型,训练结果提交kaggle 平台。
贝叶斯超参数优化:
我们利用hyperopt库对模型进行参数优化
param_grid_simple = {'num_boost_round': hp.quniform("num_boost_round",50,200,10)
,"eta": hp.quniform("eta",0.05,2.05,0.05)
,"booster":hp.choice("booster",["gbtree","dart"])
,"colsample_bytree":hp.quniform("colsample_bytree",0.3,1,0.1)
,"colsample_bynode":hp.quniform("colsample_bynode",0.1,1,0.1)
,"gamma":hp.quniform("gamma",1e6,1e7,1e6)
,"lambda":hp.quniform("lambda",0,3,0.2)
,"min_child_weight":hp.quniform("min_child_weight",0,50,2)
,"max_depth":hp.choice("max_depth",[*range(2,30,2)])
,"subsample":hp.quniform("subsample",0.1,1,0.1)
,"objective":hp.choice("objective",["reg:squarederror","reg:squaredlogerror"])
,"rate_drop":hp.quniform("rate_drop",0.1,1,0.1)
}
def hyperopt_objective(params):
paramsforxgb = {"eta":params["eta"]
,"booster":params["booster"]
,"colsample_bytree":params["colsample_bytree"]
,"colsample_bynode":params["colsample_bynode"]
,"gamma":params["gamma"]
,"lambda":params["lambda"]
,"min_child_weight":params["min_child_weight"]
,"max_depth":int(params["max_depth"])
,"subsample":params["subsample"]
,"objective":params["objective"]
,"rate_drop":params["rate_drop"]
,"nthread":14
,"verbosity":0
,"seed":1412}
result = xgb.cv(params,data_xgb, seed=1412, metrics=("rmse")
,num_boost_round=int(params["num_boost_round"]))
return result.iloc[-1,2]
def param_hyperopt(max_evals=100):
#保存迭代过程
trials = Trials()
#设置提前停止
early_stop_fn = no_progress_loss(30)
#定义代理模型
params_best = fmin(hyperopt_objective
, space = param_grid_simple
, algo = tpe.suggest
, max_evals = max_evals
, verbose=True
, trials = trials
, early_stop_fn = early_stop_fn
)
#打印最优参数,fmin会自动打印最佳分数
print("\n","\n","best params: ", params_best,
"\n")
return params_best, trials二 lightgbm
2.1 转换数据格式
用法同xgboost一样,只不过是Dataset 去调用而不是DMatrix
dtrain_class = lgb.Dataset(X_train,label=train_['ret'])
dtrain_regression = lgb.Dataset(X_train[train_['ret']==1],
label=train_['target'][train_['ret']==1])2.2 定义超参数空间
同理首先需要确定的固定参数:
objective:
对于回归任务:regression, regression_l1, huber, fair, poisson, quantile, mape, gamma, tweedie,
一般选前两个就不错了
对于分类任务:
binary, multiclass, multiclassova, cross_entropy,cross_entropy_lambda
对于二分类或者多分类设置方法同xgboost,唯一一点是,如果标签是0-1之间的概率值,可以用cross_entropy作为损失函数 或者cross_entropy_lambda也可
同xgboost,如果设置的多分类,那么需要设置num_class参数
metric:
常用的metric评价指标
对于回归任务:
'None‘注意这里的None是字符串而不是None类型,代表不设置metric指标
mse、mae、rmse、quantile、huber、
对于分类任务:
auc、binary_logloss、binary_error、muti_logloss、muti_error、cross_entropy、cross_entropy_lambda、kldiv(KL散度)
metric_freq:
输出频率默认为1,如果嫌输出太多可以设置稍大一点
如果想要用gpu加速你的运算你可以设置device =’gpu‘
‘device’ : ‘gpu’
调参需要参数
T1梯队
1 num_leaves
lightgbm 采用的分枝策略是leaf_wise的方法,这会导致树会比level_wise的数深的多,理论上叶子数量等于2**(max_depth),但是实践中官网建议我们通过设置这个数量要比2**max_depth要低才可以取得更好的效果。
2 min_data_in_leaf
这是一个非常重要的参数,可以防止在叶状树中过度拟合。它的最优值取决于训练样本的数量和num_leaves。将其设置为较大的值可以避免树长得太深,但可能会导致拟合不足。实际上,对于大型数据集,将其设置为数百或数千就足够了。
3 max_depth
与xgboost不同,xgboost树中最大深度一般不大,所以调整该参数效果不明显,但是在lightgbm中max_depth是一个非常重要的参数,越小 抗过拟合能力越强,学习能力越弱
4 num_boost_round
同xgboost
5 eta
同xgboost
6 max_bins
LightGBM的直方图算法是代替Xgboost的预排序算法的,直方图算法说白了就是把连续的浮点特征离散化为k个整数(也就是分桶bins的思想), 比如[0, 0.1) ->0, [0.1, 0.3)->1。 并根据特征所在的bin对其进行梯度累加和个数统计,在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。 max_bins 越大那么分的越细,所以 maxbins 越大效果越好,计算量也就越大
T2梯队
boosting:可选参数gbdt,dart,rf(随机森林)、goss(单边梯度抽样)
默认gbdt,如果想要更高的精度可以试试dart
另外同xgboost的booster dart参数,如果设置了dart,那么可以设置drop_rate默认0.1
skip_drop默认0.5
min_child_weight:同xgboost 为节点最小二阶导数之和。
min_child_sample(min_data_in_leaf): 一个叶子节点最小的样本数。增大此参数可以抗过拟合
一些feature将根据min_data_in_leaf的值被过滤掉,举个简单的例子,考虑一个包含1000个观察数据集,其特征名为feature_1。Feature_1只有两个值:25.0(995个观察)和50.0(5个观察)。如果min_data_in_leaf = 10,则该特性没有分割,这将导致有效的分割,至少一个叶节点将只有5个样本。可以设置feature_pre_filter=True减小训练时间
lambda_l1,lambda_l2:同xgboost的alpha和lambda参数,分别为l1,l2正则化,默认为0
min_gain_to_split: 对于每次分裂最小的分裂增益默认为0,越大会越往抗过拟合的方向前进。
T3梯队:
subsample:
bagging过程,也可以写为bagging_fraction,表示抽取样本的比例,开启此参数可以加速训练进程,可以往扛过拟合的方向前进。默认为1不进行bagging过程。(使用此参数必须设置bagging_freq参数)
bagging_freq:默认为0
0表示禁用bagging;K表示每K次迭代执行bagging。每k次迭代,LightGBM将随机选择bagging_fraction * 100%的数据用于接下来的k次迭代
extra_trees:默认为false
如果开启则分裂节点采取极端随机数的方法,会加速训练,会抗过拟合。
(声明:对于lightgbm 和 xgboost 调参上述参数绝对够用,并且很多。你可能在其他地方会看到不一样名字的参数,但那可能只是上述参数的别名罢了,所以如果想要调参,看这篇文章就够了)
下面演示用
3 实战
def param_hyperopt(train):
"""
模型参数搜索与优化函数
:param train:训练数据集
:return params_best:lgb最优参数
"""
# Part 1.划分特征名称,删除ID列和标签列
label = 'target'
features = train.columns.tolist()
features.remove('card_id')
features.remove('target')
# Part 2.封装训练数据
train_data = lgb.Dataset(train[features], train[label])
# Part 3.内部函数,输入模型超参数损失值输出函数
def hyperopt_objective(params):
"""
输入超参数,输出对应损失值
:param params:
:return:最小rmse
"""
# 创建参数集
params = params_append(params)
print(params)
# 借助lgb的cv过程,输出某一组超参数下损失值的最小值
res = lgb.cv(params, train_data, 1000,
nfold=2,
stratified=False,
shuffle=True,
metrics='rmse',
early_stopping_rounds=20,
verbose_eval=False,
show_stdv=False,
seed=2020)
return min(res['rmse-mean']) # res是个字典
# Part 4.lgb超参数空间
params_space = {
'learning_rate': hp.uniform('learning_rate', 1e-2, 5e-1),
'bagging_fraction': hp.uniform('bagging_fraction', 0.5, 1),
'feature_fraction': hp.uniform('feature_fraction', 0.5, 1),
'num_leaves': hp.choice('num_leaves', list(range(10, 300, 10))),
'reg_alpha': hp.randint('reg_alpha', 0, 10),
'reg_lambda': hp.uniform('reg_lambda', 0, 10),
'bagging_freq': hp.randint('bagging_freq', 1, 10),
'min_child_samples': hp.choice('min_child_samples', list(range(1, 30, 5)))
}
# Part 5.TPE超参数搜索
params_best = fmin(
hyperopt_objective,
space=params_space,
algo=tpe.suggest,
max_evals=30,
rstate=RandomState(2020))
# 返回最佳参数
return params_best三 深度森林算法
深度森林算法是南京大学周志华老师于2017年提出的算法,借鉴了深度学习中神经网络的思想,采用级联形式

输入特征经过第一层级联输出特征,然后将第一层的输出特征于第原始特征拼接送入第二层,级联森林的模型架构是自适应的,为了降低过度拟合的风险,每个森林产生的类向量通过k fold交叉验证生成。在扩展到新的level之后,我们需要在验证集上估计整个级联的性能,并且如果没有显着的性能增益,则训练过程将终止;因此,级联级别的数量是自动确定的。与模型复杂性固定的大多数深度神经网络相比,gcForest通过在足够时终止训练来自适应地决定其模型复杂性。这使其能够适用于不同规模的训练数据,而不仅限于大规模训练数据。
其中对于输入特征还用到了划窗扫描的操作,具体原理细节就不讲了,如有需要可以拜读周志华老师的论文。Zhou, Z.-H.; Feng, J. (2017). Deep forest: Towards an alternative to deep neural networks. IJCAI, pp 3553–3559.

#安装
$ pip install deep-forest# 定义模型 训练和预测简单小栗子
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from deepforest import CascadeForestClassifier
# Load data
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
model = CascadeForestClassifier()
# Train and evaluate
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred) * 100
print("\nTesting Accuracy: {:.3f} %".format(acc))
# Save the model
model.save("model")深度森林调参详解
oh,god 深度森林算法可以说是,四大集成算法中超参数数量最小,也最适合用户使用的了。下面介绍一下深度森林算法常用参数。
如果想要更高的精度
增加模型的复杂性
提高deep forest性能的一种直观的方法是增加其模型复杂度,下面是控制模型复杂度的一些重要参数:
n_estimators:指定每个级联层中估计器的数量。默认为2
n_trees:指定每个估计器中的树的数量。默认100
max_layers:指定级联层的最大数量。默认20
添加preditor:
除了增加模型的复杂性,你可以借用随机森林或梯度提升决策树(GBDT)的力量,这可以根据数据集有所帮助:
use_predictor:决定是否使用连接到森林深处的预测器。
predictor:指定预测器的类型,应该是"forest", "xgboost", "lightgbm"中的一个。如果你要使用它们作为预测器,请确保安装了xgboost或lightgbm。
tips:决定是否添加预测器的一个有用规则是将深森林的性能与由训练数据产生的独立预测器进行比较。如果预测器持续优于深度森林,那么通过添加预测器,深度森林的性能有望提高。在这种情况下,来自森林深处的增强特征也有助于训练预测器。
n_bins: 分割特征分桶的数量,默认255
max_depth:指定树的最大深度。None表示无约束。
min_samples_leaf:指定叶节点上所需的最小样本数。最小值为1。
n_tolerant_rounds:在处理提前停止时指定容忍轮数。最小值为1。
实战
deepforest = CascadeForestClassifier(max_layers=30,n_estimators=10,n_trees=150,use_predictor=True,n_tolerant_rounds=3,n_jobs=-1)
deepforest.fit(X_train,y_train['ret'])
#
[2022-12-03 16:25:00.856] Start to fit the model:
[2022-12-03 16:25:00.856] Fitting cascade layer = 0
[2022-12-03 16:38:32.724] layer = 0 | Val Acc = 99.330 % | Elapsed = 811.869 s
[2022-12-03 16:38:34.163] Fitting cascade layer = 1
[2022-12-03 16:58:01.859] layer = 1 | Val Acc = 99.349 % | Elapsed = 1167.696 s
[2022-12-03 16:58:03.296] Fitting cascade layer = 2
[2022-12-03 17:21:31.880] layer = 2 | Val Acc = 99.348 % | Elapsed = 1408.584 s
[2022-12-03 17:21:31.880] Early stopping counter: 1 out of 3
[2022-12-03 17:21:33.259] Fitting cascade layer = 3
[2022-12-03 17:45:39.721] layer = 3 | Val Acc = 99.350 % | Elapsed = 1446.462 s
[2022-12-03 17:45:41.235] Fitting cascade layer = 4
[2022-12-03 18:08:47.640] layer = 4 | Val Acc = 99.351 % | Elapsed = 1386.405 s
[2022-12-03 18:08:47.640] Early stopping counter: 1 out of 3
[2022-12-03 18:08:49.099] Fitting cascade layer = 5
deep_regression = CascadeForestRegressor(max_layers=30,n_estimators=10,n_trees=150,use_predictor=True,n_tolerant_rounds=3,n_jobs=-1)
deep_regression.fit(X_train[train_['ret']==1],y_train['target'][train_['ret']==1])
[2022-12-04 01:30:44.601] Start to fit the model:
[2022-12-04 01:30:44.601] Fitting cascade layer = 0
[2022-12-04 01:30:58.021] layer = 0 | Val MSE = 15.95373 | Elapsed = 13.421 s
[2022-12-04 01:30:58.076] Fitting cascade layer = 1
[2022-12-04 01:31:11.506] layer = 1 | Val MSE = 15.68419 | Elapsed = 13.430 s
[2022-12-04 01:31:11.561] Fitting cascade layer = 2
[2022-12-04 01:31:24.845] layer = 2 | Val MSE = 15.87331 | Elapsed = 13.283 s
[2022-12-04 01:31:24.845] Early stopping counter: 1 out of 3
[2022-12-04 01:31:24.898] Fitting cascade layer = 3
[2022-12-04 01:31:38.758] layer = 3 | Val MSE = 15.90996 | Elapsed = 13.860 s
[2022-12-04 01:31:38.758] Early stopping counter: 2 out of 3
[2022-12-04 01:31:38.811] Fitting cascade layer = 4
[2022-12-04 01:31:51.923] layer = 4 | Val MSE = 15.89033 | Elapsed = 13.112 s
[2022-12-04 01:31:51.923] Early stopping counter: 3 out of 3 四 catboost
catboost 作为又一个集成学习算法神器,从名字就可以看出来该算法支持对离散型变量的处理,如果你的数据集离散变量比较多,那么catboost绝对是一个不错的选择。
不讲述原理,下面之间介绍调参调用技巧。
1 转换数据格式
同xgb 和 lgb,catboost原生算法库也需要将数据格式转化成对应的格式方可进行训练。
train_pool = catboost.Pool(X_train,y_train,)
val = catboost.Pool(X_val,y_val)
注意,catboost在转换数据格式的时候,可以明确的指出哪些变量是离散的,这样可能效果会更好一点。
2 参数空间详解
同样,catboost 确定参数的时候,也有几个参数是需要最先确定的,这点同上述xgb lgb一样,那么就先看一下这几个参数:
首先贴两张图分别对应分类和回归,以方便解释下面 loss_function 和 evalmetric
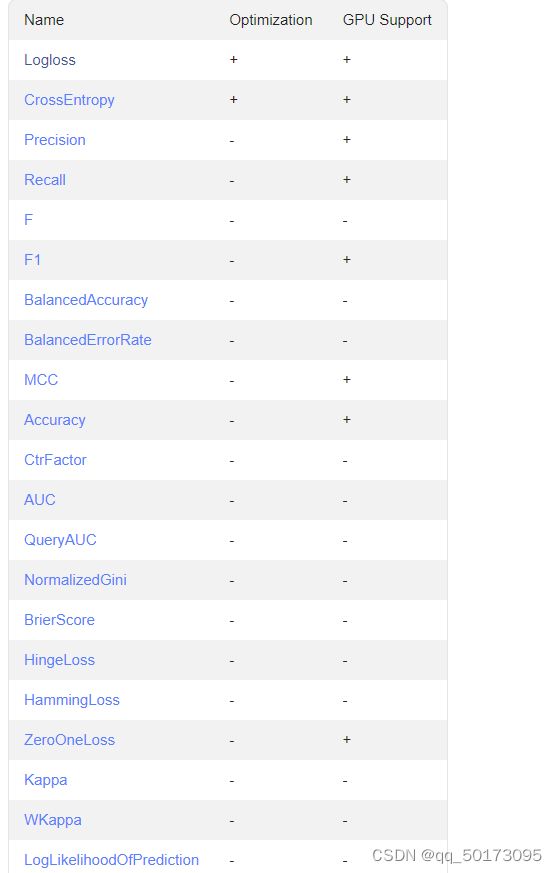

loss_function:catboost用于优化的目标函数,对于分类问题可以参考第一张图,由于我们建树的目标就是优化loss_function达到一个比较好的优解,因此loss_function只能选择optimization为+号的函数,对于分类只能选择logloss和cross_entropy两个,并且都支持gpu的加速运算。对于回归问题,同理参考第二张图。但是对于回归常规的任务我们选择MAE或者RMSE即可。
eval_metric: 该参数代表在训练过程中我们想要打印的评估指标,通用参考上述两幅图,任意都可以,只有一点需要注意的是,如果我们想使用gpu训练模型的话,那么部分评估指标是不支持gpu运算的。
讲完首先需要设置的参数后,下面就是比较重要的参数,对于catboost使用需要关注这些即可。
下面参数是参考https://huaweicloud.csdn.net/638068cddacf622b8df870b1.html?spm=1001.2101.3001.6650.6&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~activity-6-125570737-blog-119414740.pc_relevant_multi_platform_whitelistv3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~activity-6-125570737-blog-119414740.pc_relevant_multi_platform_whitelistv3&utm_relevant_index=11
catboost 调用最好是用sklearn 版本的模式,用法同sklearn 评估器差不多。
'''
公共参数
'''
params={
'loss_function': , : 损失函数,取值RMSE, Logloss, MAE, CrossEntropy, Quantile, LogLinQuantile, Multiclass, MultiClassOneVsAll, MAPE, Poisson。默认Logloss。
'custom_loss': , : 训练过程中计算显示的损失函数,取值Logloss、CrossEntropy、Precision、Recall、F、F1、BalancedAccuracy、AUC等等
'eval_metric': , : 用于过度拟合检测和最佳模型选择的指标,取值范围同custom_loss
'iterations': , : 最大迭代次数,默认500. 别名:num_boost_round, n_estimators, num_trees
'learning_rate': , : 学习速率,默认0.03 别名:eta
'random_seed': , : 训练的随机种子,别名:random_state
'l2_leaf_reg': , : l2正则项,别名:reg_lambda
'bootstrap_type': , : 确定抽样时的样本权重,取值Bayesian、Bernoulli(伯努利实验)、MVS(仅支持cpu)、Poisson(仅支持gpu)、No(取值为No时,每棵树为简单随机抽样);默认值GPU下为Bayesian、CPU下为MVS
'bagging_temperature': , : bootstrap_type=Bayesian时使用,取值为1时采样权重服从指数分布;取值为0时所有采样权重均等于1。取值范围[0,inf),值越大、bagging就越激进
'subsample': , : 样本采样比率(行采样)
'sampling_frequency': , : 采样频率,取值PerTree(在构建每棵新树之前采样)、PerTreeLevel(默认值,在子树的每次分裂之前采样);仅支持CPU
'random_strength': , : 设置特征分裂信息增益的扰动项,用于避免过拟合。子树分裂时,正常会寻找最大信息增益的特征+分裂点进行分裂,此处对每个特征+分裂点的信息增益值+扰动项后再确定最大值。扰动项服从正态分布、均值为0,random_strength参数值会作为正态分布的方差,默认值1、对应标准正态分布;设置0时则无扰动项
'use_best_model': , : 让模型使用效果最优的子树棵树/迭代次数,使用验证集的最优效果对应的迭代次数(eval_metric:评估指标,eval_set:验证集数据),布尔类型可取值0,1(取1时要求设置验证集数据)
'best_model_min_trees': , : 最少子树棵树,和use_best_model一起使用
'depth': , : 树深,默认值6
'grow_policy': , : 子树生长策略,取值SymmetricTree(默认值,对称树)、Depthwise(整层生长,同xgb)、Lossguide(叶子结点生长,同lgb)
'min_data_in_leaf': , : 叶子结点最小样本量
'max_leaves': , : 最大叶子结点数量
'one_hot_max_size': , : 对唯一值数量上面就是三个算法的基本使用了。