【面试】一、消息队列:为什么使用消息队列?消息队列有什么优缺点?众多MQ之间互相都有什么区别?
知其然知其所以然
可能有的老哥用过或者了解过消息队列,但是大部分可能还处在为了用而用,并不知道为什么要用,用了之后的好处在哪,缺点在哪,有没有其他的可以代替,那其他MQ都有什么区别。这一部分在面试中也是很重要的。
所以今天来聊聊我们为什么要用消息队列?消息队列有什么优缺点?kafka、acticeMQ、rabbitMQ、rocketMQ之间的区别是什么?知其然知其所以然!
一、用过消息队列吗?为什么要用消息队列?
用过啊,但是是我们老大让我们用的,我只是为了用而用。
(这种话在心里想想就行了,千万别说出来)
题目分析:其实面试官就是想问问你消息队列有哪些使用场景,你之前项目在没有用MQ的时候可能比较麻烦,但是用了之后给你带来了哪些好处,紧接着有好处就要弊端。
那我们就先说一下消息队列常见的三个场景,其实场景还有很多,但是比较核心的有三个:异步处理、流量削峰、解耦
1、解耦
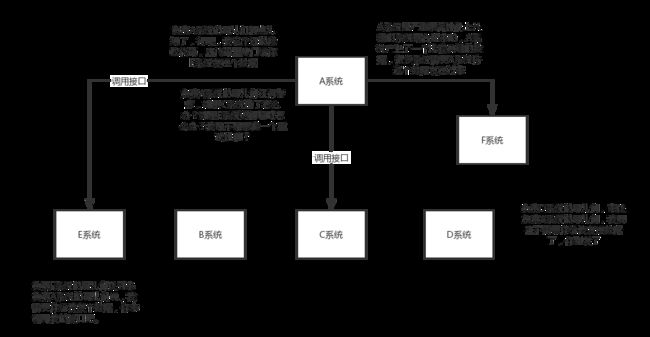
1.1) 不用MQ的系统耦合场景
首先A系统发送个数据到BCD三个系统,接口调用发送,这时因为业务需求新增一个系统E,而且他也需要A生产的数据。然后负责A的哥们还得修改代码专门给E发送。这时候D系统又说A哥,我现在不需要这个数据了,你别给我发了,A又得改代码,此时的A已经濒临崩溃。然后有新增一个系统E,A还得改代码给他发送。这A系统的负责人要是你心态不都炸了?关键A系统还要时时刻刻考虑BCDEF这几个系统如果挂掉了咋办?那我要不要重发?我要不要把消息存起来?这TM的头发都白了啊…
1.2) 使用MQ解耦场景
还是A来生产消息,他生产完消息之后,直接发送到MQ里面,那BCD需要A生产的数据进行业务操作的话,直接去MQ里面获取消费就行了。这时新增一个E,那他自己去MQ里面消费。D不需要这个数据了,就直接取消对MQ消息的消费就好了。用了MQ以后A就不需要去考虑该给谁发送数据了,也不需要维护本身的代码,只需要把消息生产出来发到MQ里面谁要就去拿就好了。是不是?简单干净到我想加班到第凌晨。
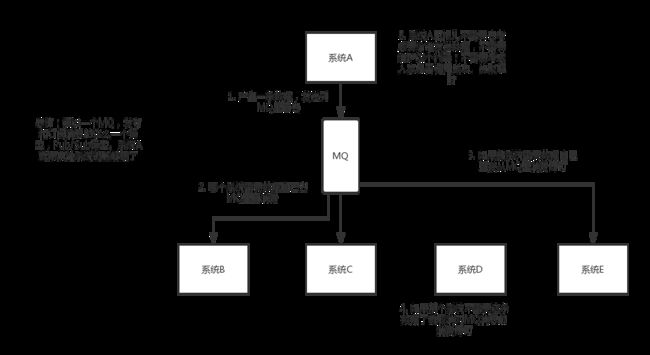
总结:通过一个MQ,发布订阅模型(Pub/Sub模型)。系统A可以和其他系统解耦。
2、异步处理
2.1) 不用MQ的同步高延时请求场景
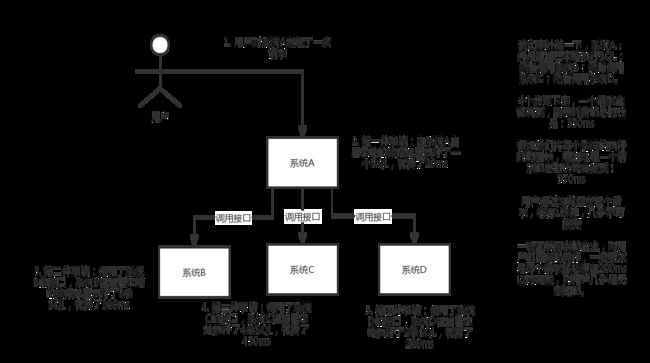
上场的还是ABCD这三位老哥,现在我们有一个用户对A系统发送了请求,A接收到请求之后执行SQL花费了20ms,然后A又调用B的接口,B执行SQL花费300ms,完成之后A又调用C的接口,C执行SQL花费450ms,完成之后A又调用了D的接口,D执行SQL花费了200ms。
我们可以来计算一下这一个请求全部完成,需要970ms,用户通过浏览器发送一个请求要等待1秒钟的时间,用户时不能够接受的。
一般在互联网企业中,对用户的直接操作,一般要求每个请求必须在200ms之内完成的,对用户几乎是无感知的。
2.2) 使用MQ进行异步化之后
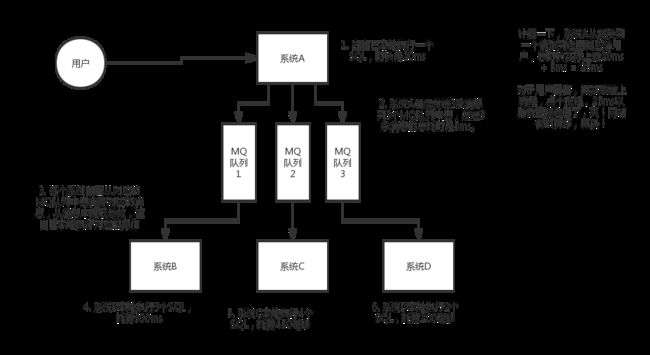
当我们使用MQ之后,A接收到用户的请求后先在本地执行花费20ms,然后又花费了5ms将消息发送到三个MQ队列当中。那么BCD这三个系统自己去消息队列中获取消息进行相对应的业务操作。
其实A系统从接收到请求到返回响应给用户只花了25ms,当他把消息成功发送到消息队列之后就已经响应给用户执行成功了。BCD他们收到消息去处理就好了,A只用走完自己的流程。
对于用户而言点个按钮,眼睛还没来得及眨一下就直接告诉我成功了,牛13!这个网站牛13!这个程序员牛13!
但是有个问题你发现了吗?你A系统的流程走完了,你就不管BCD有没有执行成功?
如果用户点的是个下单按钮,B系统是减库存的,C系统是给用户发送购买成功短信的。D系统给用户加积分的。C和D都执行成功了,唯独B没有成功减库存,那怎么办?找个程序员祭天吗!
虽然别人系统我们没必要去考虑,只需要管好自己的系统就行,但是我们也得知道如何解决。其实就是用到了分布式事务。以后会说。
3、流量削峰
3.1) 没有用MQ时高峰期系统被打死的场景
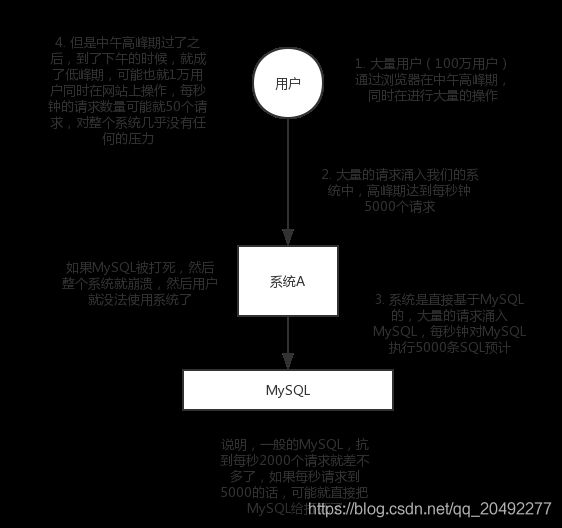
现在大约又100万个用户涌入到你的项目中,高峰期每秒收到5000个请求,如果系统时直接基于MySQL的,那么大量的请求将会直接打到MySQL上。好了,到此为止你已经炸了。
因为在不考虑机器性能的情况下MySQL扛到每秒2000个请求就已经差不多了,你这直接一下给他打到爬都爬不动了凉透了。MySQL都凉了,那你整个系统不就崩溃了吗?然后用户看到了错误页面还得扣着脚丫子喊着垃圾系统。
3.2) 使用MQ进行流量削峰
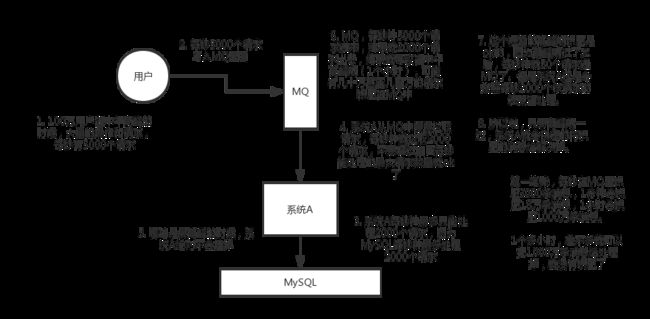
还是100万用户在中午高峰时大量涌入你的项目,每秒达到5000个请求。而这些请求并没有直接打入我们的A系统,而是进入到MQ当中。假设根据MySQ每秒最多处理2000个请求来看,所以系统A每秒最多也只能处理2000个请求。那么A系统就从MQ中每秒拉去2000个请求,只要不超过自己每秒最大处理请求数就OK了。哪怕在最高峰的时候A也不会挂掉。
但是MQ每秒有5000个请求进来,但只有2000个请求出去,结果就导致在高峰期可能有几十万甚至几百万的请求堆积在MQ中。但是高峰期过了之后,每秒进入到MQ的请求就会减少,但是A系统还是每秒2000个请求去拉取处理。所以说只要高峰期一过系统A就会很快速的将堆积的消息给解决掉。
二、消息队列有什么优缺点?
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰
1、架构中引入MQ后可能存在的一些问题
问题一:系统的可用性会降低:
本来你就是A系统调用BCD三个系统的接口就好了,人ABCD四个系统好好的,没啥问题,你偏加个MQ进来,万一MQ挂了咋整?MQ挂了,整套系统崩溃了。
这时那位扣着脚丫子的用户又得大喊垃圾系统了。
问题二:系统的复杂性变高:
怎么保证消息没有重复消费?因为之前A系统就给B发送一条数据就可以了,结果因为系统A和MQ之间出现了些问题,导致A将同一条数据发送了两次,那么消费者也就消费了两条一样的消息。
怎么处理消息丢失的情况?可能A发送消息到MQ中,结果消息在MQ中丢了,导致无法消费。
怎么保证消息传递的顺序性?比如系统A按照顺序发送了三条数据,但是到了MQ中顺序就乱了,就导致消费者拿到的消息的顺序也是乱的。
问题三:一致性问题:
A系统处理完了直接返回成功了,用户都以为你这个请求就成功了;但是问题是,如果BD两个系统写库成功了,结果C系统写库失败了,咋整?你这数据就不一致了。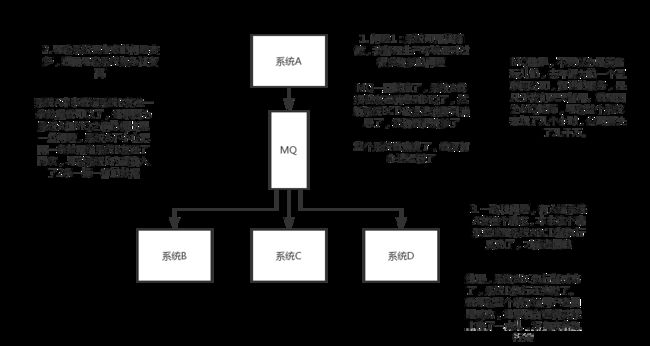
那么这些缺点如何解决以后会说。
三、kafka、acticeMQ、rabbitMQ、rocketMQ之间的区别是什么?
常见的MQ其实就这几种,别的还有很多其他MQ,但是比较冷门的,那么就别多说了
作为一个码农,你起码得知道各种mq的优点和缺点吧。
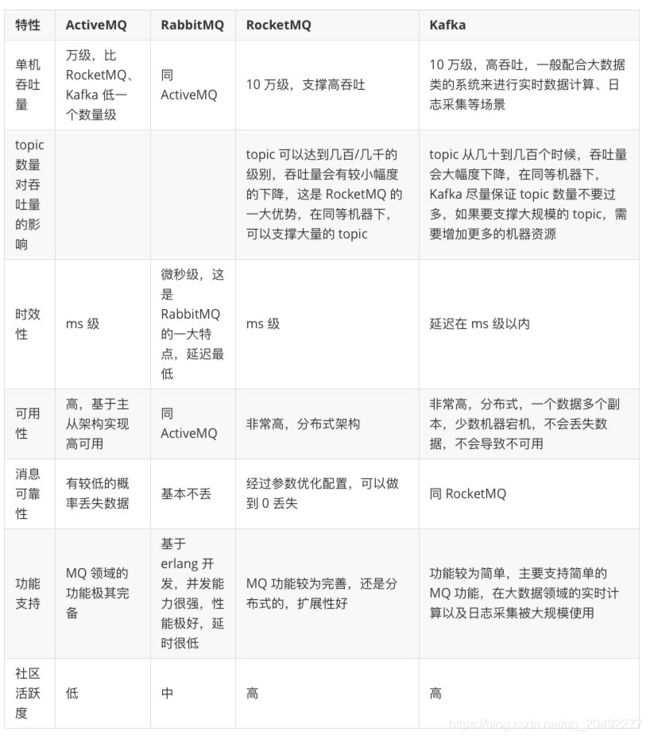
综上所述,各种对比之后,我个人倾向于是:
一般的业务系统要引入MQ,最早大家都用ActiveMQ,但是现在确实大家用的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃,所以大家还是算了吧,我个人不推荐用这个了;
后来大家开始用RabbitMQ,但是确实erlang语言阻止了大量的java工程师去深入研究和掌控他,对公司而言,几乎处于不可控的状态,但是确实人是开源的,比较稳定的支持,活跃度也高;
不过现在确实越来越多的公司,会去用RocketMQ,确实很不错,但是我提醒一下自己想好社区万一突然黄掉的风险,对自己公司技术实力有绝对自信的,我推荐用RocketMQ,否则回去老老实实用RabbitMQ吧,人是活跃开源社区,绝对不会黄
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用RabbitMQ是不错的选择;大型公司,基础架构研发实力较强,用RocketMQ是很好的选择
如果是大数据领域的实时计算、日志采集等场景,用Kafka是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范
为什么要使用MQ等一些基础就说那么多吧,后面还会接着出,这些都是面试时候必问的东西,还是那句话知其然知其所以然,公司不可能只要会用的,如果你不知道使用这个技术会带来哪些缺点你这不是给公司挖坑吗?