2023美赛C题完整论文成品文章分享

已全部完成解题,共4道题目完整原创代码和代码运行教程视频,全保姆攻略↓链接
2023美赛C题完整代码讲解视频分享
报告结果的数量每天都在变化。开发一个模型来解释这种变化,并使用您的模型为2023年3月1日报告的结果数量创建一个预测区间。单词的任何属性是否会影响在硬模式下播放的报告分数百分比?如果是,怎么办?如果没有,为什么不呢?
第一问可以分拆成2个问题:
1、建立一个模型来预测报告的结果数量,并且给出2023年3月1日的报告结果数量。
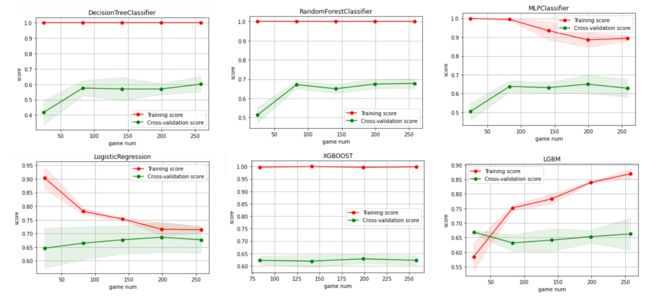
针对第一个问题比较简单,可以采用时间序列预测模型进行预测,例如可以采用传统的arima时间序列预测或者灰色预测,.也可以采用机器学习如xgboost和随机森林预测,深度学习lstm等等。这道题如果想拿高分的话,可以采用深度学习或改进的机器学习来做。
2、分析词语的任何属性是否影响报名人数在困难程度的百分比
这道题的难点是如何提取词语的属性,这道题首先需要提取单词的特征属性,例如单纯的长度:较短的单词通常更容易猜出,因为猜错后可以更快地排除错误的字母,而较长的单词则可能需要更多的猜测和尝试才能找到正确的单词。
单词的常见程度:常见的单词通常更容易猜出来,图为人们更熟悉这些单词,而不常见的单词可能需要更多的猜测和尝试才能找到正确的单词。
单词的结构和拚写:一些单词的结构或拼写可能会使它们更难猜出来,例如拼写不规则的单词或含有不常见字母组合的单词。
单词的语义范围:某些单词有多种含义或语义范围,这可能会增加猜词的难度。例如,单词“bank”既可以指银行,也可以指河岸。
单司的词性和用法:某些单词在不同的上下文中可能具有不同的强义和用法,这可能会增加猜词的难度。例如,单词“fair”可以作形容词,意为“公平的”,也可以作名词,意为“集市”。
在获取到单词的属性后。可以通过差异性检验、相关性分析、线性回归对词语的属性是否影响报名人数在困难程度的百分比进行显著性分析,给出证明结论。
对于给定的未来解决方案单词,在未来的日期,开发一个模型,使您能够预测报告结果的分布。换句话说,预测未来日期(1,2,3,4,5,6,X)的相关百分比。你的模型和预测有哪些不确定性?举一个具体的例子,说明你对2023年3月1日EERIE一词的预测。你对模型的预测有多自信?
这道题也可以拆分为几个问题:
1、建立一个模型,预测未来某一天的(1、2、3、4、5、6、X)的相关百分比
2、分析训练集的表现情况(你的模型和预测有哪些不确定因素?)
3、分析测试集的表现情况(你对你的模型的预测有多大信心?)
4、预测2023年3月1日EERIE这个词的数据。
这道题最好采用深度学习的多序列LSTM时间序列预测,这个模垂可以实现多输入与多输出,模型输入可以是单词的属性,这里我们要可能构建多单词的属性,尽可能覆盖全单词的属性,模型的输出就是这七个输出序列,然后我们分别分析训练集跟测试集的表现情况,用以说明我们的模型有哪些不确定的因素以及预测结果有多大的信心,最后对2023年3月1日案RIE这个词的数据进行预测,另外一种比较low的做法就是模型输入是单词的属性,输出Y为预测未来某一天的(1、2、3、4、5、6、X)的相关百分比的其中一个,然后迭代预测,这意味着要建立7个模型,同时彼此之间没有关联。
开发并总结一个模型,根据难度对解决方案单词进行分类。识别与每个分类相关的给定单词的属性。使用你的模型,EERIE这个词有多难?讨论分类模型的准确性。
这道题也可以拆分为几个问题:Q
1、建立一个模型,对单词的难度进行区分
2、描述模型分类的准确性
3、对单词EERIE进行难度分类
这里我们可以先对难度进行定义,可以先对从(1、2、3、4、5、6、X)的相关百分比的进行综合评价,各个单词难度的综合评价得分,然后。基于这个综合得分进行分档,划分为难易两种程度或难中易三档,这个无所谓,只要能分档就行了,接着再去构建一个分类模型,这个时候就可以花里胡哨炫机器学习或深度学习算法了,例如基于pso-随机森林等等。
列出并描述此数据集的其他一些有趣的特性
对(1、2、3、4、5、6、X)的相关百分比数据进行描述性分析或者其他统计分析展示(组委会逼着你画图呢)
代码预览:
2023美赛C题成品论文
Wordle是纽约时报目前每天提供的流行拼图。玩家尝试通过在六次或更少的尝试中猜测一个五个字母的单词来解决这个难题,每次猜测都会收到反馈。对于这个版本,每个猜测都必须是一个实际的英文单词。不被比赛识别为单词的猜测是不允许的。Wordle越来越受欢迎,该游戏的版本现已支持60多种语言。
纽约时报网站上的Wordle 说明说明,在您提交单词后,图块的颜色会发生变化。黄色方块表示该方块中的字母在单词中,但位置错误。绿色方块表示该方块中的字母在单词中并且位于正确的位置。灰色方块表示该方块中的字母根本不包含在单词中(请参阅附件2)。图1是一个示例解决方案,其中在三次尝试中找到了正确的结果。
对于问题一,报告结果的数量每天都在变化。开发一个模型来解释这种变化,并使用您的模型为 2023 年 3 月 1 日报告的结果数量创建一个预测区间。这个词的任何属性是否会影响报告的在困难模式下播放的分数的百分比?如果是这样,如何?如果不是,为什么不呢?
分析报告结果的统计规律,并根据记录的数量数据,预测其在3月1日的结果。首先我们要对提供的数据进行预处理,如异常值和多指标的去量纲处理,附件包括日期、比赛编号、当天的单词、当天报告分数的人数、困难模式下的玩家人数以及一次、两次、三次、四次猜中单词的百分比、五次尝试、六次尝试或无法解决难题(用 X表示),研究各指标之间的变化规律可以绘制可视化的图表加以辅助。分析指标的统计规律,首先要借助最基本的统计量,如趋势、中位数、方差等等,接着还可以使用配对样本t检验处理连续数据,卡方独立性检验处理离散数据,灰色关联法也可以使用。预测短期内的数量,采用时间序列ARIMA和支持向量机进行预测,并对多种模式进行组合,以提高预测精度,可以进行一个对比。
对于问题二,对于未来日期的给定未来解决方案词,开发一个模型,使您可以预测报告结果的分布。换句话说,预测未来日期 (1, 2, 3, 4, 5, 6, X) 的相关百分比。哪些不确定性与您的模型和预测相关?举一个你对 2023 年 3 月 1 日 EERIE 这个词的预测的具体例子。你对你的模型的预测有多自信?以实际例子预测其分布结果,采用神经网络进行多值预测,提高训练精度及维度。
对于问题三,开发并总结一个模型来按难度对解决方案单词进行分类。识别与每个分类关联的给定词的属性。使用您的模型,EERIE 这个词有多难?讨论分类模型的准确性。这个题很明显是聚类分析问题,考虑常用的K-MEANS聚类分析问题,当然这个题大家都会考虑到这个算法,因此,需要改进创新。对算法进行优化,比如改进的K-MEANS聚类分析,K-means++;二分k-means;k-medoids(k-中心聚类算法);Kernel k-means;ISODATA;Mini Batch K-Means等等,不同算法之间的好坏需要用指标去评估,如:误差平方和(SSE(The sum of squares due to error);"肘"方法(Elbow method)-K值确定;轮廓系数法(Silhouette Coefficient);CH系数(Calinski-Harabasz Index)等。研究多指标之间的关系,首先机器学习方法采用XGBoost为每个指标分配重要性分数构建因子分析-聚类模型,随后进行探索性因子分析对多变量进行降维和可视化,更直观地揭示各指标的差异性。在分类完成之后进行合理性与敏感性的分析,放上计算结果。对EERIE这个词属性,建立判别函数分析分类精度。
对于问题四,列出并描述该数据集的其他一些有趣的特征。
关键词:神经网络、预测、分类、支持向量机