MySQL的事务与索引
注意:文章讲的事务与索引都是只讲了怎么用,没有涉及如何实现
目录
事务(Transaction)
一、概念
二、事务的四大特性(ACID)
1.A(Atomic)原子性-动作不可被再分
2.C(Consistency)一致性⭐⭐
3.I(Isolation)隔离性
4.D(Durably)持久性
总结
三、怎样去使用事务
1.直接使用SQL(第一个角度:SQL怎么使用事务)
1)模拟三大场景
2)事务失败的原因
2.JDBC下(第二个角度:通过JDBC方式使用事务)
1)一次事务的开启,只和一条连接有关系(事务和连接绑定)
2)四个场景
a.有事务且成功,commit
b.没有事务,被动失败(重启服务器)
c.有事务,被动失败
d.有事务,主动失败
四、隔离性
1.解释
2.隔离级别
1)读未提交(追求并发性,完全没有隔离性):看到别的事物未提交的修改数据
2)读已提交:看到别的事物已经提交的修改数据
3)可重复读:一次事务中,看到的值不变(即使别的事物对此值修改且提交了)
4)快照读【并不在标准中】
5)串行性(追求隔离性,数据越正确)
索引(Index)
一、索引的作用
用来提升查询速度
查询效率高的原因
索引的hit和miss
二、索引的优缺点
1.优缺
1)优点:提升查询速度(不是只要建了索引,就能提升)
2)缺点:
2.索引的适用场所
三、explain命令-查看是否用上了索引
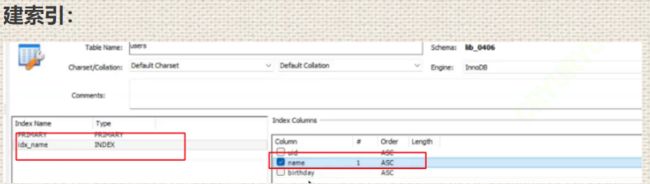
建立索引
事务(Transaction)
一、概念
事务这个单词的指向含义是广泛的,并不一定就指代我们数据库中的事务处理。在狭义上,即业务方(开发者)看来,事务是一个不可再分的业务动作,这个动作最终表达为一条或多条SQL语句。
业务动作(上架、下架、借书)往往是由多条SQL组成。我们的视角应该以业务为基本单位,而不是以SQL为基本单位。基本的业务动作就表现为数据库中的事务(transaction),事务是维护数据的一致性的手段之一。
二、事务的四大特性(ACID)
DBMS(数据库管理系统,即我们用到的mysql系统)只有满足这四大特性,才能称为支持事务功能。
1.A(Atomic)原子性-动作不可被再分
原子性指这个动作不可被再分。不可被再分:如借书时,向借阅记录中插入一条数据,count就需要修改一下减1。不能说是做一半不做了(只把count减了,records没插入;或是records插入了count没减)
2.C(Consistency)一致性⭐⭐
达到一致性的手段:事务(transaction)+约束(constraint)。
DBMS本质是维护数据的一套软件,只是对数据进行增删查改。但是开发者(Devaloper)和DBMS加起来唯一的最高性目标就是维护数据的一致性。
eg:对图书馆系统的books有要求/约束:1.books名称不可重复【通过UQ约束保证】2.0<=count<=total3.total-count=records表中bid的数量;这就叫做一致性。
3.I(Isolation)隔离性
当有多个人操作数据库时,可否做到隔离级别(互相之间认为对方不存在)。最理想的情况下,一个用户在操作数据时,是意识不到其他用户同时也在操作数据的。
4.D(Durably)持久性
数据库给你的承诺,一行插入代码一旦执行成功(mysql告诉你插入成功了),这个数据一定会落到能被持久化保存的地方(就是所谓的硬盘上)。
总结
A、I、D是DBMS承诺做到的,C是DBMS和开发者共同配合做到的【责任划分】

三、怎样去使用事务
我们如何使用事务,即我们和DBMS之间在进行数据交换。
前提:MySQL的innoDB引擎(我们现在建的所有表都支持innoDB引擎,都支持事务)
1.直接使用SQL(第一个角度:SQL怎么使用事务)
-- 直接在sql中敲下start transaction;告诉DBMS一个事务(事务中多条sql)明确开启了,然后开始正常写sql
start transaction;
sql1;
sql2;
sql3;
commit;-- 提交事务,代表事务完成(只有这个完成后,数据修改才真正的落盘(持久化到硬盘上))
-- 第一个事务结束。此时sql123就看做一个整体了,要成功都成功,要失败都失败
sql4; -- 事务中只有一条sql,所以可以省略分界。
start transaction;
sql5;
sql6;
commit;-- 第三个事务结束
-- 注意:主动进行回滚操作(假如sql5正确,sql6错误时,sql5的数据已经插入成功了但是6没有,此时主动执行回滚可以让sql5的数据回退到未插入时)
rollback;
1)模拟三大场景
a.开启事务,一切正常时
数据会被修改成功(所有sql执行成功)
b.模拟:没有事务时,数据库服务器故障的情况
先执行sql1;重启mysql服务器;观察数据:只有sql1执行成功,其他语句23未成功,一致性被破坏。
c.模拟:有事务时,数据库服务器故障的情况
先执行sql1;重启mysql服务器;观察数据:一致性没有被破坏,部分修改的数据被回滚了。
【通过事务保护了原子性-不可被再分】
2)事务失败的原因
事务无论成功或是失败,数据的一致性是不能被破坏的。(成功就会执行commit)
a.被动失败:没有执行commit,所以,事务期间做的部分数据修改都会被回滚(rollback)
1>硬件原因
2>软件原因:DBMS本身的原因(mysql关闭了);我们的原因(比如程序中出现异常)
b.主动失败
我们可以主动要求事务失败(数据回滚)--不去执行commit,而去执行rollback主动让事务失败
2.JDBC下(第二个角度:通过JDBC方式使用事务)
1)一次事务的开启,只和一条连接有关系(事务和连接绑定)
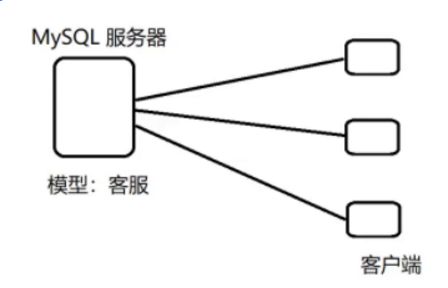
即使是一个客户端,也有多条链接关系。连接(connection)类比成一次通话:

如上,左边人当作服务器,右边两个当作客户端。右边可以用一个或两个电话跟左边人打电话。
2)四个场景
a.有事务且成功,commit
package com.util;
import com.mysql.cj.jdbc.MysqlDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
/**
* @author 美女
* @date 2022/04/09 10:38
**/
public class DButil {
private static final DataSource dataSource;
static {
MysqlDataSource db=new MysqlDataSource();
String url="jdbc:mysql://localhost:3306/java_lib?useSSL=false&characterEncoding=utf-8&serverTimezone=Asia/Shanghai";
db.setUrl(url);
db.setUser("root");
db.setPassword("xxxxxxxx");
dataSource=db;
}
public static Connection connection() throws SQLException{
return dataSource.getConnection();
}
}
package com.wy;
/**
* @author 美女
* @date 2022/04/09 10:34
**/
import com.util.DButil;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 一切成功正常情况下的事务演示
*/
public class Demo1 {
public static void main(String[] args) throws SQLException {
String sql1="insert into records (rid,bid) values (1,1)";
String sql2="update books set count=count-1 where bid=1";
//要使用事务,在同一个事务中,操作sql1和sql2,意味着必须在一条connection完成
try(Connection c= DButil.connection()){
//connection中有一个自动提交autocommit的属性。默认情况下是true(开启状态)
//开启状态下,意味着每一条sql都会被独立的视为一个事务
//我们要让sql1和sql2看作整体,只需要关闭connection的自动提交功能
c.setAutoCommit(false);//关闭自动提交。此时只能进行手动提交了。我们就可以手动控制事务的结束位置
try(PreparedStatement ps=c.prepareStatement(sql1)){
ps.executeUpdate();
}
try(PreparedStatement ps=c.prepareStatement(sql2)){
ps.executeUpdate();
}
//由于我们关闭了自动提交,所以所有的修改还未真实提交落盘(事务还未完成)
//需要让数据落盘
c.commit();//只有加上这句话,才表示事务真正提交成功了
}
}
}b.没有事务,被动失败(重启服务器)
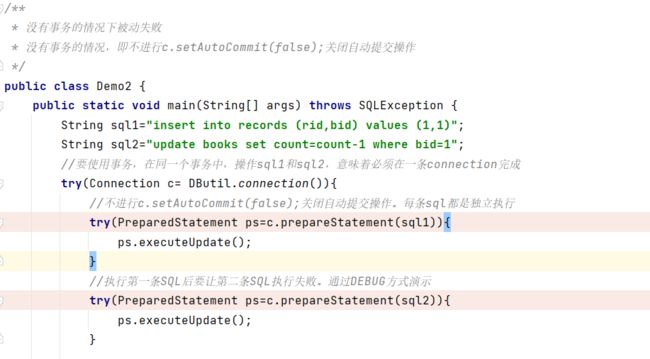
执行第一个断电完第二个断点前把服务器关掉再执行,会执行sql2失败,失败原因是没链接上服务器。此时第一条sql对应的已经改变,第二个sql2对应内容未变。
c.有事务,被动失败
只执行成功了一条sql,但是由于有事务的存在会将sql1回滚
1>服务器异常造成的被动失败(服务器(mysql)关闭)
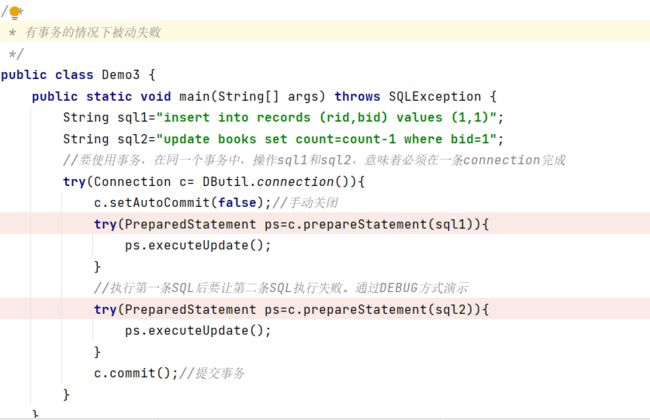
2>由于我们代码中的异常造成的被动失败
package com.wy;
/**
* @author 美女
* @date 2022/04/09 10:34
**/
import com.util.DButil;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 有事务的情况下被动失败
* 我们自己代码错误造成的
*/
public class Demo4 {
public static void main(String[] args) throws SQLException {
String sql1="insert into records (rid,bid) values (1,1)";
String sql2="update books set count=count-1 where bid=1";
//要使用事务,在同一个事务中,操作sql1和sql2,意味着必须在一条connection完成
try(Connection c= DButil.connection()){
c.setAutoCommit(false);//手动关闭
try(PreparedStatement ps=c.prepareStatement(sql1)){
ps.executeUpdate();
}
//执行第一条SQL后要让第二条SQL执行失败。通过DEBUG方式演示
int a=1/0;//此处一定会有除零异常,下面代码就一定不会执行
//我们也没有对除零异常做过catch处理,导致异常交给JVM处理,JVM会终止程序执行
//所以下面步骤都不会再执行。会有sql1成功,sql2失败。没有commit
try(PreparedStatement ps=c.prepareStatement(sql2)){
ps.executeUpdate();
}
c.commit();//提交事务
}
}
}d.有事务,主动失败
package com.wy;
/**
* @author 美女
* @date 2022/04/09 10:34
**/
import com.util.DButil;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 有事务的情况下主动失败
*/
public class Demo5 {
public static void main(String[] args) throws SQLException {
String sql1="insert into records (rid,bid) values (1,1)";
String sql2="update books set count=count-1 where bid=1";
//要使用事务,在同一个事务中,操作sql1和sql2,意味着必须在一条connection完成
try(Connection c= DButil.connection()){
c.setAutoCommit(false);//手动关闭
try(PreparedStatement ps=c.prepareStatement(sql1)){
ps.executeUpdate();
}
try(PreparedStatement ps=c.prepareStatement(sql2)){
ps.executeUpdate();
}
c.rollback();//主动失败-两条sql执行成功了,但是我们rollback让它主动失败回滚了,所以也没有添加数据成功
}
}
}四、隔离性
同时 多个用户【以Connection(连接)的形式来体现】 操作 同一批数据
1.解释
这些用户之间,理想情况下,应该是互相隔离的(互相不知道对方的存在)。但实际中,理想状况无法达到,如果追求真正的理想,就要破坏同时。
举例:学校有且仅有一个饮水机(指代同一批数据),”同一时刻“只能有一个人在使用。在一个时刻,”同时“有许多人想用饮水机,就需要排队去解决。假如n人,每人接水1ms,在1ms的微观角度下,“同一时刻”只有一个人在用,但在nms的宏观视角下,是n个人同时在用。
即“同时”是一个宏观视角下的同时,微观视角下对同一个数据的操作,一次只能一个用户进行,其实并不同时。
如JDBC上开启一个事务,但到commit不执行,同时在workbench上开启事务,会发现执行不下去,卡住running,如下:
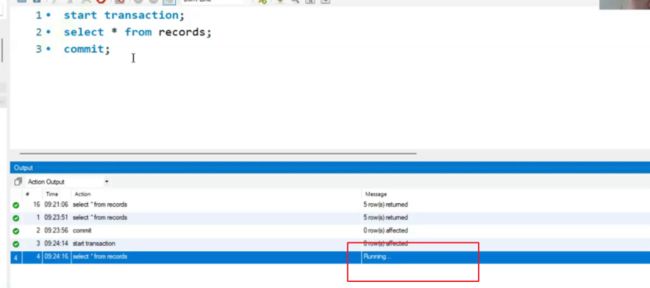
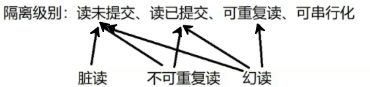
隔离性的理想情况并不能达到,实际上追求真正的隔离性,是以牺牲并发性(真的同时)为代价的。所以SQL标准制定了隔离级别(isolation level)【事先规定的几种情况】:
2.隔离级别

1)读未提交(追求并发性,完全没有隔离性):看到别的事物未提交的修改数据
read uncommited,多个同时在执行的事务,可以读取到(看到)其他事务,还正在处于数据未提交时的数据修改(完全没隔离)。
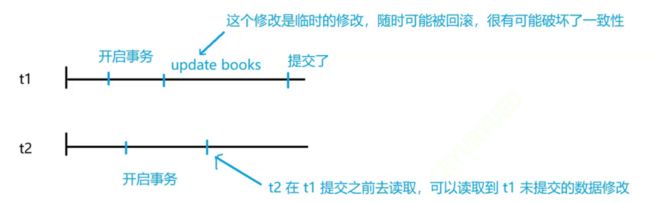
相当于t2读到了“脏数据”(dirty data),这种副作用被称为脏读(dirty read)
2)读已提交:看到别的事物已经提交的修改数据
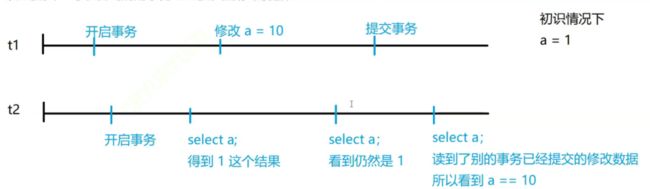
在同一个事物t2中,可能出现 多次读取同一份数据,得到的结果不同,这个副作用被称为不可重复读【没有脏读了,上面那个既有脏读也有重复读】
3)可重复读:一次事务中,看到的值不变(即使别的事物对此值修改且提交了)
保证了在一次事务过程中(只要没有提交或者回滚),看到的值是不会变化的(即使有别的事务对这个数据做过修改,并且已经提交了)【只针对已有数据做保护,但未对新添加数据做保护】
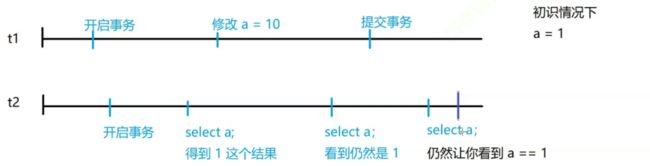
传统意义上的可重复读仍然有一个副作用—幻读(phantom read)
ps:对幻读的理解:
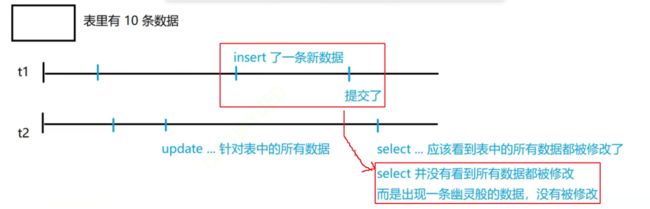
4)快照读【并不在标准中】
(snapshot read)—用来让大家理解的,不是标准中存在的隔离级别
快照读连幻读的副作用也没有了!!目前来说基本没有副作用。MySQL中的“可重复读”可以看作实际上是“快照读” --MVCC。即MySQL的默认情况下,隔离级别就是可重复读
5)串行性(追求隔离性,数据越正确)
可串行化(serializable):每个事务,必须排队执行,一次一条事务(一条事务完才开启下一个事务。宏观视角上,仍然可看作“同时”,并发性非常差)
索引(Index)
索引有很多的分类角度,主键也是索引、唯一键也是索引,但这些都有专门的用途,不做探讨,此处的索引就是普通索引。

一、索引的作用
用来提升查询速度
假设两张表users_with_index、users_without_index,第一张带了索引第二张没带索引,同时都放了1000w条数据。两张表都有字段name_a,name_b,且内容存的都一样,唯一区别是表users_with_index的name_a有索引。观察查询速度:
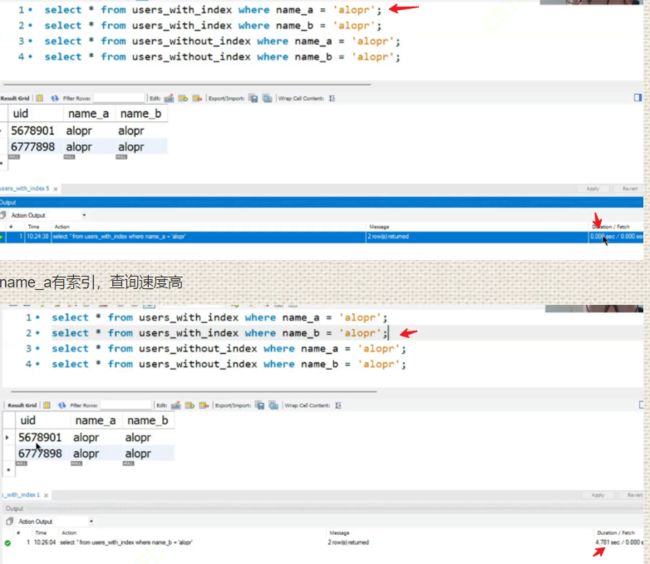
name_b没有索引,查询速度将近五秒,查询效率低
查询效率高的原因
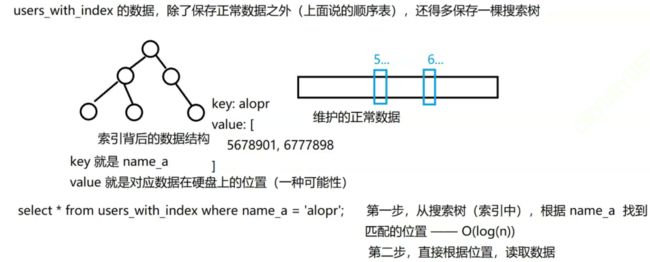
只要提到搜索(查询),大家应该想到的数据结构:1.哈希表2.搜索树、3.跳表(了解)。表中的数据,像一个“顺序表”一样分布在硬盘中(按照uid(主键)排序)【注意:这种分布是一种可能性】,name_a,name_b在表中是无序的,所以要找到name_a=?或name_b=?,只能进行暴力查找(遍历查找),把所有的元素都遍历一遍,找到符合条件的元素(本身就是O(n),+数据存储在硬盘上,会使性能差),性能非常差。
为了提升查询速度,建立了一棵搜索树(当作二叉树理解,实际不是二叉树),搜索树的key就是name_a。但这也意味着with_index除了保存正常数据外,还得多保存一棵搜索树:

索引的hit和miss
with_index的name_a就叫索引命中(hit),name_b就叫miss(更多情况下描述的是表中有但未用上,索引without_index中的两条其实不算miss)
二、索引的优缺点
1.优缺
1)优点:提升查询速度(不是只要建了索引,就能提升)
2)缺点:
1.造成空间的使用增加

2.造成修改的性能会下降(增、删、改)
没有索引时,只需要修改原始数据就行了;有索引时,不但要修改原始数据,还得修改索引结构。所以:使用索引虽然能够带来一些方面的优势,但他不是没有代价的。
2.索引的适用场所
1.数据量得有一定规模【O(logn)远小于O(n)才有很大的价值】
2.尽量针对查询的很多,修改较少的表考虑索引
3.只针对频繁被查询的字段建立索引
三、explain命令-查看是否用上了索引
通过explain命令可以精确知道是否用到了索引,看扫描了多少行就知道是否用上了索引
eg1:
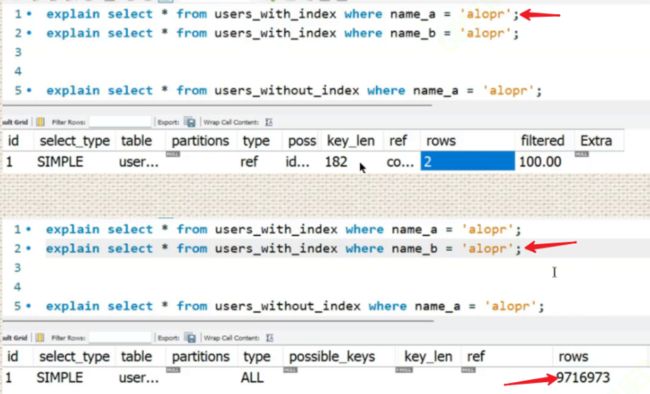
观察知:1行语句用到了索引,2行语句没有用到索引。
eg2:
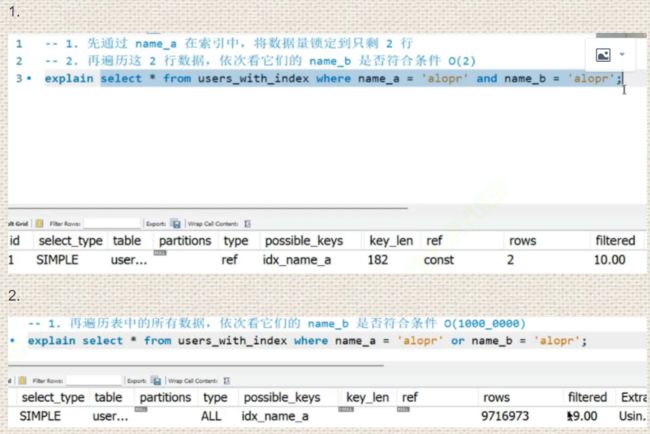
1.的语句先查找了name_a,筛出来两行,然后再找b只用在两行上找,所以用到了索引。但是2.中虽然name_a只用扫描两行,然而name_b找还得扫描全部,本质上还得扫描全表,所以就不会使用索引。
建立索引