专栏 | 解析“全闪对象存储”(二)
在上一节“对象存储的来龙去脉”中,我们介绍了驱动存储系统进化的要素,对象存储的起因、发展方向和特点。
本节,我们结合对象存储的使用场景,阐述对象存储的应用。
第 1 则
– 对象存储和非结构化数据 –
我们知道,对象存储是为了解决大规模非结构化数据存储的痛点而诞生的。所以,对象存储非常适合大量文档、图片、视频存储和处理的场景,包括媒体、备份/归档、视频监控、卫星/气象/地质数据、物联网、大数据、数据湖等等。这些场景的基本要求都是低成本、高性能的存取和处理大量的文档数据,同时,在文件大小、数量、IOPS性能等方面的侧重点不同。比如,媒体、备份/归档、视频监控场景一般都是大文件,要求高吞吐能力;卫星/气象/地质数据、物联网场景可能会有大量小文件,要求大量小文件存储和检索的高性能;大数据、数据湖场景的要求则更全面,包括大量小文件存储能力、综合性能、异构数据接入能力。
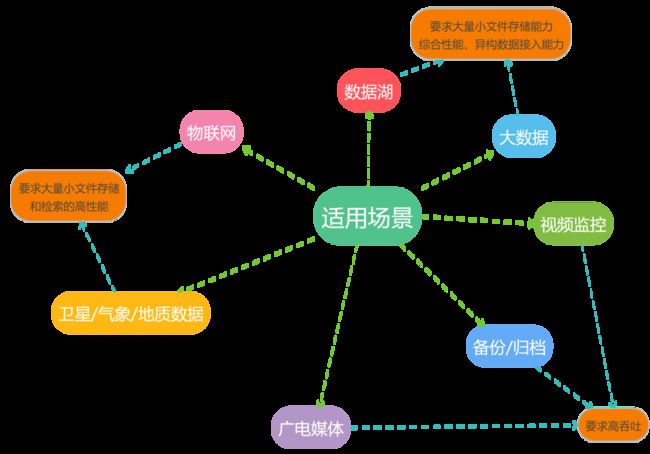
在对象存储大规模应用之前,大部分非结构化数据是保存在以NAS为代表的廉价、简便的存储系统上。对象存储系统必须要考虑如何兼容旧的存储系统和应用系统。在一个很长的产品替代期间,新部署的对象存储系统必须能同时适配新、旧数据和应用。这就需要存储网关和存储纳管系统。
以视频监控行业的存储为例。年代比较老的视频监控系统大部分用NAS存储数据。对象存储系统相比NAS系统,有可靠性高、扩展性好、成本低、全局命名空间、易于数据处理等诸多优势。但要用对象存储替代NAS存储,而不修改应用系统(只支持NAS协议),则需要通过NAS转对象存储网关。同时,旧的NAS存储系统和新的对象存储系统会在一段时间周期内并存,需要统一纳管、数据导入(NAS数据导入对象存储)等功能。
在老版本的大数据系统中使用对象存储,也需要部署HDFS转对象网关。新版本的大数据系统可直接使用S3兼容的对象存储。
第 2 则
– 对象存储和云 –
对象存储不仅仅是解决了海量非结构化存储的难题,进一步,还成为云存储的标准。
云存储发展到今天,主要目标是给基于容器、微服务架构的云端应用提供敏捷、高可用、可靠、安全的存储。
从数据和服务的可用性层面看,云存储具备以下特点:

极高的可靠性
相比传统存储,云应用对数据可靠性的标准大大提高。比如,公有云存储的可靠性标准可达99.99999999%
极高的可用性
相比传统存储,云应用对存储服务可用性的标准非常高。比如,公有云存储的可用性标准可达99.995%
优良的弹性
按需存储 - 不用预先分配大量的资源,而是动态供给
应存尽存 - 应用可以存储任意多的数据,不需要为此修改程序、扩容和中断服务
性能弹性 - 性能线性、敏捷的水平扩展;在业务高峰期,要求迅速的启动更多的服务资源,业务请求回落,回收资源
多租户
租户的资源分配可依照策略进行,达成不同租户数据的安全、可用性和性能隔离
从数据的应用层面看,云存储管理数据的整个生命周期。
数据的产生
从云外导入,或在云内产生
压缩、去重
配额、QoS
数据的安全、共享、检索
安全合规(多版本;加密;日志审计、法规依从;WORM…)
授权、访问控制
标签检索
数据的流转
生命周期
分层
复制和迁移
云存储包括块存储、文件存储和对象存储。其中只有对象存储,是最符合云原生规范的,能最好的达成云存储数据的可靠性、可用性、弹性、多租户、全生命周期管理。对象存储,是云存储的基石和未来。
第 3 则
– 对象存储和数据湖 –
大量数据存储的用途主要是数据分析。基于大数据的数据分析、机器学习、智能化是未来数字化的方向。但是,当前大数据处理系统存在数据源分散、信息系统孤岛等问题,导致数据处理的困难和低效。数据湖是为了解决信息孤岛问题,统一高效处理数据而诞生的。
数据湖是一个架构体系。通过数据湖可以快速、安全合规的存储、处理、分析海量的数据;以数据为导向,通过接口和外部的计算资源交互集成,实现任意来源、任意速度、任意规模、任意类型数据的获取、存储和全生命周期管理。
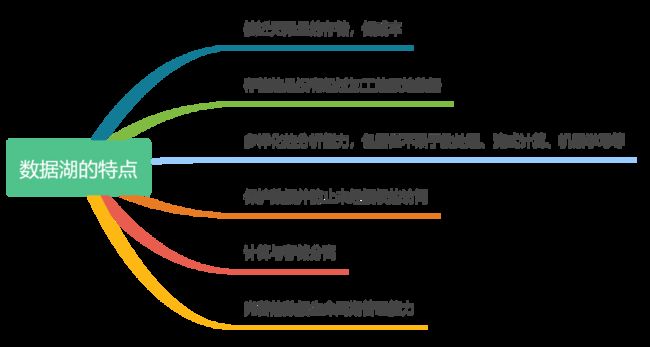
有了数据湖,数据分析系统不用在不同的数据仓库和文件存储之间进行频繁切换,也不需要重复的写抽取、加载的逻辑,极大提升了效率。
数据湖的存储依托于S3兼容的对象存储,S3是数据湖最重要的一部分, 这缘于其强大的特性:
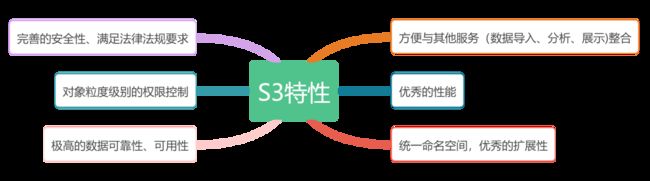
亚马逊云计算服务(AWS)明确的将S3存储作为数据湖的底座,数据流转的中枢。S3兼容的对象存储,是数据湖存储的不二选择。
以上内容就是关于对象存储使用场景的解读,下一篇我们将从对象存储的实现方式及对象存储的未来展开描述,敬请期待!