04期:领域驱动设计与微服务
这里记录的是学习分享内容,文章维护在 Github:studeyang/leanrning-share。
如何理解领域驱动设计?
随着微服务的兴起,你一定听说过领域驱动设计 DDD(domain-driven design),但是如果把它当成一个术语来看,似乎有点抽象。这到底是个什么玩意?
别急,你肯定还听说过测试驱动开发(TDD, Test-driven development)吧?
这是个什么概念呢?就是说开发的过程中要测试先行,倡导先写测试程序,然后编码实现。开发是目的,测试是辅助,所以叫做测试-驱动-开发,我们应该把它拆成 3 个术语来理解。
所以,对于领域驱动设计,设计是目的,领域才是辅助。想要设计一个软件,但是由于业务太过复杂,设计过程难以进行。这时,使用领域的思想来辅助设计。
微服务应该拆多小?
如果你是业务架构师,你在设计过程中会遇到哪些难题呢?我想你面临的第一个问题就是:微服务到底应该拆多小?
有人说:“微服务嘛,就是要越小越好!”
这时运维可能要跳出来打你了,微服务如果拆分过度,导致项目复杂度过高,不仅运维维护这些服务耗费人力,太小的微服务也占用了资源。
那是否有合适的理论或设计方法来指导微服务设计呢?
答案就是 DDD。
DDD 是一种处理复杂领域的设计思想,包括两部分,战略设计和战术设计。战略设计就是辅助建立业务领域模型,划分领域边界,建立限界上下文(DDD 的专业术语,下文会解释)。
战术设计则从技术视角出发,侧重于领域模型的技术实现,完成软件开发和落地,包括微服务代码架构模型的设计和实现。
DDD 思想是如何指导微服务拆分的呢?可以分为三步:
第一步,罗列业务场景,找出领域实体对象。
第二步,根据领域实体间的业务关联,将相关的实体组合形成聚合。它们属于同一个微服务。
第三步,根据语义边界,将多个聚合划定在一个限界上下文内,形成领域模型。这一层边界就是微服务的边界。
DDD 领域的思想
在研究复杂领域问题时,DDD 会按一定的规则将业务领域进行细分,这跟自然科学的研究方法类似。
当人们在自然科学研究中遇到复杂问题时,通常的做法就是将问题按一定的规则进行细分,再针对细分出来的问题子域逐个深入研究,当所有问题子域完成研究时,我们就建立了全部领域的完整知识体系了。
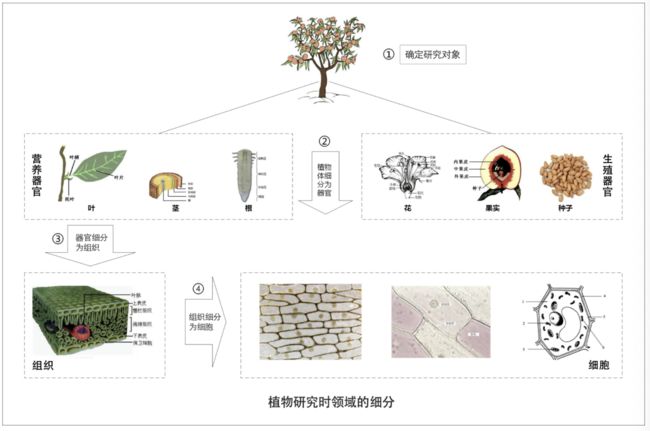
举个例子:假如我们要研究一颗桃树。按照器官的不同分为营养器官和生殖器官,对营养器官进一步细分,分为叶,茎、根,对生殖器官进一步分为花、果实、种子。
对器官进一步细分,将器官分为组织。对组织进一步细分,将组织细分为细胞。细胞就是我们要研究的最小单元。细胞之间的细胞壁确定了单元的边界,也确定了研究的最小边界。
子域
将桃树细分成了六个子域:根、茎、叶,花、果实、种子。子域再按照重要程度进行划分,分为核心域、通用域、支撑域。
决定产品和公司核心竞争力的子域是核心域;没有太多个性化的诉求,同时被多个子域使用的是通用域;既不包含决定产品和公司核心竞争力的功能,也不包含通用功能的子域,它就是支撑域。
需要注意的是,核心域要根据公司的发展战略及业务的实际情况来确定。
举例来说,如果这颗桃树的主人是一名园丁,那他关注的就是桃花盛开,春色满园,所以花就是核心域。如果这颗桃树的主人是一名果农,那他关注的就是桃子质量、产量,所以果实就是核心域。
限界上下文
我们知道语言都有它的语义环境,为了避免同样的概念或语义在不同的上下文环境中产生歧义,DDD 在战略设计上提出了“限界上下文”这个概念,用来确定语义所在的领域边界。
举个例子:下图中的两个账户,光凭名字我们根本无法区分,只有通过它们所在的限界上下文我们才能看出它们之间的区别。
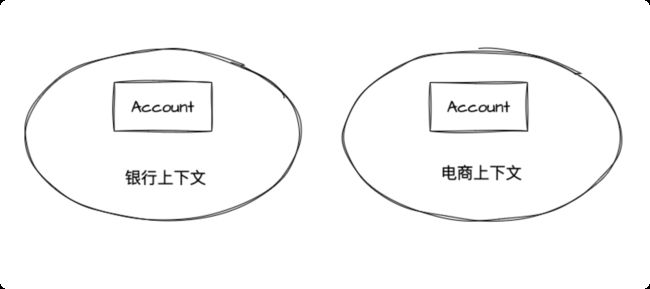
再比如,电商领域的商品在不同的阶段有不同的术语,在销售阶段是商品,而在运输阶段则变成了货物。同样的一个东西,由于业务领域的不同,赋予了这些术语不同的涵义和职责边界。
一个限界上下文就可以拆分为一个微服务,这个边界使得一个概念在这个边界内没有二义性。
实体
总结来说有四种形态。
第一,实体的业务形态:在战略设计时,领域模型中的实体是多个属性、操作或行为的载体。
第二,实体的代码形态:在代码模型中,实体的表现形式是实体类,这个类包含了实体的属性和方法,以及核心业务逻辑。
DDD 强调“设计即代码”。对于“注射流感疫苗”这个业务用例,当团队讨论到业务模型时,他们会说:“护士给病人注射标准剂量的流感疫苗。”
传统代码的表现形式是这样的:
public void shot() {
patient.setShotType(ShotTypes.TYPE_FLU);
patient.setDose(dose);
patient.setNurse(nurse);
}
DDD 思想的代码表现形式是:
public void shot() {
Vaccine vaccine = vaccines.standardAdultFluDose();
nurse.administerFluVaccine(patient, vaccine);
}
很明显,第二类代码更容易理解的多。
第三,实体的运行形态:实体以 DO(领域对象)的形式存在,每个实体对象都有唯一的 ID。我们可以对一个实体对象进行多次修改,修改后的数据和原来的数据可能会大不相同。但是,由于它们拥有相同的 ID,它们依然是同一个实体。
第四,实体的数据库形态:在领域模型映射到数据模型时,大多数情况下实体与持久化对象是一对一。
值对象
值对象是 DDD 领域模型中的一个基础对象,它跟实体一样,都包含了若干个属性,它与实体一起构成聚合。
- 值对象的业务形态。
本质上,实体是看得到、摸得着的实实在在的业务对象,实体具有业务属性、业务行为和业务逻辑。而值对象只是若干个属性的集合。
- 值对象的代码形态。
public class Person {
private Integer id;
private String name;
private Address address;
}
private class Address {
private String province;
private String city;
private String county;
}
我们看一下上面这段代码,Person 这个实体有若干个单一属性的值对象,比如 id、name 等属性;同时它也包含多个属性的值对象,比如地址 address。
- 值对象的运行形态。
实体实例化后的 DO 对象的业务属性和业务行为非常丰富,但值对象实例化的对象则相对简单。
- 值对象的数据库形态。
在领域建模时,我们可以将部分对象设计为值对象,保留对象的业务涵义,同时又减少了实体的数量;在数据建模时,我们可以将值对象嵌入实体,减少实体表的数量,简化数据库设计。
有些场景中,地址会被某一实体引用,它只承担描述实体的作用,并且它的值只能整体替换,这时候你就可以将地址设计为值对象,比如收货地址。而在某些业务场景中,地址会被经常修改,地址是作为一个独立对象存在的,这时候它应该设计为实体,比如行政区划中的地址信息维护。
聚合和聚合根
举个例子。社会是由一个个的个体组成的,我们每一个人就是一个个体。随着社会的发展,慢慢出现了社团、机构、部门等组织,我们也从个人变成了组织的一员,在组织内,大家协同工作,朝着更大的目标,发挥出更大的力量。
领域模型内的实体和值对象就好比个体,而能让实体和值对象协同工作的组织就是聚合,它用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性。
如果把聚合比作组织,那聚合根就是这个组织的负责人。聚合根也称为根实体,它不仅是实体,还是聚合的管理者。
在聚合之间,通过聚合根 ID 关联引用,如果需要访问其它聚合的实体,就要先访问聚合根,再导航到聚合内部实体,外部对象不能直接访问聚合内实体。
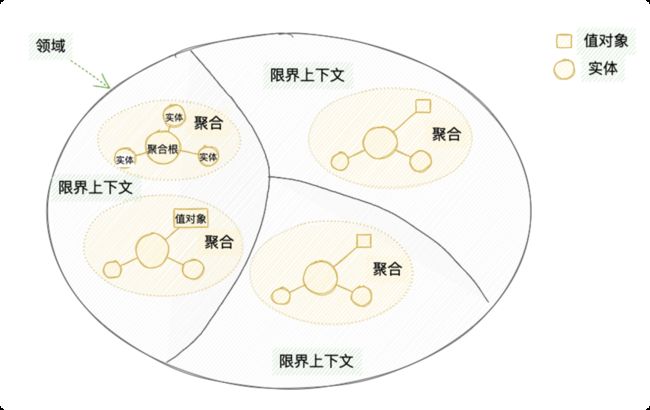
最后,我用下图来总结一下领域、限界上下文、实体、值对象、聚合、聚合根。

封面

相关文章
也许你对下面文章也感兴趣。
- 学习分享(第3期):你所理解的架构是什么?