Java虚拟机结构(内存,类加载器,执行引擎)
- JVM背景知识
- Java虚拟机结构
- 1 内存结构运行时数据区
- 11 堆
- 12 方法区
- 13 程序计数器
- 14 虚拟机栈
- 15 本地方法栈
- 16 运行时常量池
- 17 堆方法区栈的内存关系
- 1 内存结构运行时数据区
- 类加载子系统
- 1 JVM何时加载类
- 2 如何加载类
- 21 加载
- 22 类对象
- 221 获取类对象的三种方式
- 221类对象的常用方法
- 23 验证
- 24 准备
- 25 解析
- 26 初始化
- 字节码执行引擎
- 1 即时编译器JIT
- 参考
1. JVM背景知识
1995年,Java诞生于Sun公司。目标:Write Once, Run Anywhere。
2006年,Sun宣布Java开源,并在随后1年,陆续将JDK的各部分在GPL v2协议下公开源码,并建立OpenJDK组织,对源码进行管理。
2009年,Oracle收购Sun公司。
虚拟机并不是只有一种,很多公司都有各自的实现方案。目前最出名的,是传说中的 三大虚拟机: Oracle JRocket, Oracle HotSpot, IBM JVM。
Java虚拟机的生命周期
java程序运行在java虚拟机之上,在同一台机器上运行N个程序(进程),就会有N个运行中的Java虚拟机。
2. Java虚拟机结构
每一个Java虚拟机都由一个类加载器子系统(class loader subsystem)和执行引擎(execution engine)组成。
类加载器子系统负责加载程序中的类型(类和接口)。执行引擎负责执行被加载类中包含的指令。
虚拟机跑起来,当然需要内存,我们称为:运行时数据区(Runtime Data Area)。
三部分的关系如下图所示:
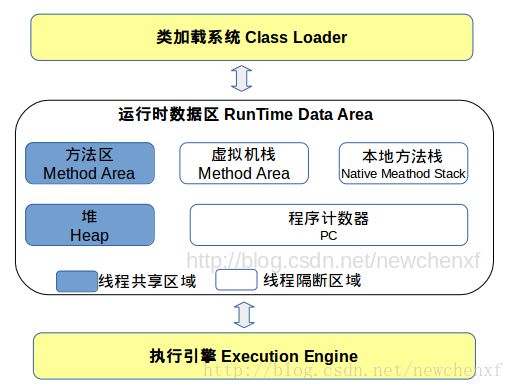
2.1 内存结构(运行时数据区)
2.1.1 堆
所有线程共享,唯一的目的就是存放实例对象。垃圾收集器(Gabage Collector),基本上也指的是回收堆的实例对象(有些虚拟机可能包括方法区),所以堆也称为GC堆。
2.1.2 方法区
所有线程共享,类加载器加载的类,就放在这里(当然,不是把文件直接加载,而是要解析转换的,具体看后文的类加载器)。
当两个线程同时需要加载一个类时,只有一个类会请求ClassLoader加载,另一个线程会等待。故可以确保只加载一次。
虽然Java虚拟机规范把方法区描述为堆的 一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
方法区加载的类,会包括如下信息:
类及其父类的全限定名(java.lang.Object没有父类)
类的类型(Class or Interface)
访问修饰符(public, abstract, final)
实现的接口的全限定名的列表
常量池 (见2.1.6)
字段信息
方法信息 (会整合为方法表,以供快速访问)
除常量外的静态变量
ClassLoader引用
Class引用
2.1.3 程序计数器
线程私有(每个线程都有一个程序计数器)
2.1.4 虚拟机栈
Java Virtual Machine Stacks,线程私有,生命周期与线程相同,描述的是Java方法执行的内存模型:每一个方法执行的同时都会创建一个栈帧(Stack Frame),用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法的执行就对应着栈帧在虚拟机栈中的入栈,出栈过程。
一个线程中方法调用路径可能很长,很多方法都处于执行状态。对于执行引擎来说,只有处于栈顶的栈帧才是有效的,称为当前栈帧(Current Stack Frame),与之相关联的方法称为当前方法(Current Method)。
2.1.5 本地方法栈
如果说虚拟机栈用于执行java方法,那本地方法栈,就是用于执行java native 方法。不过虚拟机规范并没有强制要求本地方法栈,必须执行native方法,各种虚拟机可以自由实现。像Sun Hotspot虚拟机,就把两个栈合二为一。
2.1.6 运行时常量池
Java中的常量池,实际上分为两种形态:静态常量池和运行时常量池。
静态常量池,即*.class文件中的常量池,class文件中的常量池不仅仅包含字符串(数字)字面量,还包含类、方法的信息,占用class文件绝大部分空间。
运行时常量池,则是JVM虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。
可以通过 javap命令,如javap -verbose Test.class 来查看一个类的常量池。
如以下源码的常量池:
public class Test {
private static final int intValue1 = 100;
private String strValue1 = "chenxf";
public int fooMeathod(int param) {
return param + 1;
}
} 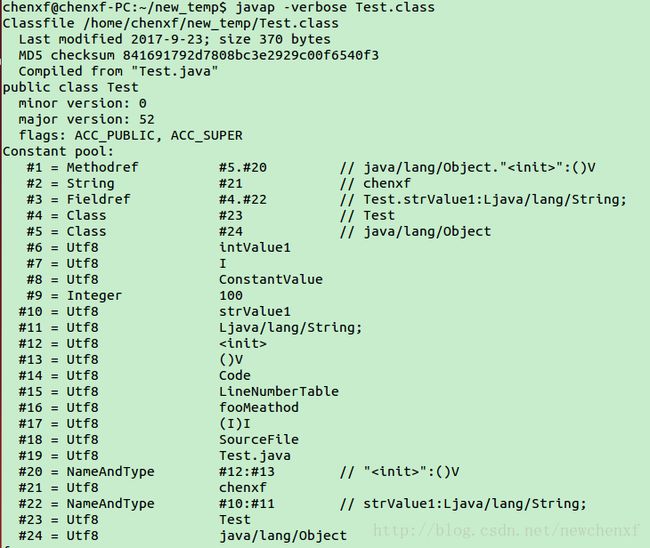
可以看到,除了必然出现的”100”, “chenxf”,还有函数名,类名,字段名等信息。
当然,对程序员来说,比较关心的,是代码写的字符串常量。其他的,大部分是JVM才操心。
就以下测试代码有助于理解常量池中的字符串。
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hel" + "lo";
String s4 = "Hel" + new String("lo");
String s5 = new String("Hello");
String s6 = s5.intern();
String s7 = "H";
String s8 = "ello";
String s9 = s7 + s8;
System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // true
System.out.println(s1 == s4); // false
System.out.println(s1 == s9); // false
System.out.println(s4 == s5); // false
System.out.println(s1 == s6); // true首先,==操作符,比较的是两个字符串的引用地址,并不是比较内容,比较内容是String.equals()。
s1 == s2这个非常好理解,因为编译时,”Hello”会作为字符串常量,放在常量池。s1和s2都指向常量池的”Hello”(指向同一个内存地址),所以肯定相等。
s1 == s3比较坑,s3虽然是动态拼接出来的字符串,但是所有参与拼接的部分都是已知的字面量,在编译期间,这种拼接会被优化,编译器直接帮你拼好,因此String s3 = “Hel” + “lo”;在class文件中被优化成String s3 = “Hello”;,所以s1 == s3成立。
s1 == s4当然不相等,s4虽然也是拼接出来的,但new String(“lo”)这部分不是已知字面量,是一个不可预料的部分,编译器不会优化,必须等到运行时才可以确定结果,结合字符串不变定理,鬼知道s4被分配到哪去了,所以地址肯定不同。
s1 == s9也不等,虽然s7、s8在赋值的时候使用的字符串字面量,但是拼接成s9的时候,s7、s8作为两个变量,都是不可预料的,编译器毕竟是编译器,不可能当解释器用,所以不做优化,等到运行时,s7、s8拼接成的新字符串,在堆中地址不确定,不可能与方法区常量池中的s1地址相同。
s4 == s5不等,毕竟2个都有new分配对象,运行时才确定地址,所以肯定各自不同。
s1 == s6也比较坑,intern方法会尝试将Hello字符串添加到常量池中,并返回其在常量池中的地址,因为常量池中已经有了Hello字符串,所以intern方法直接返回地址,所以会相等。
由此得出结论:
运行时常量池中的常量,基本来源于各个class文件中的常量池。
程序运行时,除非手动向常量池中添加常量(比如调用intern方法),否则jvm不会自动添加常量到常量池。
2.1.7 堆/方法区,栈的内存关系
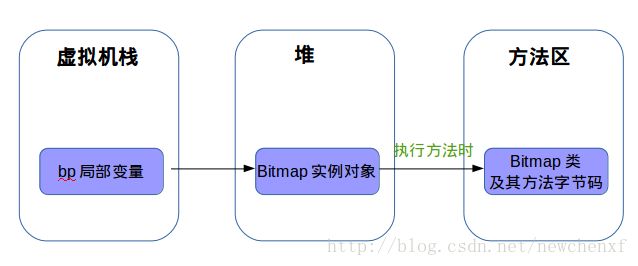
从以下代码,就能明白:
public static MemoryTest {
private int count = 0;//count属于对象的实例变量,在堆分配
private static name = "Sync";//"Sync"编译阶段在class文件的静态常量池,加载后,会放到方法区的运行时常量池。name是static,属于对象的类型变量(所有实例对象共享一个name),或者说是类变量,故在方法区分配,初始化时,指向常量池的"Sync"。
private void fooMeathod(boolean flag) {//方法本身的字节码在方法区,flag变量,运行时,在虚拟机栈分配
boolean myFlag = flag;//myFlag在虚拟机栈分配
Bitmap bp = new Bitmap();//reference变量bp在虚拟机栈分配,Bitmap对象在堆分配,bp指向Bitmap对象的堆地址。
}
}画个图,可以清晰看到堆,栈,方法区的具体分工:
3. 类加载子系统
3.1 JVM何时加载类
以下五种情况,会触发加载类:
1) 创建新对象(new),设置/读取某类的static字段(putstatic/getstatic),或调用某类的静态方法(invokestatic)这四条指令时,如果该类没有初始化,则初始化。
2) 当初始化一个类时,父类没有初始化,则先初始化父类。
3) 当虚拟机启动,需要执行main()的主类,JVM首先初始化该类。
4) 使用java.lang.reflect包得方法进行反射调用的时候,如果该类没有初始化,则初始化。
5) JDK 1.7的动态语言支持时(使java也可以像C语言那样将方法作为参数传递),如果java.lang.invoke.MethodHandle实例最后的解析结果REF_getStatic、REF_putStatic、REF_invokeStatic的方法句柄,并且这个方法句柄所对应的类没有进行过初始化,则初始化。
3.2 如何加载类

类加载包含以上5个阶段,验证,准备,解析,又统称为链接阶段。
3.2.1 加载
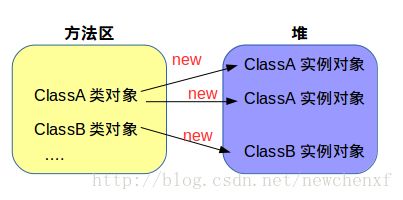
前2步没啥好说的,主要是第三步,注意Class对象与我们通常讲的堆分配的对象不是一回事。我们姑且把两者称为 类对象,和 实例对象。
两者区别:
类对象在方法区,且仅有一个;
实例对象在堆,可以有N个。
3.2.2 类对象
类对象有且只有一个,因为加载类,只需加载一次。如果有2个线程同时触发去加载,则有同步机制,保证只加载一个。举个简单例子,一个进程开始,String类会加载到方法区,方法区就有了一个String 类对象,以后创建任何实例对象的时候,都依据这个类对象去在堆分配实例对象,不再需要加载类。类对象和实例对象的关系如下(一对多,方法区内存 对 堆内存)
类对象除了虚拟机执行new指令会用,我们在代码层面,也可以用。
3.2.2.1 获取类对象的三种方式
(1) 利用实例对象调用getClass()方法获取;
(2) 使用Class类的静态方法forName(),用类的名字获取一个Class实例;
(3) 运用.class的方式来获取Class实例,对于基本数据类型的封装类,还可以采用.TYPE来获取相对应的基本数据类型的Class实例。
对应代码如下:
String str1 = "this is test";
Class cls1 = str1.getClass();
Class cls2 = String.class;
Class cls3 = Class.forName("java.lang.String");3.2.2.1类对象的常用方法
(1) getName()/getSimpleName()
获取这个类的名字
android的app代码经常用它打印log,如
public class TestActivity extends Activity {
private static final String TAG = TestActivity.class.getSimpleName();
....
private void fooFunction() {
Log.i(TAG, "fooFunction enter...");
}
}(2) newInstance()
可以根据存储在字符串中的类名创建对象。例如:
String className = Test"";
Object obj = Class.forName(s).newInstance();(3) getClassLoader()
返回该类的类加载器。
(4)getSuperclass()
返回表示此 Class 所表示的实体(类、接口、基本类型或 void)的超类的 Class。
3.2.3 验证
主要是为了确保class文件的字节流,符合当前虚拟机的要求,不然我随便把一个txt 重命名为class,如果还加载内存,估计系统要崩了。
验证包括如下几种:
(1) 文件格式验证
如
二进制流是否以魔数0xCAFEBABE开头;
主次版本号是否当前虚拟机能处理;
…等等
(2) 元数据验证
如
这个类是否有父类;
这个类是否继承了不该被继承的类;
类中的字段,方法是否与父类有矛盾;
…等等
(3) 字节码验证
对类的方法区进行校验,确保运行时,不会出现危害虚拟机的行为。
如
确保方法体中的类型转换是有效的;
…等等
(4)符号引用验证
用于确保后面的解析能正常进行,如果没通过验证,将抛出IllegalAccessError, NoSuchMeathondError等异常。
如
符号引用中的类,字段,方法的权限是否能被当前类访问;
…等等
3.2.4 准备
举个简单例子。
public static int value = 100;
准备阶段,会把value先赋值为0。赋值100的动作,在后面的3.2.6 初始化执行。
这其实说明了一件事:类的静态变量,即使一直没在代码赋值过,也可以确保有默认值,如0。不像函数中的局部变量,如果没赋值过,则是一个乱数据。
此外,如果写成public static final int value = 100; 则虚拟机会在此阶段直接赋值100。
3.2.5 解析
类/字段/方法等符号引用解析为直接引用。
3.2.6 初始化
执行类构造器():自动收集static变量和static{}块,按顺序执行初始化。
由编译器自动生成,如果没有static变量和static{}块,就不会生成。
举个例子:
public class TestClass {
public static int count = 100;
static fooMeathod() {
System.out.printlf("load TestClass...");
}
}count赋值100,以及fooMeathod函数,将在此执行。
4. 字节码执行引擎
简而言之,就是输入字节码,过程是字节码解析的等效过程,输出结果。不同的虚拟机有不同的具体实现,大体有解释执行和编译执行两种选择。这对应解释器和即时编译器(JIT Just In Time Compiler)。
当然了,JIT编译器不是强制要求,有些虚拟机就没有。
4.1 即时编译器JIT
Java程序最初是仅仅通过解释器解释执行的,即对字节码逐条解释执行,这种方式的执行速度相对会比较慢,尤其当某个方法或代码块运行的特别频繁时,这种方式的执行效率就显得很低。于是后来在虚拟机中引入了JIT编译器(即时编译器),当虚拟机发现某个方法或代码块运行特别频繁时,就会把这些代码认定为“Hot Spot Code”(热点代码),为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各层次的优化,完成这项任务的正是JIT编译器。
现在主流的商用虚拟机(如Sun HotSpot、IBM J9)中几乎都同时包含解释器和编译器(三大商用虚拟机之一的JRockit是个例外,它内部没有解释器,因此会有启动相应时间长之类的缺点,但它主要是面向服务端的应用,这类应用一般不会重点关注启动时间)。二者各有优势:当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译的时间,立即执行;当程序运行后,随着时间的推移,编译器逐渐会返回作用,把越来越多的代码编译成本地代码后,可以获取更高的执行效率。解释执行可以节约内存,而编译执行可以提升效率。
HotSpot虚拟机中内置了两个JIT编译器:Client Complier和Server Complier,分别用在客户端和服务端,目前主流的HotSpot虚拟机中默认是采用解释器与其中一个编译器直接配合的方式工作。
运行过程中会被即时编译器编译的“热点代码”有两类:
被多次调用的方法
被多次调用的循环体。
5. 参考
- 认识Java虚拟机的基本结构
- 新生代Eden与两个Survivor区的解释
- 触摸java常量池
- 深入理解JAVA虚拟机(周志明)
- 【深入Java虚拟机】之七:Javac编译与JIT编译