Java基础知识点之HashSet
HashSet是一个具有唯一元素的二叉树集合,同时HashSet是Set接口的一个实现类(HashSet实现了Set的接口),它具有Set的特点。
Set的特点有:不可重复,元素无顺序,没有带索引的方法(因此不能使用普通for循环来遍历,也不能通过索引来获取或删除Set集合中的元素值)。
HashSet的特点有:底层数据结构是哈希表;对集合的迭代顺序不作任何保证,也就是说不保证存储和取出元素顺序一致(即元素无顺序);没有带索引的方法(因此不能使用普通for循环来遍历,也不能通过索引来获取或删除HashSet集合中的元素值);不可重复。
接下来我们将从HashSet的四个特点并结合代码来学习HashSet。(由于HashSet没有带索引的方法,因此HashSet的第四个特点只能使用forEach语句与Iterator迭代器来实现HashSet的遍历)
注意:同样的,HashSet与TreeSet均是Set接口的一个实现类,因此HashSet的默认数据类型也是Object类,理论上我们可以通过add()方法来添加任意数据类型,但是如果我们这样子做,当我们进行遍历输出的时候就会遇到麻烦!!!因此我们在使用HashSet的时候,请使用泛型来约束数据类型!!!
由于哈希表同样也是一个很重要的知识点,因此在这里我们先跳过它,先来讲HashSet的后面三个特点。之后笔者会单独为哈希表写一篇知识点博客。
一、不可重复
String类型的HashSet
public static void main(String[] args) {
//若要使用HashSet,我们需要导入import java.util.HashSet;
//我们使用泛型来约束HashSet的数据类型为String数据类型
HashSet<String> hashset=new HashSet<>();
//使用add()方法来添加数据
hashset.add("bb");
hashset.add("aa");
hashset.add("cc");
hashset.add("ee");
hashset.add("aaa");
hashset.add("bb");
//打印
System.out.println(hashset);
}
运行结果(重复的bb元素被筛掉)

二、使用forEach语句和Iterator迭代器遍历输出HashSet
forEach语句遍历输出HashSet
public static void main(String[] args) {
//若要使用HashSet,我们需要导入import java.util.HashSet;
//我们使用泛型来约束HashSet的数据类型为String数据类型
HashSet<String> hashset=new HashSet<>();
//使用add()方法来添加数据
hashset.add("bb");
hashset.add("aa");
hashset.add("cc");
hashset.add("ee");
hashset.add("aaa");
hashset.add("bb");
//在此我们使用forEach来遍历HashSet
//String是hashset的数据类型,我们将hashset的数据存入str(此名字你可以自定义)中并输出
for(String str:hashset){
System.out.println(str);
}
}
运行结果(重复的bb元素被筛掉)

Iterator迭代器遍历输出HashSet
public static void main(String[] args) {
//若要使用HashSet,我们需要导入import java.util.HashSet;
//我们使用泛型来约束HashSet的数据类型为String数据类型
HashSet<String> hashset=new HashSet<>();
//使用add()方法来添加数据
hashset.add("bb");
hashset.add("aa");
hashset.add("cc");
hashset.add("ee");
hashset.add("aaa");
hashset.add("bb");
//创建迭代器对象,由于hashset的类型是String类型,因此迭代器的数据类型也是String
Iterator<String> iterator=hashset.iterator();
//判断该位置是否有值,iterator.hasNext()它会查看我们当前位置是否存在元素,存在元素返回true,不存在元素返回false
while(iterator.hasNext()){
//获取该位置的元素值,iterator.next()它会取得我们目前位置的元素,然后指针后移
System.out.println(iterator.next());
}
}
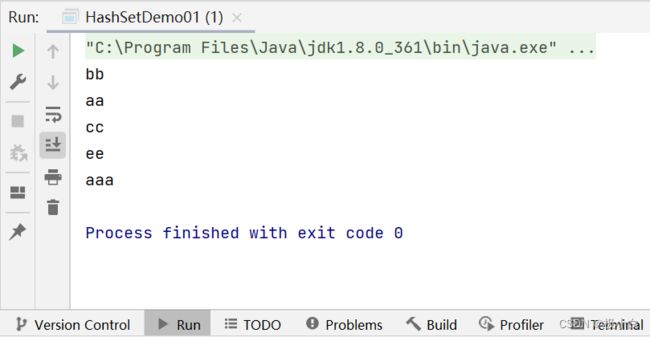
运行结果(重复的bb元素被筛掉)
三、不保证存储和取出元素顺序一致
public static void main(String[] args) {
//若要使用HashSet,我们需要导入import java.util.HashSet;
//我们使用泛型来约束HashSet的数据类型为String数据类型
HashSet<String> hashset=new HashSet<>();
//使用add()方法来添加数据
hashset.add("zhangsan");
hashset.add("wangwu");
hashset.add("lisi");
hashset.add("aa");
hashset.add("aaa");
hashset.add("aa");
//打印
System.out.println(hashset);
}
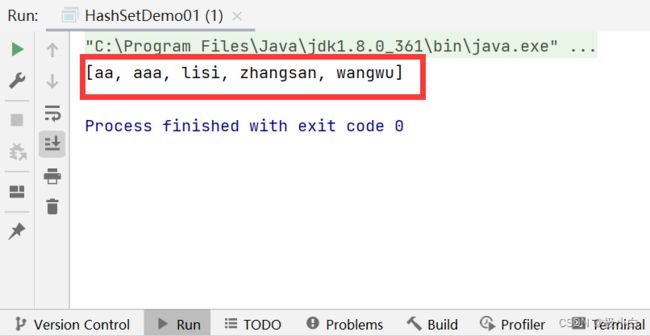
运行结果(重复的aa元素被筛掉),我们发现我们输出的顺序与插入的顺序是不一致的,因此HashSet不保证存储和取出元素顺序一致。
四、案例-HashSet集合储存学生对象并遍历
原始Student类
public class Student {
private String name;
private int age;
public Student() {}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
HsahSet的main()方法
public static void main(String[] args) {
//若要使用HashSet,我们需要导入import java.util.HashSet;
//我们使用泛型来约束HashSet的数据类型为String数据类型
HashSet<Student> hashset=new HashSet<>();
//使用add()方法来添加数据
hashset.add(new Student("zhangsan",18));
hashset.add(new Student("zhangsan",18));
hashset.add(new Student("lisi",18));
hashset.add(new Student("wangwu",20));
hashset.add(new Student("chenliu",20));
//创建迭代器对象,由于hashset的类型是Student类型,因此迭代器的数据类型也是Student
Iterator<Student> iterator=hashset.iterator();
//判断该位置是否有值,iterator.hasNext()它会查看我们当前位置是否存在元素,存在元素返回true,不存在元素返回false
while(iterator.hasNext()){
//获取该位置的元素值,iterator.next()它会取得我们目前位置的元素,然后指针后移
System.out.println(iterator.next());
}
}
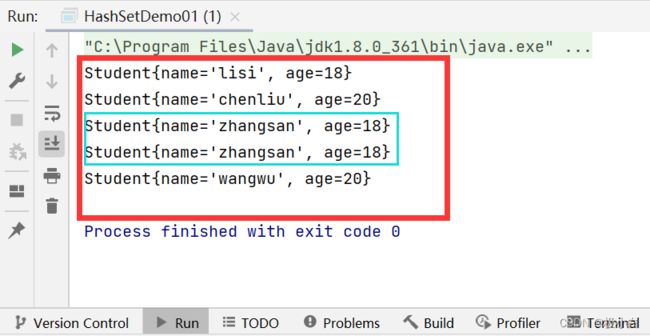
在main()方法中,我们插入两个相同的对象,我们查看重复值是否会被筛掉
运行结果(我们发现他们两个都输出了,我们认为的重复值并没有被筛掉)
那么这是为什么呢?其实我们在元素进行比较的时候,计算机并不是通过比较他们的对象值来判定他们是否不同,而是通过比较他们存储的内存地址来比较他们是否不同,那么我们接下来分别输出它们的HashCode()的值(对象存储的内存空间的int类型数值)
hashCode的main()方法
public static void main(String[] args) {
//若要使用HashSet,我们需要导入import java.util.HashSet;
//我们使用泛型来约束HashSet的数据类型为String数据类型
HashSet<Student> hashset=new HashSet<>();
//创建Student对象
Student s1=new Student("zhangsan",18);
Student s2=new Student("zhangsan",18);
//打印hashcode值,观察他们的内存地址是否相同
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
}
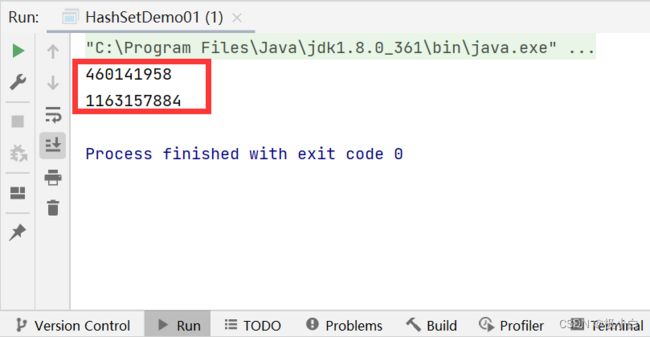
运行结果(我们发现他们两个的hashCode值是不同的,这就是为什么计算机不认为他们是一样的原因)
那么我们如何使得计算机知道他们两个是相同的呢,这就需要我们在Student类中重写HashCode()方法
改进Student类
笔者用的编译器是IDEA,在IDEA的Student类中右键--->Generate...
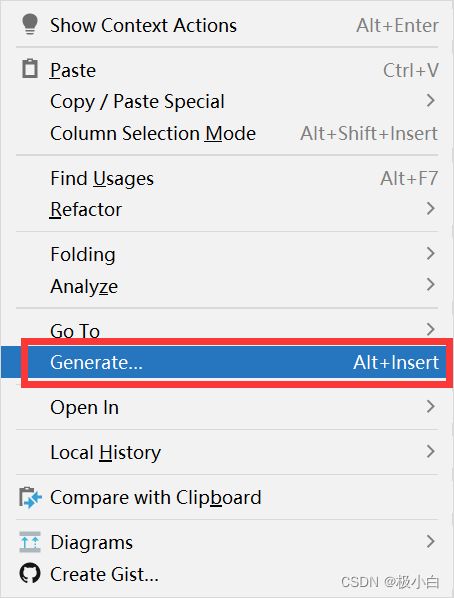
选中equals() and hashCode()

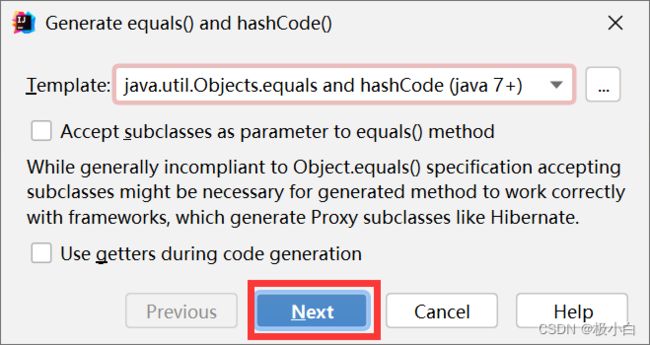
点击Next
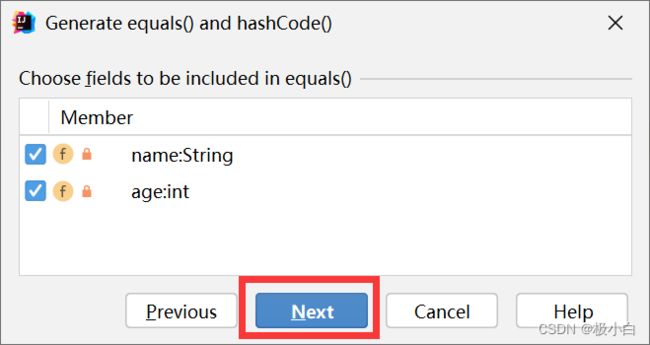
点击Next
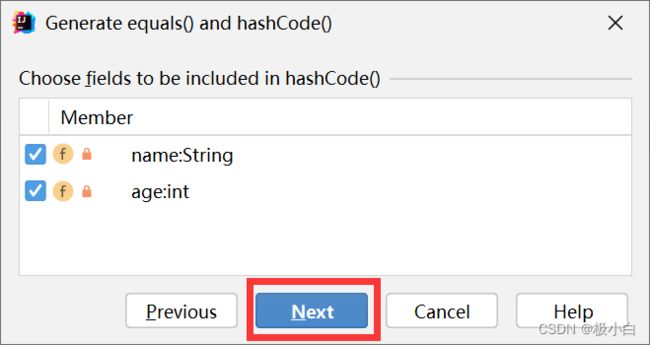
点击Next
点击Finish

重写后的Student类
public class Student {
private String name;
private int age;
public Student() {}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
hashCode的main()方法
public static void main(String[] args) {
//若要使用HashSet,我们需要导入import java.util.HashSet;
//我们使用泛型来约束HashSet的数据类型为String数据类型
HashSet<Student> hashset=new HashSet<>();
//创建Student对象
Student s1=new Student("zhangsan",18);
Student s2=new Student("zhangsan",18);
//打印hashcode值,观察他们的内存地址是否相同
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
}
运行结果如下:(我们可以看到此时计算机已然认为s1与s2是相同的)
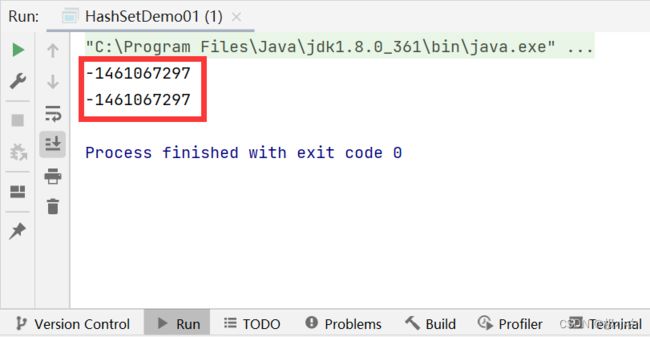
运行如下main()方法
public static void main(String[] args) {
//若要使用HashSet,我们需要导入import java.util.HashSet;
//我们使用泛型来约束HashSet的数据类型为String数据类型
HashSet<Student> hashset=new HashSet<>();
//创建Student对象
Student s1=new Student("zhangsan",18);
Student s2=new Student("zhangsan",18);
//添加对象
hashset.add(s1);
hashset.add(s1);
//1:普通打印
System.out.println(hashset);
System.out.println("====华丽的分割线====");
//2:forEach打印
for(Student stu:hashset){
System.out.println(stu);
}
System.out.println("====华丽的分割线====");
//3:Iterator迭代器打印
Iterator<Student> iterator=hashset.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
运行结果如下:(我们可以看到此时计算机已然认为s1与s2是相同的,并且筛掉重复值)
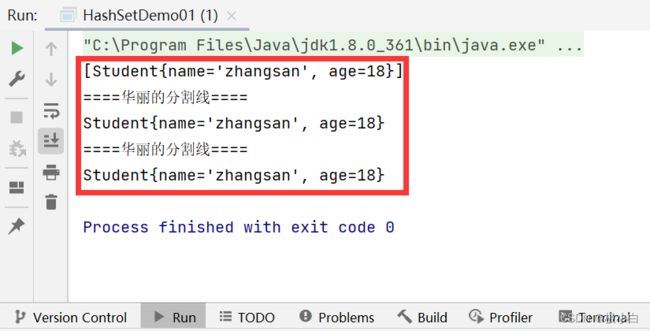
OK!!!结束!!!