Python实现经典网络架构Googlenet代码
Python实现经典网络架构Googlenet代码
VGG非常优秀,但它在ILSVRC上拿到的最高名次是亚军,在VGG登场的2014年,力压群雄拿到冠军的是
在ImageNet数据集上达到6.7%错误率的GoogLeNet。GoogLeNet由谷歌团队与众多大学合作研发,发
表于论文《Going deeper with convolutions》,整篇论文语言精练简单,从标题到内容都彰显着谷歌
团队加深卷积网络结构的决心,读起来非常有趣。受到NiN网络的启发,谷歌引入了一种全新的网络架
构:Inception block,并将使用Inception V1的网络架构称为GoogLeNet(虽然从名字上来看致敬了
LeNet5算法,但GoogLeNet已经基本看不出LeNet那种经典的卷积+池化+全连接的结构了。
Inception直译是“起始时间”,也是电影《盗梦空间》的英文名称。或许谷歌团队是无心插柳,但
Inception块的出现成为了深度视觉发展历史上的一个新的起点。从2014年的竞赛结果来看,Inception
V1的效果只比VGG19好一点点(只比VGG降低了0.6%的错误率),两个架构在深度上也没有差太多,
但在之后的研究中,Inception展现出比VGG强大许多的潜力——不仅需要的参数量少很多,架构可以达
到的上限也更高。随着架构的迭代更新,Inception V3和V4已经是典型的SOTA模型,可以在ImageNet
数据集上达到3%的错误率,但VGG在ILSVRC上的表现基本就是模型的极限了。
import torch
import torch.nn as nn
from torchinfo import summary
from torch.nn import functional as F
from typing import Type, Union, List, Optional
data=torch.ones(10,3,224,224)
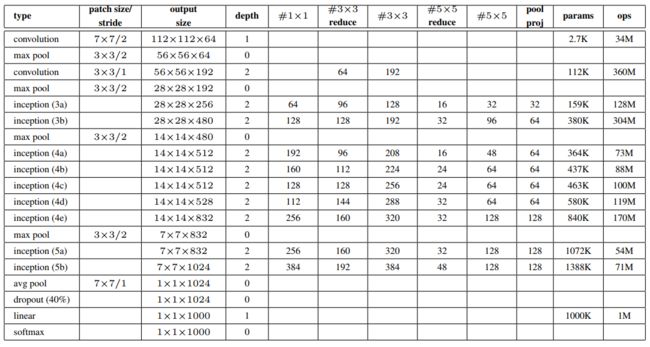
inputlist=[[192,64,96,128,16,32,32],#3a
[256,128,128,192,32,96,64],#3b
[480,192,96,208,16,48,64],#4a
[512,160,112,224,24,64,64],#4b
[512,128,128,256,24,64,64],#4c
[512,112,114,288,32,64,64],#4d
[528,256,160,320,32,128,128],#4e
[832,256,160,320,32,128,128],#5a
[832,384,192,384,48,128,128]#5b
]
class Inception(nn.Module):
def __init__(self,inputli:int =1):
if inputli==1:
inputli=[192,64,96,128,16,32,32]
super().__init__()
self.X1=nn.Conv2d(inputli[0],inputli[1],kernel_size=1)
self.X2=nn.Sequential(nn.Conv2d(inputli[0],inputli[2],kernel_size=1)
,nn.ReLU(inplace=True)
,nn.Conv2d(inputli[2],inputli[3],kernel_size=3,padding=1)
,nn.ReLU(inplace=True))
self.X3=nn.Sequential(nn.Conv2d(inputli[0],inputli[4],kernel_size=1)
,nn.ReLU(inplace=True)
,nn.Conv2d(inputli[4],inputli[5],kernel_size=5,padding=2)
,nn.ReLU(inplace=True))
self.X4=nn.Sequential(nn.MaxPool2d(kernel_size=3,stride=1,padding=1)
,nn.Conv2d(inputli[0],inputli[6],kernel_size=1)
,nn.ReLU(inplace=True))
def forward(self,x):
x1=self.X1(x)
x2=self.X2(x)
x3=self.X3(x)
x4=self.X4(x)
Xlist=[x1,x2,x3,x4]
return torch.cat(Xlist,1)
class AuxClf(nn.Module):
def __init__(self,inputnum):
super().__init__()
self.ls=nn.Sequential(nn.AvgPool2d(kernel_size=5,stride=3)
,nn.Conv2d(inputnum,128,kernel_size=1,stride=1)
,nn.ReLU(inplace=True)
)
self.fc=nn.Sequential(nn.Linear(4*4*128,1024)
,nn.ReLU(inplace=True)
,nn.Linear(1024,1000)
,nn.ReLU(inplace=True)
)
def forward(self,x):
x=self.ls(x)
x=torch.flatten(x,1)
x=self.fc(x)
out=F.softmax(x)
return out
class Google(nn.Module):
def __init__(self):
super().__init__()
self.listpro=nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3)
, nn.ReLU(inplace=True)
, nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
, nn.Conv2d(64,192,kernel_size=3,stride=1,padding=1)
, nn.ReLU(inplace=True)
, nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
#3a,3b
self.in3a=Inception(inputlist[0])
self.in3b=Inception(inputlist[1])
#4a,4b,4c,4d
self.in4a=Inception(inputlist[2])
self.avx1=AuxClf(512)
self.in4b=Inception(inputlist[3])
self.in4c=Inception(inputlist[4])
self.in4d=Inception(inputlist[5])
self.avx2=AuxClf(528)
self.in4e=Inception(inputlist[6])
#5a,5b
self.in5a=Inception(inputlist[7])
self.in5b=Inception(inputlist[8])
self.avgpoor=nn.AvgPool2d(kernel_size=7,stride=1)
self.Maxpool=nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.fc=nn.Linear(1024,1000)
def forward(self,x):
x=self.listpro(x)
x=self.in3a(x)
x=self.in3b(x)
x=self.Maxpool(x)
x=self.in4a(x)
ax1=self.avx1(x)
x=self.in4b(x)
x=self.in4c(x)
x=self.in4d(x)
ax2=self.avx2(x)
x=self.in4e(x)
x=self.Maxpool(x)
x=self.in5a(x)
x=self.in5b(x)
x=self.avgpoor(x)
x=torch.flatten(x,1)
x=self.fc(F.dropout(x,0.5))
out =F.softmax(x)
return out ,ax1,ax2
ge=Google()
ge(data)
:17: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
out=F.softmax(x)
:47: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
out =F.softmax(x)
(tensor([[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
...,
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010]],
grad_fn=),
tensor([[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
...,
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010]],
grad_fn=),
tensor([[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
...,
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010],
[0.0010, 0.0010, 0.0010, ..., 0.0010, 0.0010, 0.0010]],
grad_fn=))
summary(ge,data.shape,depth=1)
:17: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
out=F.softmax(x)
:47: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
out =F.softmax(x)
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Google [10, 1000] --
├─Sequential: 1-1 [10, 192, 28, 28] 120,256
├─Inception: 1-2 [10, 256, 28, 28] 163,696
├─Inception: 1-3 [10, 480, 28, 28] 388,736
├─MaxPool2d: 1-4 [10, 480, 14, 14] --
├─Inception: 1-5 [10, 512, 14, 14] 376,176
├─AuxClf: 1-6 [10, 1000] 3,188,840
├─Inception: 1-7 [10, 512, 14, 14] 449,160
├─Inception: 1-8 [10, 512, 14, 14] 510,104
├─Inception: 1-9 [10, 528, 14, 14] 512,226
├─AuxClf: 1-10 [10, 1000] 3,190,888
├─Inception: 1-11 [10, 832, 14, 14] 868,352
├─MaxPool2d: 1-12 [10, 832, 7, 7] --
├─Inception: 1-13 [10, 832, 7, 7] 1,043,456
├─Inception: 1-14 [10, 1024, 7, 7] 1,444,080
├─AvgPool2d: 1-15 [10, 1024, 1, 1] --
├─Linear: 1-16 [10, 1000] 1,025,000
==========================================================================================
Total params: 13,280,970
Trainable params: 13,280,970
Non-trainable params: 0
Total mult-adds (G): 15.63
==========================================================================================
Input size (MB): 6.02
Forward/backward pass size (MB): 242.30
Params size (MB): 53.12
Estimated Total Size (MB): 301.44
==========================================================================================