Vue.js基础知识
一、Vue.js是什么?
它是一套用于构建用户界面的渐进式框架。其设计为自底向上逐层应用。Vue只关心视图层。
二、声明式的渲染
1、 Vue.js的核心是采用简洁的模板语法来声明式地将数据渲染到DOM系统
{{ message }}
var app = new Vue({
el: '#app',
data: {
message: 'Hello Vue!'
}
})输出:Hello Vue!
- 什么是DOM系统
dom就是文档对象模型。当创建好一个页面并加载到浏览器中,DOM就悄然而生,它会把网页文档转换为一个文档对象,主要功能就是处理网页内容。在这个文档对象中,所有的元素呈现出一种层次结构,就是说除了顶级元素html外,其他所有元素都被包含在另一个元素中。
文档标题
我的链接
我的标题
DOM结构树就是一颗倒长的树

2、响应式
js控制台中,修改对应值,浏览器中你会看到对应的修改
3、简单的一些指令
v-if:元素是否显示;
v-for:渲染一个项目列表
v-bind: 简:数据绑定
v-on:简@ 添加一个事件监听器
v-model:实现表单输入和应用状态之间的双向绑定
5、vue-router路由跳转方式(3种)
1、router-link
2、this.$router.push() (函数里面调用)
1. 不带参数
this.$router.push('/home')
this.$router.push({name:'home'})
this.$router.push({path:'/home'})
2. query传参
this.$router.push({name:'home',query: {id:'1'}})
this.$router.push({path:'/home',query: {id:'1'}})
// html 取参 $route.query.id
// script 取参 this.$route.query.id
3. params传参
this.$router.push({name:'home',params: {id:'1'}}) // 只能用 name,若是用path,则params会被忽略,不生效
4. query和params区
query类似 get, 跳转之后页面 url后面会拼接参数,类似?id=1, 非重要性的可以这样传, 密码之类还是用params刷新页面id还在
params类似 post, 跳转之后页面 url后面不会拼接参数 , 但是刷新页面id 会消失
3、this.$router.replace() (用法同上,push)
4、this.$router.go(n) 跳转到指定页面
拓展:区别this.$router和this.$route
1、this.$router:表示一个全局路由对象,vue-router的实例,提供addRoutes、back等方法,相当于一个路由的管理者角色;
2、this.$route:表示当前路由对象,包含具体的路由名称,path、query、params等属性,其实就是routes(new Router时声明routes)里面的一条具体路由。
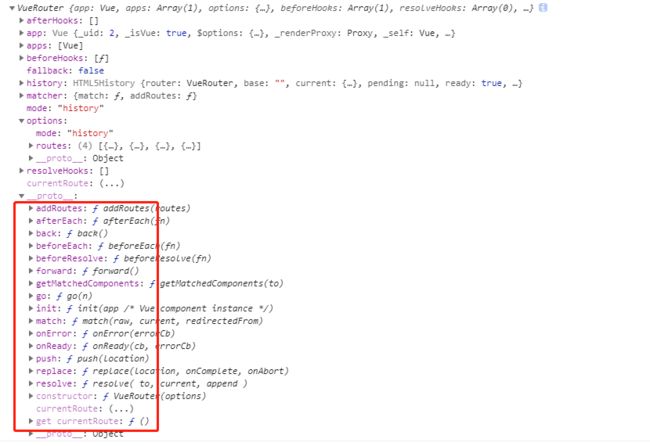
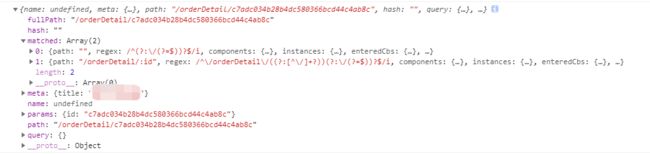
6、路由的钩子函数(6个)
1、全局的路由钩子函数:beforeEach、beforeResolve、afterEach(一般在index.js中的router对象)
2、单个的路由钩子函数:beforeEnter(路由守卫只有一个)
3、组件内的路由钩子函数:beforeRouteEnter、beforeRouteLeave(定时器的清除,东西保存等)、beforeRouteUpdate
参考用法网址:vue router钩子函数
vue路由钩子函数有几种?分别是什么?-前端问答-PHP中文网
7、vue-loader是什么?有哪些用途
是webpack的loader,是vue文件的加载器,主要用来处理vue组件文件,配合webpack和及相关loader,来进行编译模板,scoped CSS和热加载
8、vue template怎么理解
是vue的模板语法,是一种描述的视图的标记语言,在通过vue-template-compiler解析成render函数,通过vnode和diff算法,统一替换dom形成真实视图
template的作用就是模板占位符,可帮助我们包裹元素,但在循环的过程中,不会template被渲染到页面上
9、vue项目中用了哪些技术
-
vue-cli脚手架搭建项目;
-
配置路由,用axios封装网络请求
-
vuex管理全局路由
-
路由拦截(设置全局的路由钩子来做权限控制)
-
单个通用组件的封装
-
父子之间props数据交互
-
vue生命周期
10、var that=this的含义
this指的是指当前对象,所以this不是固定不变的。比如在this.query中,此时this指的是app这个实例本身。而在具体的函数中this指的就是axios的回调函数本身。所以在回调函数中使用this.函数,会出现undefined,因为找不到其中函数的属性。所以,我们要在使用回调函数之前将app实例中的属性存储给一个其他值,也就是用that指向this。此时,that即代表app这个实例,this代表axios的回调函数。所以这个时候我们的that.musicList即可以找到相应的属性。同理,当我们的methods在定义函数中自定义了其他函数或者使用其他函数代替了axios回调函数的位置,同样回出现this.musicList找不到属性。

11、vue-router中hash模式和history模式的区别
hash和history模式都属于浏览器自身的特性。
hash模式:地址栏中有#, 改变hash不会重新加载页面。因为路由的哈希模式其实是利用Window可以监听onhaschange事件,也就是说你的url中的哈希值(#后面的值)如果有变化,前端是可以做到监听并做一些响应的。
实现原理:
1、url中的hash值知识客户端的一种状态,也就是说向服务器端发出请求时,hash部分不会被发送;
2、hash值的改变,都会在浏览器历史访问中增加一条记录,因此我们能通过浏览器的前进、回退按钮控制hash的切换;
3、通过a标签的点击跳转,url中的hash的值会发生改变;
4、我们可以通过onhaschange事件来监听hash值的改变,从而对页面进行跳转(渲染)
备注:如果该地址需要分享到其他应用中的页面,建议不使用hash。因为其他应用可能不支持url中出现#。
history模式:前端的url必须和实际向后端发送的请求的url一致,比如:htttp://localhost/book/id,如果后端缺少对/book/id的路由处理,将返回404错误。所有一般需要后端配合将所有的访问都指向index.html,否则用户刷新页面,会导致出现404错误。
在html4中,已经支持window.history对象控制页面历史记录跳转,常用方法包括:
history.forward():在历史记录中前进一步;
history.back():在历史记录中后退一步;
history.go(n):在历史记录中跳转n步骤,n=0位刷新本页面,n=-1为后退一页
在html5中,window.history对象得到了扩展,新增的api包括有:
history.pushState(data[,title][,url]):向历史记录中追加一条记录history.replaceState(data[,title][,url]):替换当前页在历史记录中的信息。history.state:是一个属性,可以得到当前页的state信息。window.onpopstate:是一个事件,在点击浏览器后退按钮或js调用forward()、back()、go()时触发。监听函数中可传入一个event对象,event.state即为通过pushState()或replaceState()方法传入的data参数
实例:分别通过hash和history两种模式去获取url中的参数:
url地址:Home - IDG Events
hash模式:
import qs from 'qs'
const query = qs.parse(location.hash.substring(3))
let channel = query.channel
let user = query.userhistory模式:
import qs from 'qs'
const query = qs.parse(location.search.substring(1))
let channel = query.channel
let user = query.user12、Vue中qs使用,主要有两个方法
1、首先安装:npm install qs 或者yarn add qs;
2、然后可以按需引入:import qs from "qs";
3、主要有两个方法:qs.parse()和qs.stringify()
4、qs可分为三种类型:可参考:qs的arrayFormat与SpringBoot接收数组问题_pifutan的博客-CSDN博客
方法一:qs.stringify()将对象 序列化成URL的形式,以&进行拼接
var a = {name:'lp',age:27};
qs.stringify(a)
// 'name=lp&age=27'方法二:qs.parse()将序列化的内容拆分成一个个单一的对象
var a ='name=lp&age=27' ;
qs.parse(a)
// {name:'lp',age:27}备注:区别qs.stringify() 和JSON.stringify()
var a = {name:'lp',age:27};
qs.stringify(a)
// 'name=lp&age=27'
JSON.stringify(a)
// '{"name":"lp","age":27}'13、路由懒加载
component: resolve => require(['@/view/My/Index.vue'], resolve) 与component: index区别
require: 运行时调用,理论上可以运用在代码的任何地方,
import:编译时调用,必须放在文件开头
懒加载:component: resolve => require(['@/view/My/Index.vue'], resolve)
用require这种方式引入的时候,会将你的component分别打包成不同的js,加载的时候也是按需加载,只用访问这个路由网址时才会加载这个js
非懒加载:component: index
如果用import引入的话,当项目打包时路由里的所有component都会打包在一个js中,造成进入首页时,需要加载的内容过多,时间相对比较长
vue的路由配置文件(routers.js),一般使用import引入的写法,当项目打包时路由里的所有component都会打包在一个js中,在项目刚进入首页的时候,就会加载所有的组件,所以导致首页加载较慢,
而用require会将component分别打包成不同的js,按需加载,访问此路由时才会加载这个js,所以就避免进入首页时加载内容过多
14、keepAlive组件的作用及使用方式
keep-alive是vue内置的一个组件,而这个组件的作用就是能够缓存不活动的组件。一般情况下,组件进行切换的时候,默认会进行销毁,如果有需求,某个组件切换后不进行销毁,而是保存之前的状态,那么就可以利用keep-alive来实现
keep-alive中组件不进行销毁,其中组件的值也被缓存下来了,所以当我们只想缓存组件时,我们就需要用到如下属性:
- include 值为字符串或者正则表达式匹配的组件name会被缓存。
- exclude 值为字符串或正则表达式匹配的组件name不会被缓存
使用可参考网址:vue中keepAlive组件的作用及使用方式_搬砖猴哥-CSDN博客
15、vue中$nextTick的使用
在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。它跟全局方法 Vue.nextTick 一样,不同的是回调的 this 自动绑定到调用它的实例上。
// 修改数据
vm.msg = 'Hello'
// DOM 还没有更新
Vue.nextTick(function () {
// DOM 更新了
})
// 作为一个 Promise 使用 (2.1.0 起新增,详见接下来的提示)
Vue.nextTick()
.then(function () {
// DOM 更新了
})
//举例
hello
备注:引出问题:为什么使用$nextTick
可以用 setTimeout 替换 $nextTick,形如用 setTimeout(fn, 0) 代替 $nextTick(fn),既然可以使用 setTimeout 替换 $nextTick 那么为什么不用 setTimeout 呢?
原因就在于 setTimeout 并不是最优的选择,$nextTick 的意义就是它会选择一条最优的解决方案,即优先选择微任务。
16、 vue中的$符号含义
表示一个变量,在es6中${XXX}来在字符串中插入变量
17、父组件传值给子组件的v-model属性

问题:v-model属性是双向数据绑定,而prop是单向绑定,不能更改数据,只能由父组件传输过来 ,所以,当子组件想要改变父组件传过来的值的属性时,就会报错,典型的就是父组件传值给子组件修改v-model的值时会报错或者不生效.
解决:
1、父组件使用:msg.sync="aa" 子组件使用$emit('update:msg', 'msg改变后的值xxx')
2、父组件传值直接传对象,子组件收到对象后可随意改变对象的属性,但不能改变对象本身。
3、父组件使用: v-model
例子:利用element中el-drawer,设置起显示隐藏
子组件:Drawer.vue
哈哈哈
父组件
18、vue中父子组件传值有几种方式
- props
- event bus
- $emit
- vuex
- storage
- provide/inject(优点是不用层层传递了)
19、vue中scoped样式穿透 修改第三方组件样式
理解:scoped,相当于样式私有化,即样式只用于与当前组件,避免组件间样式不互相污染
第一种:使用 /deep/ 深度修改标签样式
找到需要修改的 ElementUI 标签的类名,然后在类名前加上 /deep/ ,可以强制修改默认样式。这种方式可以直接用到有 scoped 属性的 style 标签中。
// 修改选择框的默认宽度
/deep/ .el-cascader {
width: 200px;
}第二种:使用>>>
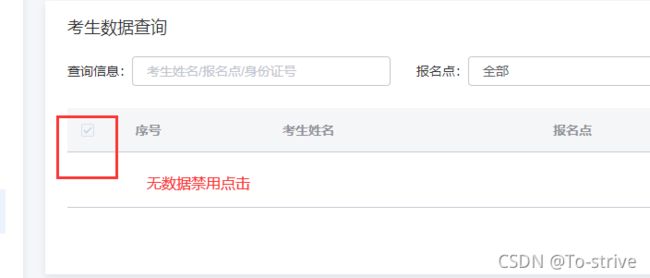
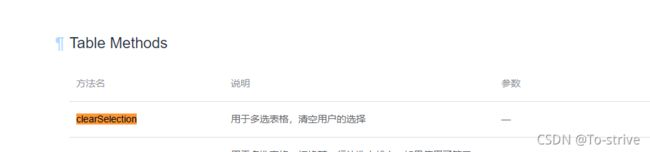
20、element-ui table表头中禁用全选功能
21、vue中两种运行模式(Runtime + Compiler 和 Runtime-only)
1、问题描述:
在使用 vue-cli 脚手架构建项目时,会遇到一个构建选项 Vue build,有两个选择,Runtime + Compiler 和 Runtime-only ,如图所示

Runtime + Compiler: recommended for most users
运行程序+编译器:推荐给大多数用户
Runtime-only: about 6KB lighter min+gzip, but templates (or any Vue-specific HTML) are ONLY allowed in .vue files - render functions are required elsewhere
仅运行程序: 比上面那种模式轻大约 6KB,但是 template (或任何特定于vue的html)只允许在.vue文件中使用——其他地方用需要 render 函数
2. 两种模式的区别
1)runtime-only 比 runtime-compiler 轻 6kb,代码量更少
2)runtime-only 运行更快,性能更好
3)runtime-only 其实只能识别render函数,不能识别template,.vue 文件中的template也是被 vue-template-compiler 翻译成了render函数,所以只能在.vue里写 template
有关vue中的render函数可以看这篇博客:vue中的render函数
3. 解释
两种模式生成的 脚手架 即(代码模板)主要区别在 main.js 中,其它基本上是一样的:

再看一张图:
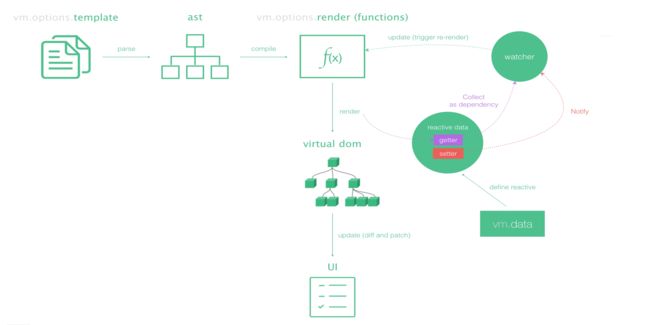
runtime + compiler 中 Vue 的运行过程
对于 runtime-compiler 来说,它的代码运行过程是:template -> ast -> render -> virtual dom -> UI
首先将vue中的template模板进行解析解析成abstract syntax tree (ast)抽象语法树
将抽象语法树在编译成render函数
将render函数再翻译成virtual dom(虚拟dom)
将虚拟dom显示在浏览器上
runtime-only 中 Vue 的运行过程
对于 runtime-only来说,它是从 render -> virtual dom -> UI
可以看出它省略了从template -> ast -> render的过程
所以runtime-only比runtime-compiler更快,代码量更少
runtime-only 模式中不是没有写 template ,只是把 template 放在了.vue 的文件中了,并有一个叫 vue-template-compiler 的开发依赖时将.vue文件中的 template 解析成 render 函数。 因为是开发依赖,不在最后生产中,所以最后生产出来的运行的代码没有template
4. 总结
如果在之后的开发中,你依然使用template,就需要选择 Runtime + Compiler
如果你之后的开发中,使用的是.vue文件夹开发,那么可以选择 Runtime-only
22、vue中import和require理解
1)Import(模块、文件)引入方式
1.引入js文件
在用的那一页,引入文件
Import tools from ‘./tools.js’
相应的js文件,必须暴露出来
2.引入组件
Import Hello from ‘./components/hello’
3.引入外部组件
npm install --save axios
npm install mint-ui -S
//引入全部组件
import Vue from ‘vue’
import Mint from ‘mint-ui’
Vue.use(Mint)
//按需引入部分组件
Import {Cell,Checklist} from ‘minu-ui’
Vue.component(Cell.name,Cell)
Vue.component(Checklist.name,Checklist)
4.引入外部js插件
Import cookies from ‘js-cookie
2)require.js的加载
require的使用非常简单,它相当于module.exports的传送门,module.exports后面的内容是什么,require的结果就是什么,对象、数字、字符串、函数……
再把require的结果赋值给某个变量,相当于把require和module.exports进行平行空间的位置重叠
优点:
1)实现js文件的异步加载,避免网页失去响应;
2)管理模块之间的依赖性,便于代码的编写和维护。
引入:
require('./a')(); // a模块是一个函数,立即执行a模块函数
var data = require('./a').data; // a模块导出的是一个对象
var a = require('./a')[0]; // a模块导出的是一个数组在vue的js引入图片,就需要使用require(“路径”)进来
注:
从理解上,require是赋值过程,import是解构过程,当然,require也可以将结果解构赋值给一组变量,但是import在遇到default时,和require则完全不同:
var $ = require('jquery');
import $ from 'jquery'
是完全不同的两种概念。
3、require和import区别
- require 是赋值过程并且是运行时才执行,也就是异步加载。
- require可以理解为一个全局方法,因为它是一个方法所以意味着可以在任何地方执行。
- import 是解构过程并且是编译时执行。
- import必须写在文件的顶部。
4、总结
require的性能相对于import稍低,因为require是在运行时才引入模块并且还赋值给某个变量,而import只需要依据import中的接口在编译时引入指定模块所以性能稍高
23、vue-router的push和replace的区别
1.this.$router.push()
描述:跳转到不同的url,但这个方法会向history栈添加一个记录,点击后退会返回到上一个页面。
2.this.$router.replace()
描述:同样是跳转到指定的url,但是这个方法不会向history里面添加新的记录,点击返回,会跳转到上上一个页面。上一个记录是不存在的。
3.this.$router.go(n)
相对于当前页面向前或向后跳转多少个页面,类似 window.history.go(n)。n可为正数可为负数。正数返回上一个页面
24、vue - @import css 加载第三方css
@import '@/assets/css/style.css'会出现如下错误
CSS loader 会把把非根路径的url解释为相对路径, 加~前缀才会解释成模块路径。
所以引入改成 :@import '~@/assets/css/style.css'
25、 vue 中axios跨域请求发送两次
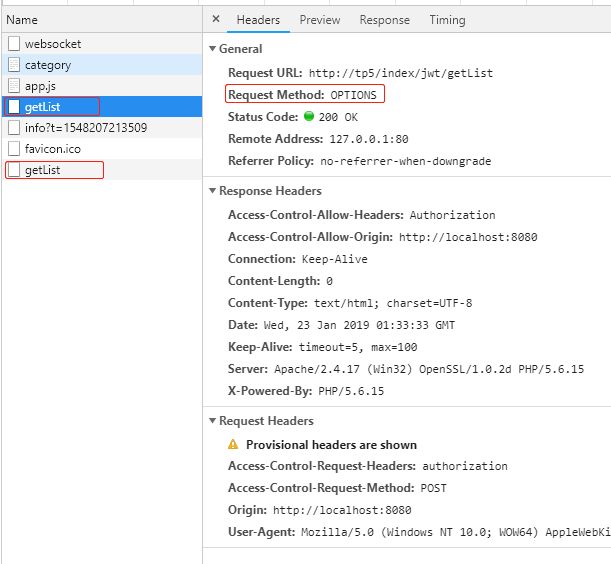
问题:
vue axios跨域请求,在Request Headers加Authorization传递Token时,发现统一请求触发了两次,第一次是Request Method: OPTIONS请求
原因:
跨域请求时,浏览器会首先使用OPTIONS方法发起一个预请求,判断接口是否能够正常通讯。如果通讯异常,则不会发送真正的请求,如果测试通讯正常,则开始真正的请求。

26、Router嵌套路由(children)的用法
嵌套路由就是父路由里面嵌套其他的自路由,父路由有自己的路由导航和路由容器,通过配置children可实现多层嵌套。
{
path: '/Home',
name: 'HomeIndex',
component: resolve => require(['@/views/Home'], resolve),
children: [{
//#region 欢迎页
path: '/Welcome/Index', //欢迎页面
name: 'WelcomeIndex',
component: resolve => require(['@/views/Welcome/Index'], resolve),
meta: {
requireAuth: true
}
}]
}父页面:/Home
子页面:/Welcome/Index
按照此代码运行,则访问地址就是http://localhost:8080/Welcome/Index
注意:
若自路由的path的最前面无"/",则需要添加父路由的路径即可以访问此子路由,则访问路径为:
http://localhost:8080/Home/Welcome/Index
27、require.context(自定加载指定目录下的js模块等作用)
理解:require.context是webpack中,用来创建自己的(模块)上下文,当webpack在构建的时候解析代码中的require.context()
require.context函数接收三个参数:
1. 要搜索的文件夹目录
2. 是否还应该搜索它的子目录
3. 以及一个匹配文件的正则表达式语法:require.context(directory, useSubdirectories = false, regExp = /^\.\//);
示例:
1、针对文件夹/api下所有js文件

2、获取api下所有js文件
const apiFiles=require.context('./api', false, /\.js$/) // (创建了)一个包含了 api文件夹(不包含子目录)下面的、所有文件名以 .js 结尾的、能被 require 请求到的文件的上下文。
console.log(apiFiles.keys());
// apiFiles(key).default 获取文件中使用default导出的内容。
打印结果:
![]()
通过打印, 可以看出返回的是一个函数,意思就是说,require.context模块导出(返回)一个(require)函数。
这个函数有三个属性:
resolve:是一个函数,它返回请求被解析后得到的模块 id。
keys:也是一个函数,它返回一个数组,由所有可能被上下文模块处理的请求组成。
id:是上下文模块里面所包含的模块 id. 它可能在你使用 module.hot.accept 的时候被用到
调用 apiFiles.keys() 可以打印出./api目录下所有api文件集合
28、数组响应式操作及高阶函数
主要涉及:
push、pop、unshift、shift、slice、filter过滤函数、map高阶函数、reduce高阶函数
1、数组的响应式操作:
1. this.array.push('在数组末尾添加一个元素')
2. this.array.pop()//'在数组末尾删除一个元素'
3. this.array.unshift('在数组的开始添加一个元素')
4. this.array.shift()//'在数组的结尾删除一个元素'
5. this.array.slice(1,2)//'在数组的下标为1的元素开始删除两个元素'
6. this.array.slice(1,2,'123','456')//'在数组的下标为1的元素开始删除两个元素,并插入一个元素'
7. this.array.slice(1,0,'123','456')//'在数组的下标为1的元素删除,并插入两个元素'
8. this.array.slice(2)//保留前两个,其他删除
2、高阶函数
1. filter过滤函数
//filter也是一个常用的操作,它用于把Array的某些元素过滤掉,然后返回剩下的元素。
//filter把传入的函数依次作用于每个元素,然后根据返回值是true还是false决定保留还是丢弃该元素。
const nums = [2,3,5,1,77,55,100,200];
let newArray = nums.filter(function (n) {
//小于100就是true,进入newArray数组
return n < 100;
})
console.log(newArray);//[2,3,5,1,77,55]
2. map高阶函数
map函数同样会遍历数组每一项,传入回调函数为参数,num是map遍历的每一项,回调函数function返回值会被添加到新数组中
const nums = [2,3,5,1,77,55,100,200];
let newArray = nums.map(function (n) {
//小于100就是true,进入newArray数组
return n < 100;
})
console.log(newArray);//[2,3,5,1,77,55]
3. reduce高阶函数
reduce函数同样会遍历数组每一项,传入回调函数和‘0'为参数,0表示回调函数中preValue初始值为0,回调函数中参数preValue是每一次回调函数function返回的值,currentValue是当前值
const nums = [2,3,5,1,77,55,100,200];
let new3Array = nums.reduce(function (preValue,currentValue) {
//数组为[2,3,5,1,77,55,100,200],则回调函数第一次返回值为0+2=2,第二次preValue为2,返回值为2+3=5,以此类推直到遍历完成
return preValue+currentValue;
},0);//第二个参数0是preValue的初始值
console.log(new3Array);//443
3、例子
1.找出小于100的数字:
2. 将小于100的数字, 全部乘以5:
3.在2的基础上, 对所有数求和:
let numsp = [12, 4, 5, 60, 655, 123, 432, 65, 190, 100];
let newNum11 = this.array
.filter((num) => num < 100)//对数组进行过滤//[12, 4, 5, 60, 65]
.map((num) => num * 5,this)//对数组里面每个元素进行处理//[60, 20, 25, 300, 325]
.reduce((total, num) => total + num);//对数组里的所有元素求和//730
console.log(newNum11);//730
29、vue中path.resolve(__dirname,'../dist/index.html') 解析
- path.resolve() 理解
path.resolve方法用于将相对路径转为绝对路径
path.resolve('path1', 'path2')
// 结果:/path1/path2
path.resolve('path1', '/path2')
// 结果:/path2
path.resolve('path1', '../path2')
// 结果:/path2
path.resolve('path1/path2/path3', 'path4/path5', '../path6')
// 结果:/path1/path2/path3/path4/path62. __dirname和__filename理解
Node.js中的文件路径大概有 __dirname, __filename, process.cwd(), ./ 或者 ../
__dirname: 获得当前执行文件所在目录的完整目录名
__filename: 获得当前执行文件的带有完整绝对路径的文件名
process.cwd():获得当前执行node命令时候的文件夹目录名
./: 文件所在目录