pytorch进阶学习(一):使用远程服务器在pycharm上运行简单的小型网络模型,使用fashion-minist数据集进行训练
参考视频和代码来源详见up主Leo在这的b站教学视频:
1、Pytorch的安装与环境配置【小学生都会的Pytorch】_哔哩哔哩_bilibili
如何在pycharm上连接远程服务器详见:
(7条消息) 如何使用租用的云服务器实现神经网络训练过程(超详细教程,新手小白适用)_好喜欢吃红柚子的博客-CSDN博客
一、服务器上下载conda
如果你的服务器上没有conda,需要下载。
(7条消息) 远端服务器安装anaconda并创建conda环境_头秃的和尚的博客-CSDN博客
期间可能会遇到无法识别conda的命令,此时需要使用vim命令手动添加conda的环境变量。
(7条消息) conda: command not found解决办法_奥特曼熬夜不睡觉的博客-CSDN博客
下载完之后服务器文件中会出现对应的conda文件夹。
二、创建和激活环境
使用conda create -n xxx python = 3.8 创建虚拟环境,使用conda activate xxx激活该虚拟环境。

三、安装torch和对应包
进入虚拟环境后,使用pip install torch 和 pip install torchvision下载代码所需的pytorch框架、matplotlib和numpy
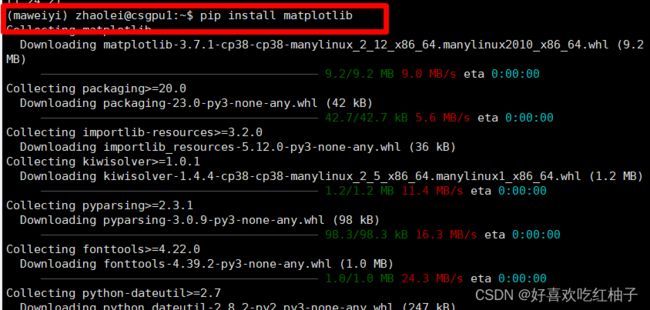

可以看到numpy之前以及下载好了,不用重新下载。耐心等待下载安装即可,最后可使用pip list命令查看一下现有的包,发现已经全部下载完毕
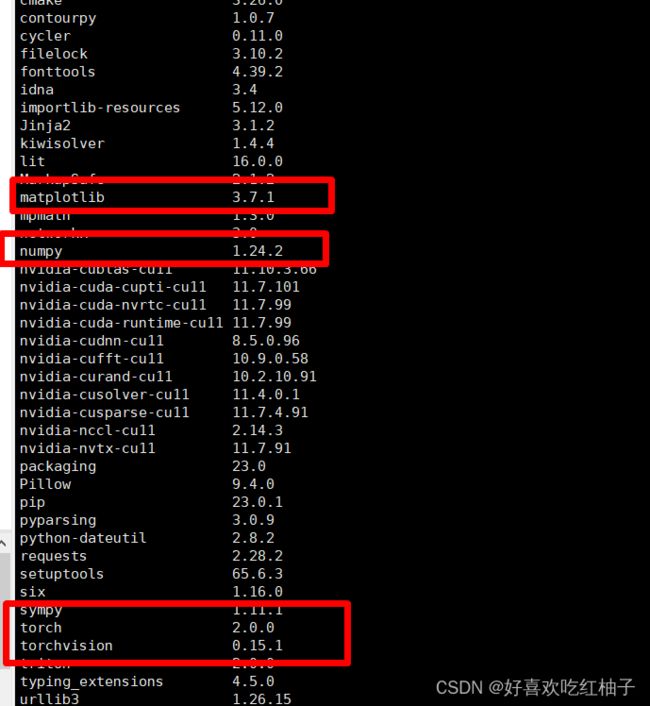
四、把程序上传到服务器中
准备代码
服务器上的环境都下载完毕后,回到pycharm中,打开运行的文件,我这里名为main.py,是一个简单地训练模型,代码如下。
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda, Compose
import matplotlib.pyplot as plt
# 采用torchvision里面的datasets里面的FashionMNIST数据集,该数据集在第一次用时需要下载,
# 数据集分为训练集(用于模型训练)和测试集(验证模型性能)
# 下面是训练集
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# 下面是测试集,同样需要下载
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
batch_size = 64
# 给训练集和测试集分别创建一个数据集加载器
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
for X, y in test_dataloader:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
# 定义网络模型
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
# 碾平,将数据碾平为一维
self.flatten = nn.Flatten()
# 定义linear_relu_stack,由以下众多层构成
self.linear_relu_stack = nn.Sequential(
# 全连接层
nn.Linear(28*28, 512),
# ReLU激活函数
nn.ReLU(),
# 全连接层
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
# x为传入数据
def forward(self, x):
# x先经过碾平变为1维
x = self.flatten(x)
# 随后x经过linear_relu_stack
logits = self.linear_relu_stack(x)
# 输出logits
return logits
# 调用刚定义的模型,将模型转到GPU(如果可用)
model = NeuralNetwork().to(device)
print(model)
# 定义损失函数,计算相差多少
loss_fn = nn.CrossEntropyLoss()
# 定义优化器,用来训练时候优化模型参数
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
# 定义训练函数,需要
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。
for batch, (X, y) in enumerate(dataloader):
# 将数据存到显卡
X, y = X.to(device), y.to(device)
# 得到预测的结果pred
pred = model(X)
# 计算预测的误差
loss = loss_fn(pred, y)
# 反向传播,更新模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每训练100次,输出一次当前信息
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model):
size = len(dataloader.dataset)
# 将模型转为验证模式
model.eval()
# 初始化test_loss 和 correct, 用来统计每次的误差
test_loss, correct = 0, 0
# 测试时模型参数不用更新,所以no_gard()
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
# 将数据转到GPU
X, y = X.to(device), y.to(device)
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
# 计算预测值pred和真实值y的差距
test_loss += loss_fn(pred, y).item()
# 统计预测正确的个数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
# 一共训练5次
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model)
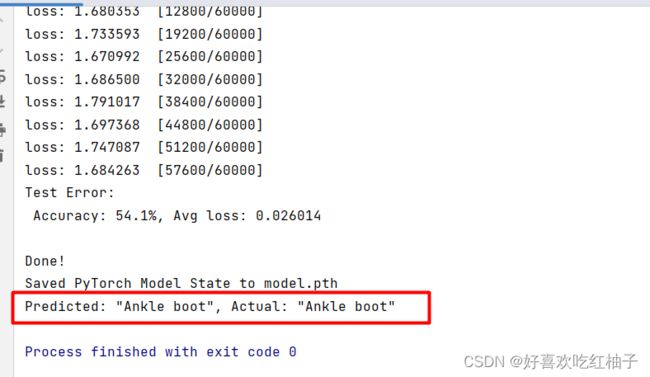
print("Done!")
# 保存训练好的模型
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")
# 读取训练好的模型,加载训练好的参数
model = NeuralNetwork()
model.load_state_dict(torch.load("model.pth"))
# 定义所有类别
classes = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
# 模型进入验证阶段
model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]
print(f'Predicted: "{predicted}", Actual: "{actual}"')2. 上传到服务器
按照我前面说的方法配置服务器,可以看到我的Python解释器已经变成了服务器上的conda虚拟环境,pycharm右下角也对应改变成了该环境。
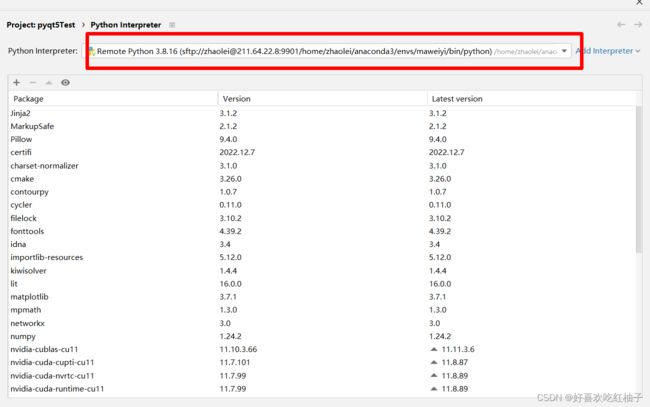
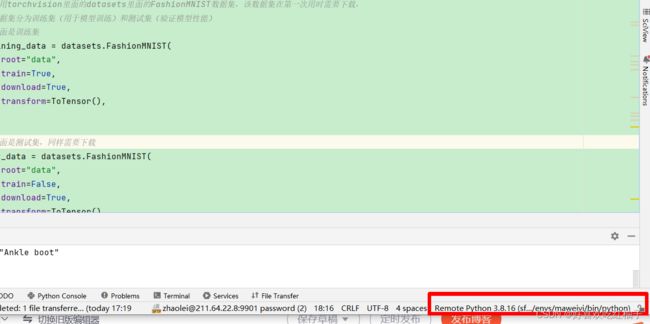
依次点击tools->deployment->upload to xxx,xxx为你连接的服务器的主机,即可完成对代码的上传。
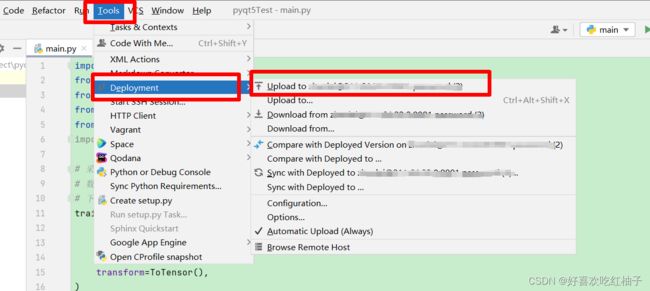
五、在pycharm上运行代码
点击运行,模型开始训练。可以看到虽然我们的pycharm中代码有报错,torch等环境都无法识别,但是服务器中以及进行了环境的配置,因此代码还是可以正常运行,因为代码实际是在远程服务器上运行的,pycharm担任了可视化界面的作用。

自动下载数据集,数据集会下载到服务器中的data文件夹下,下载后模型开始训练5轮,5轮后训练完成。
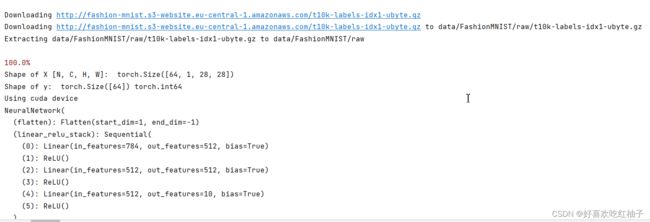
耐心等待训练……
等待……

训练完成!!!
六、代码解析
fashion-minist数据集
灰度图像,channel=1,大小为28*28

2. 要点解析
2.1 dataloader
https://blog.csdn.net/weixin_45662399/article/details/127601983?spm=1001.2014.3001.5502
在dataloader中,每一个对象元组由batchsize张图片对象imgs和batchsize个标签targets组成。输入图片的batchsize=64,说明一次输入64张图
故X有64张,每张图片通道=1,大小=28*28。
y为64张图像对应的标签,也为64个,为int型。
# 测试训练集数据加载器,X为输入图片,y为对应标签
for X, y in test_dataloader:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break输出:

2.2 使用gpu/cpu训练
如果gpu可用,则使用gpu进行训练,否则使用cpu
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))2.3 定义神经网络
# 定义网络模型
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
# 碾平,将数据碾平为一维
self.flatten = nn.Flatten()
# 定义linear_relu_stack,由以下众多层构成
self.linear_relu_stack = nn.Sequential(
# 全连接层
nn.Linear(28*28, 512),
# ReLU激活函数
nn.ReLU(),
# 全连接层
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
# x为传入数据
def forward(self, x):
# x先经过碾平变为1维
x = self.flatten(x)
# 随后x经过linear_relu_stack
logits = self.linear_relu_stack(x)
# 输出logits
return logits定义sequential
flatten:先把二维矩阵展平为一维向量,输入网络
全连接层1:输入为28*28,输出为512
激活层1:relu函数激活
全连接层2:输入和输出都是512
激活层2
全连接层3:输入为512,输出变为10
把以上操作都放在sequential序列里,即可按顺序依次操作。
2. 前向传播forward
把x进行输入,然后经过sequential定义的神经网络结构后输出logits,即为训练后对x图片的预测结果y'。
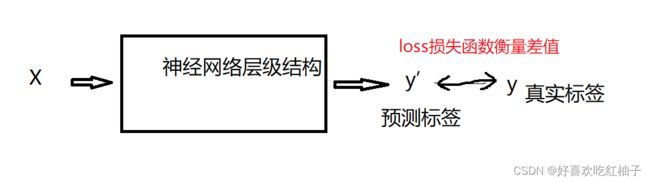
3. 损失函数
计算预测值和真实值的差值,使用交叉熵损失。
loss_fn = nn.CrossEntropyLoss()4. 优化器
随机梯度下降SSD
# 定义优化器,用来训练时候优化模型参数
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)2.4 网络训练train
获取到图标真实标签y和预测后的标签pred,使用loss_fn计算两者差距并保存在loss中,使用反向传播更新参数。
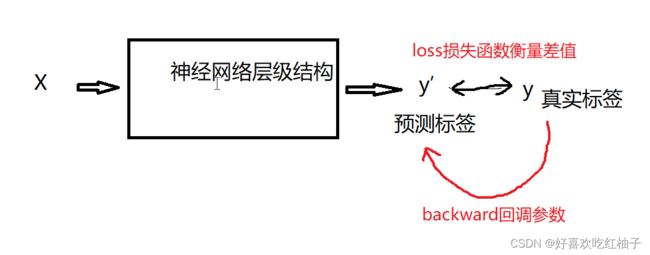
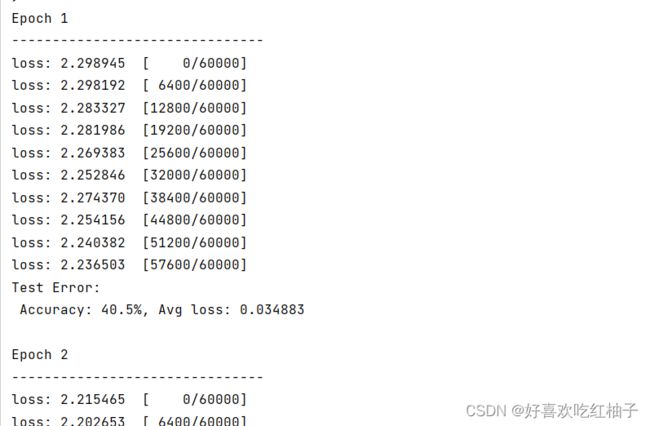
每训练100张,输出一次loss,可以看到loss值是越来越小的,说明模型训练越来越成功。
Epoch 1
-------------------------------
loss: 2.302158 [ 0/60000]
loss: 2.293674 [ 6400/60000]
loss: 2.289693 [12800/60000]
loss: 2.289169 [19200/60000]
loss: 2.281888 [25600/60000]
loss: 2.273417 [32000/60000]
loss: 2.272296 [38400/60000]
loss: 2.256825 [44800/60000]
loss: 2.247419 [51200/60000]
loss: 2.276489 [57600/60000]
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。
for batch, (X, y) in enumerate(dataloader):
# 将数据存到显卡
X, y = X.to(device), y.to(device)
# 得到预测的结果pred
pred = model(X)
# 计算预测的误差
loss = loss_fn(pred, y)
# 反向传播,更新模型参数
#梯度置零
optimizer.zero_grad()
#调整参数,反向传播,训练
loss.backward()
#更新参数
optimizer.step()
# 每训练100次,输出一次当前信息
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")2.5 网络测试test
模型在结束训练进行测试时,无需再进行参数的反向传播来调整参数,因此使用torch.no_grad( )。
def test(dataloader, model):
size = len(dataloader.dataset)
# 将模型转为验证模式
model.eval()
# 初始化test_loss 和 correct, 用来统计每次的误差
test_loss, correct = 0, 0
# 测试时模型参数不用更新,所以no_gard()
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
# 将数据转到GPU
X, y = X.to(device), y.to(device)
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
# 计算预测值pred和真实值y的差距
test_loss += loss_fn(pred, y).item()
# 统计预测正确的个数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")2.6 epoch次数
# 一共训练5次
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model)
print("Done!")设置epoch=5,一共训练5轮,每一次训练完后都会进行一次测试
2.7 model.pth
把训练好的模型文件保存在model.pth中,等到需要使用模型进行验证时,直接读取该模型文件即可。
# 保存训练好的模型
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")
# 读取训练好的模型,加载训练好的参数
model = NeuralNetwork()
model.load_state_dict(torch.load("model.pth"))2.8 网络验证validation
验证阶段和测试阶段一样,不进行梯度更新调整参数。
取测试集中的第一张图片和其对应标签,pred保存模型的预测类别,pred[0].argmax[0]得到所有预测类别得分最高的一类,然后找到classes中对应的具体类别,即可与真实类别比较判断预测结果。
# 定义所有类别
classes = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
# 模型进入验证阶段
model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]
print(f'Predicted: "{predicted}", Actual: "{actual}"')预测结果:可以看到模型预测的类别和真正类别一样,都是ankle boot。