Web自动化测试-Selenium快速入门
Web自动化测试(学习笔记一)——Selenium快速入门
- 安装
- 打开页面查找元素
- ActionChains
- Touch Actions
- 多窗口
- 多frame
- 隐式等待与显式等待
- javascript交互
- 文件上传
- 弹框处理
- remote开启Chrome调试
- 使用cookie
- 扩展:Page Object 基本原理
学习路径
- 官网.
- 学习文档
- 官方学习文档
安装
- selenium环境
- 各浏览器的driver(注意版本)Driver介绍
Chrome driver 下载地址:官网 淘宝镜像(推荐)
Firefox driver 下载地址:geckodriver - driver配置环境变量
- selenium IDE 火狐IDE (可直接录制、执行,并导出代码
打开页面查找元素
- 简单例子
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("http://www.python.org")
assert "Python" in driver.title
elem = driver.find_element_by_name("q")
elem.clear()
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
assert "No results found." not in driver.page_source
driver.close()
#quit将关闭整个浏览器,而close只会关闭一个标签页,如果你只打开了一个标签页,大多数浏览器的默认行为是关闭浏览器
- 元素定位
| 定位一个元素 | 说明 |
|---|---|
| find_element_by_id | 页面中第一个该 id 元素会被匹配并返回。如果找不到任何元素,会抛出 NoSuchElementException 异常。 |
| find_element_by_name | name元素(约定俗成,页面中ID和name是唯一的) |
| find_element_by_xpath | XPath是XML文档中查找结点的语法。当你想获取一个既没有id属性也没有name属性的元素时, 你可以通过XPath使用元素的绝对位置来获取他(这是不推荐的),或相对于有一个id或name属性的元素 (理论上的父元素)来获取你想要的元素。XPath定位器也可以通过非id和name属性查找元素。 |
| find_element_by_link_text | 页面中第一个匹配链接内容锚标签,会被匹配并返回 |
| find_element_by_partial_link_text | 部分a标签内容 |
| find_element_by_tag_name | 标签名的元素 |
| find_element_by_class_name | class属性的元素 |
| find_element_by_css_selector | 页面中第一个匹配该CSS 选择器的元素,会被匹配并返回。css比xpath快,因为css是样式定位,xpath从头到尾遍历。除xpath外,其余定位的底层都是cssselector。 |

| xpath | 说明 | cssselector | 说明 |
|---|---|---|---|
| / | 单斜杠,父子关系 | > | 大于号,父子关系 |
| * | 星,选取所有元素 | * | 星,选取所有元素 |
| // | 双斜杠,选取所有目标元素 | . | 对应class的元素 |
| @ | 属性,$x(’//*[@id=“sb_form_q”]’) | # | 对应id的元素,$(’#sb_form_q’) |
| //input[1] | 选取第一个 | [attribute=value] | 选择对应元素,$(’[id=“sb_form_q”]’) |
| //input[last()] | 选取最后一个 | div p | 空格,选择div元素内部的所有p元素 |
| //input[last()-1] | 选取倒数第二个 | div+p | 选择紧接在div元素之后的所有p元素 |
| //input[position()<4] | 选取最前面的3个 | :nth-child(n) | 选择属于其父元素的第n个子元素的相应元素,$(’#b_results a:nth-child(2)’) |
| //input[price>35.00] | 选取price元素的值大于35.00的 | ||
| //input[price>35.00]/title | 选取input元素中的title元素,其中price元素的值大于35.00 |

ActionChains
执行PC端的鼠标点击、右键、拖拽等事件。
执行原理:调用ActionChains的方法时,不会立即执行。而是会将所有的操作按顺序存放在一个队列里,当你调用perform()方法时,队列中的事件会依次执行。
- 链式写法
ActionChains(driver).move_to_element(element).click(element).perform()
- 分布写法
actions = ActionChains(driver)
actions.move_to_element(element)
actions.click(element)
actions.perform()
| ActionChains | 说明 |
|---|---|
| click(on_element=None) | 单击鼠标左键 |
| click_and_hold(on_element=None) | 点击鼠标左键,不松开 |
| context_click(on_element=None) | 点击鼠标右键 |
| double_click(on_element=None) | 双击鼠标左键 |
| drag_and_drop(source, target) | 拖拽到某个元素,然后松开 |
| drag_and_drop_by_offset(source, xoffset, yoffset) | 拖拽到某个坐标,然后松开 |
| key_down(value, element=None) | 按下某个键盘上的键 |
| key_up(value, element=None) | 松开某个键 |
| move_by_offset(xoffset, yoffset) | 鼠标从当前位置移动到某个坐标 |
| move_to_element(to_element) | 鼠标移动到某个元素 |
| move_to_element_with_offset(to_element, xoffset, yoffset) | 移动到距某个元素(左上角坐标)多少距离的位置 |
| perform() | 执行链中的所有动作 |
| release(on_element=None) | 在某个元素位置松开鼠标左键 |
| send_keys(*keys_to_send) | 发送某个键到当前焦点的元素 |
| send_keys_to_element(element, *keys_to_send) | 发送某个键到指定元素 |
| pause(seconds) | 在指定的持续时间内暂停(以秒为单位) |
| reset_actions() | 清除已存储在本地和远程端的操作 |
Touch Actions
ActionChains无法操作H5页面,TouchAction可以对H5页面进行操作,实现点击,滑动,拖拽,模拟手势等各种操作。
| TouchAction | 说明 |
|---|---|
| double_tap(on_element) | 双击 |
| flick(xspeed, yspeed) | 滑动 |
| flick_element(on_element, xoffset, yoffset, speed) | 从元素开始以指定的速度移动 |
| long_press(on_element) | 长按不释放 |
| move(xcoord, ycoord) | 移动到指定的位置 |
| perform() | 执行链中的所有动作 |
| release(xcoord, ycoord) | 在某个位置松开操作 |
| scroll(xoffset, yoffset) | 滚动到某个位置 |
| scroll_from_element(on_element, xoffset, yoffset) | 从某元素开始滚动到某个位置 |
| tap(on_element) | 单击 |
| tap_and_hold(xcoord, ycoord) | 某点按住 |
from selenium import webdriver
from selenium.webdriver import ActionChains, TouchActions
class TestAction():
def setup(self):
option = webdriver.ChromeOptions()
option.add_experimental_option("w3c",False)
self.driver = webdriver.Chrome(options=option)
def teardown(self):
self.driver.quit()
def test_click(self):
self.driver.get("https://cn.bing.com/")
self.driver.maximize_window()
self.driver.find_element_by_id("est_en").click()
a = self.driver.find_element_by_id("est_cn")
ActionChains(self.driver).click(a).perform()
def test_scroll(self):
self.driver.get("https://www.baidu.com/")
self.driver.maximize_window()
kw = self.driver.find_element_by_id("kw")
kw.send_keys("selenium")
su = self.driver.find_element_by_id("su")
action = TouchActions(self.driver)
action.tap(su).perform()
多窗口
当浏览器打开新的窗口时,想在新页面上操作,就需要切换窗口。获取窗口唯一的标识用句柄表示,即切换句柄,就可以切换窗口。
- 先获取当前的窗口句柄driver.current_window_handle
- 再获取所有的窗口句柄driver.window_handles
- 切换窗口driver.switch_to.window(list[no.])
from selenium import webdriver
class TestWindow():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.get("https://www.baidu.com/")
self.driver.maximize_window()
self.driver.implicitly_wait(5)
def teardown(self):
self.driver.quit()
def test_window(self):
a = self.driver.current_window_handle
print(a)
self.driver.find_element_by_link_text("新闻").click()
b = self.driver.window_handles
print(b)
self.driver.switch_to.window(b[-1])
c = self.driver.current_window_handle
print(c)
多frame
frame是html中的框架,即显示不止一个页面,分为垂直框架和水平框架(cols,rows)
frame标签包含frameset、frame、iframe三种。(frameset与普通标签一样)
| 切换 | 说明 |
|---|---|
| driver.switch_to.frame(frame_reference) | Switches focus to the specified frame, by index, name, or webelement.索引从0开始 |
| driver.switch_to.default_content() | 切换倒默认frame |
| driver.switch_to.parent_frame() | 切换到父级frame |
隐式等待与显式等待
- 强制等待,线程休眠一定时间 time.sleep(3)
- 隐式等待,设置一个等待时间,轮询查找(默认0.5秒)元素是否出现,如果没出现就抛出异常
driver.implicitly_wait(3) - 显式等待,在代码中定义等待条件,当条件发生时才继续执行代码,webdriverwait配合until和untilnot方法,程序每隔一段时间(默认0.5秒)进行条件判断,如果条件成立,则执行下一步,否则继续等待,直至超过设置的最长时间
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://cn.bing.com/")
try:
wait = WebDriverWait(driver, 10)
element1 = wait.until(EC.presence_of_element_located((By.ID, "id_a")))
element2 = wait.until(EC.element_to_be_clickable((By.ID, 'id_sd')),message="notfind_TimeoutException")
finally:
driver.quit()
| expected_condition类提供的方法 | 说明 |
|---|---|
| title_is | 判断当前页面的 title 是否完全等于(==)预期字符串,返回布尔值 |
| title_contains | 判断当前页面的 title 是否包含预期字符串,返回布尔值 |
| presence_of_element_located | 判断某个元素是否被加到了 dom 树里,并不代表该元素一定可见 |
| visibility_of_element_located | 判断元素是否可见(可见代表元素非隐藏,并且元素宽和高都不等于 0) |
| visibility_of | 同上一方法,只是上一方法参数为locator,这个方法参数是 定位后的元素 |
| presence_of_all_elements_located | 判断是否至少有 1 个元素存在于 dom 树中。举例:如果页面上有 n 个元素的 class 都是’wp’,那么只要有 1 个元素存在,这个方法就返回 True |
| text_to_be_present_in_element | 判断某个元素中的 text 是否 包含 了预期的字符串 |
| text_to_be_present_in_element_value | 判断某个元素中的 value 属性是否包含 了预期的字符串 |
| frame_to_be_available_and_switch_to_it | 判断该 frame 是否可以 switch进去,如果可以的话,返回 True 并且 switch 进去,否则返回 False |
| invisibility_of_element_located | 判断某个元素中是否不存在于dom树或不可见 |
| element_to_be_clickable | 判断某个元素中是否可见并且可点击 |
| staleness_of | 等某个元素从 dom 树中移除,注意,这个方法也是返回 True或 False |
| element_to_be_selected | 判断某个元素是否被选中了,一般用在下拉列表 |
| element_selection_state_to_be | 判断某个元素的选中状态是否符合预期 |
| element_located_selection_state_to_be | 跟上面的方法作用一样,只是上面的方法传入定位到的 element,而这个方法传入 locator |
| alert_is_present | 判断页面上是否存在 alert |
javascript交互
selenium可以执行js,直接使用js操作页面可以解决很多click不生效的问题,多段代码用分号隔开
| 调用js | driver.execute_script(“js代码”) |
|---|---|
| 返回js | driver.execute_script(“return js代码”) |
常用js代码
- window.alert(‘弹框’)
- a = document.getElementById(‘sb_form_q’).value
- document.title
- JSON.stringify(performance.timing)——页面的性能指标数据
- document.documentElement.scrollTop=10000
import pytest
from selenium import webdriver
class TestJs():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
self.driver.get("https://www.baidu.com/")
self.driver.maximize_window()
def teardown(self):
self.driver.quit()
@pytest.mark.skip
def test_scroll(self):
self.driver.find_element_by_id("kw").send_keys("selenium")
self.driver.execute_script("document.getElementById('su').click()")
self.driver.execute_script("document.documentElement.scrollTop=10000")
self.driver.find_element_by_partial_link_text("下一页").click()
def test_return(self):
code = self.driver.execute_script("return JSON.stringify(performance.timing)")
print(code)
文件上传
from time import sleep
from selenium import webdriver
class TestFile():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
self.driver.get("https://www.baidu.com/")
self.driver.maximize_window()
def teardown(self):
self.driver.quit()
def test_file_up(self):
self.driver.find_element_by_class_name("soutu-btn").click()
a = self.driver.find_element_by_xpath("//*[@id='form']/div/div[2]/div[2]/input")
a.send_keys("F:/PycharmProjects/img/2021-12-13_153042.png")
sleep(2)
弹框处理
| 操作alert常用方法 | 说明 |
|---|---|
| switch_to.alert | 获取当前页面上的弹框 |
| text | 返回alert、confirm、prompt中的文字信息 |
| accept | 接受弹框 |
| dismiss | 解散弹框 |
| send_keys("") | 发送文本至弹框 |
remote开启Chrome调试
开启 Chrome 的调试,复用正在打开并使用的浏览器页面。
chrome --remote-debugging-port=8233
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class TestDemo():
def setup(self):
option = Options()
option.debugger_address = "127.0.0.1:8233"
self.driver = webdriver.Chrome(options=option)
def teardown(self):
self.driver.quit()
def test_demo(self):
self.driver.find_element_by_id("est_en").click()
使用cookie
- 获取driver.get_cookies()——调试模式
- 获取的cookie存起来——shelve
- 添加driver.add_cookie(cookie)——for循环,注意expiry
import shelve
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class TestDemo():
def setup(self):
option = Options()
option.debugger_address = "127.0.0.1:8233"
self.driver = webdriver.Chrome(options=option)
def teardown(self):
self.driver.quit()
def test_demo(self):
db = shelve.open("cookies")
db['cookie'] = self.driver.get_cookies()
import shelve
from time import sleep
from selenium import webdriver
class TestDemo():
def setup(self):
self.driver = webdriver.Chrome()
def teardown(self):
self.driver.quit()
def test_demo(self):
self.driver.get('https://work.weixin.qq.com/wework_admin/frame')
db = shelve.open("cookies")
cookies = db['cookie']
for cookie in cookies:
if "expiry" in cookie.keys():
cookie.pop("expiry")
self.driver.add_cookie(cookie)
self.driver.get('https://work.weixin.qq.com/wework_admin/frame')
sleep(3)
扩展:Page Object 基本原理
selenium官方说明
Martin Flower
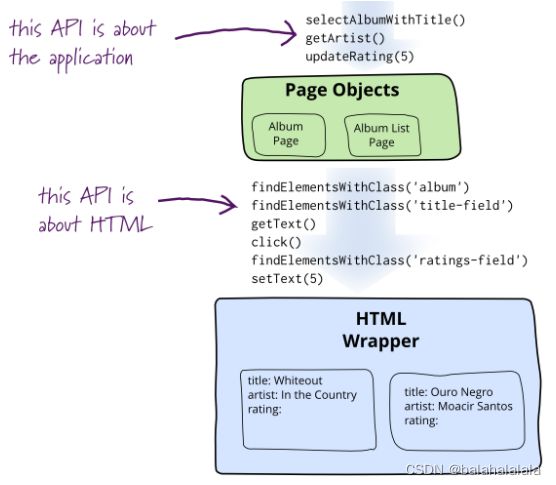
个人理解:封装!将操作、验证等等分开管理。为页面中重要的功能创建page类,将操作细节封装成一个个方法。通过pageA进入pageB时,在pageA的某个方法中return pageB。