分布式系统
目录
分布式存储系统
分布式计算系统
分布式消息队列系统
分布式机器学习系统
分布式框架
分布式数据库

分布式存储系统
分布式存储系统分为两大类中心化控制架构(HDFS)和完全无中心架构(Ceph)。
中心化控制架构:以单独元数据服务器为中间控制,具体数据存储服务器为分布式存储的架构存储。

用户第一步先访问元数据的服务器节点,这个元数据服务器为中间控制,每一次访问真正数据前,都需要先访问元数据服务节点,服务器节点存储的是元数据,元数据是描述数据的数据,元数据存储了真实数据的描述信息,包含具体数据的路径以及相关信息;
完全无中心架构:客户端通过设备映射关系计算出具体数据的位置,直接访问。客户端通过Mon通信服务,计算得到客户端需要写到的具体文件路径。

客户端有一个Mon服务,根据Mon服务经过一系列的运算可以得到一个想要访问数据的具体地址。Mon在客户端和数据端都存在,两者之间会有一个通信来保持相关节点信息的更新,客户端通过Mon服务和对应的信息可以计算得到想要访问的具体数据的具体文件路径,以便于直接访问。
分布式计算系统
常用的分布式计算系统主要有三类:HadoopMapReduce、Spark(批处理+实时处理)、Flink(实时处理)。
HadoopMapReduce,一种大数据编程模型,将数据处理运用Map和Reduce的概念进行分而治之将大任务划分成小任务的处理。应用场景:批处理(一次性处理数据)


HadoopMapReduce的特点是分布式计算、中间结果都存放在硬盘、无法查询上一步的结果、效率一般。
Spark是基于内存优化的分布式大数据计算框架,分而治之,将大任务划分成小任务,引入RDD概念。应用场景:批处理(效率最好) + 流处理(微小批处理)

在Spark中每一个执行计划的中间结果都是写在分布式内存中,当需要读取数据的时候,可以直接从分布式内存中直接进行读取,这种基于内存优化的分布式大数据框架在单纯计算的时候高于HadoopMapReduce,所以Spark在批处理中效率是最好的,而且Spark也可以做流处理,流处理就是实时的处理。
Flink,分布式大数据处理框架,对流数据可以进行计算,实时处理。

分布式消息队列系统
Kafka是一个分布式消息队列。具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑计算。
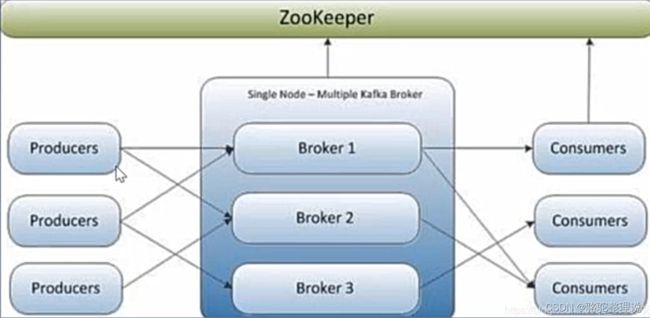
Topic:定义特定的消息,可以让生产者和消费者都从该Topic中进行数据读写;
Partition:一个Topic可以分成好几个分区;
Broker:服务器存储数据,可以做备份。
分布式机器学习系统
Spark ML和分布式Tensorflow。
Spark ML,以Spark为计算引擎的分布式机器学习框架。提供一个分布式的模型训练环境,提供一个训练数据集分布式处理的环境。常见机器学习框架比较:Sklearn、Tensorflow、Pytorch。
分布式TensorFlow,分布式TensorFlow是在分布式集群上进行训练
分布式框架
SpringCloud微服务全家桶式的框架,内部涵盖了开发中所需的各个组件。SpringCloud是http协议,通过心跳通知服务的消费者。Dubbo是Alibaba开源的高性能轻量级分布式服务框架,提供面向接口的远程方法调用,负载均衡和智能容错以及服务的自动注册和发现机制。
分布式数据库
TiDB、Google Spanner、OceanBase。