Scala函数式编程
一、基本函数编程
在Scala 中函数式编程和面向对象编程完美融合在一起了
1 基础概念
1) 面向对象编程
解决问题,分解对象,行为,属性,然后通过对象的关系以及行为的调用来解决问题。
对象:用户
行为:登录、连接 JDBC、读取数据库属性:用户名、密码
Scala 语言是一个完全面向对象编程语言。万物皆对象对象的本质:对数据和行为的一个封装
2) 函数式编程
解决问题时,将问题分解成一个一个的步骤,将每个步骤进行封装(函数),通过调用这些封装好的步骤,解决问题。
例如:请求->用户名、密码->连接 JDBC->读取数据库
Scala 语言是一个完全函数式编程语言。万物皆函数。函数的本质:函数可以当做一个值进行传递
// (1)函数定义
def f(arg: String): Unit = {
println(arg)
}
// (2)函数调用
// 函数名(参数)
f("hello world")2 函数和方法的区别
1)核心概念
- 为完成某一功能的程序语句的集合,称为函数。
- 类中的函数称之方法。
2)案例实操
- Scala 语言可以在任何的语法结构中声明任何的语法
- 函数没有重载和重写的概念;方法可以进行重载和重写
- Scala 中函数可以嵌套定义
object TestFunction {
// 方法可以进行重载或重写,也可以执行
def main():Unit={}
def main(args: Array[String]): Unit = {
// (1)Scala 语言可以在任何的语法结构中声明任何的语法
import java.util.Date
new Date()
// (2) 函数没有重写和重载的概念,重写报错
def test():Unit = {
println("test")
}
//def test(i:Unit):Unit = { // error
// println("test")
//}
// (3)Scala 中函数可以嵌套定义
def myFun():Unit={
println()
}
}
3 函数定义
3.1 无参,无返回值
def test1(): Unit ={
println("无参,无返回值")
}
test1()
3.2 无参,有返回值
def test2():String={
return "无参,有返回值"
}
println(test2())
3.3 有参,无返回值
def test3(s:String):Unit={
println(s)
}
test3("haha")
3.4 有参,有返回值
def test4(s:String):String={
return s+"有参,有返回值"
}
println(test4("hello "))
3.5 多参,无返回值
def test5(name:String, age:Int):Unit={
println(s"$name, $age")
}
4 函数参数
(1)可变参数
(2)如果参数列表中存在多个参数,那么可变参数一般放置在最后
(3)参数默认值,一般将有默认值的参数放置在参数列表的后面
(4)带名参数
4.1 可变参数
def test(s: String*): Unit = {
println(s)
}
test()
test("haha", "lala")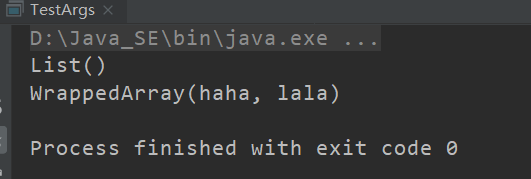
4.2 如果参数列表中存在多个参数,那么可变参数一般放置在最后
def test(s0: String, s: String*): Unit = {
println(s"${s0}有学生:${s}")
}
test("sfm", "zmy", "hlq", "zdc", "...") 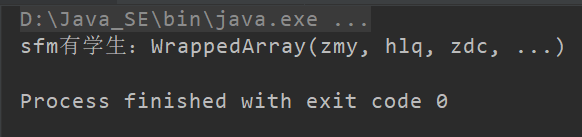
4.3 参数默认值,一般将有默认值的参数放置在参数列表的后面
def test(name: String, age: Int = 23): Unit = {
println(s"${name}今年${age}岁")
}
test("chen chen")
// 如果参数传递了值,那么会覆盖默认值
test("chen chen", 18) 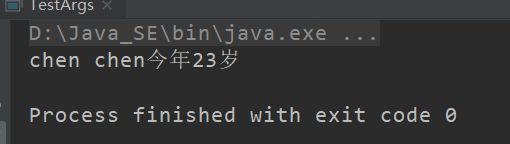

4.4 带名参数
test(name="辰辰")5 函数至简原则
函数至简原则:能省则省
- return 可以省略,Scala 会使用函数体的最后一行代码作为返回值
- 如果函数体只有一行代码,可以省略花括号
- 返回值类型如果能够推断出来,那么可以省略(:和返回值类型一起省略)
- 如果有 return,则不能省略返回值类型,必须指定
- 如果函数明确声明unit,那么即使函数体中使用 return 关键字也不起作用
- Scala 如果期望是无返回值类型,可以省略等号
- 如果函数无参,但是声明了参数列表,那么调用时,小括号,可加可不加
- 如果函数没有参数列表,那么小括号可以省略,调用时小括号必须省略
- 如果不关心名称,只关心逻辑处理,那么函数名(def)可以省略
5.0 函数标准写法
// (0)函数标准写法
def f(s: String): String = {
return s + " chen chen"
}
println(f("Hello"))5.1 return 可以省略,Scala 会使用函数体的最后一行代码作为返回值
def f1(s: String): String = {
s + " chen chen1"
}
println(f1("Hello"))5.2 如果函数体只有一行代码,可以省略花括号
def f2(s: String): String = s + " chen chen1"
println(f2("Hello"))5.3 返回值类型如果能够推断出来,那么可以省略(:和返回值类型一起省略)
def f3(s: String) = s + " chen chen1"
println(f3("Hello"))5.4 如果有 return,则不能省略返回值类型,必须指定
def f4(s: String): String = {
return s + " chen chen"
}
println(f4("Hello"))
5.5 如果函数明确声明unit,那么即使函数体中使用 return 关键字也不起作用
def f5(s: String): Unit = {
return s + " chen chen"
}
println(f5("Hello"))
5.6 Scala 如果期望是无返回值类型,可以省略等号(将无返回值的函数称之为过程)
def f6(s: String) {
println(s + " chen chen")
}
f6("Hello")5.7 如果函数无参,但是声明了参数列表,那么调用时,小括号,可加可不加
def f7() = "明宇"
println(f7)
println(f7()) 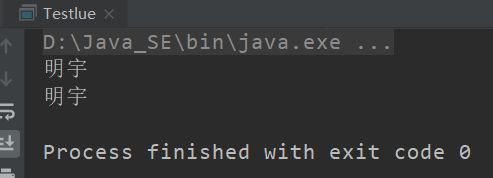
5.8 如果函数没有参数列表,那么小括号可以省略,调用时小括号必须省略
def f8 = "辰辰"
println(f8)
//println(f8()) // error5.9 如果不关心名称,只关心逻辑处理,那么函数名、def 可以省略【匿名函数】
() => {
s"nihao"
}
// 调用
def f9 = (x: String) => {
s"nihao,${x}"
}
println(f9("ming yu"))
二、高阶函数编程
所谓的高阶函数,其实就是将函数当成一个类型来使用,而不是当成特定的语法结构。
1 函数可以作为值进行传递
package com.mingyu.spark.core.test
object Test_High_Fun {
def main(args: Array[String]): Unit = {
def f(name: String) = {
println(s"hello,${name}")
}
// 将函数f作为对象赋值给v1
// Function1 -> 有一个参数的函数类型
// [String,Unit] -> 参数类型为String,返回值类型为Unit
// 函数对象参数最多有22个,并不是函数的参数最多有22个
val v1: Function1[String, Unit] = f _
//println(v1.getClass.getSimpleName) // Test_High_Fun$$$Lambda$1/517938326
v1 //不会执行,只是一个对象
v1("mingyu")
// 以上方法太麻烦,使用以下方法
def test2(name: String, age: Int): Unit = {
println(s"${name}今年${age}岁了:)")
}
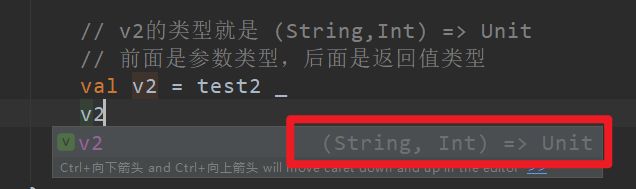
// v2的类型就是 (String,Int) => Unit
// 前面是参数类型,后面是返回值类型
val v2 = test2 _
v2("cc", 23)
}
}

2 函数可以作为参数进行传递
package com.mingyu.spark.core.test
object Test_High_Fun {
def main(args: Array[String]): Unit = {
// 函数对象作为参数使用
def fun(): Unit = {
println("test...")
}
// 参数类型是函数对象
def test(f: () => Unit): Unit = {
f()
}
val f = fun _
test(f) // test...
}
}
3 函数可以作为函数返回值返回
package com.mingyu.spark.core.test
object Test_High_Fun {
def main(args: Array[String]): Unit = {
def outer(): () => Unit = {
def inner(): Unit = {
println("inner...")
}
inner _
}
outer()() // inner...
}
}
4 匿名函数
object Test {
def main(args: Array[String]): Unit = {
def fun( f:Int => Int ): Int = {
f(20)
}
println(fun((x:Int)=>{x * 10}))
println(fun((x)=>{x * 10}))
println(fun((x)=>x * 10))
println(fun(x=>x * 10))
println(fun(_ * 10))
}
}
5 闭包
闭包:如果一个函数,访问到了它的外部(局部)变量的值,那么这个函数和他所处的环境,称为闭包
object Test_High_Fun {
def main(args: Array[String]): Unit = {
// addX 函数接受一个整数参数 x,并返回一个函数,
// 该函数接受一个整数参数 y,并返回 x + y 的结果。
// 然后,我们通过调用 addX(5) 来创建一个新函数 addFive,它将 5 作为 x 的值。
// 最后,我们调用 addFive(3),它返回 8,因为 5 + 3 = 8。
def addX(x: Int) = (y: Int) => x + y
val addFive = addX(5)
println(addFive(3)) // 8
}
}6 函数柯里化
函数柯里化:把一个参数列表的多个参数,变成多个参数列表。
package com.mingyu.spark.core.test
object Test_High_Fun {
def main(args: Array[String]): Unit = {
//def add(x: Int, y: Int) = x + y
//println(add(1, 2)) // 输出 3
// 现在,我们可以使用函数柯里化来将 add 函数转换为一系列只接受单个参数的函数:
def add(x: Int) = (y: Int) => x + y
val addOne = add(1)
println(addOne(2)) // 输出 3
"""
|在这个例子中,add 函数接受一个整数参数 x,并返回一个函数,
|该函数接受一个整数参数 y,并返回 x + y 的结果。
|然后,我们通过调用 add(1) 来创建一个新函数 addOne,它将 1 作为 x 的值。
|最后,我们调用 addOne(2),它返回 3,因为 1 + 2 = 3。
|
|通过函数柯里化,我们可以轻松地创建新的函数,例如 addTwo、addThree 等,
|它们分别将 2 和 3 作为 x 的值,并接受单个整数参数 y。
|这使得我们可以更容易地组合这些函数,并创建更复杂的函数,例如将它们作为参数传递给其他函数。
""".stripMargin
}
}
7 递归
package com.mingyu.spark.core.test
object Test_High_Fun {
def main(args: Array[String]): Unit = {
def fibo(n: Int): Int = {
if (n > 2) return fibo(n - 1) + fibo(n - 2)
else if (n == 2) return 1
else return 0
}
//println(fibo(3))
for (elem <- 1 to 10) print(fibo(elem) + "\t")
}
}
// 0 1 1 2 3 5 8 13 21 34 8 控制抽象
package com.mingyu.spark.core.test
object Test_High_Fun {
def main(args: Array[String]): Unit = {
"""
|在Scala中,控制抽象是一种将控制流作为函数参数传递的技术。
|换句话说,控制抽象允许我们将一些代码块作为参数传递给函数,并在函数内部执行这些代码块。
|这使得我们可以编写更加灵活和可复用的代码。
|
|Scala中的控制抽象通常使用高阶函数和函数字面量实现。
|高阶函数是一个接受一个或多个函数作为参数的函数,而函数字面量是一个匿名函数,
|它可以在任何需要函数的地方使用。
|
|Scala中的控制抽象通常用于实现以下功能:
|
|延迟计算:控制抽象可以用于延迟计算,即只有在需要的时候才计算某个值。例如,lazy 关键字就是一种控制抽象,它允许我们延迟计算某个值,直到我们需要使用它。
|错误处理:控制抽象可以用于错误处理,例如使用 try 和 catch 块捕获异常。
|并发编程:控制抽象可以用于并发编程,例如使用 Future 和 Promise 实现异步计算
""".stripMargin
"""
|repeat 函数接受一个整数参数 n 和一个函数字面量 f,
|并在函数内部执行 f 函数 n 次。
""".stripMargin
def repeat(n: Int)(f: => Unit): Unit = {
for (i <- 1 to n) f
}
// 调用 repeat(5) 来创建一个新函数,并将一个打印语句作为 f 函数的参数
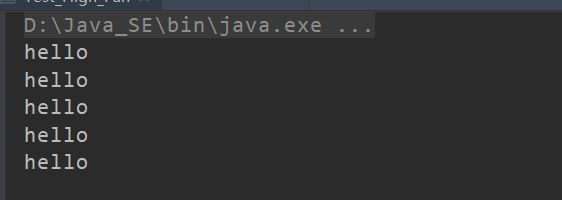
val f2 = repeat(5) {
println("hello")
}
// 用这个新函数,它将打印语句执行了 5 次
f2
}
}
(Scala语言真的好奇特)
9 惰性加载
package com.mingyu.spark.core.test
object Test_High_Fun {
def main(args: Array[String]): Unit = {
"""
|在这个例子中,变量 y 的值是立即计算出来的,因为它是一个非惰性值。
|而变量 z 的值需要计算 x 的值,因此在第一次访问 x 时,初始化代码块被执行,
|输出了 "Initializing x"。然后,变量 z 的值被计算为 43。
|
|惰性加载在 Scala 中还有许多其他的应用场景,例如:
|
|惰性集合:Scala 中的集合类支持惰性加载,可以在需要时才计算集合中的元素。
| 例如,Stream 就是一种惰性集合,它只会计算需要的元素,而不会一次性计算所有元素。
|惰性参数:Scala 中的函数可以定义惰性参数,即只有在需要时才会计算参数的值。
| 例如,可以使用 => 来定义惰性参数,例如 def f(x: => Int) = ...。
|
|此外,
| 在 Scala 中,惰性参数的值在被第一次访问后会被存放在一个临时变量中。
| 这个临时变量只会在第一次访问时被计算,然后将计算结果保存在这个变量中,
| 以后再次访问时直接返回这个变量的值,而不会重新计算。
|
|具体来说,当我们在函数体内访问一个惰性参数时,Scala 会自动将这个参数转换成一个函数,
|然后调用这个函数。这个函数只会在第一次调用时被计算,然后将计算结果保存在一个临时变量中。
|以后再次调用这个函数时,直接返回这个临时变量的值,而不会重新计算。
""".stripMargin
lazy val x = {
println("Initializing x")
42
}
val y = 1 + 2
println("y = " + y) // 输出 "y = 3"
"""
|第一次调用x,输出:
|Initializing x
|z = 43
""".stripMargin
val z = x + 1
println("z = " + z)
"""
|第二次调用x,输出
|u = 43
""".stripMargin
val u = x + 1
println("u = " + u)
}
}