数据结构单链表的创建以及简单操作
在数据结构中:
目录
一、数据节点类型结构体封装
二、创建单链表
1、创建链表
2、头部插入
3.遍历链表
4.尾部插入
5.释放链表
链表可以解决顺序表无法开辟连续空间的问题,大大提高了内存的利用率。这使我们在开发中不再局限于小型数据量的项目。
链表:
- 逻辑结构为:线性结构(是一对一的)。
- 存储结构为:链式结构(但是在内存中不一定是连续的)。
 根据上图, 顺序表和链表的区别一目了然。
根据上图, 顺序表和链表的区别一目了然。
在链表中,每个数据元素都是一个节点,每个节点都分为数据域和指针域:
数据域:用于存储数据元素的信息
指针域:指向下一个节点的首地址
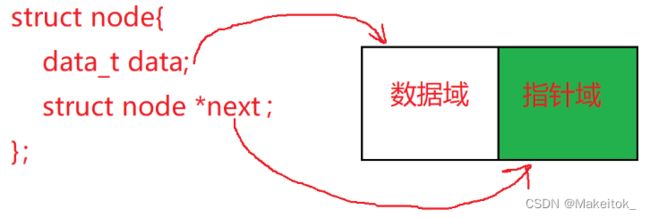
这样的节点数据类型在传统的C语言库里没有这样数据类型定义,所以我们就要用结构体的方式来封装节点。
一、数据节点类型结构体封装
typedef int data_t;//此处是用类型重命名了一个数据节点类型 data_t
//用typdef可以类型重定义任意数据类型
//结构体分装
struct node{
data_t data;//数据域
struct node *next;//指针域
};以上就是一个数据节点类型的声明,用于链表的节点创造。
二、创建单链表
1、创建链表
链表分为有头链表和无头链表,此文章创建的是有头链表。
有头链表的创建本质就是创建头节点,一般来说头节点是数据域不作使用,所以可以设置成任意数据。
//重定义数据类型
typedef int data_t;
//封装数据节点类型
typdef struct node{
data_t data;//数据域
struct node *next;//指针域
} link_list_t;
1.定义链表头节点指针
link_list_t *L = NULL;//初始化为空
2.从堆区申请头节点空间
L = (link_list_t *)malloc(sizeof(link_list_t));
3.初始化头节点
L->data = -1;//不作使用 随意设置
L->next = NULL;
4.返回头结点首地址
return L;总结(代码实现):
//函数源码
/*
*功能:创建新节点
*参数:空
*返回值:成功创建新节点的首地址
*/
link_list_t *create_list(void){
link_list_t *L = NULL;
//申请节点空间
L = (link_list_t *)malloc(sizeof(link_list_t));
if(NULL == L){
puts("创建链表节点失败");
return NULL;
}
//初始化节点
L->data = -1;
L->next = NULL;
//返回节点首地址
return L;
} 2、头部插入
当创建链表成功后(本质是创建头节点),对链表进行操作--头部插入。
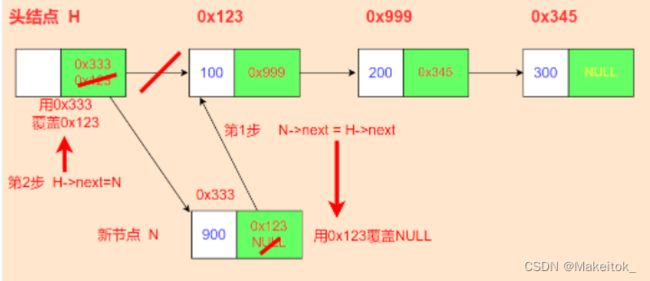
以上是头部插入的逻辑图。
算法思路:
1.要先创建一个新节点来存放要插入的数据
link_list_t *N = (link_list_t *)malloc(sizeof(link_list_t));
2.初始化新节点
N->data = value;//要插入的数据 value为传参过来的数值
N->next = NULL;
3.进行头部插入
link_list_t *Q = L;//建议定义一个新的同类型指针来接收传过来的指针参数
//目的是为了保护调用者的数据 防止出现不可预知的错误
N->next = Q->next;//将头节点的指针域赋值给新节点的指针域
Q->next = N;//再将头节点的指针域存放新节点的首地址即可指向新节点总结(代码实现):
//函数源码
/*
*功能:对单链表进行头部插入
*参数:原单链表的首地址,要插入的数据值
*返回值:成功返回0 失败返回-1
*/
int head_insert(link_list_t *L,data_t value){
//健壮性判断 判断传过来的指针参数是否合法
if(NULL == L){
puts("传入参数非法");
return -1;
}
//创建新节点
link_list_t *N = (link_list_t*)malloc(sizeof(link_list_t));
if(NULL==N){
puts("创建新节点失败");
return -1;
}
//初始化新节点
N->data = value;
N->next = NULL;
//头部插入操作
link_list_t *Q = L;
N->next = Q->next;
Q->next = N;
return 0;
}3、遍历链表

算法思路:
1.首先判断传过来的表参数是否合法
2.确保表内不为空,有数据遍历
3.我们操作的是有头链表,有效数据为头节点的下一个节点的数据域开始,可以定义一个指针指向头节点的下一个节点
4.单链表的尾节点的指针域为NULL,所以可以循环遍历,直到节点的指针域为NULL,作为结束的条件总结(代码实现):
//函数源码
/*
*功能:遍历输出单链表内所有节点的数据域
*参数:原表参数的首地址
*返回值:成功返回0 失败返回-1
*/
int show_list(link_list_t *L){
//健壮性判断
if(NULL == L){
puts("传入参数非法");
return -1;
}
//判断表是否为空
if(NULL == L->next){
puts("链表为空 无数据可遍历");
return -1;
}
//定义一个数据节点指针变量Q指向头节点的下一位
//直接指向有效数据位
link_list_t *Q = L->next;
//循环遍历输出数据域
while(NULL == Q){
printf("%d ",Q->data);//打印有效数据节点的数据
Q = Q->next;
}
return 0;
}4、尾部插入
算法思路:
1.判断表参数是否合法
2.创建新节点并初始化来存放要插入的数据
3.移动指针到链表的尾部,可以根据尾部节点指针域为NULL的特点作为循环移动的结束条件
4.插入操作
将新的节点的首地址赋值给为节点的指针域即可总结(代码实现):
//函数源码
/*
*功能:单链表尾部插入新节点
*参数:链表的指针参数,要插入的数据值
*返回值:成功返回0 失败返回-1
*/
int tail_insert(link_list_t *L,data_t value){
//健壮性判断
if(NULL == L){
puts("传入参数非法");
return -1;
}
//创建新节点
link_list_t *N = (link_list_t *)malloc(sizeof(link_list_t));
if(N == NULL){
puts("创建新节点失败");
return -1;
}
//初始化新节点
N->data = value;
N->next = NULL;
//循环移动指针指向尾部节点
while(Q->next != NULl){
Q = Q->next;//遍历到链表最后一个节点
}
//进行插入操作
Q->next = N;
return 0;
}5、释放链表
算法思路:
1.定义一个节点指针变量Q作为动点 初始化为链表头节点的指向
link_list_t *Q = *L;//*L的原因是指针传参要用耳机指针
//不然释放的只是给传过来的指针参数开辟的内存空间 并不是原单链表
2.Q作为动点指向头节点的下一位
Q = Q->next;
3.将头节点*L释放掉
free(*L);
4.将Q重新赋值给*L,同时Q指向下一个节点
*L = Q;
Q = Q->next;//此步骤可以放在循环里的第一步总结(代码实现):
//函数源码
/*
*功能:释放单链表
*参数:链表参数首地址
*返回值:成功返回0 失败返回-1
*/
int free_list(link_list_t **L){
//健壮性判断
if(NULL == L || NULL == *L){
puts("传入参数非法");
return -1;
}
//定义一个节点数据类型变量作为动点
link_list_t *Q = *L;
//循环释放
while(*L != NULL){
Q = Q->next;
printf("%d即将被释放",(*L)->data);
free(*L);
*L = Q;
}
*L = NULL;
return 0;
}6、任意位置插入数据
算法思路:
1.进行健壮性判断指针参数是否合法 以及表内是否为空
2.定义一个动点指针--用来确定插入位置的定位左右
link_list_t *Q = L;
3.用循环 移动Q的指向 用于定位 将位置确定到要插入位置的前一个位置
4.注意:
单链表在任意位置插入数据时需要考虑 空表和非空表两种情况
空表时 位置参数只能是 0 其他都不可以
单链表在插入操作时由于每个节点保存的信息只有 节点数据和下一个节点的地址信息,所以我们在插 入操作时要定位到要插入的位置的前一个节点位置。否则直接定位到要插入的位置是无法让新节点插入到对应位置上的,如果想要插入对应位置又无法与前一个节点建立联系(节点中没有存储前一个节点的信息)
5.插入操作:(定义一个新节点存放要插入的数据 再定义一个指针类型节点Q接收传过来的指针参数L)
新节点N的指针域 = Q指向的节点的指针域
Q指向的节点的指针域 = 新节点N总结(代码实现):
//函数源码
/*
*功能:能在单链表任意位置插入数据
*参数:原单链表指针参数,要插入的位置,要插入的数据
*返回值:成功返回0 失败返回-1
*/
int insert_pos(link_list_t *L,int pos,data_t value){
//健壮性判断
if(NULL == L){
puts("传入参数非法");
return -1;
}
//位置参数判断
if(pos < 0){
puts("位置参数非法");
return -1;
}
//创建新节点
link_list_t *N = (link_list_t *)malloc(sizeof(link_list_t));
if(N == NULL){
puts("创建节点失败");
return -1;
}
//初始化节点
N->data = value;
N->next = NULL;
//定位操作
int i= 0;
link_list_t *Q = L;
for(;i0){
printf("表为空表 未知参数必须等于0\n");
return -1;
}
if(NULL==Q->next && (inext;
}
//插入操作
N->next = Q->next;
Q->next = N;
return 0;
} 7、任意位置删除数据
算法思路:
1.判断表参数和位置参数是否都合法
2.定位节点 循环移动指针直到指向要删除的位置的前一个节点
3.删除操作总结(代码实现):
//函数源码
/*
*功能:能在链表中任意位置删除数据
*参数:原链表指针参数,要删除的数据的位置
*返回值:成功返回0 失败返回-1
*/
int insert_pos(link_list_t *L,int pos){
//健壮性判断
if(NULL==L){
puts("传入表参数非法");
return -1;
}
if(NULL==L->next){
puts("表为空表 无数据可删除");
return -1;
}
if(0>pos){
puts("位置参数必须大于 0");
return -1;
}
//定位操作
int i = 0;
link_list_t *Q = L;
for(;inext;
if(NULL==Q->next && pos>0){//此处判断表只有一个元素时 pos的合法性
printf("表只有一个元素 只可以删除 0 位置节点\n");
return -1;
}
if(NULL==Q->next->next && inext;
Q->next = Q->next->next;
printf("%d 将被删除\n",P->data);
P->next = NULL;
free(P);
P = NULL;
return 0;
} 9、翻转链表
算法思路:
1.可以将一个链表截断成两个链表,一分为二
如:我们有一个 L 表,可以将它截成 L 表和 Q表。
link_list_t *Q = L->next->next;//此处的的截断点在 L 表数据节点的第一个节点后
//将第一个数据节点后的节点由 Q控制
L->next->next = NULL;//彻底断掉
2.将 Q 表的节点通过头删法 依次对 L表进行头部插入数据
link_list_t *P = Q;
while(Q!=NULL){
P = Q;
Q = P->next;
P->next = L->next;
L->next = P;
}
直至Q 表所有节点插入L表停止,
至此链表翻转完成总结(代码实现):
//函数源码
/*
*功能:将单链表翻转
*参数:原链表指针参数
*返回值:成功返回0 失败返回-1
*/
int turn_list(link_list_t *L){
//健壮性判断
if(NULL==L){
puts("传入表参数非法");
return -1;
}
if(NULL==L->next || NULL==L->next->next){
puts("表为空表或只有一个数据元素 无需翻转");
return -1;
}
//翻转操作
//将原表分为两个表 Q 表和 L表
link_list_t *Q = L->next->next;
L->next->next = NULL;
//将 P 表中的节点 依次对 L 表进行头部插入
link_list_t *P = Q;
while(Q!=NULL){
P = Q;
Q = P->next;
P->next = L->next;
L->next = P;
}
return 0;
}至此,数据结构创建单链表以及相关简单操作的算法思想以及思路就分享完毕啦!作者也是个数据结构的初学者,这是在学习过程中的笔记整理,在此分享,如果文章内容有什么错误或者是不足的地方,欢迎伙伴们向我私信或者评论告诉我,我会及时改正~谢谢(#^.^#)