经验整理-1-多线程高并发-100-@
参考路人甲java系列:https://www.cnblogs.com/itsoku123/p/11424473.html
12.4.3 JDK状态转换、线程状态的流转
此项忽略

看此项
https://blog.csdn.net/Hollake/article/details/89671232
| 状态名称 | 说明 |
| NEW | 初始状态,线程刚被构建,但是还没有调用start()方法 |
| RUNNABLE | 运行状态,Java系统系统中将操作系统中的就绪和运行两种状态笼统地称为“运行中” |
| BLOCKED | 阻塞状态,表示线程阻塞于锁 |
| WAITTING | 等待状态,表示线程进入等待状态,进入该状态表示当前线程做出一些特定动作(通知或者中断)--一直等,直到被通知才去参考抢锁 |
| TIME_WAITTING | 超时等待状态,该状态不同于等待状态,它可以在指定的时间后自行返回---超t时间后,自动去参考抢锁 |
| TERMINATED | 中止状态,表示当前线程已经执行完毕 |

三种状态:就绪、运行、等待
五种状态:新建、就绪、运行、等待、退出
上面已经把RUNNABLE拆解成就绪和运行状态,另外Java的BLOCKED、WAITING、TIMED_WAITING都属于传统模型的等待状态。
线程之间怎么通讯的?
1、volatile修饰符:全局变量方式,最简单的一种方法是使用全局变量
2、使用Object类的wait() 和 notify() 方法:Object类提供了线程间通信的方法:wait()、notify()、notifyaAl(),它们是多线程通信的基础,而这种实现方式的思想自然是线程间通信。
3、JUC工具类 CountDownLatch\信号量semaphore等通知
4、使用 ReentrantLock 结合 Condition:
5、消息队列
6 redis
?Volatile非原子性的原因?
jmm的8大原子操作use\asize\store\lock
lock(锁定):作用于主内存,它把一个变量标记为一条线程独占状态;
read(读取):作用于主内存,它把变量值从主内存传送到线程的工作内存中,以便随后的load动作使用;
load(载入):作用于工作内存,它把read操作的值放入工作内存中的变量副本中;
use(使用):作用于工作内存,它把工作内存中的值传递给执行引擎,每当虚拟机遇到一个需要使用这个变量的指令时候,将会执行这个动作;
assign(赋值):作用于工作内存,它把从执行引擎获取的值赋值给工作内存中的变量,每当虚拟机遇到一个给变量赋值的指令时候,执行该操作;
store(存储):作用于工作内存,它把工作内存中的一个变量传送给主内存中,以备随后的write操作使用;
write(写入):作用于主内存,它把store传送值放到主内存中的变量中。
unlock(解锁):作用于主内存,它将一个处于锁定状态的变量释放出来,释放后的变量才能够被其他线程锁定;
----------高并发多线程----------
?多线程用到的场景?
1、前期的补偿通知机制是用线程池newScheduledThreadPool 开启的多线和去通知的。
2、上层来调网关的一些业务逻辑处理慢的接口,先快速返回,开启线程异步处理业务逻辑,处理完了之后再通知上层业务方
3、mysql主从备份原理也是线程异步去实现的
-------------------ThreadLocal-------------
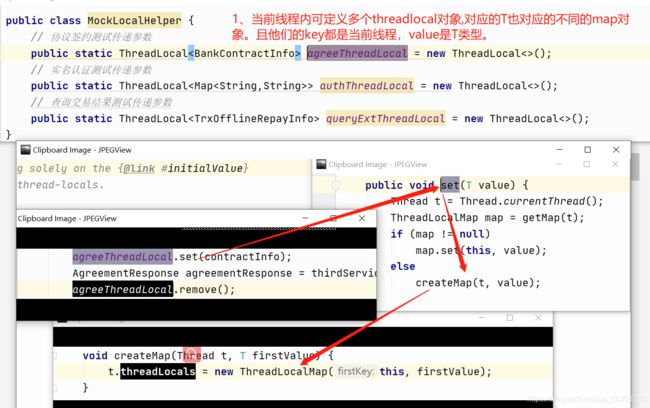
?ThreadLocal工作原理或实现原理?
https://www.cnblogs.com/kancy/p/10702310.html
底层也是封装了ThreadLocalMap集合类来绑定当前线程和变量副本的关系,以threadlocal实例为key,其他信息为value,保证各个线程独立并且访问安全!
ThreadLocalMap
?ThreadLocal的作用或优点或应用场景?
Mybatis高并发数据库连接操作,都会使用ThreadLocal类来保证Java多线程程序访问和数据库数据的一致性问题.
一个ThreadLocalMap的存储上线就是其数组长度的三分之二。并且很重要的一个点ThreadLocalMap解决hash冲突是使用的开放寻址法,和HashMap的链表法不一样
?我搭建过,如何搭建或如何使用?
示例:
-------------------Volatile-------------
?Volatile工作原理或实现原理?
?Volatile的作用或优点或应用场景?
作用是变量在多个线程之间可见,就可以通讯了
-------------------锁-------------
1)wait方法----当interrupt方法遇到---严格不算是锁
Object o= new Object();
try { o.wait();} catch (InterruptedException e) {}//thread里执行了wait,释放资源,wait进入等待队列
wait(long)//过这个时间则自动唤醒。(线程timed_waiting中,需到时唤醒或主动唤醒;如果未设时间则进入waiting)
thread.interrupt();//线程打断interrupt唤醒wait
o.notify();//对象唤醒,调用notify()方法一次只随机通知一个线程进行唤醒。
o.notifyAll();//对象唤醒,所有线程进行唤醒。
(sleep(t)不需要唤醒,线程timed_waiting,但占着cpu资源呢)
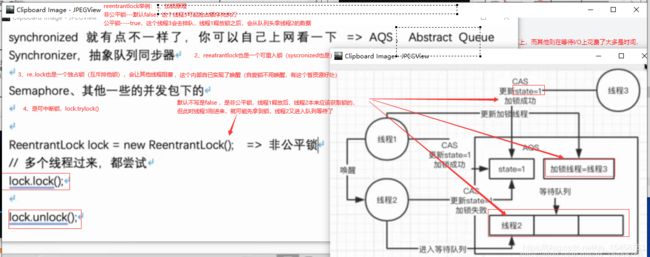
2)synchronized 是一种悲观锁,阻塞的可重入锁
synchronized (lock) {}
3)lock 是CAS乐观锁(但优化后的AQS加队列后还是阻塞了,并不像是乐观),用tryLock方式是非阻塞的可重入锁
private Lock lock = new ReentrantLock();
方式一: lock.lock();
方式二 : if (lock.tryLock()) { lock.lock(); try { } catch (Exception e) { } finally { lock.unlock(); }
------------------------------sleep,wait,await,park的区别------------------------------
Thread.sleep()和Object.wait()的区别
(1)Thread.sleep()不会释放占有的锁,Object.wait()会释放占有的锁;(sleep拿着资源锁睡着了,wait清醒的等着并交还了资源锁)
(2)Thread.sleep()必须传入时间,Object.wait()可传可不传,不传表示一直阻塞下去;
(3)Thread.sleep()到时间了会自动唤醒,然后继续执行;
(4)Object.wait()不带时间的,需要另一个线程使用Object.notify()唤醒;
(5)Object.wait()带时间的,假如没有被notify,到时间了会自动唤醒,醒了之后分好两种情况,一是立即获取到了锁,线程自然会继续执行;二是没有立即获取锁,线程进入同步队列等待获取锁;
Thread.sleep()和Condition.await()的区别
跟Object.wait()是基本一致的,不同的是Condition.await()底层是调用LockSupport.park()来实现阻塞当前线程的。
Thread.sleep()和LockSupport.park()的区别
(1)Thread.sleep()不会释放占有的锁,Object.wait()会释放占有的锁;
(2)Thread.sleep()必须传入时间,Object.wait()可传可不传,不传表示一直阻塞下去;
(3)Thread.sleep()到时间了会自动唤醒,然后继续执行;
(4)Object.wait()不带时间的,需要另一个线程使用Object.notify()唤醒;
(5)Object.wait()带时间的,假如没有被notify,到时间了会自动唤醒,这时(1)从功能上来说,Thread.sleep()和LockSupport.park()方法类似,都是阻塞当前线程的执行,且都不会释放当前线程占有的锁资源;
(2)Thread.sleep()没法从外部唤醒,只能自己醒过来;
(3)LockSupport.park()方法可以被另一个线程调用LockSupport.unpark()方法唤醒;
(4)Thread.sleep()方法声明上抛出了InterruptedException中断异常,所以调用者需要捕获这个异常或者再抛出;
(5)LockSupport.park()方法不需要捕获中断异常;
(6)Thread.sleep()本身就是一个native方法;
(7)LockSupport.park()底层是调用的Unsafe的native方法;又分好两种情况,一是立即获取到了锁,线程自然会继续执行;二是没有立即获取锁,线程进入同步队列等待获取锁;
Object.wait()和LockSupport.park()的区别
二者都会阻塞当前线程的运行,他们有什么区别呢?经过上面的分析相信你一定很清楚了,真的吗?往下看!
(1)Object.wait()方法需要在synchronized块中执行;
(2)LockSupport.park()可以在任意地方执行;
(3)Object.wait()方法声明抛出了中断异常,调用者需要捕获或者再抛出;
(4)LockSupport.park()不需要捕获中断异常【本文由公从号“彤哥读源码”原创】;
(5)Object.wait()不带超时的,需要另一个线程执行notify()来唤醒,但不一定继续执行后续内容;
(6)LockSupport.park()不带超时的,需要另一个线程执行unpark()来唤醒,一定会继续执行后续内容;
(7)如果在wait()之前执行了notify()会怎样?抛出IllegalMonitorStateException异常;
(8)如果在park()之前执行了unpark()会怎样?线程不会被阻塞,直接跳过park(),继续执行后续内容;
?synchronized是线程安全的吗?
是。线程安全性包括两个方面,①可见性。②原子性(并发不会被覆盖)。有的锁可以用lock代替。
Disruptor---Disruptor可以非常简单的完成这种复杂的多线程并发、等待、先后执行
https://blog.csdn.net/tianyaleixiaowu/article/details/79787377
--------------------------------------------------------------------线程池--------------------------------------------------------------------
什么是线程池----都是基于线程池执行器
线程池是一个线程集合,线程池是运用场景最多的并发框架,需要异步或并发执行任务的程序都可以使用线程池。在开发过程中,合理地使用线程池能够带来3个好处。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,
还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用
线程池,必须对其实现原理了如指掌。
线程池作用
减少了创建和销毁线程所需的时间,从而提高效率。
?巧记四种线程池?
1)公共创建头:ExecutorService newExecutorService = Executors.new*Thread*--------EE
2)四种特殊线程池:------即ssfc(姗姗FC)
Single--------newSingleThreadExecutor总结:用唯一的工作线程来执行任务,结果依次输出,相当于顺序执行各个任务
S-------newScheduledThreadPool总结:定长线程池,支持定时及周期性任务执行
F---------newFixedThreadPool 总结:创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
C-------------newCachedThreadPool 总结:线程池为无限大,当执行第二个任务时第一个任务已经完成,会复用执行第一个任务的线程,而不用每次新建线程。
不允许使用Executors去创建线程池
不允许使用Executors去创建线程池,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
说明:Executors返回的线程池对象的弊端如下:
1)FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为整数最大值Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。
2)CachedThreadPool 和 ScheduledThreadPool :
允许创建的线程数量为整数最大值Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
线程池中shutdown()和shutdownNow()方法的区别
1、当线程池调用shutdown()时,线程池状态则立刻变成SHUTDOWN状态。拒绝新任务,否则将会抛出RejectedExecutionException异常。线程池中执行的任务和队列中的任务都已经处理完成,才会退出
2、当执行shutdownNow(),线程池的状态立刻变成STOP状态,拒绝新任务,,并试图停止所有正在执行的线程,不再处理还在池队列中等待的任务,当然,它会返回那些未执行的任务。
它试图终止线程的方法是通过调用Thread.interrupt()方法来实现的,但是大家知道,这种方法的作用有限,如果线程中没有sleep 、wait、Condition、定时锁等应用, interrupt()方法是无法中断当前的线程的。所以,ShutdownNow()并不代表线程池就一定立即就能退出,它可能必须要等待所有正在执行的任务都执行完成了才能退出。
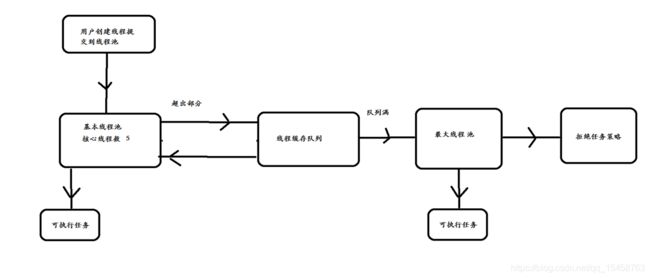
线程池原理剖析--
提交一个任务到线程池中,线程池的处理流程如下:
1、判断线程池里的核心线程是否都在执行任务,如果不是(核心线程空闲或者还有核心线程没有被创建)则创建一个新的工作线程来执行任务。如果核心线程都在执行任务,则进入下个流程。
2、线程池判断工作队列是否已满,如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程。
3、判断线程池里的线程是否都处于工作状态,如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
合理配置线程池
要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析:
任务的性质:CPU密集型任务,IO密集型任务和混合型任务。
任务的优先级:高,中和低。
任务的执行时间:长,中和短。
任务的依赖性:是否依赖其他系统资源,如数据库连接。
任务性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务配置尽可能少的线程数量,如配置Ncpu+1个线程的线程池。IO密集型任务则由于需要等待IO操作,线程并不是一直在执行任务,则配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,则将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先得到执行,需要注意的是如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用CPU。
一般总结哦,有其他更好的方式,希望各位留言,谢谢。
CPU密集型时,任务可以少配置线程数,大概和机器的cpu核数相当,这样可以使得每个线程都在执行任务
IO密集型时,大部分线程都阻塞,故需要多配置线程数,2*cpu核数
操作系统之名称解释:
某些进程花费了绝大多数时间在计算上,而其他则在等待I/O上花费了大多是时间,
前者称为计算密集型(CPU密集型)computer-bound,后者称为I/O密集型,I/O-bound。
浅谈Java中的深克隆和浅克隆
浅克隆:对于非基本类型字段属性,只拷贝对象内存地址,修改该字段会影响原字段对象--类实现Cloneable接口
深克隆:对于非基本类型字段属性,会重新创建一个对象,使用新的内存地址--实现clone()方法后,对非基本类型的对象类属性字段,创建新对象,重新赋值
----------------并发包相关--------------------------------------
自旋锁和互斥锁的区别,java中lock Syncronized区别
1、自旋锁---busy-waiting,自旋锁是未获得锁的线程(对外被阻塞-但自旋锁是一种非阻塞锁,因为它没睡眠),但会死循环检测,一直消耗cpu,直到获得别人释放的锁(copy_to_user之类的接口可能造成死锁)------无限检测循环中,执行一个 CAS 操作,直到成功
2、互斥锁---sleep-waiting,未获得锁的线程会sleep(被阻塞),放入等待队列里,直到获得别人释放的锁--synchronized悲观锁
3、可重入锁就是递归锁,ReentrantLock和synchronized都是可重入锁
4、公平锁--公平锁就是保障了多线程下各线程获取锁的顺序,先到的线程优先获取锁,而非公平锁则无法提供这个保障
5、可中断锁:顾名思义,就是可以相应中断的锁.synchronized就不是可中断锁,而Lock是可中断锁。lockInterruptibly()

?synchronized与ReentrantLock的区别?
same同点:
ReentrantLock和synchronized都是可重入锁。
不同点:
synchronized是不可中断锁,而ReentrantLock则提供了中断功能。
synchronized是非公平锁,而ReentrantLock的默认实现是非公平锁,但是也可以设置为公平锁
-----------ReentrantLock--------
名词?
AQS--------------AbstractQueuedSynchronizer抽像队列同步
CAS操作----------(CompareAndSwap)-比较和清除(巧记--比较抽象)
AQS使用一个FIFO的队列表示排队等待锁的线程,包含:ReentrantLock,Semaphore,CountDownLatch,ReentrantReadWriteLock,FutureTask
CAS和AQS?(巧记--比较抽象)
一、CAS是CompareAndSwap-比较和清除, 比较旧值是否变化,变化则重新读取再设置。,操作包含三个操作数——内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。-----CAS操作保证修改状态码过程的原子性
二、AQS是AbstractQueuedSynchronizer 抽象队列同步器,里面有3个属性:
int锁状态码--从0变为1表示加锁成功;
当前加锁线程--从Null变为当前获取锁的线程;
一个等待队列-----来存放多个等待线程。(使用volatile关键字保证状态码在线程间的可见性)
比如说ReentrantLock、ReentrantReadWriteLock等大多数并发包下的底层都是基于AQS来实现的。
1、AQS是状态变量+一个队列(还有状态码、当前锁线程)来放并发拿锁失败的等待线程,但默认false是不公平锁,最后进的可能先拿到锁。可设置属性值ture改成公平锁,
2、从ReentrantLock的加锁和释放锁的过程,给大家讲清楚了其底层依赖的AQS的核心原理:
这个讲一下3个线程情况,线程1加锁和释放锁的过程中,线程2、3是按顺序还是不按顺序,这个就有公平和非公平两种锁的场景
基于AQS框架实现的CountDownLatch和CyclicBarrier对比:
CountDownLatch维护有个int型的状态码,每次调用countDown时状态值就会减1;调用wait方法的线程会阻塞,直到状态码为0时才会继续执行。
CyclicBarrier可以实现CountDownLatch一样的功能,不同的是CountDownLatch属于一次性对象,声明后只能使用一次,而CyclicBarrier可以循环使用。
总结#
CountDownLatch创建后只能使用一次,而CyclicBarrier可以循环使用,并且CyclicBarrier功能更完善。
CountDownLatch内部的状态是基于AQS中的状态信息,而CyclicBarrier中的状态值是单独维护的,使用ReentrantLock加锁保证并发修改状态值的数据一致性。
它们的使用场景:允许一个或多个线程等待其他线程完成操作, 即当指定数量线程执行完某个操作再继续执行下一个操作
?ReentrantLock工作原理或实现原理?
ReentrantLock是Lock的默认实现之一。使用排队等待锁的机制,并发安全的
-----------CopyOnWriteArrayList--------
CopyOnWriteArrayList是线程安全List,适合----读多写少时且服务器内存够用(CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单等场景)
?CopyOnWriteArrayList工作原理或实现原理?
写时是需要在方法内开始时,写时加ReentrantLock锁的,避免多线程写的时候会Copy出N个副本出来。
读的时候不需要加锁,因为是安全失败机制,写的时候会复制新的副本,读的是旧的副本,写完会把引用改成改好的副本。,所以改成锁读依然读到的是旧对象
快速失败fail-fast----在A线程对集合进行遍历的同时,B线程对集合进行了删除操作,此时会抛出并发修改异常
安全失败机制----集合在进行内容操作的时候,会先将集合内容复制一份,在新复制的集合上进行操作。所以当线程报错的时候不会抛出异常
?的作用或优点或应用场景?
比如ArrayList,写的时候,有人同时在读,就会报并发修改异常---原因是
(Iterator 遍历开始时,会把modCount记录下来,循环结束时会比较一下这个值是否被改了,改动过就报异常)。
1)优点:所以和ArrayList比,CopyOnWriteArrayList采用安全失败机制,先复制副本出来改副本,改的过程中,Iterator遍历就不会报修改异常了。
1)缺点:对于业务来说,可能数据不一致,读的是旧值。写的时候,因为要复制(当一个数组里面数据量很大时,这时在复制一个副本就容易造成GC),还有加锁,所以很慢。但查没锁没复制,所以快。
应用场景----读多写少时且服务器内存够用(复制占内存),比如白名单,黑名单
?CopyOnWriteArrayList与Vector的区别?
1、Vector是比较古老的线程安全的,但性能不行,Vector读写方法上都是同步的(Synchronized),;
2、CopyOnWriteArrayList在兼顾了线程安全的同时,又提高了并发性,性能比Vector有不少提高----CopyOnWriteArrayList读方法无读;且写方法内开始时,加ReentrantLock锁后复制一个新副本出来记录写操作,之后再把引用指向新副本,释放锁。
?Vector & ArrayList ?
1) Vector的读写方法都是同步的(Synchronized),是线程安全的,但效率低
2) 扩容不一样,Vector会将它的容量*2,而ArrayList只增加50%的大小。
?. Hashtable & HashMap
Hashtable和HashMap它们的性能方面的比较类似 Vector和ArrayList,比如Hashtable的方法是同步的,而HashMap的不是。
? ArrayList & LinkedList
ArrayList的内部实现是基于内部数组Object[],所以从概念上讲,它更象数组,但LinkedList的内部实现是基于一组连接的记录,所以,它更象一个链表结构,所以,它们在性能上有很大的差别:
查ArrayList和写LinkedList
?ArrayBlockingQueue、ConcurrentLinkedQueue 和 LinkedBlockingQueue
ArrayBlockingQueue是初始容量固定的阻塞队列,我们可以用来作为数据库模块成功竞拍的队列,比如有10个商品,那么我们就设定一个10大小的数组队列
ConcurrentLinkedQueue使用的是CAS原语无锁队列实现,是一个异步队列,入队的速度很快,出队进行了加锁,性能稍慢。
LinkedBlockingQueue是阻塞的队列,入队和出队都用了加锁,当队空的时候线程会暂时阻塞
Synchronized和Lock比较?
- Synchronized是关键字,java内置语言实现,Lock是接口。(Java中每个对象都可以用来实现一个同步的锁,这些锁被称为内置锁(Intrinsic Lock)或监视器锁(Monitor Lock))----monitorenter 必须 有 对应 的 monitorexit
- Synchronized在线程发生异常时会自动释放锁,因此不会发生异常死锁。Lock异常时不会自动释放锁,所以需要在finally中实现释放锁。
- Lock是可以中断锁,Synchronized是非中断锁,必须等待线程执行完成释放锁。
- Lock可以使用读锁提高多线程读效率。
多线程核心知识整事导图: