java多线程(线程池)
线程池
管理线程的资源池,可以复用线程,不用频繁的创建新线程,节省线程开销的资源损耗,节省资源,提高响应速度。主要概念:核心线程、阻塞队列、非核心线程、空闲时间、饱和策略。
线程池执行过程
大于设定的空闲时间的非核心线程会被销毁释放。
JUC线程管理
ThreadPoolExecutor
《阿里巴巴java开发手册》中指出了线程资源必须通过线程池提供,不允许在应用中自行显示的创建线程,这样一方面是线程的创建更加规范,可以合理控制开辟线程的数量;另一方面线程的细节管理交给线程池处理,优化了资源的开销。而线程池不允许使用Executors去创建,而要通过ThreadPoolExecutor方式,这一方面是由于jdk中Executors框架虽然提供了如newFixedThreadPool()、newSingleThreadExecutor()、newCachedThreadPool()等创建线程池的方法,但都有其局限性,不够灵活;另外由于前面几种方法内部也是通过ThreadPoolExecutor方式实现,使用ThreadPoolExecutor有助于大家明确线程池的运行规则,创建符合自己的业务场景需要的线程池,避免资源耗尽的风险。
ThreadPoolExecutor的构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
参数含义:
corePoolSize:指定了线程池中的线程数量,它的数量决定了添加的任务是开辟新的线程去执行,还是放到workQueue任务队列中去;
maximumPoolSize:指定了线程池中的最大线程数量,这个参数会根据你使用的workQueue任务队列的类型,决定线程池会开辟的最大线程数量;
keepAliveTime:当线程池中空闲线程数量超过corePoolSize时,多余的线程会在多长时间内被销毁;
unit:keepAliveTime的单位
workQueue:任务队列,被添加到线程池中,但尚未被执行的任务;它一般分为直接提交队列、有界任务队列、无界任务队列、优先任务队列几种;
threadFactory:线程工厂,用于创建线程,一般用默认即可;
handler:拒绝策略;当任务太多来不及处理时,如何拒绝任务;
四种类型的阻塞队列:
-
直接提交队列(SynchronousQueue队列)
使用SynchronousQueue队列,提交的任务不会被保存,总是会马上提交执行。如果用于执行任务的线程数量小于maximumPoolSize,则尝试创建新的进程,如果达到maximumPoolSize设置的最大值,则根据你设置的handler执行拒绝策略。 -
有界的任务队列(ArrayBlockingQueue)
使用ArrayBlockingQueue有界任务队列,若有新的任务需要执行时,线程池会创建新的线程,直到创建的线程数量达到corePoolSize时,则会将新的任务加入到等待队列中。若等待队列已满,即超过ArrayBlockingQueue初始化的容量,则继续创建线程,直到线程数量达到maximumPoolSize设置的最大线程数量,若大于maximumPoolSize,则执行拒绝策略。 -
无界的任务队列(LinkedBlockingQueue)
使用无界任务队列,线程池的任务队列可以无限制的添加新的任务,而线程池创建的最大线程数量就是你corePoolSize设置的数量,也就是说在这种情况下maximumPoolSize这个参数是无效的,哪怕你的任务队列中缓存了很多未执行的任务,当线程池的线程数达到corePoolSize后,就不会再增加了;若后续有新的任务加入,则直接进入队列等待,当使用这种任务队列模式时,一定要注意你任务提交与处理之间的协调与控制,不然会出现队列中的任务由于无法及时处理导致一直增长,直到最后资源耗尽的问题. -
优先任务队列(PriorityBlockingQueue)
PriorityBlockingQueue它其实是一个特殊的无界队列,它其中无论添加了多少个任务,线程池创建的线程数也不会超过corePoolSize的数量,只不过其他队列一般是按照先进先出的规则处理任务,而PriorityBlockingQueue队列可以自定义规则根据任务的优先级顺序先后执行。
待执行的任务实现Comparable接口,返回的值越小,表示优先级越高。
线程池的饱和策略有四种:
- AbortPolicy: 抛出一个异常,,阻止系统正常工作,默认值;
- DiscardPolicy:新提交的任务直接抛弃;
- DiscardOldestPolicy:丢弃队列里最老的任务,将当前这个任务继续提交给线程池
- CallerRunsPolicy:交给线程池调用所在的线程进行处理,即将某些任务退回给调用者。该策略会把任务队列中的任务放在调用者线程当中运行
通过线程工厂自定义线程创建:
线程池中线程就是通过ThreadPoolExecutor中的ThreadFactory,线程工厂创建的。那么通过自定义ThreadFactory,可以按需要对线程池中创建的线程进行一些特殊的设置,如命名、优先级等,下面代码我们通过ThreadFactory对线程池中创建的线程进行记录与命名
public class ThreadPool {
private static ExecutorService pool;
public static void main( String[] args )
{
//自定义线程工厂
pool = new ThreadPoolExecutor(2, 4, 1000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(5),
new ThreadFactory() {
public Thread newThread(Runnable r) {
System.out.println("线程"+r.hashCode()+"创建");
//线程命名
Thread th = new Thread(r,"threadPool"+r.hashCode());
return th;
}
}, new ThreadPoolExecutor.CallerRunsPolicy());
for(int i=0;i<10;i++) {
pool.execute(new ThreadTask());
}
}
}
public class ThreadTask implements Runnable{
public void run() {
//输出执行线程的名称
System.out.println("ThreadName:"+Thread.currentThread().getName());
}
}
ThreadPoolExecutor扩展:
ThreadPoolExecutor扩展主要是围绕beforeExecute()、afterExecute()和terminated()三个接口实现的。
- beforeExecute:线程池中任务运行前执行
- afterExecute:线程池中任务运行完毕后执行
- terminated:线程池退出后执行
线程吃线程数量的设置没有一个明确的指标,根据实际情况,结合下面这个公式即可
/**
* Nthreads=CPU数量
* Ucpu=目标CPU的使用率,0<=Ucpu<=1
* W/C=任务等待时间与任务计算时间的比率
*/
Nthreads = Ncpu*Ucpu*(1+W/C)
参考文章:ThreadPoolExecutor
线程池实现线程复用的原理
- 线程池持有一个Worker的内部类,改内部类实现Runable,其run方法(runWorker)中是一个while循环,会从任务队列里获取任务,实现一个线程执行多个任务,实际上是将任务和线程分离。
- 提交任务时,当线程数小于核心线程数时,创建worker内部类,执行任务;当核心线程池满时,任务添加到阻塞队列,当队列满时,创建非核心线程执行任务。
参考文章
Future获取多线程的执行结果
继承Thread、实现Runnable接口的多线程实现方式,无法获取到多线程执行的结果。通过实现Callable,返回Future的方式,可以获取到多线程的执行结果。Future表示一个可能还没有完成的异步任务的结果。
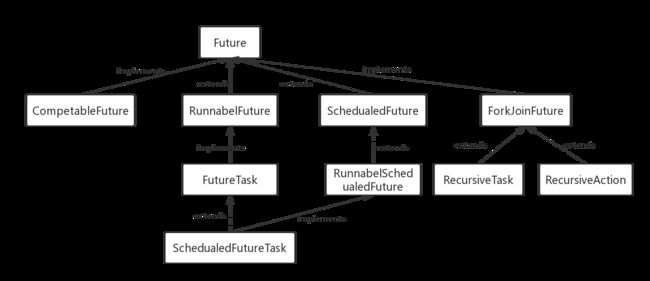
future
-
get()方法可以当任务结束后返回一个结果,如果调用时,工作还没有结束,则会阻塞线程,直到任务执行完毕
-
get(long timeout,TimeUnit unit)做多等待timeout的时间就会返回结果
-
cancel(boolean mayInterruptIfRunning)方法可以用来停止一个任务,如果任务可以停止(通过mayInterruptIfRunning来进行判断),则可以返回true,如果任务已经完成或者已经停止,或者这个任务无法停止,则会返回false.
-
isDone()方法判断当前方法是否完成
-
isCancel()方法判断当前方法是否取消
CompletableFuture
参考文章:CompletableFuture
- 创建异步任务的四个方法:
public static CompletableFuture<Void> runAsync(Runnable runnable) //不支持返回值的异步任务创建,使用默认的ForkJoinPool.commonPool() 的线程池
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)//支持指定线程池
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) //支持返回值
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
- 计算结果完成的回调方法:
public CompletableFuture<T> whenComplete(BiConsumer<? super T,? super Throwable> action)//使用原有任务的线程执行回调方法
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action) //回调方法继续交由线程池执行
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action, Executor executor)
public CompletableFuture<T> exceptionally(Function<Throwable,? extends T> fn) //异常时执行回调方法
- 两个线程有依赖关系时,使用thenApply把这两个线程串行化
public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn) //T上一个线程的返回类型,U当前线程的返回类型
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn)
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn, Executor executor)
//example
private static void thenApply() throws Exception {
CompletableFuture<Long> future = CompletableFuture.supplyAsync(new Supplier<Long>() {
@Override
public Long get() {
long result = new Random().nextInt(100);
System.out.println("result1="+result);
return result;
}
}).thenApply(new Function<Long, Long>() {
@Override
public Long apply(Long t) {
long result = t*5;
System.out.println("result2="+result);
return result;
}
});
long result = future.get();
System.out.println(result);
}
- 任务执行完成的方法handle,与thenApply处理方式类似,可以处理正常和异常结束的情况,thenApply只能处理正常结束的情况:
public <U> CompletionStage<U> handle(BiFunction<? super T, Throwable, ? extends U> fn);
public <U> CompletionStage<U> handleAsync(BiFunction<? super T, Throwable, ? extends U> fn);
public <U> CompletionStage<U> handleAsync(BiFunction<? super T, Throwable, ? extends U> fn,Executor executor);
- thenAccept 消费处理结果,依赖任务的执行结果
public CompletionStage<Void> thenAccept(Consumer<? super T> action);
public CompletionStage<Void> thenAcceptAsync(Consumer<? super T> action);
public CompletionStage<Void> thenAcceptAsync(Consumer<? super T> action,Executor executor);
thenRun 方法,不关心任务的结果,只要任务完成就开始执行
public CompletionStage<Void> thenRun(Runnable action);
public CompletionStage<Void> thenRunAsync(Runnable action);
public CompletionStage<Void> thenRunAsync(Runnable action,Executor executor);
- thenCombine 合并任务,将调用方与第一个future的结果合并
- thenAcceptBoth任务合并后的任务的后续处理
- applyToEither 方法,两个任务对执行的快的那个任务的结果做处理
- acceptEither 方法,两个任务对执行的快的那个任务的结果做处理
- runAfterEither 方法,两个任务任何一个返回了就执行
- runAfterBoth ,两个任务都完成了执行
- thenCompose,两个任务的流水线操作,第一个任务的结果用于第二个任务
java并发包JUC
juc参考文档

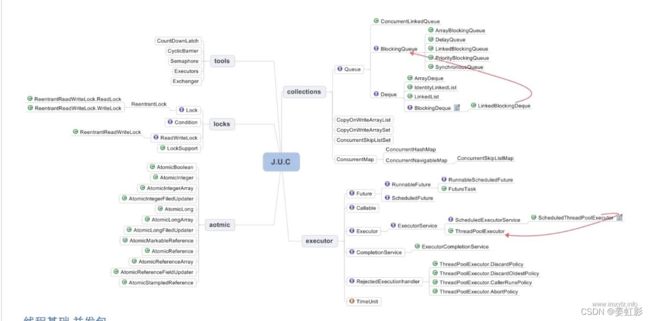
tools
-
CountDownLatch 闭锁,必须等指定的线程数完成后,主线程才能继续向下执行。countDownLatch参考文章
* 初始化:CountDownLatch latch = new CountDownLatch(3);
* 计数器减一:latch.countDown();
* 主线程阻塞等待其他线程完成(计数器降到0,阻塞解除):latch.await(); -
CyclicBarrier 循环栅栏,当指定数量的线程到达栅栏时,解除线程阻塞,未达到指定数量时,子线程阻塞。CyclicBarrier参考文章
* 初始化指定数量的栅栏和满足条件的处理逻辑:CyclicBarrier barrier = new CyclicBarrier(2,() -> {System.out.println(“[” + Thread.currentThread().getName() + “]” + “task1and2 finish…”);});
* 多个子线程等待栅栏条件触发(有2个await时,自动执行栅栏逻辑): barrier.await(); -
Exchanger 交换器,两个线程的数据交换,多个偶数线程时,随机配对。线程需同时(指定时间范围内)到达。Exchanger参考文章
* 初始化:Exchanger exchanger = new Exchanger<>()
* 交换数据:Object data = exchanger.exchange(data); //两个线程会互相拿到对方的数据
线程的五种状态
线程状态参考文章
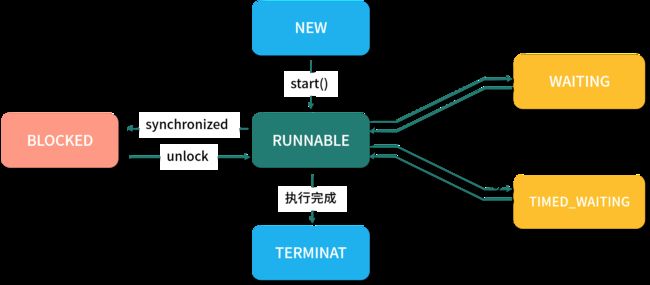
new : 线程对象被实例化(new)
runable: 线程实例调用start启动,分为等待cpu分配资源(ready)、或正在运行(running)
blocked: 线程等待其他线程释放锁,synchronized 。
waiting:当前线程发起等待(不限期),如Object.wait()。另一个线程通过notify可以唤醒
time_waiting: 有超时时间的等待,和waiting类似,由当前线程发起。Object.wait(time)
terminated: 终止,线程执行完成
阻塞线程的四种方式对比
Thread.sleep;Object.wait;Condition.await;LockSupport.park;

参考文章
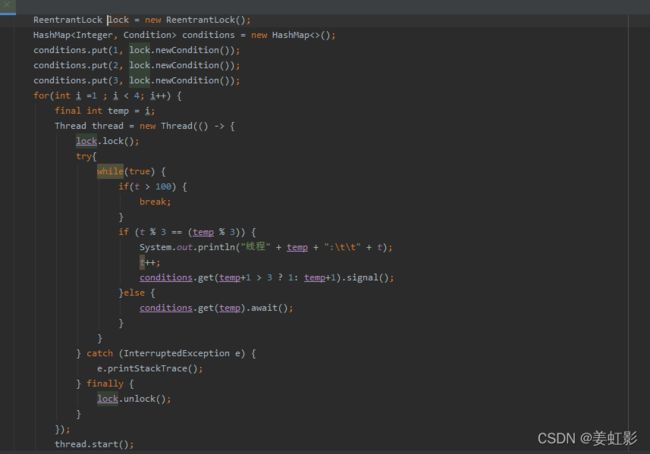
- RetraintLock结合Condition,做多线程同步
给RetraintLock添加Condition条件,线程开始时加锁,线程内的所有任务完成后释放锁,中间当不满足当前线程的执行条件时,通过condition的await方法,是当前线程进入waiting状态并释放锁;当前线程任务执行完成后,通过condition的signal方法,唤醒满足条件的线程执行对应任务。

- CountDownLatch闭锁,通过初始化信号量的值,在线程内做countdown,监听线程阻塞等待countDownLatch降为0后,继续后续任务,可以等多个并发线程都执行完成后,再执行后续的逻辑

Synchronized 关键字式同步锁
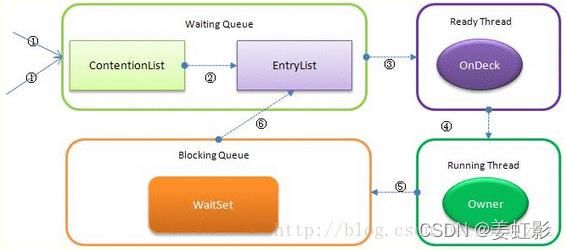
- synchronized是非公平锁,线程进入时,会首先通过自旋尝试获取锁,获取到则直接成owner,也可以竞争成为onDeck(准备线程);获取不到,则进入ContentionList(竞争队列),contentionList会有频繁的cas写入,Owner unlock时,会将contentionList的一部分线程迁移到EntryLIst,并指定entryLIst的某个线程进入OnDesk(准备线程),Owner被wait后进入waitSet,被notify唤醒后,重新进入到EntryList;Owner释放锁后,Ondesk尝试竞争锁成为Owner.
- waitSet/Contentionlist/EntryList中的线程都处于阻塞状态,该状态是有操作系统的内核函数实现的。线程的切换需要操作系统从内核态到用户态的切换,上下文切换。
- 每个对象都有monitor对象,加锁是在竞争monitor对象,通过指令实现,需要调用操作系统相关接口,是低效的。1.6有很多优化,如适应自旋、锁消除、锁粗化、轻量级锁及偏向锁等,效率有了本质的提高。
reentrantlock api级的可重入锁
- reentrantlock是实现了lock接口中方法的锁,除了能支持synchronized的所有操作外,还支持公平锁、可中断锁、可轮询锁等。(非公平锁:随机、就近原则分配锁,更高的性能;公平锁:按提出请求的顺序获取锁)
- lock 提供了丰富的api,如获取等待线程数、总数、添加条件对象(Condition,可通过Condition.await释放锁,可通过signal唤醒)、获取锁、尝试获取锁等。Condittion signal可以唤醒指定的线程;Object notify随机唤醒线程
- 有lock,必须保证最后(finally)有unlock释放锁
- 可重入锁,外层获取到锁后,内层也可以获取到锁,reentrantlock和synchronized都是可重入锁
- aqs //todo
Semaphore 信号量
- 是一种基于计数的信号量,可以设定阈值。可以用来构建一些数据池、资源池(如数据库链接)。基本能实现reentrantlock的所有功能
其他概念
-
共享锁与独占锁
1. 独占锁:只能有一个线程能获取锁。如reentrantLock。是一种悲观保守的加锁策略
2. 共享锁:允许多个线程同时获取锁,乐观锁,放宽了加锁策略。如ReadWriteLock,允许多个线程进行多操作,读写互斥,写写互斥。aqs的内部类Node 定义了两个常量 SHARED 和 EXCLUSIVE,标识等待线程的锁获取方式。 -
四种状态的锁:
- 无锁状态:
- 偏向锁:锁不仅仅不存在多线程竞争,而且锁由同一个线程获取和释放。这种情况下,需要消除消除线程锁重入(轻量级锁cas)的开销,看起来就像这个线程得到偏护。轻量级锁需要依赖多次cas原子操作,而偏向锁只是在置换ThreadId时存在一次cas操作。如果出现多线程竞争,则必须撤销偏向锁
- 轻量级锁:在没有多线程竞争的情况下(如果有多线程竞争,则升级到重量级锁),减少重量级锁带来的性能消耗。适用于多线程交替执行某个同步代码块时,如果同一时间有两个以上线程竞争,则升级未重量级锁。
- 重量级锁:依赖于操作系统的命令来实现的锁,线程切换需要用户态到内核态的转换,成本非常高。未优化的synchronized就是这种。
分段锁
ConcurrentHashMap 对segment加锁,就是分段锁理念非常好的实践。
cas
- 比较并交换,新值、旧值、内存值
AQS
- 抽象的队列同步器,多线程访问共享资源的同步器框架。ReentrantLock/Semaphore/CountDownLatch都依赖它
- 包含一个voilate int state(代表共享资源)和fifo线程等待队列(多线程争用共享资源被阻塞时进入此队列)
- 定义了两种资源共享模式,Exclusive独占模式、Share共享模式。独占模式下实现 tryAcquire-tryRelease,共享模式下实现
tryAcquireShared-tryReleaseShared - 一般的锁只实现独占或共享模式的一种,但ReentrantReadWriteLock两种都会实现,共享读和独占写,共享资源(int state)的高16位标识读锁,低16位标识写锁