图像分类算法:ResNet论文解读
图像分类算法:ResNet论文解读
前言
其实网上已经有很多很好的解读各种论文的文章了,但是我决定自己也写一写,当然,我的主要目的就是帮助自己梳理、深入理解论文,因为写文章,你必须把你所写的东西表达清楚而正确,我认为这是一种很好的锻炼,当然如果可以帮助到网友,也是很开心的事情。
说明
如果有笔误或者写错误的地方请指出(勿喷),如果你有更好的见解也可以提出,我也会认真学习。
原始论文地址
点击这里,或者复制链接
https://arxiv.org/abs/1512.03385
目录结构
文章目录
-
- 图像分类算法:ResNet论文解读
-
- 1. 背景简介:
- 2. 文章内容概述:
- 3. 深层网络退化问题:
- 4. 残差框架:
- 5. 残差结构形状不一致解决方法:
- 6. shortcut connections:
- 7. 网络架构介绍:
- 8. 总结:
1. 背景简介:
CNN在快速发展,在短短两三年时间,各种网络层出不穷。而VGG这篇论文表明了深度的重要性,但是在深度重要性的驱动下,一个问题出现了:更好的网络难搞就像堆积木一样堆得越高越好嘛?
回答这个问题的一个障碍是:**梯度消失与梯度爆炸。而这个问题已经被初始化手段(BN)**很大程度的解决了。但是,作者发现当网络随着深度的增加,准确度会饱和,然后迅速退化。
什么意思,如下图(论文原图)所示,深度的增加并没有如我们所想那样,精度也随之增加:

在这种情况下,作者提出了ResNet网络。
2. 文章内容概述:
由于更深层次神经网络更难训练,作者提出了基于残差的学习框架,并借此探索了深层神经网络的准确率,最大的深度甚至达到1000层,而其最佳的模型也在ImageNet上取得了top-5错误率3.57的精度,这个精度已经超过了人类所能达到的标准(我记得好像是5左右),也因此,后面就没有举办该比赛了,但是这个数据集仍然可以被拿来使用。
3. 深层网络退化问题:
作者发现,随着网络深度增加,准确度会饱和,然后迅速退化。
但是,从理论上来说:假设一个浅层模型和另外一个深层模型,其中这个深层模型的前面层都是从浅层模型复制过来的,是恒等映射,那么理论上性能应该更好,因为这相当于你在别人的基础上进一步学习,效果自然应该更好。如下图所示:
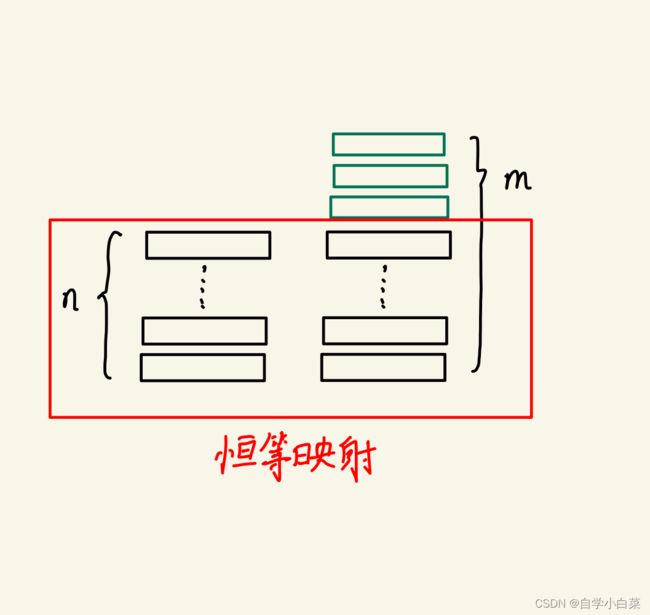
但是,实际上,现有的求解器无法如我们所想的那样运作。但这也符合世界的客观规律,因为学习不是一成不变的,即使同一个人在不同的时间点看同一个风景心情也是不同的。
4. 残差框架:
为了一定程度上解决退化问题,作者提出了基于残差的学习框架。
如下图所示(论文原图):
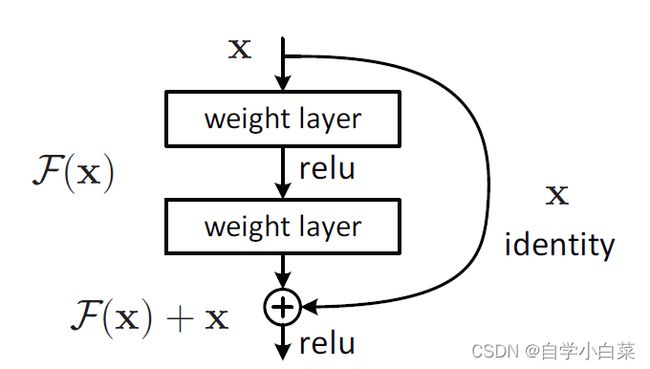
即,我们不希望让对叠层去适应底层映射,而是去适应残差。
说人话,在理论情况下,假设我们的已有的模型输入为x,此时堆叠一层,那么其可以看成学习一个目标函数H(x)的映射。但是退化问题表明了,实际上学的与我们所想可能有点差距。因此,作者希望新增加的层,去学习H(x)与x之间的差值,即这个新增加的层去学习残差H(x)-x。
作者为了实现这个目的,特意添加上图右边的曲线(并且这个曲线并没有增加学习参数),这样模型的输出值为F(x)+x(假设F(x)为残差),即新的层没有直接学习最终目标,而是学习了残差值。
虽然普通的我们也许并清除这样做是否可以解决网络退化问题,但是试验就是最好的证明方法,而作者也采用试验证明了这个方法的确可行。
5. 残差结构形状不一致解决方法:
残差结构有一个问题,就是如果我们的x与F(x)的shape不一致,那么两者是不能相加的。
解决这个问题的方法很多:
- 为输入输出添加0值,让两者大小一致(不建议)
- 添加1*1卷积层,来改变通道数
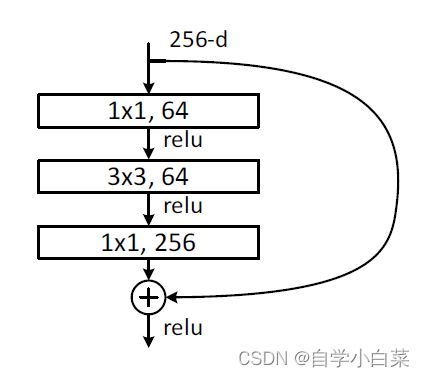
6. shortcut connections:
上图中,右边的曲线被作者称为“shortcut connections”,之所以用英文,主要中文翻译起来怪怪的,叫“快捷连接???”。
其特点是:满足要求的同时不增加任何需要学习的参数。
一个问题:能不能只跨一层或者跨多层?
跨多层是可以的,上面图片就跨了三层。不过不建议跨单层,因为跨单层就相当于线性变换了,效果不佳。
因为最后才送入relu函数中,那么跨单层就类似于:H(x) = F(x) + x,其中F(x)=w1*x
而两层的话,F(x) = w2*ReLU(w1*x)
上面只是随便举个例子,示意一下,勿较真
7. 网络架构介绍:
来自作者的原表格:

这个表格很容易看懂,我只稍微提几点:
- 为什么上面没有作者尝试的1000层,因为1000层只是作者的初次尝试,里面仍然存在一些问题等待解决(比如作者的1000层效果并不佳,和100层的类似)
- FLOPs(flop + s): 浮点运算数,是计算量的体现。还有一个类似的是FLOPS(floating-point operations per second),是每秒浮点运算次数,体现了计算速度。(可以从英文单词角度记忆)
另外还有一张图,是ResNet-34的架构,帮助大家辅助理解上表(不过这张图有点小,大家可以把论文下载下来看):

8. 总结:
ResNet可以说是图像分类的一个小巅峰,是一个很常用的网络结构 。其主要贡献就是提出残差学习框架,并探索了更深的网络模型,为后面的发展继续开拓了道路。
如果你对使用pytorch实现ResNet感兴趣,可以看我的另外两篇文章,一篇是实现ResNet架构,另外一篇是侧重训练、测试。(必须提一句,前一篇有些笔误的地方,在后一篇中提及并改正了)
https://blog.csdn.net/weixin_46676835/article/details/128745885
https://blog.csdn.net/weixin_46676835/article/details/129716004