[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介
Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation [SIGIR'22]
论文链接:Are Graph Augmentations Necessary? | Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval
XSimGCL: Towards Extremely Simple Graph Contrastive Learning for Recommendation
论文链接:XSimGCL: Towards Extremely Simple Graph Contrastive Learning for Recommendation
背景/动机
基于对比学习的图推荐系统已经引起了广泛的关注,并且在收敛速度、推荐性能和鲁棒性等方面均占山出明显优势。以SGL为代表的图对比推荐方法采用基于抽样、dropout等方式的图数据增强策略来构造用户-物品交互图的不同视角,以此提供额外监督信号,该过程如下图所示:
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第1张图片](http://img.e-com-net.com/image/info8/ac31967e88b3486fb1a50cb41563c76e.jpg)
虽然这些基于图数据增强的方法取得了令人瞩目的性能提升,但隐藏在提升背后的真正原因并未被挖掘,即对比学习为什么会提升推荐性能,以及数据增强是否真的必要?
回顾基于对比学习的图推荐系统
一般地,基于对比学习的图推荐系统通过构造两个不同的图视角,并计算跨视角的对比损失以向主推荐任务提供额外的监督信号,这样的对比损失定义如下:
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第2张图片](http://img.e-com-net.com/image/info8/8d91d8efb64e491e98b601a583d2a869.jpg)
其中![]() 和
和![]() 是在不同图视角里学习得到的嵌入表示,
是在不同图视角里学习得到的嵌入表示, 是温度系数。具体来说,对比损失鼓励同一节点的两个视角的一致性,同时让负样本节点在特征空间里远离正样本节点。不失一般性,在不同视角里的嵌入表示通常是利用LightGCN进行学习。
是温度系数。具体来说,对比损失鼓励同一节点的两个视角的一致性,同时让负样本节点在特征空间里远离正样本节点。不失一般性,在不同视角里的嵌入表示通常是利用LightGCN进行学习。
很显然,为了执行该对比损失,数据增强环节必不可少,这包含一系列复杂且耗时的矩阵运算。为了进一步分析对比损失,作者为SGL构造了一个变体,称为SGL-WA(WA代表without augmentation,即不进行数据增强),其对应的对比损失定义为:
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第3张图片](http://img.e-com-net.com/image/info8/c327850dba0144d79f87a5cc3bcc8614.jpg)
作者在Yelp2018和Amazon-Book数据集上将SGL-WA与LightGCN和SGL的三种数据增强方法(分别为SGL-ND,SGL-ED和SGL-WA)进行了对比实验,结果如下表所示:
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第4张图片](http://img.e-com-net.com/image/info8/80127a80ceb4454dab7a1e219aa667e4.jpg)
其中CL Only代表只最小化SGL中的对比损失。实验结果表明所有SGL的变体均优于没有应用对比学习的LightGCN,这展示了对比学习的有效性。另一方面,移除数据增强后,SGL-WA的性能和SGL-ED仍然具有可比性,这一结果反映出一个结论:影响性能的核心是对比损失本身,而非数据增强。
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第5张图片](http://img.e-com-net.com/image/info8/43c789b775ef4a7e983304efb9c8b62f.jpg)
基于此,作者进一步给出了将学习到的嵌入表示映射至超球面上的2维向量的t-SNE图 ,随后用非参数高斯核密度估计绘制特征分布 。简单来说,映射的嵌入表示在超球面越接近圆环,或者特征分布越平滑,则代表该分布越接近均匀分布。从上图可以清晰地看出LightGCN表现出明显的聚类效应,而后续几个利用对比学习的方法的分布则更接近于均匀分布。
LightGCN作为一种基于信息传播和信息聚合的图推荐范式,随着图卷积层的变多,节点之间的相似性开始变大,并且趋向于高度流行的物品,从而加剧流行度偏差问题(popularity bias),这一问题在使用基于BPR损失的优化措施的情况下变得更为严重,推荐模型的训练梯度会大幅偏向于热门物品。
在XSimGCL论文中,作者则给出更为清晰的分析。具体来说,随机选择用户绘制t-SNE图的策略转变为绘制流行/冷启动用户和物品的t-SNE图,如下所示:
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第6张图片](http://img.e-com-net.com/image/info8/97c3b07efae94154a1adb6ba3e1941c3.jpg)
![]()
一个清晰的发现是活跃用户和热门物品具有相似分布,同时冷启动用户同样贴近于热门物品,于此同时冷启动物品则“无人问津”,独自形成一种分布。这一结果更加凸显出LightGCN会倾向于推荐热门物品的偏向性,从而导致长尾物品无法被推荐。
对于SGL-WA,可将其对比损失进行改写:

可以看出优化对比损失的本质是最小化不同节点嵌入之间的相似性(通常通过内积计算),这会使节点在特征空间里相互远离,从而形成均匀分布。至此,可以得出结论:分布的均匀性(uniformity)是SGL的推荐性能得到提升的核心因素,而不是冗余的数据增强。至此,则又有一个新的问题,即如何在不进行数据增强的前提下进行高效的对比学习?
SimGCL
由于操纵图结构来实现均匀的表示分布是费时且棘手的,所以可以从嵌入空间的视角重新考虑。具体来说,可以向嵌入表示直接添加随机噪声以实现数据增强:

其中添加的噪声变量满足![]() ,并且有
,并且有

该过程如下图所示,通过向原始表示增加随机噪声向量,原始表示通过两个很小的角度进行旋转:
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第7张图片](http://img.e-com-net.com/image/info8/5a0a7aa5ef044b7c9785779ea6198edd.jpg)
由于旋转足够小,增强后的嵌入表示依然保留着大部分原始信息。
与SGL一致,SimGCL同样采用LightGCN作为GNN模型。在每个图卷积层,不同的噪声向量均被加入目前的节点嵌入:
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第8张图片](http://img.e-com-net.com/image/info8/49391decd0b4430aa92c434f5e92c8be.jpg)
其中
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第9张图片](http://img.e-com-net.com/image/info8/411f6604d87e45dfb4be499ceda7fa09.jpg)
XSimGCL
相比于SGL,SimGCL更为轻量级,因为其无需额外的数据增强操作。然而,SimGCL仍然受限于对比学习辅助任务,这使得其训练过程变得冗余。在每次迭代中,其都需要计算三次图卷积才能获得损失并反向传播。基于此,作者采用了跨层对比(cross-layer contrast)的思想,如下图所示:
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第10张图片](http://img.e-com-net.com/image/info8/45c6ada59a5544de8f60acf04adb9c77.jpg)
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第11张图片](http://img.e-com-net.com/image/info8/07e08cada85f49ef99530fa589e85d37.jpg)
可以看出XSimGCL将辅助的对比学习任务融于主推荐任务中,并且采用跨层对比来计算对比损失:
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第12张图片](http://img.e-com-net.com/image/info8/fdbad51b3e9844dca83e66cbdf5dd4d8.jpg)
其中![]() 表示与最终层进行对比的指定层数。
表示与最终层进行对比的指定层数。
时间复杂度
下表给出了LightGCN、SGL、SimGCL和XSimGCL的时间复杂度对比:
![[SIGIR‘22]图对比推荐论文SimGCL/XSimGCL算法和代码简介_第13张图片](http://img.e-com-net.com/image/info8/e9762eff48d74c7b8e7078742e0daeee.jpg)
其中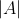 是交互图的边数,
是交互图的边数, 是嵌入大小,
是嵌入大小, 是批大小,
是批大小, 表示每个批次中用户个数,
表示每个批次中用户个数, 表示GCN层数,
表示GCN层数, 表示SGL-ED的边保留比率。
表示SGL-ED的边保留比率。
从上表可以看出,在移除了数据增强操作后,SimGCL和XSimGCL的时间复杂度显著降低。由于SGL-ED和LightGCN需要分别完成主任务和辅助任务,这使得SGL-ED和SimGCL在图卷积过程中的时间复杂度为LightGCN的3倍,而XSimGCL与LightGCN的时间复杂度一致。
实验
未完待续。