山东大学NLP实验2
利用给定的中英文文本序列(见Chinese.txt 和 English.txt),分别利用以下给定的中英文分词工具进行分词并对不同分词工具产生的结果进行简要对比分析,将实验过程与结果写成实验报告,实验课结束后提交。
需要注意授权是否过期,而解决方法就是去下载心得license以更新授权。
问题2:安装apscy时出现诸多问题:

解决:主要是这个语言模型安装有点问题,先去官网找到需要的模型名字叫什么,然后去这个github下载,一定要注意语言模型要和自己的spacy版本对应。下载地址:spacy-models,下载之后不用解压,记住这个绝对路径。
Wget https://github.com/explosion/spacy-models/releases/download/
en_core_web_sm-2.3.0/en_core_web_sm-2.3.0.tar.gz
然后在安装:
pip install C:\Users\86138\Desktop\exp2\en_core_web_sm-2.3.0.tar.gz
问题3:在尝试使用StanfordCoreNLP 进行中文分词时,发生了报错现象。报错信息为编码不正确,使用的为 4.4.0 版本。
解决:怀疑是Python 版本与StanfordCoreNLP 版本不匹配引发的错误。
github 仓库中提供的版本对应表Python 版本最低到3.7 ,而我使用的是3.6 版本。之后更改为3.7.0 版本,但分词结果全为空。最后更改到3.9.1 版本(尝试了github 仓库中提供样例使用的版本),得到正确的结果。
中文分词:
首先我们查看一下数据集,中文数据集为一段中文文本:
Jieba:
结巴分词是用于中文分词的分词工具,安装与使用都比较容易掌握,而且结巴分词支持三种分词模式:
1.精确模式,试图将句子最精确地切开,适合文本分析;
2.全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
3.搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
这次实验使用三种不同的模式,来对实验文件内的中文文档内容进行分词。
使用全模式如下:

全模式的分词结果如下:发现全模式基本将词分成2个或3个词,并且部分词会重复出现在不同分词里,该模式运行结果符合其特点:把句子中所有的可以成词的词语都扫描出来。比如将 湖北省 分成了 湖北 和 湖北省 ,将 消费者 分成 消费 和 消费者 等。将分词结果拼接起来,容易改变原句子的意思。

使用精确模式如下:

精确模式的分词结果如下:结果比全模式的好一点,是按照文本分词,没有复制字去分不同的词。该模式相较于Full Mode 来说,该模式容易将不同的形容词结合成一个词,而不容易将形容词与名词结合在一起。比如将 土鸡蛋 分成 土 , 鸡蛋 。将 好土商标 分成了 好土 , 商标 。词性区分比较明显。但是不能很好地处理专有名词,比如将 新京报 分成 新 ,京报 。
使用搜索引擎模式如下:

搜索引擎模式的分词结果如下:与全模式一样,部分词会重复出现在不同分词里。其分词结果与精确模式相差不大,在精确模式的基础上,对长词进行了再拆分。比如将有限公司分为了有限,公司和有限公司。再分词确实有利于搜索时触发关键词。

使用自定义词典:
首先我们将一些不常见的词写下来,如“湖北神丹健康食品有限公司”方便 分词使用:
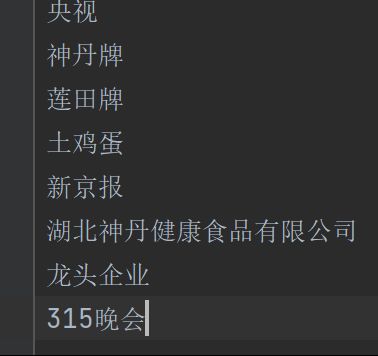

自定义词典的分词结果如下:可以发现因为加入了自定义的词典,部分生僻词很好的得到了很好的解决:
SnowNLP:
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,这个类库可以做的事情很多,例如中午分词、词性标注、情感分析、文本分类、文本相似等等十多种功能,而这次我要用的仅仅是最简单的分词功能:

Snownlp还可以得到文本的拼音:

Snownlp还可以提取文本的关键词,比如这里提取3个关键词:


HULAC:
THULAC(THU Lexical Analyzer for Chinese)是由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。它具有能力强、准确率高、速度较快等特点。

Thulac分词结果入下:发现其主要将词分为1或2个字,效果不是很好。同时它可以对所得的分词进行词性标注。该模型对专有名词的识别有不错的能力,可以识别出 神丹牌_nz , 莲田牌_nz 等。但是该能力不稳定,可能是受上下文影响。比如前面不能识别土鸡蛋,将其分成土_a 鸡蛋_n ,后面却可以识别出土鸡蛋_n 。前面可以识别出新京报_nz ,后面却将其识别成了新_a 京报_n 。但总体识别结果优于前面出现的其他模型。
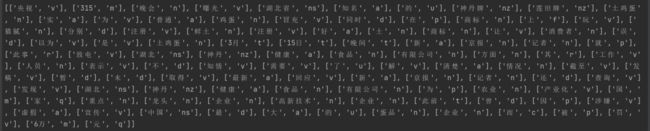
NLPIR:
Nlpir分词结果如下:其与thulac一样,主要分为1-2个字,但整体来说,效果较好一点。同时它也可以对分词进行词性标注。该模型倾向于利用词性进行分词,容易将专有词,按不同词性划分成好几个词。常见的术语如 有限公司 , 高新技术 等分词效果较好。对不常见的 土鸡蛋 则会将其分成 土 和 鸡蛋。
StanfordCoreNLP:
斯坦福大学的分词工具,在使用之前要下载一些比较大的包,所以在使用中遇到了一些问题,不过都是可以通过百度解决的

该模型也是主要依据词性而不是语义来进行分词,不能在专有词的分词上取得比较好的结果。

各自的实验结果在实验步骤中已经给出,这里我分别对中文分词和英文分词的分词结果进行总结对比。
中文分词
中文分词中,jieba 中的 paddle 方法分词效果是最好的。该方法可以在一定程度上识别名称和专有名词,不会刻意地将一个比较长的词分成不同的部分。它相交于其它方法最显著的不同就是出现了湖北神丹健康食品有限公司这一名称,这在其他模型中是没有出现过的。但是其速度在jieba 中略慢。
其次,效果第二好的就是THULAC 。该模型对专有名词的识别有不错的能力,可以识别出神丹牌_nz ,莲田牌_nz 等。但是该能力不稳定,可能是受上下文影响。比如前面不能识别土鸡蛋,将其分成土_a 鸡蛋_n ,后面却可以识别出土鸡蛋_n 。前面可以识别出新京报_nz ,后面却将其识别成了新_a 京报_n 。但总体识别结果仅次于上面评价一个模型的好坏都是通过,其分词后的结果是否符合人类阅读习惯来划分的。但是针对不同的用途,可以使用不同的模型。像jieba 中的搜索引擎模式,倾向于将词的彻底拆分。不仅保留拆分的词,而且对拆分后的词进行再拆分,且保留结果。这有利用用户输入关键字,就能搜索得到想要的内容。
其他方法各有优劣,但是StanfordCoreNLP 有很明显的缺点,使用复杂,运行速度慢。
英文分词
从实验结果看,分词效果为StanfordCoreNLP > NLTK > Spacy 。
StanfordCoreNLP 分词效果与人工分词相比差异不大,准确分词出family's ,coauthored ,$3.1 等复合型结构。NLTK 能够分词出co-authored ,Spacy 会将coauthored 分成co ,- ,authored 三部分,效果不佳。
总的来说,上述各种方法都能起到分词的作用,且都具有自己的特点。英文分词相对中文分词来说要简单一些,英文分词主要任务是区分word ,而中文分词会设计到很多phrase 。
1.自定义字典的作用?
有很多专有名词是算法学不准的,而且一个词拆不拆,从分词器角度出发,不一定跟人一样。所以词典相当于一个规则,但每个分词的词典作用不一。例如thulac的词典影响不大,添加的词没有绝大部分都分出来。pkuseg的词典没有词频数据,部分词的词性会被强制变成词典中的词性。对词典的准确率的要求很高。
2.jieba
jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用
jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
3. snownlp
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的unicode编码,所以使用时请自行decode成unicode。
4 THULAC
THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。THULAC具有如下几个特点:
1.能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
2.准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
3.速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。
5.中英文分词的3个典型区别
区别1:分词方式不同,中文更难
英文有天然的空格作为分隔符,但是中文没有。所以如何切分是一个难点,再加上中文里一词多意的情况非常多,导致很容易出现歧义。下文中难点部分会详细说明。
区别2:英文单词有多种形态
英文单词存在丰富的变形变换。为了应对这些复杂的变换,英文NLP相比中文存在一些独特的处理步骤,我们称为词形还原(Lemmatization)和词干提取(Stemming)。中文则不需要
词性还原:does,done,doing,did 需要通过词性还原恢复成 do。
词干提取:cities,children,teeth 这些词,需要转换为 city,child,tooth”这些基本形态
区别3:中文分词需要考虑粒度问题
例如「中国科学技术大学」就有很多种分法:
中国科学技术大学
中国\ 科学技术 \ 大学
中国\ 科学 \ 技术 \ 大学
粒度越大,表达的意思就越准确,但是也会导致召回比较少。所以中文需要不同的场景和要求选择不同的粒度。这个在英文中是没有的。