图像分类算法:AlexNet论文解读
图像分类算法:AlexNet论文解读
前言
其实网上已经有很多很好的解读各种论文的文章了,但是我决定自己也写一写,当然,我的主要目的就是帮助自己梳理、深入理解论文,因为写文章,你必须把你所写的东西表达清楚而正确,我认为这是一种很好的锻炼,当然如果可以帮助到网友,也是很开心的事情。
说明
如果有笔误或者写错误的地方请指出(勿喷),如果你有更好的见解也可以提出,我也会认真学习。
目录结构
文章目录
-
- 图像分类算法:AlexNet论文解读
-
- 1. 背景简介:
- 2. 论文内容概述:
- 3. 基础知识点:
-
- 3.1 CNN相比于ANN的优点:
- 3.2 ImageNet与ILSVRC:
- 3.3 Top-1与Top-5:
- 4. 模型架构:
-
- 4.1 双GPU架构:
- 4.2 单GPU架构:
- 5. 架构细节:
-
- 5.1 激活函数:
- 5.2 LRN归一化:
- 5.3 重叠池化:
- 5.4 防止过拟合的手段:
- 6. 训练细节:
- 7. 作者的一个发现:
- 8. 总结:
1. 背景简介:
在当时,人们主要还是使用机器学习方法来应对各种任务,这种方法在小数据集上表现很好,比如在论文中提及MNIST手写数字识别任务最佳错误率接近人类性能。但是,现实中,物体具有更大的可变性,想要识别它们,需要在大数据集上训练,但是大数据集意味着要求我们使用一个更强大的模型。
基于此,作者提出了由CNN构成的AlexNet。
2. 论文内容概述:
作者提出了一个名为AlexNet 的CNN架构网络,该网络由八层构成(不包含池化层),在其中使用了数据增强、dropout、relu激活函数等技术,并采取了GPU训练网络,在2012年的ImageNet的一个比赛上取得了很好的结果。
3. 基础知识点:
3.1 CNN相比于ANN的优点:
最直观的优点肯定是参数少。
如下图:
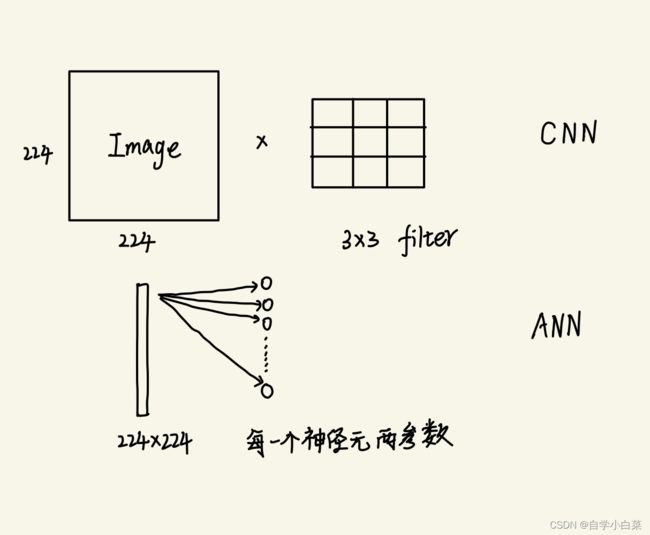
假设输入图像为224*224,卷积用3*3卷积
===>
CNN : 9个参数,即3*3卷积核共9个参数
ANN : 很多参数,因为线性连接要求输入固定,而输入为图像的话要拉平,即224*244=50176
3.2 ImageNet与ILSVRC:
ImageNet是一个大型开源数据集(没错你可以在网上获取图片,这也可以成为你自己用来训练网络的数据),有超过1500万张图片,大约22000个类别高分辨率图片。
而ILSVRC是ImageNet举行的一个图像分类比赛,一年一度,其使用ImageNet的一个子集,大约120万张训练图片,5万张验证图片,15万张测试图片。
3.3 Top-1与Top-5:
这里的Top-1与Top-5在论文中指的是错误率,Top-5就是图像得出的结果中,模型认为最有可能是正确标签的前五个,Top-5错误率就是指这五个都不是真实标签的概率。Top-1与之对应理解即可。
4. 模型架构:
值得一提的是,当时作者由于算力受限,采取了两块GPU训练,因此将模型架构分类两条路走。现在的话,大家复现AlexNet都不会分两条路,而是合并一条来走。但是,现在,你训练大规模数据集,其实也是采取多个GPU的思路来训练的。
这里,我两个都会介绍一下,但是主要介绍一条路的架构。
4.1 双GPU架构:
论文原图:
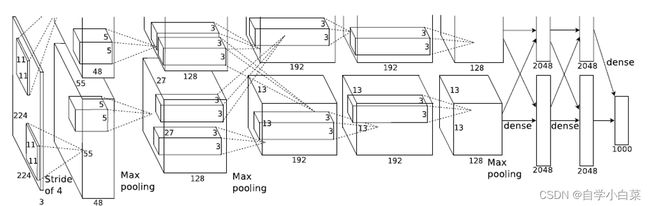
上图中输入图像大小为224*224,其实应该是作者笔误了,输入大小应该为227*227。因为,当输入大小为224时,经过第一层卷积(11*11,S=4,P=0),输出特征图大小应该为:
(224-11)/4 + 1 = 54.25
当输入改为227后,输出特征图大小为:
(227-11)/4 + 1 = 55
此时才符合图中的标注,即55*55。
补充: 计算输出大小公式
输出大小 = (图像大小 - 卷积核大小 + 2*padding)/stride + 1
4.2 单GPU架构:
来自网上经典的图:
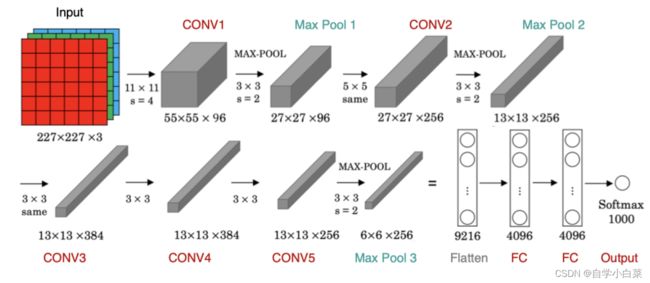
这张图可以说时清晰明了了,可以把这张图转为一个表格,然后大家可以根据上面的公式和表格子集推一下,很简单的:

5. 架构细节:
5.1 激活函数:
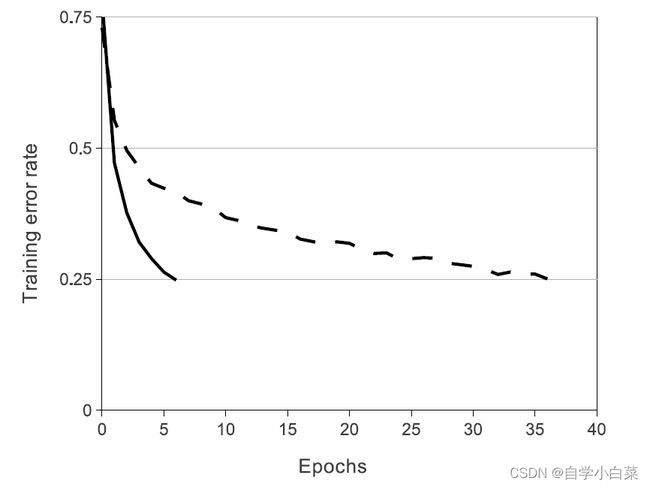
作者采用了新的激活函数ReLU,相信大家对这个激活函数肯定不陌生。
而在论文中,作者发现使用ReLU作为激活函数,比tanh激活函数收敛快几倍,如下图所示:
5.2 LRN归一化:
LRN叫做局部响应归一化,作者发现将该方法加入网络中,提高了约1.2%、1.4%的精度。
公式如下:
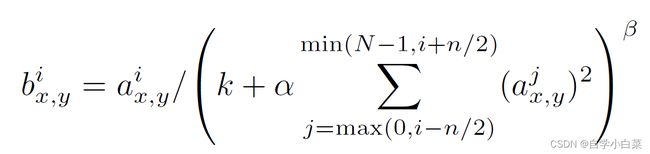
其中,N为通道数,k、α、β、n为超参数,a(上标i,下标xy)表示第i个核在(x,y)位置上ReLU后的输出值。
公式很复杂,但是可以用图来直观理解,如图:
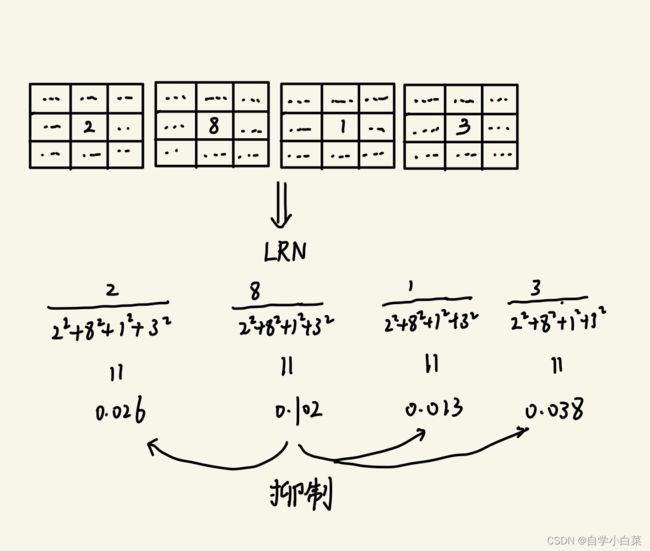
LRN模仿人类的神经细胞,兴奋的神经元抑制其它神经元。比如上图中,中心点位置的值,8这个值最大,我们认为最兴奋,按照计算公式,可以发现经过LRN后的值,8变为了0.102,而其他值都非常小,这就是抑制作用。
但是,在后面的VGG论文中证明了LRN没有什么作用,因此后面就被抛弃了,基本没人用LRN了,而是采用更好用的BN。
5.3 重叠池化:
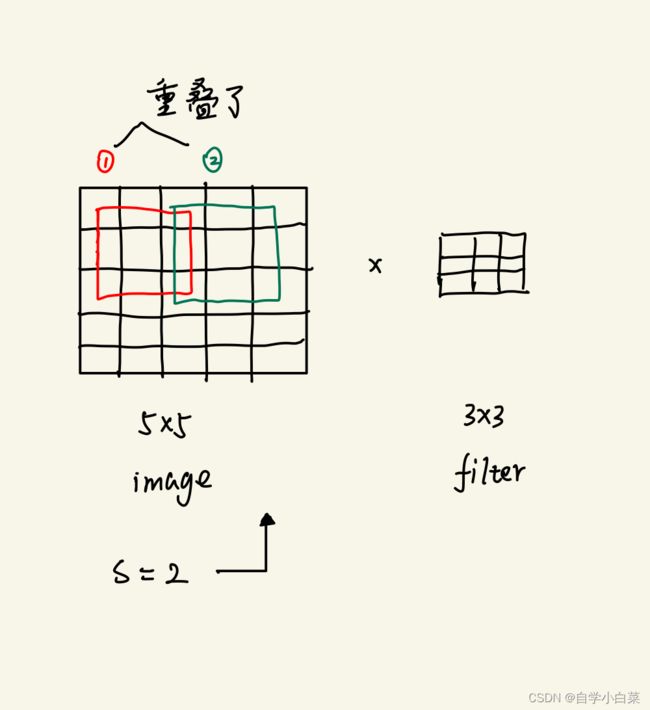
作者采取了重叠池化的操作,因为作者认为这个方法可以缓解过拟合问题。
什么叫做重叠池化?即步长S小于核的大小,如下图所示:
5.4 防止过拟合的手段:
作者主要采取了两种方法取防止过拟合:
- dropout方法:随机杀死神经元
- 图像增强:图像平移、水平翻转、改变图像RGB通道强度等
6. 训练细节:
- 优化器:SGD
- 学习率0.01,动量0.9
- 权重衰减0.0005
- batch_size为128
- 参数初始化:均值为0,方差为0.01的高斯分布
- 启发式调整学习率:并行验证集,当验证集精度不提示时,学习率除以10
解释:权值衰减
这个我也是看别人博客写的。
当网络过拟合时,网络权值逐渐变大,因此为了避免过拟合,会给误差函数加一个项,一般使用所有权值的平方乘以一个权值衰减常数之和,用于惩罚大权值。称之为权值衰减。
7. 作者的一个发现:
作者发现深度似乎很重要,因为他删除网络任何一个层,结果都会变化很大。
这一点在后面的VGG论文中,深入探讨了深度的重要性。
8. 总结:
其实深度学习一直在进步,比如九几年便有LeNet5这个网络,不过受限于算力和数据集,这个网络仅仅用于了MNIST手写数字数据。不过该网络为CNN架构打定了基础,即架构通常为卷积–池化—卷积—池化—等等—全连接—全连接—输出。
AlexNet的贡献:
- GPU训练
- ReLU、dropout、图像增强等技术手段
- 网络自动提取的特征打败了人工提取的特征
AlexNet像小火苗,点燃了装满炸药的桶,也点燃了深度学习的热潮。固然,最新的网络很强,但是读以前的网络架构,会带给我们更多的思考。
也欢迎大家阅读我的另外两篇博客,pytorch实现AlexNet架构 and 基于pytorch实现AlexNet并训练和测试:
https://blog.csdn.net/weixin_46676835/article/details/128730161
https://blog.csdn.net/weixin_46676835/article/details/128773953