python自动化测试之DDT数据驱动,使用excel实现数据分离实战
python自动化测试之DDT数据驱动,使用excel实现数据分离实战
以往都是说使用yaml做数据分离,这篇来说一下excel
1.什么是DDT
DDT data driver test数据驱动
它是主流的设计模式之一
核心技能:独立搭建一套落地产出自动化框架
1)满足实现测试各种工作
2)满足一定的通用性 易用性,不懂代码的人也可以维护自动化测试 满足所有的项目
3)工作效率最大化
为什么基于DDT进行对应设计,它的意义?
数据驱动意义:多组数据对同一脚本实现测试,从而实现脚本与数据分离,提高代码复用性及扩展维护。
线性代码存在问题:
1.代码冗余
2.维护成本高
2.DDT应用
类装饰器ddt 继承TestCase基类
三个方法装饰器
1.data(元组/列表/字典)参数接受多组数据,数据可以是元组或者列表、字典
2.file_data(文件)数据文件:yaml\json
3.unpack()复杂结构的数据,通过这个方法进行分解多个参数
3.协程项目实战execl
用例管理文件excel、yaml
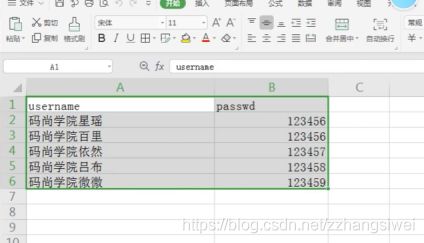
常见的数据文件操作,我们需要搞清楚什么是工作簿,工作表,单元格
1.excel文件常用操作模块有以下三种 openpyxl xlrd pandas
2.openpyxl实现excel文件操作
3.这里我们选择第一个安装 pip install openpyxl
(1)工作簿
(2)工作表
(3)单元格
1)获取工作表单个数据的方法
import openpyxl
#加载工作簿
wk=openpyxl.load_workbook('testdata.xlsx')#这里得是xlsx的不然会报错
#获取存储数据的工资表
sheet1=wk["Sheet1"]
#获取某个单元格数据
print(sheet1.cell(row=2,column=1).value) #获取第二行第一列
2)获取工作表所有数据的方法
思考如何把单元格所有数据取出来?
这里用循环就可以
#@File:getexceldata.py
import openpyxl
#加载工作簿
wk=openpyxl.load_workbook('testdata.xlsx')#这里得是xlsx的不然会报错
#获取存储数据的工资表
sheet1=wk["Sheet1"]
#获取某个单元格数据
print(sheet1.cell(row=2,column=1).value) #获取第二行第一列
print(f'最大行数:{sheet1.max_row}')
print(f'最大列数:{sheet1.max_column}\n')
# 思考如何把单元格所有数据取出来?
for i in range(1,sheet1.max_row+1):
for j in range(1,sheet1.max_column+1):
print(sheet1.cell(row=i,column=j).value)
3)用python存储获取的数据
接下来思考如何把这些数据存储起来,以什么格式存储?
excel数据传递给其它模块进行对应的业务处理,存储成python数据类型。
存储成例表字典,可以通过键值对取数据[{key1:value1},字典2]
#@File:getexceldata.py
import openpyxl
#加载工作簿
wk=openpyxl.load_workbook('testdata.xlsx')#这里得是xlsx的不然会报错
#获取存储数据的工资表
sheet1=wk["Sheet1"]
#获取某个单元格数据
print(sheet1.cell(row=2,column=1).value) #获取第二行第一列
print(f'最大行数:{sheet1.max_row}')
print(f'最大列数:{sheet1.max_column}\n')
# 思考如何把单元格所有数据取出来?
datalist=[]
for i in range(2,sheet1.max_row+1):
dict1={}
for j in range(1,sheet1.max_column+1):
key=sheet1.cell(row=1,column=j).value
value=sheet1.cell(row=i,column=j).value
# print(sheet1.cell(row=i,column=j).value)
dict1[key]=value
datalist.append(dict1)
print(datalist)
[{‘username’: ‘码尚学院星瑶’, ‘passwd’: 1}, {‘username’: ‘码尚学院百里’, ‘passwd’: 2}, {‘username’: ‘码尚学院依然’, ‘passwd’: 3}, {‘username’: ‘码尚学院吕布’, ‘passwd’: 4}, {‘username’: ‘码尚学院微微’, ‘passwd’: 5}]
取得excel数据,如何结合DDT实现循环测试
4)传几个参数就运行几次
import unittest
from selenium import webdriver
import time
from ddt import ddt,data,file_data,unpack
# from getexceldata import GetExcelData
@ddt
class Testcase_Demo(unittest.TestCase):
# @data(GetExcelData().getdata())
@data("星耀","小微","zsw")
def test_01(self,username):
print(username)
实际工作中不会向上面这样做,因为没有实现脚本和数据分离
5)从python函数里接受读到的参数
import unittest
from selenium import webdriver
import time
from ddt import ddt,data,file_data,unpack
from class202107.test_cases.getexceldata import GetExcelData
@ddt
class Testcase_Demo(unittest.TestCase):
# @data(GetExcelData().getdata())
# @data(("username:星耀11","passwd:小微22"))
@data(*GetExcelData().getdata())
def test_01(self,userdata):
print(userdata['username'],userdata['passwd'])
print(userdata)
6)一条用例执行几百几千次测试
#@File:testcase_01.py
import unittest
from selenium import webdriver
import time
from ddt import ddt,data,file_data,unpack
from class202107.test_cases.getexceldata import GetExcelData
@ddt
class Testcase_Demo(unittest.TestCase):
# @data(GetExcelData().getdata())
# @data(("username:星耀11","passwd:小微22"))
@data(*GetExcelData().getdata())
def test_01(self,userdata):
print(userdata['username'],userdata['passwd'])
print(userdata)
self.driver=webdriver.Chrome()
self.driver.get("https://passport.ctrip.com/user/login")
time.sleep(3)
self.driver.find_element_by_css_selector('#nloginname').send_keys(userdata['username'])
self.driver.find_element_by_css_selector("#npwd").send_keys(userdata['passwd'])
time.sleep(3)
self.assertIn("ctrip",self.driver.current_url)
以上代码读到几组数据就执行多少次,一次代码多次运行,避免代码冗余,方便维护,修改,数据分离保证安全性。
总体思路就是往excel写数据→使用python从excel读数据→使用python取到的数据,传送到代码里运行。