大数据存储与处理——配置HADOOP伪分布式
链接: https://pan.baidu.com/s/1j4nwwTne1AeAfa7x5zpEZQ 提取码: qdpj
首先了解hadoop的几种分布模式
1、本地模式:
本地模式就是解压源码包,不需要做任何的配置。通常用于开发调试,或者感受hadoop
2、伪分布模式:
在学习当中一般都是使用这种模式,伪分布模式就是在一台机器的多个进程运行多个模块。虽然每一个模块都有相应的进程,但是却还是运行在同一个系统里面。所以叫伪分布式。
3、完全分布式:
这种模式才是工作当中所用的模式,hadoop运行在多台机器上面,我们称之为hadoop集群。
4、HA:
在实际的工作当中,对于hadoop完全分布式来说,并不真正的可靠,因为hadoop完全分布式集群会有单点故障(namenode单点故障、yarn单点故障),所以一般都会对这个集群做HA,一般都是做namenode和yarn的高可用。
♥ hadoop分布式文件系统(HDFS):一种分布式文件系统,能够提供高可靠、高可用、可扩展以及对应用程序数据的高吞吐量访问。
♥ yarn :作业调度和资源管理的框架。
♥ MapReduce :基于yarn框架,用于并行计算处理大型数据集,是一种计算框架。
♥ ambari :基于Web的工具,用于配置,管理和监控Apache Hadoop集群,包括对Hadoop HDFS,Hadoop MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop的支持。Ambari还提供了一个用于查看群集运行状况的仪表板,例如热图,以及可视化查看MapReduce,Pig和Hive应用程序的功能,以及以用户友好的方式诊断其性能特征的功能。
♥ avro :数据序列化系统。
♥ cassandra:可扩展的多主数据库,没有单点故障。
♥ hbase:可扩展的分布式数据库,支持大型表的结构化数据存储。
♥ hive:一种数据仓库基础架构,提供数据汇总和即席查询。
♥ pig:用于并行计算的高级数据流语言和执行框架。
♥ spark:用于Hadoop数据的快速通用计算引擎。Spark提供了一种简单而富有表现力的编程模型,支持广泛的应用程序,包括ETL,机器学习,流处理和图形计算。
♥ zookeeper:用于分布式应用程序的高性能协调服务
建立伪分布式:
1:下载并接下hadoop
http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
tar -zxvf hadoop-2.7.1.tar.gz
可以改名字:mv hadoop-2.7.1 hadoop
这里我之前犯了一个很蠢的错误。。下载了hadoop的补充包导致里面没bin,sbin,没法配环境变量,下载的时候注意 200M左右才是对的
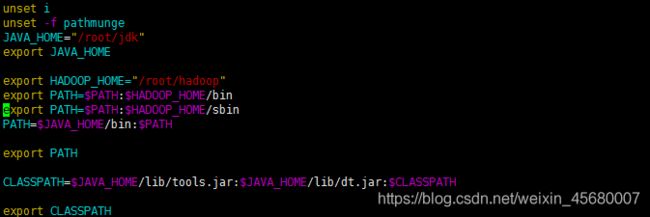
2:配置环境变量
因为需要配置JDK,所以和JDK一起配置即可
JAVA_HOME="/root/jdk"
export JAVA_HOME
export HADOOP_HOME="/root/hadoop"
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
PATH=$JAVA_HOME/bin:$PATH
export PATH
CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH
export CLASSPATH
#source /etc/profile
hadoop
3:配置相关文件
这些文件都在hadoop/etc/hadoop里
1.core-site.xml 配置如下:
hadoop.tmp.dir
file:/home/leesf/program/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000
其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
2.mapred-site.xml.template配置如下:
mapred.job.tracker
localhost:9001
3.hdfs-site.xml配置如下:
dfs.replication
1
dfs.namenode.name.dir
file:/home/leesf/program/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/home/leesf/program/hadoop/tmp/dfs/data
其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
补充,如果运行Hadoop的时候发现找不到jdk,可以直接将jdk的路径放置在hadoop.env.sh里面,具体如下:
export JAVA_HOME="/root/jdk"
运行hadoop
1:进入根目录,运行指令:
cd hadoop
#bin/hdfs namenode -format
显示下图则说明成功启动

2:开启NameNode和DataNode守护进程
使用如下命令开启:
sbin/start-dfs.sh,成功的截图如下:
[因为没有ssh免密,所以输入多次密码]

3:测试 #jps

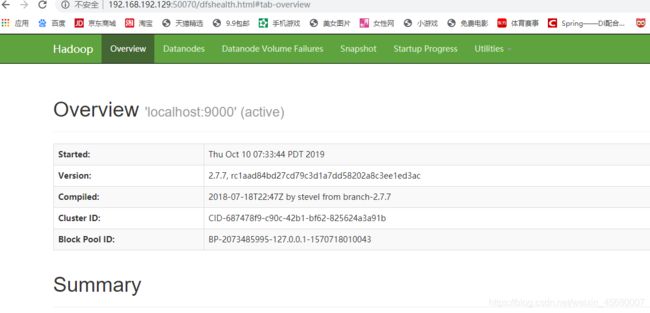
4::浏览器输入http://ip:50070
./stop-all.sh
配置Yarn集群
1:进入hadoop/etc/hadoop
配置
yarn-site.xml
同样在configuration中加入
yarn.resourcemanager.hostname
bigdata-test.com
yarn.nodemanager.aux-services
mapreduce_shuffle
2:启动
在根目录中
#sbin/yarn-daemon.sh start resourcemanager
#sbin/yarn-daemon.sh start nodemanager
3:测试
jps
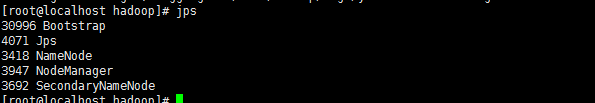
参考资料:
https://www.cnblogs.com/hello-/articles/9600269.html
https://blog.csdn.net/yuechu4492/article/details/80070326