实习-----Mybatis 框架
Mybatis 框架
ORM持久化介绍 了解
什么是“持久化”
即把数据(如内存中的对象)保存的磁盘的某一文件中
ORM概念
ORM,即Object Relational Mapping,它是对象关系映射的简称。它的作用是在关系型数据库和对象之间作一个映射,是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术(ORM解决的主要问题是对象关系的映射,一般情况下,一个持久化类和一个表对应,类的每个实例对应表中的一条记录,类的每个属性对应表的每个字段)。使程序能够通过操纵描述对象方式来操纵数据库。
简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。ORM在业务逻辑层和数据库层之间充当了桥梁的作用。
ORM的优劣势
优势
ORM解决的主要问题是对象和关系的映射。它通常把一个类和一个表一一对应,类的每个实例对应表中的一条记录,类的每个属性对应表中的每个字段。
ORM提供了对数据库的映射,不用直接编写SQL代码,只需像操作对象一样从数据库操作数据。
让软件开发人员专注于业务逻辑的处理,提高了开发效率。
劣势
ORM的缺点是会在一定程度上牺牲程序的执行效率。
经常使用ORM,会退化使用SQL的技能。
Mybatis 介绍 了解
Mybatis是一个优秀的持久层框架,也是一个半ORM(对象关系映射)框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
XML 配置文件 熟悉
属性(properties)
在XML配置文件中,配置项的排列顺序是有要求的,如上所排列,如果顺序放错,xml配置文件会提示报错(idea)
properties,
settings,
typeAliases,
typeHandlers,
objectFactory,
objectWrapperFactory,
reflectorFactory,
plugins,
environments,
databaseIdProvider,
mappers 
通过mapper元素引入映射文件的方法有4种:
使用类路径引入:
从 MyBatis 3.4.2 开始,你可以为占位符指定一个默认值。例如:
这个特性默认是关闭的。要启用这个特性,需要添加一个特定的属性来开启这个特性。例如:
如果一个属性在不只一个地方进行了配置,那么,MyBatis 将按照下面的顺序来加载:
首先读取在 properties 元素体内指定的属性。
然后根据 properties 元素中的 resource 属性读取类路径下属性文件,或根据 url 属性指定的路径读取属性文件,并覆盖之前读取过的同名属性。
最后读取作为方法参数传递的属性,并覆盖之前读取过的同名属性。
因此,通过方法参数传递的属性具有最高优先级,resource/url 属性中指定的配置文件次之,最低优先级的则是 properties 元素中指定的属性。
类型别名(typeAliases)
类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写。例如:
当这样配置时,Blog 可以用在任何使用 domain.blog.Blog 的地方。
也可以指定一个包名,MyBatis 会在包名下面搜索需要的 Java Bean,比如:
每一个在包 domain.blog 中的 Java Bean,在没有注解的情况下,会使用 Bean 的首字母小写的非限定类名来作为它的别名。 比如 domain.blog.Author 的别名为 author;若有注解,则别名为其注解值。见下面的例子:
@Alias("author")
public class Author {
...
}下面是一些为常见的 Java 类型内建的类型别名。它们都是不区分大小写的,注意,为了应对原始类型的命名重复,采取了特殊的命名风格。
别名 |
映射的类型 |
_byte |
byte |
_char (since 3.5.10) |
char |
_character (since 3.5.10) |
char |
_long |
long |
_short |
short |
_int |
int |
_integer |
int |
_double |
double |
_float |
float |
_boolean |
boolean |
string |
String |
byte |
Byte |
char (since 3.5.10) |
Character |
character (since 3.5.10) |
Character |
long |
Long |
short |
Short |
int |
Integer |
integer |
Integer |
double |
Double |
float |
Float |
boolean |
Boolean |
date |
Date |
decimal |
BigDecimal |
bigdecimal |
BigDecimal |
biginteger |
BigInteger |
object |
Object |
date[] |
Date[] |
decimal[] |
BigDecimal[] |
bigdecimal[] |
BigDecimal[] |
biginteger[] |
BigInteger[] |
object[] |
Object[] |
map |
Map |
hashmap |
HashMap |
list |
List |
arraylist |
ArrayList |
collection |
Collection |
iterator |
Iterator |
设置(settings)
设置名 |
描述 |
有效值 |
默认值 |
cacheEnabled |
全局性地开启或关闭所有映射器配置文件中已配置的任何缓存。 |
true | false |
true |
lazyLoadingEnabled |
延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。 |
true. | false |
false |
aggressiveLazyLoading |
开启时,任一方法的调用都会加载该对象的所有延迟加载属性。 否则,每个延迟加载属性会按需加载(参考 lazyLoadTriggerMethods)。 |
true | false |
false (在 3.4.1 及之前的版本中默认为 true) |
multipleResultSetsEnabled |
是否允许单个语句返回多结果集(需要数据库驱动支持)。 |
true | false |
true |
useColumnLabel |
使用列标签代替列名。实际表现依赖于数据库驱动,具体可参考数据库驱动的相关文档,或通过对比测试来观察。 |
true | false |
true |
useGeneratedKeys |
允许 JDBC 支持自动生成主键,需要数据库驱动支持。如果设置为 true,将强制使用自动生成主键。尽管一些数据库驱动不支持此特性,但仍可正常工作(如 Derby)。 |
true | false |
False |
autoMappingBehavior |
指定 MyBatis 应如何自动映射列到字段或属性。 NONE 表示关闭自动映射;PARTIAL 只会自动映射没有定义嵌套结果映射的字段。 FULL 会自动映射任何复杂的结果集(无论是否嵌套)。 |
NONE, PARTIAL, FULL |
PARTIAL |
autoMappingUnknownColumnBehavior |
指定发现自动映射目标未知列(或未知属性类型)的行为。
|
NONE, WARNING, FAILING |
NONE |
defaultExecutorType |
配置默认的执行器。SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(PreparedStatement); BATCH 执行器不仅重用语句还会执行批量更新。 |
SIMPLE REUSE BATCH |
SIMPLE |
defaultStatementTimeout |
设置超时时间,它决定数据库驱动等待数据库响应的秒数。 |
任意正整数 |
未设置 (null) |
defaultFetchSize |
为驱动的结果集获取数量(fetchSize)设置一个建议值。此参数只可以在查询设置中被覆盖。 |
任意正整数 |
未设置 (null) |
defaultResultSetType |
指定语句默认的滚动策略。(新增于 3.5.2) |
FORWARD_ONLY | SCROLL_SENSITIVE | SCROLL_INSENSITIVE | DEFAULT(等同于未设置) |
未设置 (null) |
safeRowBoundsEnabled |
是否允许在嵌套语句中使用分页(RowBounds)。如果允许使用则设置为 false。 |
true | false |
False |
safeResultHandlerEnabled |
是否允许在嵌套语句中使用结果处理器(ResultHandler)。如果允许使用则设置为 false。 |
true | false |
True |
mapUnderscoreToCamelCase |
是否开启驼峰命名自动映射,即从经典数据库列名 A_COLUMN 映射到经典 Java 属性名 aColumn。 |
true | false |
False |
localCacheScope |
MyBatis 利用本地缓存机制(Local Cache)防止循环引用和加速重复的嵌套查询。 默认值为 SESSION,会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地缓存将仅用于执行语句,对相同 SqlSession 的不同查询将不会进行缓存。 |
SESSION | STATEMENT |
SESSION |
jdbcTypeForNull |
当没有为参数指定特定的 JDBC 类型时,空值的默认 JDBC 类型。 某些数据库驱动需要指定列的 JDBC 类型,多数情况直接用一般类型即可,比如 NULL、VARCHAR 或 OTHER。 |
JdbcType 常量,常用值:NULL、VARCHAR 或 OTHER。 |
OTHER |
lazyLoadTriggerMethods |
指定对象的哪些方法触发一次延迟加载。 |
用逗号分隔的方法列表。 |
equals,clone,hashCode,toString |
defaultScriptingLanguage |
指定动态 SQL 生成使用的默认脚本语言。 |
一个类型别名或全限定类名。 |
org.apache.ibatis.scripting.xmltags.XMLLanguageDriver |
defaultEnumTypeHandler |
指定 Enum 使用的默认 TypeHandler 。(新增于 3.4.5) |
一个类型别名或全限定类名。 |
org.apache.ibatis.type.EnumTypeHandler |
callSettersOnNulls |
指定当结果集中值为 null 的时候是否调用映射对象的 setter(map 对象时为 put)方法,这在依赖于 Map.keySet() 或 null 值进行初始化时比较有用。注意基本类型(int、boolean 等)是不能设置成 null 的。 |
true | false |
false |
returnInstanceForEmptyRow |
当返回行的所有列都是空时,MyBatis默认返回 null。 当开启这个设置时,MyBatis会返回一个空实例。 请注意,它也适用于嵌套的结果集(如集合或关联)。(新增于 3.4.2) |
true | false |
false |
logPrefix |
指定 MyBatis 增加到日志名称的前缀。 |
任何字符串 |
未设置 |
logImpl |
指定 MyBatis 所用日志的具体实现,未指定时将自动查找。 |
SLF4J | LOG4J(3.5.9 起废弃) | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING |
未设置 |
proxyFactory |
指定 Mybatis 创建可延迟加载对象所用到的代理工具。 |
CGLIB (3.5.10 起废弃) | JAVASSIST |
JAVASSIST (MyBatis 3.3 以上) |
vfsImpl |
指定 VFS 的实现 |
自定义 VFS 的实现的类全限定名,以逗号分隔。 |
未设置 |
useActualParamName |
允许使用方法签名中的名称作为语句参数名称。 为了使用该特性,你的项目必须采用 Java 8 编译,并且加上 -parameters 选项。(新增于 3.4.1) |
true | false |
true |
configurationFactory |
指定一个提供 Configuration 实例的类。 这个被返回的 Configuration 实例用来加载被反序列化对象的延迟加载属性值。 这个类必须包含一个签名为static Configuration getConfiguration() 的方法。(新增于 3.2.3) |
一个类型别名或完全限定类名。 |
未设置 |
shrinkWhitespacesInSql |
从SQL中删除多余的空格字符。请注意,这也会影响SQL中的文字字符串。 (新增于 3.5.5) |
true | false |
false |
defaultSqlProviderType |
指定一个拥有 provider 方法的 sql provider 类 (新增于 3.5.6). 这个类适用于指定 sql provider 注解上的type(或 value) 属性(当这些属性在注解中被忽略时)。 (e.g. @SelectProvider) |
类型别名或者全限定名 |
未设置 |
nullableOnForEach |
为 'foreach' 标签的 'nullable' 属性指定默认值。(新增于 3.5.9) |
true | false |
false |
argNameBasedConstructorAutoMapping |
当应用构造器自动映射时,参数名称被用来搜索要映射的列,而不再依赖列的顺序。(新增于 3.5.10) |
true | false |
false |
的属性值
属性说明
id属性 ,resultMap标签的标识。
type属性 ,返回值的全限定类名,或类型别名。
autoMapping属性 ,值范围true(默认值)|false, 设置是否启动自动映射功能,自动映射功能就是自动查找与字段名小写同名的属性名,并调用setter方法。而设置为false后,则需要在resultMap内明确注明映射关系才会调用对应的setter方法。
子元素说明:
id元素 ,用于设置主键字段与领域模型属性的映射关系
result元素 ,用于设置普通字段与领域模型属性的映射关系
id、result语句属性配置细节:
属性 |
描述 |
property |
需要映射到JavaBean 的属性名称。 |
column |
数据表的列名或者标签别名。 |
javaType |
一个完整的类名,或者是一个类型别名。如果你匹配的是一个JavaBean,那MyBatis 通常会自行检测到。然后,如果你是要映射到一个HashMap,那你需要指定javaType 要达到的目的。 |
jdbcType |
数据表支持的类型列表。这个属性只在insert,update 或delete 的时候针对允许空的列有用。JDBC 需要这项,但MyBatis 不需要。如果你是直接针对JDBC 编码,且有允许空的列,而你要指定这项。 |
typeHandler |
使用这个属性可以覆写类型处理器。这项值可以是一个完整的类名,也可以是一个类型别名。 |
和的属性
注意:在采用嵌套结果的方式查询一对一、一对多关系时,必须要通过resultMap下的id或result标签来显式设置属性/字段映射关系,否则在查询多条记录时会仅仅返回最后一条记录的情况。
collection 它的属性大部分和association标签的属性相同,但多了个ofType属性
property:用于指定映射到的实体类对象的属性,与表字段一 一对应
column:用于指定表中对应的字段
javaType:用于指定映射到实体对象的属性的类型(要接收数据库数据的完整的java类对象名或别名)
jdbcType:用于指定数据表中对应字段的类型
fetchType:用于指定在关联查询时是否启动延迟加载。有lazy和eager两个属性值,默认值为lazy
select:用于指定引入嵌套查询的子SQL语句
autoMapping:用于指定是否自动映射
typeHandler:用于指定一个类型处理器
ofType:ofType与javaType属性对应,它用于指定实体类对象中的集合类属性所包含的类型(如List< A >,ofType就为A)
MyBatis就是通过collection标签用来实现一对多和多对多,association则用来实现一对一和多对一,而这两种方式实际上都涉及到两种查询分别是联合查询和嵌套子查询
https://www.cnblogs.com/achengmu/p/9241113.html
XML 映射文件 熟悉
https://www.w3cschool.cn/mybatis/f4uw1ilx.html
https://blog.csdn.net/poloto_s/article/details/123067441
Select 元素的属性
属性 |
描述 |
id |
在命名空间中唯一的标识符,可以被用来引用这条语句。 |
parameterType |
将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,默认值为未设置(unset)。 |
resultType |
期望从这条语句中返回结果的类全限定名或别名。 注意,如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身的类型。 resultType 和 resultMap 之间只能同时使用一个。 |
resultMap |
对外部 resultMap 的命名引用。结果映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂的映射问题都能迎刃而解。 resultType 和 resultMap 之间只能同时使用一个。 |
flushCache |
将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:false。 |
useCache |
将其设置为 true 后,将会导致本条语句的结果被二级缓存缓存起来,默认值:对 select 元素为 true。 |
timeout |
这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动)。 |
fetchSize |
这是一个给驱动的建议值,尝试让驱动程序每次批量返回的结果行数等于这个设置值。 默认值为未设置(unset)(依赖驱动)。 |
statementType |
可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
resultSetType |
FORWARD_ONLY,SCROLL_SENSITIVE, SCROLL_INSENSITIVE 或 DEFAULT(等价于 unset) 中的一个,默认值为 unset (依赖数据库驱动)。 |
databaseId |
如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有不带 databaseId 或匹配当前 databaseId 的语句;如果带和不带的语句都有,则不带的会被忽略。 |
resultOrdered |
这个设置仅针对嵌套结果 select 语句:如果为 true,则假设结果集以正确顺序(排序后)执行映射,当返回新的主结果行时,将不再发生对以前结果行的引用。 这样可以减少内存消耗。默认值:false。 |
resultSets |
这个设置仅适用于多结果集的情况。它将列出语句执行后返回的结果集并赋予每个结果集一个名称,多个名称之间以逗号分隔。 |
Insert, Update, Delete 元素的属性
属性 |
描述 |
id |
在命名空间中唯一的标识符,可以被用来引用这条语句。 |
parameterType |
将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,默认值为未设置(unset)。 |
parameterMap |
用于引用外部 parameterMap 的属性,目前已被废弃。请使用行内参数映射和 parameterType 属性。 |
flushCache |
将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:(对 insert、update 和 delete 语句)true。 |
timeout |
这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动)。 |
statementType |
可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
useGeneratedKeys |
(仅适用于 insert 和 update)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系型数据库管理系统的自动递增字段),默认值:false。 |
keyProperty |
(仅适用于 insert 和 update)指定能够唯一识别对象的属性,MyBatis 会使用 getGeneratedKeys 的返回值或 insert 语句的 selectKey 子元素设置它的值,默认值:未设置(unset)。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
keyColumn |
(仅适用于 insert 和 update)设置生成键值在表中的列名,在某些数据库(像 PostgreSQL)中,当主键列不是表中的第一列的时候,是必须设置的。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
databaseId |
如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有不带 databaseId 或匹配当前 databaseId 的语句;如果带和不带的语句都有,则不带的会被忽略。 |
selectKey 元素的属性
对于不支持自动生成主键列的数据库和可能不支持自动生成主键的 JDBC 驱动,MyBatis 有另外一种方法来生成主键。
属性 |
描述 |
keyProperty |
selectKey 语句结果应该被设置到的目标属性。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
keyColumn |
返回结果集中生成列属性的列名。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
resultType |
结果的类型。通常 MyBatis 可以推断出来,但是为了更加准确,写上也不会有什么问题。MyBatis 允许将任何简单类型用作主键的类型,包括字符串。如果生成列不止一个,则可以使用包含期望属性的 Object 或 Map。 |
order |
可以设置为 BEFORE 或 AFTER。如果设置为 BEFORE,那么它首先会生成主键,设置 keyProperty 再执行插入语句。如果设置为 AFTER,那么先执行插入语句,然后是 selectKey 中的语句 - 这和 Oracle 数据库的行为相似,在插入语句内部可能有嵌入索引调用。 |
statementType |
和前面一样,MyBatis 支持 STATEMENT,PREPARED 和 CALLABLE 类型的映射语句,分别代表 Statement, PreparedStatement 和 CallableStatement 类型。 |
单表 sql 和动态 sql 熟悉
动态 sql 熟悉
MyBatis if标签:条件判断
最常见的场景是在 if 语句中包含 where 子句,例如。
以上代表表示根据网站名称去查找相应的网站信息,但是网站名称是一个可填可不填的条件,不填写的时候不作为查询条件。
可多个 if 语句同时使用。以下语句表示为可以按照网站名称(name)或者网址(url)进行模糊查询。如果您不输入名称或网址,则返回所有的网站记录。但是,如果你传递了任意一个参数,它就会返回与给定参数相匹配的记录。
MyBatis choose、when和otherwise标签
MyBatis 中动态语句 choose-when-otherwise 类似于 Java 中的 switch-case-default 语句。由于 MyBatis 并没有为 if 提供对应的 else 标签,如果想要达到
SQL语句1
SQL语句2
SQL语句3
SQL语句4
choose 标签按顺序判断其内部 when 标签中的判断条件是否成立,如果有一个成立,则执行相应的 SQL 语句,choose 执行结束;如果都不成立,则执行 otherwise 中的 SQL 语句。这类似于 Java 的 switch 语句,choose 为 switch,when 为 case,otherwise 则为 default。
示例
以下示例要求:
当网站名称不为空时,只用网站名称作为条件进行模糊查询;
当网站名称为空,而网址不为空时,则用网址作为条件进行模糊查询;
当网站名称和网址都为空时,则要求网站年龄不为空。
SQL 语句中加入了一个条件“1=1”,如果没有加入这个条件,那么可能就会变成下面这样一条错误的语句。
SELECT id,name,url,age,country FROM website where AND name LIKE CONCAT('%',#{name},'%')MyBatis where标签
where 标签主要用来简化 SQL 语句中的条件判断,可以自动处理 AND/OR 条件,语法如下。
AND/OR ...
if 语句中判断条件为 true 时,where 关键字才会加入到组装的 SQL 里面,否则就不加入。where 会检索语句,它会将 where 后的第一个 SQL 条件语句的 AND 或者 OR 关键词去掉。
MyBatis set标签
在 Mybatis 中,update 语句可以使用 set 标签动态更新列。set 标签可以为 SQL 语句动态的添加 set 关键字,剔除追加到条件末尾多余的逗号。
UPDATE website
name=#{name}
url=#{url}
WHERE id=#{id}
MyBatis foreach标签
对于一些 SQL 语句中含有 in 条件,需要迭代条件集合来生成的情况,可以使用 foreach 来实现 SQL 条件的迭代。
Mybatis foreach 标签用于循环语句,它很好的支持了数据和 List、set 接口的集合,并对此提供遍历的功能。语法格式如下。
参数值
foreach 标签主要有以下属性,说明如下。
item:表示集合中每一个元素进行迭代时的别名。
index:指定一个名字,表示在迭代过程中每次迭代到的位置。
open:表示该语句以什么开始(既然是 in 条件语句,所以必然以(开始)。
separator:表示在每次进行迭代之间以什么符号作为分隔符(既然是 in 条件语句,所以必然以,作为分隔符)。
close:表示该语句以什么结束(既然是 in 条件语句,所以必然以)开始)。
使用 foreach 标签时,最关键、最容易出错的是 collection 属性,该属性是必选的,但在不同情况下该属性的值是不一样的,主要有以下 3 种情况:
如果传入的是单参数且参数类型是一个 List,collection 属性值为 list。
如果传入的是单参数且参数类型是一个 array 数组,collection 的属性值为 array。
如果传入的参数是多个,需要把它们封装成一个 Map,当然单参数也可以封装成 Map。Map 的 key 是参数名,collection 属性值是传入的 List 或 array 对象在自己封装的 Map 中的 key。
MyBatis bind标签
每个数据库的拼接函数或连接符号都不同,例如 MySQL 的 concat 函数、Oracle 的连接符号“||”等。这样 SQL 映射文件就需要根据不同的数据库提供不同的实现,显然比较麻烦,且不利于代码的移植。幸运的是,MyBatis 提供了 bind 标签来解决这一问题。
bind 标签可以通过 OGNL 表达式自定义一个上下文变量。
比如,按照网站名称进行模糊查询,SQL 映射文件如下。
bind 元素属性如下。
value:对应传入实体类的某个字段,可以进行字符串拼接等特殊处理。
name:给对应参数取的别名。
以上代码中的“_parameter”代表传递进来的参数,它和通配符连接后,赋给了 pattern,然后就可以在 select 语句中使用这个变量进行模糊查询,不管是 MySQL 数据库还是 Oracle 数据库都可以使用这样的语句,提高了可移植性。
MyBatis trim标签
在 MyBatis 中除了使用 if+where 实现多条件查询,还有一个更为灵活的元素 trim 能够替代之前的做法。
trim 一般用于去除 SQL 语句中多余的 AND 关键字、逗号,或者给 SQL 语句前拼接 where、set 等后缀,可用于选择性插入、更新、删除或者条件查询等操作。trim 语法格式如下。
SQL语句
trim 中属性说明如下。
属性 |
描述 |
prefix |
给SQL语句拼接的前缀,为 trim 包含的内容加上前缀 |
suffix |
给SQL语句拼接的后缀,为 trim 包含的内容加上后缀 |
prefixOverrides |
去除 SQL 语句前面的关键字或字符,该关键字或者字符由 prefixOverrides 属性指定。 |
suffixOverrides |
去除 SQL 语句后面的关键字或者字符,该关键字或者字符由 suffixOverrides 属性指定。 |
单表sql好文:https://blog.csdn.net/z2598849479/article/details/126288204
动态sql好文:https://blog.csdn.net/partworld/article/details/125232457
动态sql好文:http://c.biancheng.net/mybatis/sql-dynamic.html
mybatis 逆向工程自动生成代码 了解
https://cloud.tencent.com/developer/article/2095433
Spring+DruidDataSource +Mybatis 框架整合 熟悉
https://blog.csdn.net/Numb_ZL/article/details/126357068
事务注意事项 熟悉
https://www.myttjp.com/share/10771.html
https://blog.csdn.net/CSDN_WYL2016/article/details/122254559
mybatis sql语句里写 #和$区别?
#{}是预编译处理,是占位符,${}是字符串替换,是拼接符
Mybatis在处理#{}的时候会将sql中的#{}替换成?号,调用PreparedStatement来赋值,Mybatis在处理${}的时候就是把${}替换成变量的值,调用Statement来赋值
使用 #{} 可以有效的防止SQL注入,但是使用${}不可以防止SQL注入。
什么是SQL注入
SQL 注入就是在用户输入的字符串中加入 SQL 语句,如果在设计不良的程序中忽略了检查,那么这些注入进去的 SQL 语句就会被数据库服务器误认为是正常的 SQL 语句而运行,攻击者就可以执行额外的命令或访问未被授权的数据。
举个例子
我们有一个简单的查询操作:根据id查询一个用户信息。
它的sql语句应该是这样:select * from user where id = 。
我们根据传入条件填入id进行查询。
如果正常操作,传入一个正常的id,比如说2,那么这条语句变成
select * from user where id =2。
这条语句是可以正常运行并且符合我们预期的。
但是如果传入的参数变成'' or 1=1,这时这条语句变成select * from user where id = '' or 1=1。
它会将我们用户表中所有的数据查询出来,显然这是一个大的错误。这就是SQL注入。
也就是可以恶意的拼接sql语句来达到查询所有的数据的目的
#{} 方式
#{}: 解析为SQL时,会将形参变量的值取出,并自动给其添加双引号。 例如:当实参username="Amy"时,传入下Mapper映射文件后
SQL将解析为:
SELECT * FROM user WHERE username="Amy"
${} 方式
${}: 解析为SQL时,将形参变量的值直接取出,直接拼接显示在SQL中
例如:当实参username="Amy"时,传入下Mapper映射文件后
SELECT * FROM user WHERE username=${value}
SQL将解析如下:
SELECT * FROM user WHERE username=Amy
mybaits怎么防止SQL注入?
这个问题其实就是问#{}是能够防止sql注入是什么原理?
#{}方式是先用占位符代替参数(sql中的#{}替换为?号)将SQL语句先进行预编译,最后再将参数中的内容替换进来。由于SQL语句已经被预编译过,其SQL注入将无法通过非法的参数内容实现更改其参数中的内容,无法变为SQL命令的一部分,故#{}可以防止SQL注入。${}之所以不能防止SQL注入是因为它是直接把那个传入的值拼接在sql语句后面,这个时候如果恶意拼装sql就可以实现sql注入。
说白了就是#{}会把sql语句中的参数部分用?代替进行预编译(这个时候由于没有具体的参数所以叫预编译),最后把参数替换那个问号进行真正的sql操作,然后这个时候sql语句就已经固定了,所以你后面传的参数哪怕恶意拼装成了一个sql样式也没用,因为sql已经固定了,你传的任何参数在它眼里只是一个字符串,而不会当做一个sql语句去执行
更加底层的讲解
MyBatis防止SQL注入的原理:MyBatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值 ,PreparedStatement在执行阶段只是把输入串作为数据处理,不再对sql语句进行解析,准备,因此也就避免了sql注入问题。
PreparedStatement防止SQL注入的原理:JDBC的PreparedStatement会将带'?'占位符的sql语句预先编译好,也就是SQL引擎会预先进行语法分析,产生语法树,生成执行计划。对于占位符输入的参数,无论是什么,都不会影响该SQL语句的语法结构了,因为语法分析已经完成了,即使你后面输入了这些sql命令,也不会被当成sql命令来执行了,只会被当做字符串字面值参数。所以的sql语句预编译可以防御SQL注入。而且在多次执行同一个SQL时,能够提高效率。原因是SQL已编译好,再次执行时无需再编译。
MyBatis Plus 框架
MyBatis-Plus 是什么 了解
MyBatis-Plus 是一个 Mybatis 增强版工具,在 MyBatis 上扩充了其他功能没有改变其基本功能,为了简化开发提高效率而存在
适用情况
1、对于只进行单表操作来说,mybatis-plus代码量比mybatis的代码量少很多,极大的提高了开发效率
2、对于多表操作来说,更推荐mybatis,因为mybatis-plus的方法比较难以理解,用起来不太方便,不如自己写sql语句的逻辑那么清晰明了
MyBatis-Plus 与 Mybatis 的区别 了解
MyBatis
1)所有SQL语句全部自己写
2)手动解析实体关系映射转换为MyBatis内部对象注入容器
3)不支持Lambda形式调用
Mybatis Plus
1)强大的条件构造器,满足各类使用需求
2)内置的Mapper,通用的Service,少量配置即可实现单表大部分CRUD操作,连SQL语句都不需要编写
3)支持Lambda形式调用
4)自动解析实体关系映射转换为MyBatis内部对象注入容器
总结
Mybatis Plus的宗旨是简化开发,但是它在提供方便的同时却容易造成代码层次混乱,我们可能会把大量数据逻辑写到service层甚至contoller层中,使代码难以阅读。凡事过犹不及,在使用Mybatis Plus时一定要做分析,不要将所有数据操作都交给Mybatis Plus去实现。毕竟Mybatis Plus只是Mybatis的增强工具,它并没有侵入Mybatis的原生功能,在使用Mybatis Plus的增强功能的同时,原生Mybatis的功能依然是可以正常使用的。
通用 CRUD 熟悉
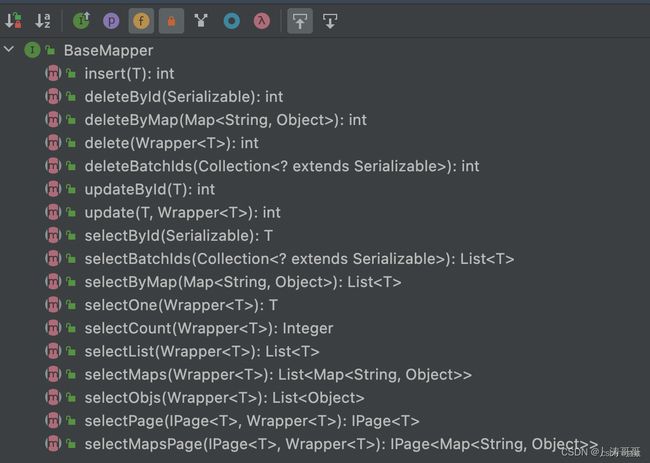
https://blog.csdn.net/LXZ_1024/article/details/123930130
https://blog.csdn.net/qq_37829947/article/details/125852116
配置 熟悉
https://blog.csdn.net/weixin_45525272/article/details/123694959
条件构造器 熟悉
https://blog.csdn.net/m0_63300795/article/details/126953915
https://blog.csdn.net/PIKapikaaaa/article/details/125628180
Sequence 主键 熟悉
https://blog.csdn.net/weixin_42220853/article/details/114585361
https://www.bookstack.cn/read/mybatis-plus-3.x/6139df349d82599b.md
分页插件 PageHelper 熟悉
https://blog.csdn.net/weixin_44720982/article/details/125152107
使用注意事项
多数源应用介绍 了解
数据库操作风险意识
数据操作风险意识 熟悉
sql 性能优化问题 了解
1, 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2,应尽量避免在 where 子句中对字段进行 null 值判断,创建表时NULL是默认值,但大多数时候应该使用NOT NULL,或者使用一个特殊的值,如0,-1作为默 认值。
3,应尽量避免在 where 子句中使用!=或<>操作符, MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE。
4,应尽量避免在 where 子句中使用 or 来连接条件, 否则将导致引擎放弃使用索引而进行全表扫描, 可以 使用UNION合并查询: select id from t where num=10 union all select id from t where num=20
5,in 和 not in 也要慎用,否则会导致全表扫描,对于连续的数值,能用 between 就不要用 in 了:Select id from t where num between 1 and 3
6,下面的查询也将导致全表扫描:select id from t where name like ‘%abc%’ 或者select id from t where name like ‘%abc’若要提高效率,可以考虑全文检索。而select id from t where name like ‘abc%’ 才用到索引
7, 如果在 where 子句中使用参数,也会导致全表扫描。
8,应尽量避免在 where 子句中对字段进行表达式操作,应尽量避免在where子句中对字段进行函数操作
9,很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b).用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)
10,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
11,应尽可能的避免更新 clustered 索引数据列, 因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
12,尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
13,尽可能的使用 varchar/nvarchar 代替 char/nchar , 因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
14,最好不要使用”“返回所有: select from t ,用具体的字段列表代替“”,不要返回用不到的任何字段。
15,尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
16,使用表的别名(Alias):当在SQL语句中连接多个表时,请使用表的别名并把别名前缀于每个Column上.这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
17,使用“临时表”暂存中间结果 简化SQL语句的重要方法就是采用临时表暂存中间结果,但是,临时表的好处远远不止这些,将临时结果暂存在临时表,后面的查询就在tempdb中了,这可以避免程序中多次扫描主表,也大大减少了程序执行中“共享锁”阻塞“更新锁”,减少了阻塞,提高了并发性能。
18,一些SQL查询语句应加上nolock,读、写是会相互阻塞的,为了提高并发性能,对于一些查询,可以加上nolock,这样读的时候可以允许写,但缺点是可能读到未提交的脏数据。使用 nolock有3条原则。查询的结果用于“插、删、改”的不能加nolock !查询的表属于频繁发生页分裂的,慎用nolock !使用临时表一样可以保存“数据前影”,起到类似Oracle的undo表空间的功能,能采用临时表提高并发性能的,不要用nolock 。
19,常见的简化规则如下:不要有超过5个以上的表连接(JOIN),考虑使用临时表或表变量存放中间结果。少用子查询,视图嵌套不要过深,一般视图嵌套不要超过2个为宜。
20,将需要查询的结果预先计算好放在表中,查询的时候再Select。这在SQL7.0以前是最重要的手段。例如医院的住院费计算。
21,用OR的字句可以分解成多个查询,并且通过UNION 连接多个查询。他们的速度只同是否使用索引有关,如果查询需要用到联合索引,用UNION all执行的效率更高.多个OR的字句没有用到索引,改写成UNION的形式再试图与索引匹配。一个关键的问题是否用到索引。
22,在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数。
23,尽量将数据的处理工作放在服务器上,减少网络的开销,如使用存储过程。存储过程是编译好、优化过、并且被组织到一个执行规划里、且存储在数据库中的SQL语句,是控制流语言的集合,速度当然快。反复执行的动态SQL,可以使用临时存储过程,该过程(临时表)被放在Tempdb中。
24,当服务器的内存够多时,配制线程数量 = 最大连接数+5,这样能发挥最大的效率;否则使用 配制线程数量<最大连接数启用SQL SERVER的线程池来解决,如果还是数量 = 最大连接数+5,严重的损害服务器的性能。
25,查询的关联同写的顺序 select a.personMemberID, * from chineseresume a,personmember b where personMemberID = b.referenceid and a.personMemberID = ‘JCNPRH39681’ (A = B ,B = ‘号码’) select a.personMemberID, * from chineseresume a,personmember b where a.personMemberID = b.referenceid and a.personMemberID = ‘JCNPRH39681’ and b.referenceid = ‘JCNPRH39681’ (A = B ,B = ‘号码’, A = ‘号码’) select a.personMemberID, * from chineseresume a,personmember b where b.referenceid = ‘JCNPRH39681’ and a.personMemberID = ‘JCNPRH39681’ (B = ‘号码’, A = ‘号码’)
26,尽量使用exists代替select count(1)来判断是否存在记录,count函数只有在统计表中所有行数时使用,而且count(1)比count()更有效率。
27,尽量使用“>=”,不要使用“>”。
28,索引的使用规范:索引的创建要与应用结合考虑,建议大的OLTP表不要超过6个索引;尽可能的使用索引字段作为查询条件,尤其是聚簇索引,必要时可以通过index index_name来强制指定索引;避免对大表查询时进行table scan,必要时考虑新建索引;在使用索引字段作为条件时,如果该索引是联合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用;要注意索引的维护,周期性重建索引,重新编译存储过程。
29,下列SQL条件语句中的列都建有恰当的索引,但执行速度却非常慢: SELECT * FROM record WHERE substrINg(card_no,1,4)=’5378’ (13秒) SELECT * FROM record WHERE amount/30< 1000 (11秒) SELECT * FROM record WHERE convert(char(10),date,112)=’19991201’ (10秒) 分析: WHERE子句中对列的任何操作结果都是在SQL运行时逐列计算得到的,因此它不得不进行表搜索,而没有使用该列上面的索引;如果这些结果在查询编译时就能得到,那么就可以被SQL优化器优化,使用索引,避免表搜索,因此将SQL重写成下面这样: SELECT * FROM record WHERE card_no like ‘5378%’ (< 1秒) SELECT * FROM record WHERE amount< 100030 (< 1秒) SELECT * FROM record WHERE date= ‘1999/12/01’ (< 1秒)
30,当有一批处理的插入或更新时,用批量插入或批量更新,绝不会一条条记录的去更新!
31,在所有的存储过程中,能够用SQL语句的,我绝不会用循环去实现! (例如:列出上个月的每一天,我会用connect by去递归查询一下,绝不会去用循环从上个月第一天到最后一天)
32,选择最有效率的表名顺序(只在基于规则的优化器中有效): oracle 的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表.
33,提高GROUP BY语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉.下面两个查询返回相同结果,但第二个明显就快了许多. 低效: SELECT JOB , AVG(SAL) FROM EMP GROUP BY JOB HAVING JOB =’PRESIDENT’ OR JOB =’MANAGER’ 高效: SELECT JOB , AVG(SAL) FROM EMP WHERE JOB =’PRESIDENT’ OR JOB =’MANAGER’ GROUP BY JOB
34,sql语句用大写,因为oracle 总是先解析sql语句,把小写的字母转换成大写的再执行。
35,别名的使用,别名是大型数据库的应用技巧,就是表名、列名在查询中以一个字母为别名,查询速度要比建连接表快1.5倍。
36,避免死锁,在你的存储过程和触发器中访问同一个表时总是以相同的顺序;事务应经可能地缩短,在一个事务中应尽可能减少涉及到的数据量;永远不要在事务中等待用户输入。
37,避免使用临时表,除非却有需要,否则应尽量避免使用临时表,相反,可以使用表变量代替;大多数时候(99%),表变量驻扎在内存中,因此速度比临时表更快,临时表驻扎在TempDb数据库中,因此临时表上的操作需要跨数据库通信,速度自然慢。
38,最好不要使用触发器,触发一个触发器,执行一个触发器事件本身就是一个耗费资源的过程;如果能够使用约束实现的,尽量不要使用触发器;不要为不同的触发事件(Insert,Update和Delete)使用相同的触发器;不要在触发器中使用事务型代码。
39,索引创建规则: 表的主键、外键必须有索引; 数据量超过300的表应该有索引; 经常与其他表进行连接的表,在连接字段上应该建立索引; 经常出现在Where子句中的字段,特别是大表的字段,应该建立索引; 索引应该建在选择性高的字段上; 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引; 复合索引的建立需要进行仔细分析,尽量考虑用单字段索引代替; 正确选择复合索引中的主列字段,一般是选择性较好的字段; 复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引; 如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引; 如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段; 如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引; 频繁进行数据操作的表,不要建立太多的索引; 删除无用的索引,避免对执行计划造成负面影响; 表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。 尽量不要对数据库中某个含有大量重复的值的字段建立索引。
40,mysql查询优化总结:使用慢查询日志去发现慢查询,使用执行计划去判断查询是否正常运行,总是去测试你的查询看看是否他们运行在最佳状态下。久而久之性能总会变化,避免在整个表上使用count(),它可能锁住整张表,使查询保持一致以便后续相似的查询可以使用查询缓存 ,在适当的情形下使用GROUP BY而不是DISTINCT,在WHERE, GROUP BY和ORDER BY子句中使用有索引的列,保持索引简单,不在多个索引中包含同一个列,有时候MySQL会使用错误的索引,对于这种情况使用USE INDEX,检查使用SQL_MODE=STRICT的问题,对于记录数小于5的索引字段,在UNION的时候使用LIMIT不是是用OR。 为了 避免在更新前SELECT,使用INSERT ON DUPLICATE KEY或者INSERT IGNORE ,不要用UPDATE去实现,不要使用 MAX,使用索引字段和ORDER BY子句,LIMIT M,N实际上可以减缓查询在某些情况下,有节制地使用,在WHERE子句中使用UNION代替子查询,在重新启动的MySQL,记得来温暖你的数据库,以确保您的数据在内存和查询速度快,考虑持久连接,而不是多个连接,以减少开销,基准查询,包括使用服务器上的负载,有时一个简单的查询可以影响其他查询,当负载增加您的服务器上,使用SHOW PROCESSLIST查看慢的和有问题的查询,在开发环境中产生的镜像数据中 测试的所有可疑的查询。
41,MySQL 备份过程: 从二级复制服务器上进行备份。在进行备份期间停止复制,以避免在数据依赖和外键约束上出现不一致。彻底停止MySQL,从数据库文件进行备份。 如果使用 MySQL dump进行备份,请同时备份二进制日志文件 – 确保复制没有中断。不要信任LVM 快照,这很可能产生数据不一致,将来会给你带来麻烦。为了更容易进行单表恢复,以表为单位导出数据 – 如果数据是与其他表隔离的。 当使用mysqldump时请使用 –opt。在备份之前检查和优化表。为了更快的进行导入,在导入时临时禁用外键约束。 为了更快的进行导入,在导入时临时禁用唯一性检测。在每一次备份后计算数据库,表以及索引的尺寸,以便更够监控数据尺寸的增长。 通过自动调度脚本监控复制实例的错误和延迟。定期执行备份。
42,查询缓冲并不自动处理空格,因此,在写SQL语句时,应尽量减少空格的使用,尤其是在SQL首和尾的空格(因为,查询缓冲并不自动截取首尾空格)。
43,member用mid做標準進行分表方便查询么?一般的业务需求中基本上都是以username为查询依据,正常应当是username做hash取模来分表吧。分表的话 mysql 的partition功能就是干这个的,对代码是透明的; 在代码层面去实现貌似是不合理的。
44,我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。
45,在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。 无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
46,MySQL查询可以启用高速查询缓存。这是提高数据库性能的有效Mysql优化方法之一。当同一个查询被执行多次时,从缓存中提取数据和直接从数据库中返回数据快很多。
47,EXPLAIN SELECT 查询用来跟踪查看效果 使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。
48,当只要一行数据时使用 LIMIT 1 当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
49,选择表合适存储引擎: myisam: 应用时以读和插入操作为主,只有少量的更新和删除,并且对事务的完整性,并发性要求不是很高的。 Innodb: 事务处理,以及并发条件下要求数据的一致性。除了插入和查询外,包括很多的更新和删除。(Innodb有效地降低删除和更新导致的锁定)。对于支持事务的InnoDB类型的表来说,影响速度的主要原因是AUTOCOMMIT默认设置是打开的,而且程序没有显式调用BEGIN 开始事务,导致每插入一条都自动提交,严重影响了速度。可以在执行sql前调用begin,多条sql形成一个事物(即使autocommit打开也可以),将大大提高性能。
50,优化表的数据类型,选择合适的数据类型: 原则:更小通常更好,简单就好,所有字段都得有默认值,尽量避免null。 例如:数据库表设计时候更小的占磁盘空间尽可能使用更小的整数类型.(mediumint就比int更合适) 比如时间字段:datetime和timestamp, datetime占用8个字节,而timestamp占用4个字节,只用了一半,而timestamp表示的范围是1970—2037适合做更新时间 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。 因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。例如, 在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间, 甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很好的完成任务了。同样的,如果可以的话, 我们应该使用MEDIUMINT而不是BIGIN来定义整型字段。 应该尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。 对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,ENUM类型被当作数值型数据来处理, 而数值型数据被处理起来的速度要比文本类型快得多。这样,我们又可以提高数据库的性能。
51, 字符串数据类型:char,varchar,text选择区别
52,任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。