NLP论文解读:EMNLP 2020 Experience Grounds Language
来源:投稿 作者:Sally can wait
编辑:学姐

自然语言处理、乃至于人工智能最终要去往何方?功成名就的AI大牛们依然不停止思考这样抽象而宏大的问题,并积极引领着学界的思考方向。这篇文章的作者里,有深度学习三巨头之一Bengio。他们所讨论的问题具有哲学意味,涉及对NLP整个学术历史的思考,和对NLP未来的展望,提出语言模型终将回归物理世界和具身体验。有趣的是,这篇论文发表两年了,NLP还是没有发生划时代的突破。上次可以称得上划时代的突破还是2018年的BERT问世。我们正处在瓶颈期,是否是浪潮来临之间的平静还未可知。
尽管如今的语言模型在很多NLP任务上超过了人类,但是AI仍然缺乏对物理世界的具身经验以及社会交际中察觉语境的能力。人类语言中“意义”的产生,来源于我们共享着一套不言自明的的世界经验。作者认为,机器人所使用的“语言”,也应当从世界经验和社会交际中产生,并作用于世界,而不仅仅是从大量互联网文本的分布中获得一些反映共现信息的表示。为了阐述NLP的过去、现在和未来,作者归纳了NLP发展过程中的5个阶段,将它们概括为五个“世界视野”(world scope):
-
WS1: 语料库
-
WS2: 互联网
-
WS3: 多模态
-
WS4: 具身认知
-
WS5: 社会交际
最后作者提出了对NLP未来发展的展望。我们将跟随这五个“世界视野”,梳理NLP发展史的来龙去脉。
世界视野1:语料库
语料库是数据驱动的语言研究“梦开始的地方”。 此处的语料库,早期指的是专家语料库,即经过语言学家分析、加工和标注的语言资源,比如宾州树库;
图1:宾州树库示例
后来这个概念扩展到了一切人类在网络上留下的自然语言的集合。在70-90年代,NLP的研究热点在于有监督地让机器学习到语言使用中的句法规则。90年代后,“表示学习”作为一种NLP的学习范式被搬上了历史舞台。
表示学习(Representation Learning)是一种学习数据表示的技术,用于将现实世界中的数据转化成能够被计算机高效处理的形式。 早期表示学习的例子:
1.Brown基于互信息的层次聚类算法
2.鲍姆-韦尔奇算法+ HMM (一种参数逼近的方法,本质上是EM,但比EM早很多)
3.LDA算法,把文档看成“词袋 bag of words”,用矩阵编码词语的共现信息,用矩阵分解的方法压缩embedding的维度,来获得文章的表示。词袋模型这种基于计数的语言学特征抽取方法,缺点在于无法编码词语的前后顺序,潜藏在语法结构关系中的信息则会丢失。
受到Firth(1957)著名的分布式理论“观其伴知其义 You shall know a word by the company it keeps.”的启发,研究者致力于统计文本的上下文信息,以实现对文本的表示。比如著名的LDA算法,把文档看成“词袋 bag of words”,用矩阵编码词语的共现信息,用矩阵分解的方法压缩embedding的维度,来获得文章的表示。词袋模型的缺点在于无法编码词语的前后顺序,因此潜藏在语法结构关系中的信息则会丢失。在语料库阶段,尽管专家已经开始致力于基于统计的词表示方法,但是受到语料规模和算力的限制,模型的参数规模较小,对文本的表示仅能捕捉到浅层的共现特征。
世界视野2:互联网
这也是我们现在所处于的发展阶段。随着90年代后互联网上信息的爆炸式增长以及爬虫技术的广泛使用,NLP研究视野一下子被拓宽了。如今的NLP研究者使用海量的互联网数据无监督地训练语言模型,使得模型学习到词语之间的关系,并编码到向量中。尽管训练语料和参数规模指数级地扩大了,如今基于互联网数据的NLP研究仍然遵循着Firth的分布式假说,无论学习任务、目标函数如何推陈出新,语言模型的任务始终是根据上下文信息优化词语的表示。
世界视野2的关键技术是迁移学习。有赖于迁移学习的“预训练+微调”的范式,我们让语言模型从海量的多领域文本中学会“一般地说话”,然后再在目标领域的文本中学会“专业地说话”。这是历史性的进步,也直接让见多识广的NLP模型在很多任务上直逼甚至超过了人类的水平。

图2:来源于论文Language Models are Few-Shot Learners
但是基于互联网数据的语言模型也逐渐遇到了边际效益递减的瓶颈:尽管模型的训练数据和参数量依然在增大,但是收益率逐渐下降。大模型在一些交互性较强的NLP任务上(如LAMBDA意图识别任务)无法匹敌人类水平。人们发现,基于海量互联网数据训练而成的语言模型,仍然无法捕捉一些世界事实的知识(比如事物的相对大小关系)并进行合理的推理,这导致在长尾数据上泛化性能较差。
世界视野3:多模态
就像人类学习语言一样,机器学习语言也需要视觉信号、声音信号,这样才能对一些长尾分布的事实做出正确的推理,比如“猫会无声地落地”。有些共识是不会用语言记录下来的,比如物体之间的相对大小、物体的重量、质地等。这样的信息在互联网上海量的文本中,分布依然是稀疏的。
图3 Imagenet
而现如今,计算机视觉已经能够区分1000个类别的物体(ImageNet),而且这些CV领域的图像分类模型已经拥有了一些事实推理能力。既然语言不能反映真实世界,那么不妨加上视觉信息。无论是语言序列,还是图像,都统一地遵循向量的数学形式和运算法则,因此将二者结合起来是很自然且可行的选择。自2018年后,多模态模型就如雨后春笋一般涌现。加上了视觉信息,模型就更有把握地基于真实情况回答“这辆货车能否通过这条隧道?”这样的问题,而不仅仅是返回一个由语料库词共现计算出来的结果。
尽管如此,多模态也有它的局限性:AI依然独立于真实世界之外,它的“教材”是二手资料,而不是像牙牙学语的婴儿那样整天在触摸各种各样的物品、与世界交互。对于全新的问题,没有很好的泛化性。
世界视野4:具身认知
当模型打通了语言和行为的界限,它就更接近“具身认知”模型了。这不仅体现在从行为中学习语言,也体现在将语言转化为外显的行为,来塑造外部世界。在人类掌握语言之前,就在和外界的互动中习得了很多常识,这些常识也是不会记录在语言中的。比如鸡蛋应当轻拿轻放,而球类则无需。这些知识很难从大规模的互联网信息中获取(哪怕是多模态,也缺乏物理感知,研究表明儿童在把ipad上获取的2d信息和3d世界联系起来的过程中遇到了困难),而需要AI与物理世界进行实际的交互。
作者以一个自然语言问题“橘子更像棒球还是香蕉?”具体讨论了前面说到的4个世界视野。世界视野1可能无法给出答案,因为这些词语在语句中的语法角色都是名词,并且语义角色都是能被人拿住的受事。世界视野2可能拥有“棒球”和“橘子”都是球状的,但是没有它们质地、相对大小、使其变形所需要的力方面的知识。世界视野3可能可以认识到这些物品可能的形态变化(如香蕉、橘子可以剥皮,棒球可以压扁),但是不知道实现形变需要施加多大的力。世界视野4可以觉察到事物之间的细微区别,比如橘子和棒球可以用差不多的力抓取,因为它们表面差不多粗糙、重量差不多;橘子和香蕉都可以剥皮、都是可食用的,这才更像人类的推理过程:从一些词语激发更多的相关的联想。
但是,当前若要把自然语言作为机器人行为的指导,还面临着一些障碍。目前,基于互联网数据训练得到的语言表示,在编码精细的机器人动作上捉襟见肘。比如“把爪子向右移动10cm”这样的句子在互联网上的分布稀疏,语言模型较难在这些句子上提供很好的表示。简而言之,语言作为影响和改变物理世界的“功能”还未实现。
WS5: 社会交际
语言最基本的功能是社会交际。尽管物理世界给符号赋予了意义,但语言的实际含义存在于动态的使用之中。社会交际因素在语言学习和使用中扮演重要的角色。语言学一大颇具影响力的流派:系统功能语言学,认为功能才是是意义的来源。
从世界视野1到4的发展过程中,“语言”从仅仅作为数据源逐渐变成了事件的起因。这也是语言学习者的最终目标:产出对外部世界产生影响的语言。这也呼应了语言作为功能的基本要求。
然而当前的问题是,对于开放数据的获取和标注面临着很多难点,AI局限于训练集-测试集的研究范式,最常用的交叉熵损失函数会忽视对长尾分布的处理,这有可能导致信息茧房。目前,让用户和机器自由地交互学习是一个可行的方法,人类在与机器的交互中,不断地扩展机器的决策边界和世界常识,然而这只是一个方面。
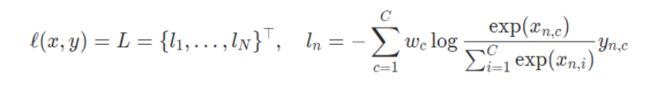
图4:交叉熵损失函数,其中x是输入,y是目标标签,w是类别权重,C是类别数量,N是维度
那么,设想中的语言模型该如何突破这信息茧房?参考人类的语言的使用情境,如果将它迁移到机器的语言学习上,它们可以帮助我们突破目前互联网语料的局限:
-
二语习得 当你去国外的时候,借助于共通的世界模型,我们可以通过指某个物体或者表达饥饿这样共通的感受来表达我们的意思。目前,机器可以先借助图像的桥梁,然后经过模拟,最后到达真实世界。
-
同指和词义消歧 如果我们的模型不只是利用词共现信息,而是能对使用者的愿望和经历进行建模,或许可以更好地实现同指和多义词消歧这两个困难的NLP任务。
-
新词学习 一个物体可以从语言和动作两个方面进行描述(比如弹吉他),如果能让机器学习到这种关联,可以用来解决现在模型中棘手的隐喻问题。
-
客制化的对话 社交知识的学习依赖于对语言具体使用情景的理解。(对个人一个学习很痛苦但成绩不好的人来说,叫他“再努力一点”,可能是对他的伤害,但对另一个人来说这句话可能是鼓励。)
尾声
这篇论文给我的最大收获是,让我体会到站在学术前沿的科学家是如何思考问题的。在对目前手头的领域精耕细作的同时,也需要同时具备更宏大的学术视野,思考一些前沿的问题。并同时参考多个人的观点,有一个自己的判断。
前段时间,也看到另一位大牛LeCun的关于Human-level AI的言论,他也坚定地认为纯粹的大模型并非出路,而需要一种「Macro Architecture」(宏观框架)来完成对下一代AI的探索,通过借鉴动物大脑,构建AI的 “心识框架”。这都是学界前沿对现状的不满和对出路的探索,而和这篇文章又有一些不谋而合之处。
关注下方《学姐带你玩AI》
回复“500”获取论文资料合集⬇⬇⬇
220+篇下载好的论文PDF(包含CV/NLP/RL等细分方向)
码字不易,欢迎大家点赞评论收藏!