HashSet底层原理,为什么要重写hashCode()和equals(),重写equals()为什么一定要重写hashCode()
文章目录
- 前言
- 一、重写hashCode()和equal()小测试
-
- (1)未重写hashCode()和equal()
- (2)重写hashCode()和equal()
- 二、重写equals()为什么一定要重写hashCode()?
- 三、总结
前言
在写文章之前我阅读了这篇博客https://blog.csdn.net/qq_35868412/article/details/89380409
关于hashCode和equals方面介绍的很清晰,也很官方。但接下来的内容是我个人针对hashCode()、equals()这两个方法并结合HashSet底层源码进行的分析。
=====================
重写hashCode()和equals()相信有不少小伙伴是在学HashMap或HashSet中接触到的,下面这篇文章彻底带你搞懂这两个方法的作用
一、重写hashCode()和equal()小测试
(1)未重写hashCode()和equal()
首先来看下面这段代码,你们认为hashset集合的大小size()是多少?是1还是2?
public class Text {
public static void main(String[] args) {
HashSet<Object> hashSet = new HashSet<>();
people people1= new people("张三");
people people2= new people("张三");
hashSet.add(people1);
hashSet.add(people2);
System.out.println(hashSet.size());
}
}
class people{
public String name;
public people(String name) {
this.name = name;
}
}
先来揭晓答案:2
有些人已经猜出来了,因为我们都知道HashSet集合的一个特点,那就是不允许集合中有重复值,而上面代码中people1和people2作为值并不是同一个对象(哪怕它们的属性一样),这两个引用都是存储在栈中,分别指向堆中不同的两个People实例,相信大家都知道。所以这里HashSet不会将它们作为相同值而去重。
不信的话我们先输出这两个对象的hashcode值。
System.out.println("people1的hashCode:"+people1.hashCode());
System.out.println("people2的hashCode:"+people2.hashCode());
结果:
people1的hashCode:1360875712
people2的hashCode:1625635731
很明显不一样,hashCode不同说明并不是同一个对象。
接下里再结合源码验证上面所述,首先我们追踪people2是怎么添加进hashset集合中发生了什么。

图中看出,HashSet.add()底层实际上调用了HashMap.put(),和HashMap不同的是,HashSet仅存储对象,HashMap存储键值对。那HashSet底层调用put时不也是有key和value的吗。其实这里的key就是person2对象,value是一个叫PRESENT的东西,这里就不展开讲PRESENT是什么,它涉及到判断add和remove返回值问题。
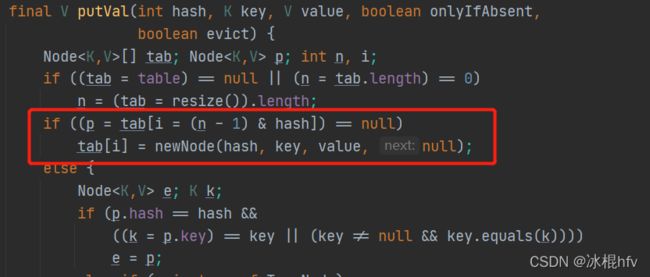
继续看putVal()方法。只挑核心部分
程序运行到这个地方,说明存放元素映射到桶中索引处没有元素,那么直接创建一个新节点

查看一下当前数组中存放的对象个数 ---- 两个对象

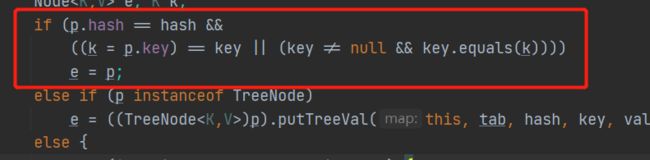
当然这是不发生hash冲突的情况,如果发送了hash冲突呢?就会经过这段代码

但这段代码是不会返回true的,hash值是经过高低十六位异或运算的,哪怕有极小的概率相同,那么接下来的判断p.key==key是否相等也是不成立的,因为是person1和person2是两个不同的对象。好了关键来了,后面的equals方法判断会不会是true呢?不可能。因为Object对象中的equals()在没重写之前,它就是判断两个对象的内存地址是否是相同的(对引用类型,==判断内存地址)。

总结:以上就是为什么size()为2的原因,因为存储对象不同,所以哪怕对象的属性(名称)相同,也不作为同一种元素,因此不会当做重复处理。
那么问题来了,实际业务中,我们是希望person1和person2是同一个对象的,因为他们的名称都相同代表同一个人,现在我想让HashSet集合中只存放一个元素,能实现吗?
(2)重写hashCode()和equal()
看下接下来的代码↓
public class Text {
public static void main(String[] args) {
HashSet<Object> hashSet = new HashSet<>();
people people1= new people("1001","张三");
people people2= new people("1001","张三");
System.out.println("people1的hashCode:"+people1.hashCode());
System.out.println("people2的hashCode:"+people2.hashCode());
hashSet.add(people1);
hashSet.add(people2);
System.out.println(hashSet.size());
}
}
class people{
public String id;
public String name;
public people(String id, String name) {
this.id = id;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
people people = (people) o;
return Objects.equals(id, people.id) && Objects.equals(name, people.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}
我对People增加了id属性,并重写了hashCode()和equals()方法。运行结果如下:

结果显示,people1和people2的hashCode是相同的,并且size()大小也是1。为什么?它们两个不是两个不同的对象吗,为什么hashCode会相同?这是因为原先的Object中的hashCode()方法是一个本地方法,它是为了给每个对象生成一个唯一的标识符。但是我经过重写hashCode()后,生成的hashCode值是按照People的id和name属性生成的,为了验证得到的hashCode相同,我们还需要看一下hash()计算的底层实现。
return Objects.hash(id, name);
先调用了Object.hash(),参数就是id、name。但底层实际上是调用了Array.hashCode()
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
看看Array.hashCode()
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
返回值是result,那么这段代码就是关键了----> result = 31 * result + (element == null ? 0 : element.hashCode());
这里又调用了一个hashCode方法,element.hashCode(),继续往下看
element.hashCode()
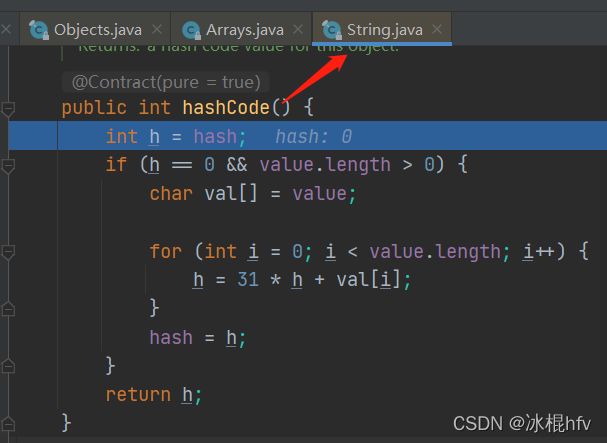
很明显答案出来了,最终还是调用的是String.hashCode()方法。其中hash表示该串的哈希值,在第一次调用hashCode方法时,字符串的哈希值被计算并且赋值给hash字段,之后再调用hashCode方法便可以直接取hash字段返回。

它是缓存字符串的哈希码,也就是说,相同字符串因为这个缓存机制,都能获取到同样的hash值。所以就算people1和people2不是同一个对象,经过重写hashCode()后,因为它们的属性都是相同的,而字符串内容一样的String对象,调用String.hashCode()返回值也是一样的,所以最终得到的hashCode也是相同的。
因为hashCode都是相同的,那么add的时候,经过hash计算,元素映射到数组的索引位置也是相同的,在运行到这一段代码的时候

hash值相同,直接将p(people1)节点赋值给e(people2),这是为了接下来的value覆盖。

直接覆盖了原先位置上的值,当然这个值是前面提到的PRESENT,实际上存储的对象并没有被覆盖。
查看此时数组table中的元素个数(1,还是原来的对象即people1)

总结:以上就是为什么size为1的原因,因为people1和people2的hashCode相同,所以并不会新增加一个元素,而只会进行vlaue的覆盖,不影响HashSet里面存储的对象。
二、重写equals()为什么一定要重写hashCode()?
个人理解:比如在HashSet中,因为只重写equals()的话,hashCode()依旧是调用Object.hashCode(),也就是说不同的对象生产的hashCode不同且唯一,那么就必然会新建一个节点。举个例子(只重写了equals时,且只进行两次元素添加)
第二次元素添加,当没有发生hash冲突的时候,存进来的元素就会作为一个新的节点。
如果发送了hash冲突(意味着桶处已有值),那么就会进行下面这段代码进行判断,由于没有重写hashCode(),那么不同对象的hashCode必然不同,&&具有短路性,这里if直接跳过
于是就会执行下面这段代码,拉链法,还是会创建一个新的节点。
总结:所以这跟之前的size为2的例子是一样的,hashCode不同,代表对象不同,所以存储不会影响。但是在业务逻辑中就有问题了,people people1= new people(“1001”,“张三”);和people people1= new people(“1001”,“张三”);我希望的是只存储一个,那就必须要重写hashCode才行,重写之后才能保证它们逻辑上是同一个对象,这样才能符合业务逻辑。
三、总结
- 未重写hashCode和equals时,HashSet底层add()方法实际上是调用了HashMap的put()方法,当hashCode相同并且equals为true的时候,会进行覆盖value(PRESENT),但不影响对象的存储,对象并没有被覆盖,保证为Set的唯一性。
- 重写了equals但没重写hashCode时,结果判断对象相等,但其hashCode却不一致。当使用hash集合类时,存放时会根据该类的hashcode方法,来确定其存放位置,如hashset,将无法过滤业务逻辑上相同的对象,因为不重写hashcode,会默认调用Object类的hashcode方法,计算出来的存放地址不一样,会导致能同时存放两个值相等的对象,产生混淆。
以上内容大部分基于个人研究,如果有错误还请指正!