用4+1架构视图说说Flink架构
友情提示,本文11239字,预计阅读时间25分钟。
在实时流计算的江湖里,Flink 大有一统江湖的味道,其正处于如日中天的高光时刻。溯古论今,Flink 起源于德国柏林大学2010年的一个研究项目,2014年到 Apache 舞台露了个脸,2019年被阿里巴巴收购后开始走上人生巅峰,收获一众粉丝,名气越来越大,在实时流计算的地位越来越高,截止本文写作时间,最新版本为1.14.4,功能越来越多,操作越来越简单,生态越来越多样化。九层楼台,起于垒土,千里之行始于足下,万变不离其宗,一切的迭代都是基于设计好的脚手架去不断的夯实各种能力,唯有良好的架构地基,才能支撑起 Flink 想要构建高耸如云的摩天大楼的梦想。以此为初心,本文想要聊聊 Flink 的架构,从架构的视角说道说道 Flink 是什么,现在在哪里,未来要去哪里,怎么去,全文将会按照逻辑架构、数据架构、开发架构、部署架构、运行架构展开。
请各位看官思考以下几个问题:
(1)如果是你来对 Flink 进行架构设计,你会怎么做?
(2)你会选什么样的理基础作为 Flink 的理论依据?
PS: 以下问题可以从“从马斯洛需求层次理论”思考,可以练习一下和马老师来一次对话,也许会发现不一样的视角。
(3)Flink 如果能大一统流式实时计算的江湖,对开发人员会带来什么伤害?
(4)你将 Flink 引入自己公司技术栈后,会给公司带来什么好处和坏处?
PS:以下问题可以从架构战略意图思考。
(5)使用 Flink 会最大化的降低你们公司研发成本吗?会带来多少的商业价值?
(6)你认为 Flink 最正确的唯一的架构目标是什么?
带着这些问题,我们上路吧。
Flink 的理论基石包括:时间、窗口、状态、检查点。分布式快照,感兴趣的看官可以读我公众号另外一篇文章:分布式快照:确定分布式系统的全局状态赏析。
一、核心概念
(1)Streams(流式计算,无界流,有界流)
流包括有界流和无界流。有界流等价于批,有界流的计算能覆盖传统的离线数仓的计算;无界流说的是数据源源不断的产生,根本停不下来,无界流的计算覆盖了实时计算。无界流的计算和有界流的计算合起来,就是批流融合,流批一体。从理论角度来看,Flink 的设计者从上帝视角抽象了数据的分类,将物理世界的数据建模后,镜像到数字世界就是无界流和有界流模型。各位看官,我们是不是可以说 Flink 起于建模?
(2)Window(窗口)
为了对有界流和无界流进行更好的计算,Flink 的设计者抽象出了 Window 的窗口模型,主要包括三种窗口类型:计数窗口、时间窗口、会话窗口。具体可以查阅笔者:Flink窗口原理与机制|清风。
(3)State(状态计算)
应用程序 State 是 Flink 的一等公民,只有单个事件应用转换的应用程序不需要 State ,其他的情况都需要,否则计算结果就不准确。Flink State 的特点有:多状态原语(如原子操作,list,map)、可插拔状态后端(如RocksDB)、精确一次状态一致性(利用检查点和恢复算法)、超大状态(TB 级应用程序状态)、可扩展应用程序(如应用程序状态分发到其他工作节点)。
(4)Checkpoint(检查点)
检查点是 Flink 实现容错的核心理论,包括流重放和状态检查,提供的是一种轻量级的分布式快照。检查点的核心是Stream Barriers,数据流入 Flink 时,Flink 会向数据流插入 Barrier,Barrier 不会超过记录的数据,只会默默的跟随,Flink 借助 Barrier 插入检查点,犹如一个摄影师给模特拍照一样,总是在最需要的时刻给模特排出一张张美照。拍照的过程如图所示:

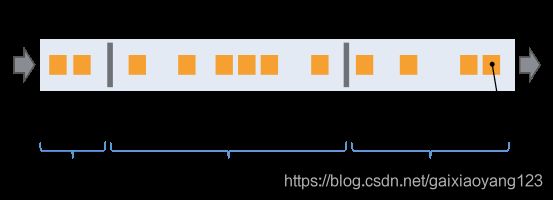
(5)Time(时间)
Flink 设计者对时间做了如下定义:
event-time:事件发生时间,最准确记录数据携带的事件是什么时候发生的;
process-time:事件处理时间;
ingest-time:时间摄入时间,从数据流入 Flink source 开始算。
和时间相关的特性主要有 Watermark(水印)、Late Data Handling(迟到数据处理),后续文章会做专门的介绍。
(6)Layered APIs(分层接口)
最上层为 SQL/Table API,实现了流批的统一,往下一层是 DataStream API,再往下一层是 ProcessFunction。越往上越简单,学习成本越低,越往下越复杂,灵活性越高,学习成本越低。可以认为 SQL/Table API 是水果刀,DataStream API 是厨房常用菜刀,ProcessFunction 是牛刀,如果前面两把刀满足不了业务需求,就可以用 ProcessFunction 自定义开发。接口分层如下图所示:
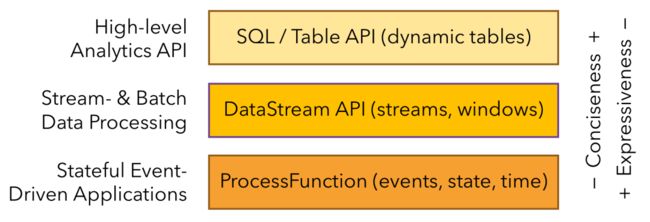
不同层级的 API 的使用技巧在笔者接下来的文章里将会为各位看官们一一道来。
二、逻辑架构视角说 Flink
Flink 逻辑架构图如下图所示
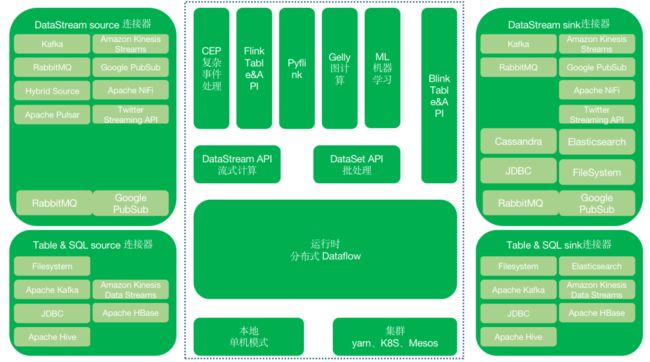
DataStream 内置支持的 source 连接器有files,、directories,、sockets、collections 、iterators。
DataStream 内置支持的 sink 连接器有files,、directories,、sockets、collections 、iterators。
用于DataStream 的 source 捆绑式连接器有:Kafka、Amazon Kinesis Streams、RabbitMQ、Google PubSub、Hybrid Source、Apache NiFi、Apache Pulsar、Twitter Streaming API。
用于DataStream 的 sink 捆绑式连接器有:Kafka、Apache Cassandra、Amazon Kinesis Streams、RabbitMQ、Google PubSub、 Apache NiFi、JDBC。
基于Apache Bahir 实现的 source 连接器有:Apache ActiveMQ、Netty。
基于Apache Bahir 实现的 sink 连接器有:Apache ActiveMQ、Apache Flume、Redis、Akka。
另外,在 map 和 flatMap 操作中,Flink 也提供异步 IO 接口实现从外部数据库或外部服务查询数据。
用于 Table & SQL 的 source 连接器有:Filesystem、Apache Kafka、Amazon Kinesis Data Streams、JDBC、Apache HBase、Apache Hive。
用于 Table & SQL 的 sink 连接器有:Filesystem、Elasticsearch、Apache Kafka、Amazon Kinesis Data Streams、JDBC、Apache HBase、Apache Hive。
(1)Table&SQL
Table & SQL 是 Flink 提供的高级 API 接口,基于 Apache Calcite 实现 SQL,开发人员既可以使用 Scala 也可以使用 Java ,支持 Table API 和 SQL 混合编码。Table API 因为是使用 Scala 或 Java 编码,开发人员能够获得更大的灵活度用于处理一些 SQL 无法处理的业务场景。开发示例如下图:


(2)CEP
Flink CEP 支持通过SQL定义复杂事件处理匹配规则。那什么是 CEP 呢?是一种复杂事件处理的模式匹配技术,通过分析事件间的关系,利用过滤、关联、聚合等技术,根据事件间的时序关系和聚合关系制定匹配规则,持续地从事件流中匹配出符合要求的事件序列,通过模式组合能够识别更加复杂的事件序列,主要用于反欺诈、风控、营销决策、网络安全分析等场景。
(3)Gelly
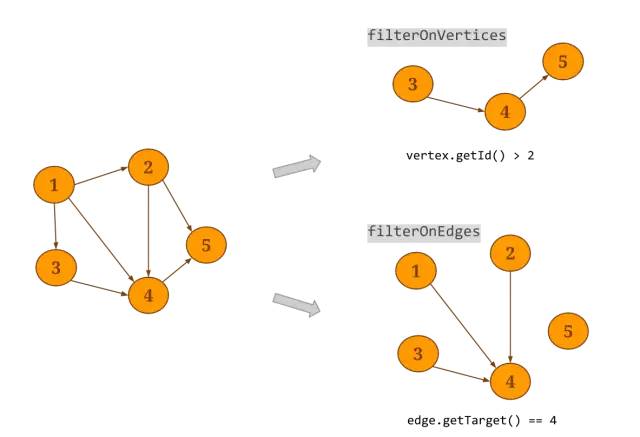
Flink Gelly 是一个可扩展的图形处理和分析库。Gelly 是在DataSet API 之上实现的,并与DataSet API集成在一起。Gelly提供了创建、转换和修改图的方法,以及图算法库。下图为一个 Gelly 生成的图示例:
(4)ML
Flink ML是Flink的机器学习框架,定位类似于Spark MLLib,截止本文写作时,最新版本为Apache Flink ML 2.0.0,维护的仓库已经迁移到 apache-flink-ml,其中,分类模型支持 KNN (最邻近规则分类)、逻辑回归、朴素贝叶斯。聚类模型支持 kmeans 。其他如热编码算法。
(5)PyFlink
PyFlink 是 Flink 提供的使用 Python 语言开发的 API ,例如实时数据处理管道、大规模探索性数据分析、机器学习(ML)管道和ETL流程都可以使用 PyFlink 来实现,这对于熟悉 Python 开发人员来讲,进一步降低了学习 Flink 的开发门槛,另外可以巧妙的借力 Python 丰富的生态,如 Pandas等 Python 框架。最新版本的 Flink 使用的 Python 版本为3。
三、数据架构视角说 Flink
有状态数据的计算流程如下图所示:
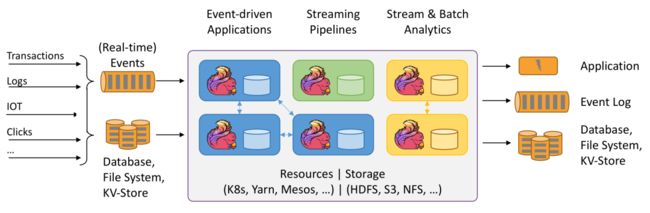
Flink 对于数据的抽象建模包括有界流和无界流。
无界数据流有一个开始但没有定义结束,数据流需要持续地被处理,当应用程序关注的事件发生时,需要适时的处理,并且要求事件按照某个规则有序,同时无界数据流不可能等到把所有的数据都装载完成再统一处理。
有界数据流有一个明确的开始点和明确的结束点,可以等到所有数据都装载完成后再开始计算,不需要按照某种规则排序,因为如果想排序的话可以等到所有数据都装载完成后用排序算法进行排序。有界数据流就是我们常说的批处理。
有界数据流和无界数据流示意图
笔者认为,从数据视角来看最重要的架构对象是 State(状态),Flink 对 State 数据处理的数据流示意图如下图所示:
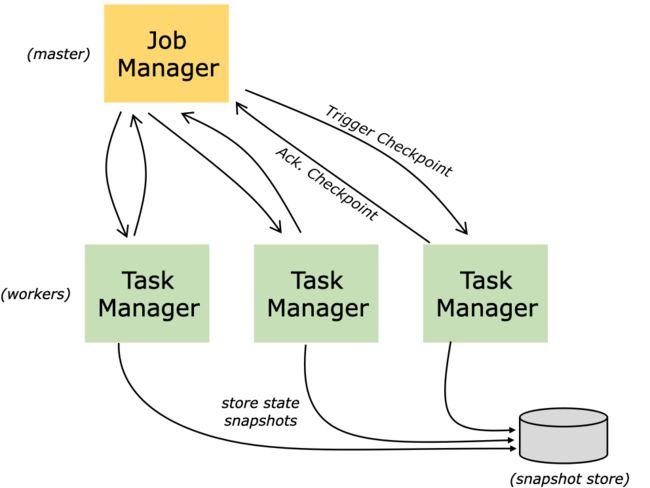
JobManager 触发一个检查点,TaskManager 收到保存 State 安排时,就会将 State 保存到内存/ RocksDB/FsStateBackend,具体使用何种持久化方式,可以在 flink-conf.yaml 中配置。
数据处理的编程模型就是Source-Transform-Sink,具体可以参考下图:
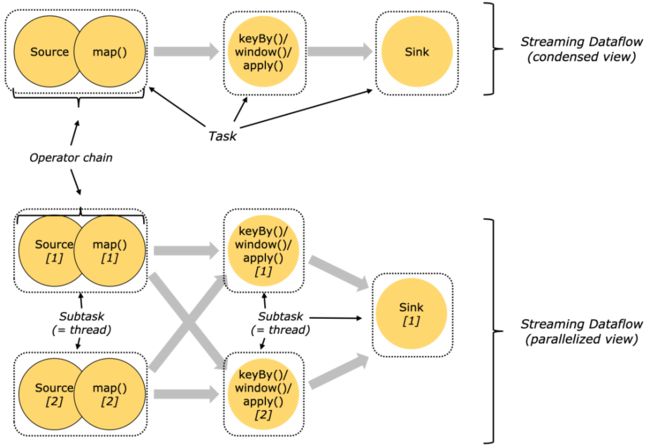

在上图中,数据的流向遵循一个 Source 对应一个 sink,也可以是多个 Source对应一个 sink。还有一种情况是一个 Source,多个 sink ,譬如把一份数据 sink 到 Hbase,一份数据 sink 到 kafka,需要用到的关键技术就是 SideOutput。
四、开发架构视角说 Flink
Flink源代码的目录主体结构图

(1)Flink主体模块
和上图的序号对应起来:
1)flink-annotations:包括定义文档方面的注解,以及类、方法使用范围的注解。
3)flink-clients:提供本地模式和Standalone模式的启动方式的提交实现,并提供其他模式的启动接口;提供作业的编译、提交以及对已运行作业进行查看等功能。
7)flink-core:提供通用的API、通用的工具包、各种配置相关的实现、各种数据类型及解析;提供核心文件系统的抽象接口和通用方法,以及内存管理部分和Flink I/O部分的接口。
8)flink-dist:提供Flink构建打包的配置和相关脚本。
18)flink-java:提供Flink批处理DataSet的Java API。
22)flink-metrics:提供Flink Metric注册的核心实现以及各种Metric Reporter。
23)flink-optimizer:主要提供编译作业,生成优化后的执行计划(Plan)。
24)flink-python:提供Flink Python的运行支持,以及Python DataStream、DataSet和Table API。flink-queryable-state:提供查询状态的Client API和查询状态的服务。
28)flink-runtime:提供运行时各个通信组件的实现、数据传输、HA服务、blob服务、检查点等。
29)flink-runtime-web:Flink Web 部分,提供外部的REST API 及 Web UI。
30)flink-scala:提供Flink批处理 DataSet 的 Scala API。
31)flink-state-backends:在 flink-state-backends 中只有 RocksDB backend(RocksDB 后端处理组件)的实现模块,filebackend(文件后端处理组件)、memory backend(内存状态后端处理组件)等其他状态后端处理组件的实现都在 flink-runtime 模块中。
32)flink-streaming-java:提供 Flink 流处理 DataStream的 JavaAPI。
33)flink-streaming-scala:提供 Flink 流处理 DataStream的 Scala API。
34)flink-table:提供Flink Table的 Java API、Scala API、SQL 解析、SQL 客户端以及关于 Table 的运行时。
(2)Flink部署模块
和上图的序号对应起来:
5)flink-container:提供构建Flink镜像的 Docker 配置和 Flink on Kubernetes 的相关YAML的模板
(如taskmanager.deployments.yaml.template)。
20)flink-kubernetes:提供 Flink On Kubernetes 的部署支持。
38)flink-yarn:Flink on YARN 的部署模式的启动和集群的管理。
(3)Flink测试模块
和上图的序号对应起来:
2)flink-architecture-tests:使用 ArchUnit 对 Flink 架构的测试。
12)flink-end-to-end-tests:Flink端到端的测试。
16)flink-fs-tests:Flink文件系统的测试。
19)flink-jepsen:基于Jepsen的测试,通过模拟异常来验证Flink引擎的健壮性。
35)flink-test-utils-parent:Flink测试的一些基本工具类。
36)flink-tests:Flink重要模块的集成测试。
39)flink-yarn-tests:Flink on YARN 的集成测试。
(4)Flink其他模块
和上图的序号对应起来:
4)flink-connectors:多种 Flink connector 的实现和 API。
6)flink-contrib:提供 Docker 启动 Flink 的方式和 Wikipedia 的 connector。
9)flink-dist-scala:使用协议。
10)flink-docs:Flink文档的生成方式的实现。
11)flink-dstl:FsState 的 change log。
13)flink-examples:一些 Flink 的应用实例。
14)flink-filesystems:Flink 对 HDFS、S3、Azure 等多种文件系统的支持和实现。
15)flink-formats:Flink 对 Avro、Parquet、CSV、JSON 等格式的支持。
17)flink-external-resources:外部资源的发现,如 NVIDIA GPU。
21)flink-libraries:CEP、Gelly 的实现,Scala、Java API 和状态操作的 API。
25)flink-queryable-state:提供 Flink 从外部系统查询 Flink 作业内部 State 的能力,在一些要给外部开放状态查询的场景可以使用这个模块特性。
26)flink-quickstart:两个分别使用 Scala 和 Java 实现的完整 Flink 应用实例。对应官网 quick start 的应用源代码。
27)flink-rpc:提供 akka RPC ,抽象了 RPC 相关接口,如RpcService,RpcServer 等。
37)flink-walkthroughs:支持欺诈检测,检测的业务逻辑封装在 FraudDetector。
40)licenses:一些协议文件,如LICENSE.anchorjs、LICENSE.chroma、LICENSE.cloudpickle、LICENSE.font-awesome、LICENSE.py4j。
41)tools:支持Shade、CheckStyle、Releasing 等项目代码管理的工具。
42)docs:可以使用 Hugo 编译 Flink 文档。
DataStream 程序结构
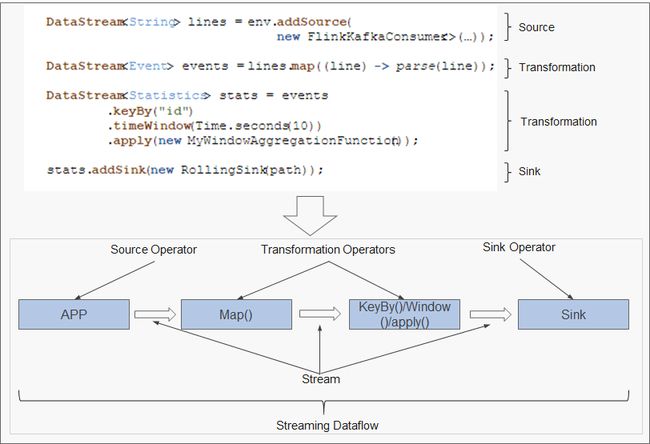
Table & SQL 程序结构
五、部署架构视角说 Flink
Flink支持多种部署模式:
1)Standalone 模式:Flink安装在普通的 Linux 机器上,或者安装在 K8S 中,集群的资源由Flink自行管理。
2)Yarn、Mesos、K8S 等资源管理集群模式:Flink 向资源集群申请资源,创建Flink集群。
3)云上模式:Flink 可以在 Google、亚马逊云、阿里云等云计算平台上轻松部署。
Flink Client 是 应用程序代码实现的地方,Client 会将作业转换为 JobGraph,然后再提交到 JobManager,JobManager 再把作业的执行下发到 TaskManager,source,transform,sink 都是在 TaskManager 中完成的。部署组件如下面列表所示:
| 组件 |
功能描述 |
实现方式 |
| Flink Client |
将批或流作业应用转换为数据流图,然后把作业提交到 JobManager,无论在什么部署模式下,都不可缺少。 |
|
| JobManager |
JobManager 管理层。是 Flink 的工作调度中心组件,它有针对不同资源提供者的实现,这些实现在高可用性、资源分配行为和支持的作业提交模式上有所不同。 JobManager 的运行模式有:
|
|
| TaskManager |
TaskManagers 是真正干活的。 |
|
| 外部组件 |
||
| High Availability Service Provider(服务高可用) |
Flink的JobManager可以在高可用性模式下运行,从而允许Flink从JobManager故障中恢复。为了更快地进行故障切换,可以启动多个备用JobManager作为备份。 |
|
| File Storage and Persistency(文件存储和持久化) |
对于检查点(流作业的恢复机制),Flink依赖于外部文件存储系统 |
参考 FileSystems |
| Resource Provider(资源供应商) |
Flink可以通过不同的资源提供者框架进行部署,比如Kubernetes或Thread。 |
参考 JobManager 的实现方式 |
| Metrics Storage(度量指标存储) |
Flink组件报告内部指标,Flink作业也可以报告其他特定于作业的指标。 |
Flink提供了Counter、Gauge、Histogram和Meter 4类监控指标。同时提供了JMX、Graphite、InfluxDB、Prometheus 、PrometheusPushGateway、StatsD、Datadog和Slf4j共8种Reporter。 |
| Application-level data sources and sinks(应用程序级数据源和接收器) |
虽然应用程序级数据源和接收器在技术上不是Flink cluster组件部署的一部分,但在规划新的Flink生产部署时,应该考虑它们。使用Flink对频繁使用的数据进行归档可以带来显著的性能优势 |
For example:
参考 Connectors 连接器。 |
六、运行架构视角说 Flink
flink采用master-slave架构,由三部分构成:Job Client、Job Manager、Task Manager。
(一)运行时架构
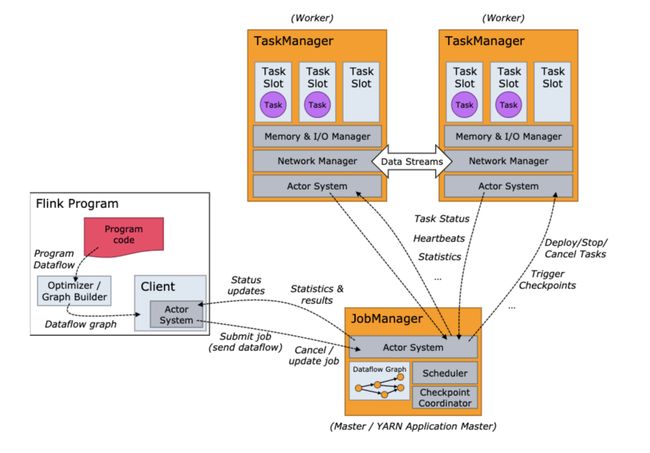
1)Flink client
客户端不是运行时和程序执行的一部分,但用于准备数据流并将其发送到JobManager。之后,客户端可以断开连接(分离模式),或保持连接以接收进度报告(连接模式)。客户端可以作为触发执行的Java/Scala程序的一部分运行,也可以在命令行进程中运行 ./bin/flink 。
2)JobManager
它决定何时安排下一个任务(或一组任务),对已完成的任务或执行失败做出反应,协调检查点,以及协调失败时的恢复,等等。该过程由三个不同的部分组成:
ResourceManager:ResourceManager负责Flink集群中的资源取消/分配和资源调配——它管理任务槽,任务槽是Flink集群中的资源调度单元。
Dispatcher:Dispatcher提供了一个REST接口,用于提交Flink应用程序以供执行,并为每个提交的作业启动一个新的JobMaster。它还运行Flink WebUI来提供有关作业执行的信息。
JobMaster:JobMaster负责管理单个JobGraph的执行。Flink集群中可以同时运行多个作业,每个作业都有自己的JobMaster。
一个集群有至少一个 JobManager,高可用部署方式时可有多个 JobManager,但只有一个是 leader,其他的处于 standby 状态。
3)TaskManagers
必须始终至少有一个TaskManager。TaskManager中资源调度的最小单位是任务槽。TaskManager中任务槽的数量表示并发处理任务的数量,一个任务槽中可能会执行多个运算符。
4)任务和操作链
对于分布式执行,Flink将操作符子任务链接到一起,形成任务。每个任务由一个线程执行。将操作符链接到任务中是一种有用的优化:它减少了线程到线程切换和缓冲的开销,提高了总体吞吐量,同时减少了延迟。
5)任务槽与资源
TaskManager 是一个 JVM 进程,在该进程的一个线程里,可以执行一个或多个子任务,为了控制一个 TaskManager 能够接受多少个子任务,Flink 抽象出一个概念【任务槽】,一个TaskManager 里至少有一个任务槽。多个任务槽平均分配一个 TaskManager 里的内存,共享 CPU 资源,共享 TCP 连接,共享心跳信息,共享数据和数据架构。
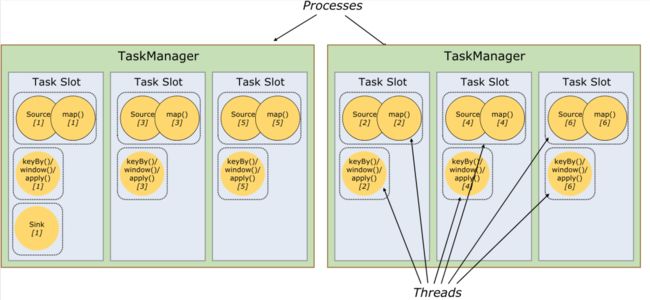
将上图的增加一个任务槽后的效果图如下图所示:
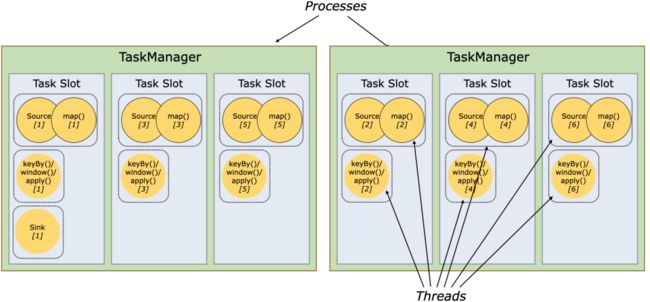
子任务在 TaskManager 里能得到公平的调度。
(二)作业提交流程
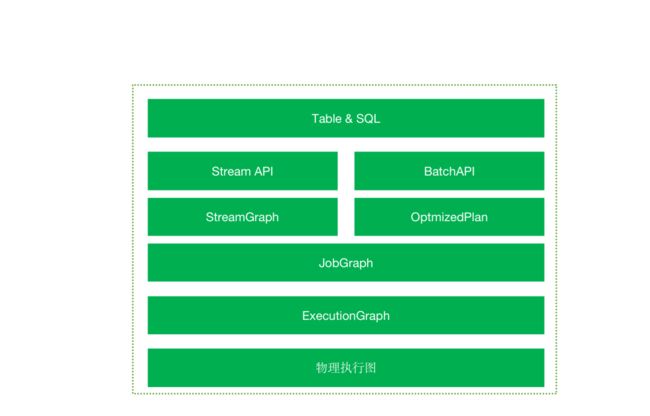
Flink 作业的提交遵循三层图结构,四层执行逻辑。
三层图结构:StreamGraph、JobGraph、ExecutionGraph。
四层执行逻辑:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
Flink On K8S 的作业提交流程可以参考:Flink安装部署之Flink On Kubernetes Session Model | 清风。
Flink On Yarn 的作业提交流程可以参考:Flink安装部署之Flink On Yarn|清风。
Flink On Local & Standalone的作业提交流程可以参考:Flink安装部署之Local&Standalone(一)|清风。
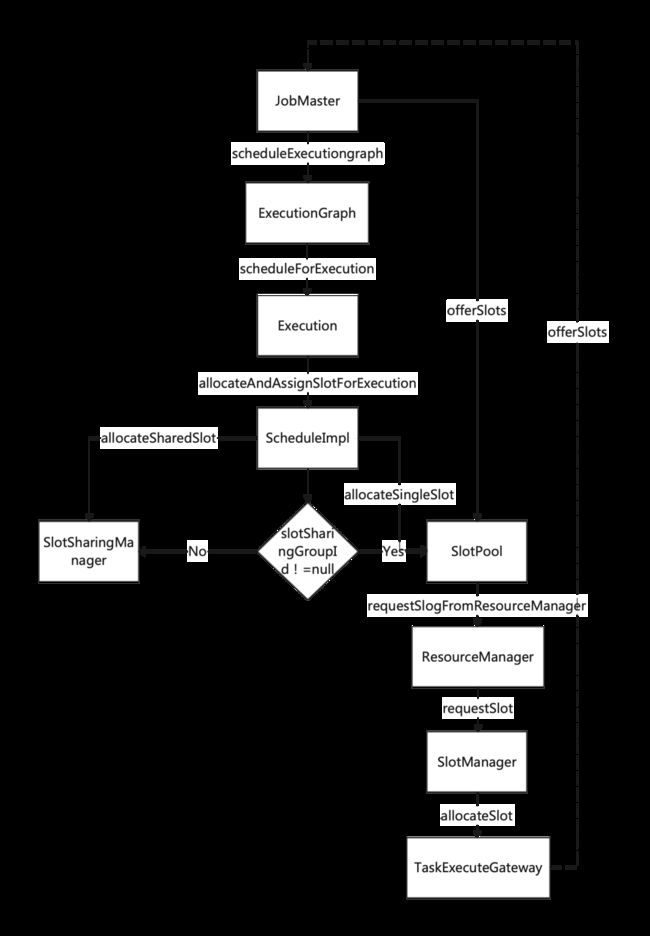
(三)资源分配流程
(四)作业计算流程
执行图 ExecutionGraph 是调度 Flink 作业执行的核心数据结构,包含了作业中所有并行执行的Task信息、Task之间的关联关系、数据流转关系。
StreamGraph 和JobGraph都在Flink Client生成,然后交给Flink集群。JobGraph 到 ExecutionGraph 在 JobMaster 中完成。
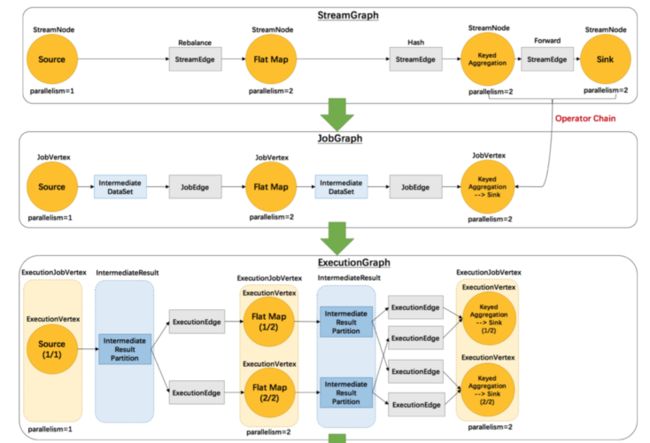
具体的解释后面的文章会专门解析。
(五)作业监控流程
监控通常也和作业任务状态的流转相关,本文以反压为例对 Flink 的监控有一个感知。在发送端,当一个subtask的发送缓存池被耗尽时(缓存数据要么被暂存在结果子分区( result subpartiiton )的缓存队列中,要么在 Netty 网络栈中),那么生产者就会被阻塞,不能继续发送数据,这就是背压产生的原因。接收端以类似的方式工作:任何进来的 Netty 缓存需要先通过网络缓存(network buffer)。如果在缓存池中没有可用的网络缓存(network buffer),Flink 将会停止读取读取通道数据直到有可用的缓存。这会极大的影响同一个TaskManager之下的多个 subtask 的共享通道。下图展示了subtask B.4因为没有缓存引起了背压,从而导致B.3在缓存池中还有可用缓存的情况下依然不能接收和处理数据。
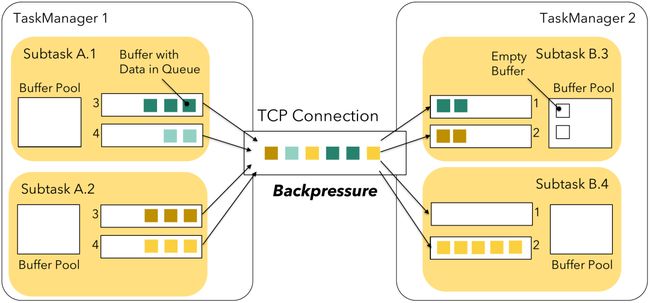
为了解决上面的问题,Flink 使用了流控机制。详细的监控相关的知识点后续文章将会有专门的分析。
(六)作业状态生命周期状态图
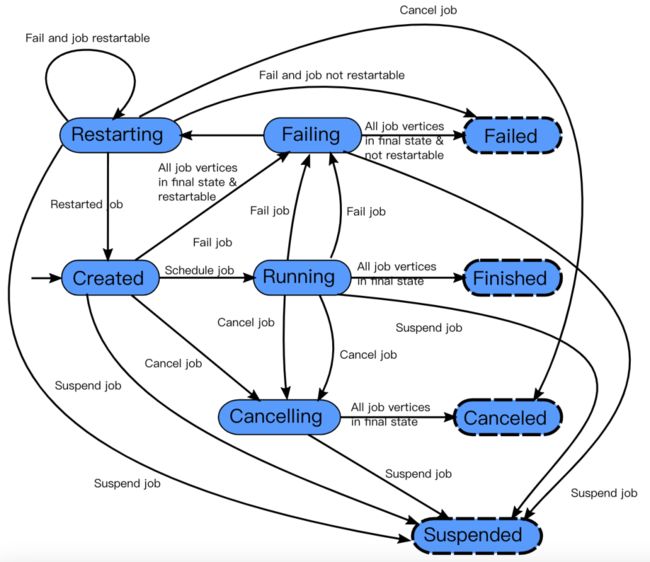
每个 ExecutionGraph 都有一个与之相关的作业状态信息,用来描述当前的作业执行状态。
Flink 作业刚开始会处于 created 状态,然后切换到 running 状态,当所有任务都执行完之后会切换到 finished 状态。如果遇到失败的话,作业首先切换到 failing 状态以便取消所有正在运行的 task。如果所有 job 节点都到达最终状态并且 job 无法重启, 那么 job 进入 failed 状态。如果作业可以重启,那么就会进入到 restarting 状态,当作业彻底重启之后会进入到 created 状态。
如果用户取消了 job 话,它会进入到 cancelling 状态,并取消所有正在运行的 task。当所有正在运行的 task 进入到最终状态的时候,job 进入 cancelled 状态。
Finished、canceled 和 failed 会导致全局的终结状态,并且触发作业的清理。跟这些状态不同,suspended 状态只是一个局部的终结。局部的终结意味着作业的执行已经被对应的 JobManager 终结,但是集群中另外的 JobManager 依然可以从高可用存储里获取作业信息并重启。因此一个处于 suspended 状态的作业不会被彻底清理掉。
笔者公众号:数据中台知行合一,不定时的写一些技术类文章,感兴趣的朋友可以扫码关注或微信公众号搜索:数据中台知行合一

所以,Flink 的正确的架构目标是什么?实时流计算。那在实时计算和流批一体里,选一个,你选哪个?Flink 架构的初心是什么?是让开发人员用得爽?是帮助企业降低研发成本?是做学术研究?不同的答案将会得出不同的架构目标。
至此,我们从逻辑架构、数据架构、开发架构、部署架构、运行架构不同视角学习了 Flink。没有目标的世界是个混乱的世界,那看官你学习 flink 的目标是什么呢?你的企业愿意用 flink 吗?为什么愿意用?如果不愿用,那为什么不愿意用呢?
Flink 的未来在哪里?要想进一步的开强拓土,是完善 Flink SQL & Table API?是夯实资源调度底座?是丰富 ML 能力?是存算一体?是湖仓一体?是批流融合?是拥抱云原生?Talk is cheap,show me your code。