Dubbo的使用和原理
目录
架构演进
分布式与RPC
Dubbo的使用
启动式检查
只订阅/只发布
分组/多版本控制
限流
多协议
声明式缓存
延迟暴露
隐式参数传递
泛化调用
异步调用
编辑
Mock服务降级
本地存根
应用/配置实践
Dubbo的原理
架构设计
URL Bus
SPI扩展点
Java SPI
Dubbo SPI
服务限流
集群容错
failfast
failover
failsafe
failback
forking
broadcast
服务降级
分组多版本
多协议/注册中心
服务暴露
服务引用
负载均衡
服务调用
double协议
Filter原理
优雅停机
总结
架构演进
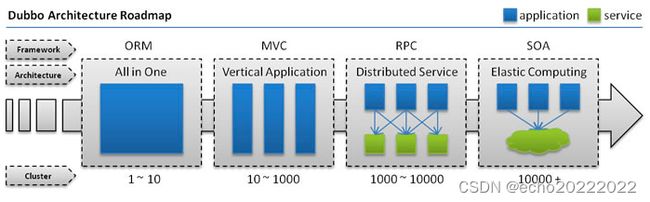
在早期,IT系统以All In One的单体架构为主,所有的服务都部署在同一台机器上,所有的功能都在一个应用中开发,这种架构的好处是能够对需求进行快速的响应,对运维部署和团队协作更友好,但是这样架构下系统各个模块之间的耦合度过大,牵一发动全身,如果服务体积不断增加,一次部署所需要的时间越来越长,此时就需要根据服务的功能特点进行拆分。
对单体架构的拆分,可以根据系统的特点采用横向拆分或纵向拆分,如果模块与模块之间的耦合度不大,那么就可以采用纵向拆分,把每个功能独立成一个服务,如果服务与服务之间的耦合度比较大,那就只能进行横向拆分,横向拆分后,就形成了一种面向服务的SOA架构,如果再往前进化就到了分布式微服务架构,基于dubbo构建的分布式服务是一种在SOA和微服务之间的一种架构模式,因为并没有清晰的界限,完全看具体的实现方式。
对于IT系统的架构来说,并不是架构越复杂越好,而是需要根据当前的业务发展情况、公司的人力资源以及相应的运维能力等做综合的判断,最后选择一种合适的架构。对于分布式架构来说,虽然说它能够提供更强的性能和可扩展性,但是这也是有前提的,比如团队要有很强的运维能力,相比于All In One的单体架构来说,分布式架构会带来很多额外的挑战,比如:
- 分布式配置
- 分布式任务
- 调用链跟踪
- 项目交付方式的变化
- 团队协作模式的变化
- 技术成本的提高
所以,对于一个IT系统来说,能不拆就不拆,如果非拆不可,能简单拆就简单拆,否则会为团队和公司带来很大的不确定性,当然对于新构建的系统,完全可以根据实际情况采用合适的架构模式。
分布式与RPC
分布式是技术发展和业务发展的产物,对于分布式系统来说,它由多个节点组成一个整体对外提供服务,那么远程通信能力就成了它的一个基础,比较常见的的远程通信方式有两种,一种是基于http协议,另一种是一系列的基于TCP构建的长连接协议,比如dubbo、thrift、grpc、hession等,这些协议都被称为是RPC协议。
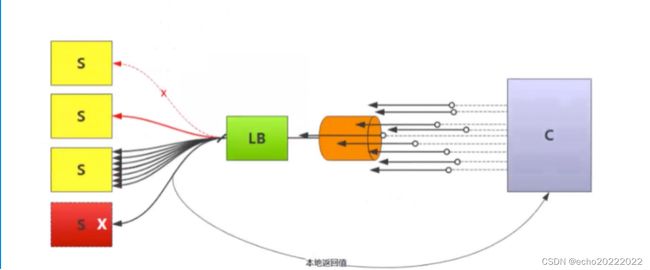
- 降级:服务降级属于通用业务模块,当服务出现问题时,返回给客户端一个缓存结构或伪结果,保证用户体验,服务降级一般分为大粒度和小粒度,大粒度一般是针对整个服务的降级,小粒度一般是针对单个请求的降级。
- 负载均衡:在及群众均摊流量,增加系统的吞吐量。
- 容错:当一个请求发送错误时,如何进行有效的补救,使得业务最终能够成功。
- 熔断:熔断一般分为客户端熔断和服务端熔断,核心目的是保证系统的最佳负载或最大吞吐量,在测试阶段找到系统负载的临界点,当系统负载超过临界点时多余的负载就快速失败。
- 限流:限流的目的是为了保证系统的可用性(RPS Request Pre Second)
-
- 客户端限流
- 信号量限流
- 连接数限流
- 服务端限流
- 线程池限流(隔离手段)
- 信号量限流(非隔离手段)
- 连接数限流(TCP Socket数量)
- 客户端限流
Dubbo的使用
启动式检查
只订阅/只发布
在开发阶段经常用到这个特性。
分组/多版本控制
一般用在灰度发布中。
限流
tcp socket限流:客户端connections,服务端accept
线程池限流:客户端active, 服务端executes
多协议
能够更好的在异构环境下进行系统集成。
声明式缓存
延迟暴露
- 服务预热
- 平滑发布(provider注册到注册中心后不一定马上可用)
隐式参数传递
RpcContext.getContext().setAttachment(key, value);
RpcContext.getContext().getAttachment(key,value);隐式参数传递用于传递在API接口之外的一些信息,比如做dubbo调用链跟踪的的时候就可以通过隐式参数来传递traceId。
泛化调用
GenericService genericService=ref.get();
Object result=genericService.$invoke(“methodName”, new String[{“java.lang.String”}], new Object[{“hello world”}]) 泛化调用指的是不通过API接口来调用服务提供者,一般用在异构系统集成或没有API接口支持的场景中。
异步调用
service.sayHello();
Future hello=RpcContext.getContext().getFuture()
Hello result = hello.get(); 
消费者端的用户线程不需要进行同步等待。
Mock服务降级
在接口所在包下找ServiceNameMock
直接指定Mock类
抛出指定的异常
不调用服务,直接强制走mock逻辑:
Mock是一种服务降级策略,但是dubbo的mock只有在抛出RpcException是才被触发,有一定的局限性,有时候会用Hystrix来做服务降级。
/**
* 隔离策略:
* 为什么要设置隔离?
*
* 线程隔离:(开销比较大,注意使用ThreadLoaca时的问题)
* 线程隔离策略 通过线程池 中的线程数量来控制并发访问量,线程池的大小和等待队列
* 可以通过参数进行配置,如果等待队列也满了,那么就会有一部分请求走fallback逻辑
*
* 由于使用了线程池,需要进行线程的上下文切换以及参数传递等,相对于信号量隔离 开销比较大
*
* 线程隔离策略比较适合那种计算量比较大的服务,因为支持异步和超时
*
* 信号量隔离(不支持超时、异步、线程切换,开销比较小)
* 信号量隔离策略 通过制定信号量的数量 来控制对资源的并发访问数量
* 超过信号量数量的请求一部分会进入队列等待,队列满后,其他的请求会走fallback逻辑
*
* 信号量隔离 自始至终都使用请求线程,没有线程切换,开销比较小。
*
* 信号量隔离策略 比较适合能快速响应的轻量级服务,不适合计算量比较大的接口
*
* */
@HystrixCommand(fallbackMethod = "error", commandProperties = {
//线程隔离模式 or 信号量隔离模式
@HystrixProperty(name = "execution.isolation.strategy", value = "THREAD"),
//如果请求超过5秒没有返回,则进入熔断降级
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "5000"),
//接口调用失败次数如果超过10次,则进入熔断降级
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10")
},
threadPoolProperties = {
@HystrixProperty(name="coreSize", value = "10"),
@HystrixProperty(name = "maxQueueSize", value = "10"),
@HystrixProperty(name = "keepAliveTimeMinutes", value = "1000"),
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "10")
}
)本地存根
本地存根类似于dubbo接口的静态代理,本地存根类实现业务接口,并提供一个依赖于业务接口的构造函数,在运行时真实的业务对象就会被注入进来,可以在stub内部完成一些额外的逻辑,比如参数校验等。
本地存根是运行在客户端的,所以本地存根一般存放在api的依赖包中。
应用/配置实践
- api和model放到同一个jar包中,共享给各个依赖项目;
- 修改api接口及model时,一定要做到向下兼容,如果不能兼容,必须通知所有服务调用方,制定上线计划;
- 把api接口的参数封装到bean中,这样参数修改的时候只修改bean对象中的字段就行了;
- 对于bean中的参数字段,只增加不删除;
- 基于版本号实现api接口的平滑升级,但在实现上如果不能做到上下兼容,还是要通知所有调用方;
Dubbo的原理
架构设计

这是官方网站给出的dubbo的总体逻辑架构,主要包含四个部分:Consumer服务消费者、Provider服务提供者、Registry服务注册中心和Monitor服务管控中心。
Provider启动后异步向注册中心注册自己,Consumer异步从注册中心拉取服务列表,当Provider发生变化时,注册中心异步通知Consumer,Provider和Consumer异步向Monitor上报监控信息,Consumer以同步的方式调用Provider。
 这是dubbo的微观架构,按照不同的职责,dubbo在代码实现层面分成了多层:
这是dubbo的微观架构,按照不同的职责,dubbo在代码实现层面分成了多层:
- Service:业务层,定义了业务接口和具体的实现类
- Config:Consumer和Provider的配置层,ReferenceConfig和ServiceConfig
- Proxy:封装了对接口调用的代理和服务暴露的代理
- Registry:注册层,负责与注册中心交互,实现服务的注册与发现
- Cluster:集群层,提供服务路由、集群容错、负载均衡等功能
- Monitor:监控层,负责与dubbo管控中心交互
- Protocol:对rpc协议进行了封装,屏蔽底层通信细节
- Exhange:转换层,把对业务接口的调用转换成Request-Respone模式
- Transport:网络通信层,Netty、Mina;
- Serialize:序列化层,在数据发送到网络前和从网络接收后进行序列化和反序列化
在微观层面,dubbo采用一种微内核架构,每一种组件都是一个SPI扩展点,dubbo内核通过SPI机制把这些扩展点组装起来,形成一个整体,这为dubbo提供了非常好的扩展性。
URL Bus
URL Bus是dubbo的核心设计思想,它的作用于两个,对外提供资源定位能力,对内通过与SPI机制配合动态串联各个组件。dubbo中的很多参数都是通过URL Bus来传递。
URL:protocol://username:password@host:port/path?key=value&key=valueDubbo URL的构造函数(与URL格式完全相同):
protected URL() {
this.protocol = null;
this.username = null;
this.password = null;
this.host = null;
this.port = 0;
this.address = null;
this.path = null;
this.parameters = null;
this.methodParameters = null;
}在实际的使用中zookeeper协议的url和dubbo协议的url最常见。Dubbo中的URL可以包含非常多的扩展点参赛,URL作为上下文信息贯穿整个扩展点体系。
SPI扩展点
从微观上看,dubbo采用的是一种微内核架构,各个服务组件通过SPI机制组合在一起,还可以通过SPI机制对Dubbo进行扩展。

Java SPI
在Java中也提供了SPI机制,使用方式也比较简单
- 首先创建用于提供服务的接口和实现类
public interface IHelloService {
String hello(String name);
}
//定义两个实现类
public class HelloService1 implements IHelloService {
@Override
public String hello(String name) {
return "HelloService1:" + name;
}
}
public class HelloService2 implements IHelloService {
@Override
public String hello(String name) {
return "HelloService2:" + name;
}
}- 然后在META-INF/services目录下创建于接口全名称为名字的配置文件
com.learn.dubbo.chapter1.echo.server.spi.IHelloService- 在配置文件中指定接口的实现了,用换行符分隔
com.learn.dubbo.chapter1.echo.server.spi.HelloService1
com.learn.dubbo.chapter1.echo.server.spi.HelloService2- 通过ServiceLoader获取实现类的实例对象
ServiceLoader helloServices = ServiceLoader.load(IHelloService.class);
for (IHelloService helloService : helloServices) {
System.out.println(helloService.hello("zhangsan"));
}
输出:
HelloService1:zhangsan
HelloService2:zhangsan java spi的底层原理其实很简单,就是读取配置文件信息,然后对每一个实现类进行实例化后,添加到LinkedHashMap中缓存起来,其中Key是实现类的全名称,value是对应的实例对象。但java spi并不好用,首先它无法按需实例化对象,其次无法按需获取对象的实例,只能通过遍历来获取,所以dubbo并没有使用java api,而是实现自己的dubbo spi。
Dubbo SPI
相对于java spi,dubbo spi有以下的特性
- 能够按需实例化实例对象和按需获取
- 提供了IoC和Aop功能
- 支持基于参数的动态加载机制
@SPI("helloService1") //指定默认的SPI接口实现
public interface IHelloService {
//通过URL中的helloService参数对应的值进行自适应,主要为了配置setter实现依赖注入
@Adaptive("helloService")
String hello(URL url, String name);
}
//第一个实现类
public class HelloService1 implements IHelloService {
@Override
public String hello(URL url, String name) {
return "HelloService1:" + name;
}
}
//第二个实现类
public class HelloService2 implements IHelloService {
@Override
public String hello(URL url, String name) {
return "HelloService2:" + name;
}
}
//第三个实现类
public class MyHelloService implements IHelloService {
private IHelloService helloService;
//这里有一个setter依赖注入,具体注入的对象是由URL中的参数决定的
public void setHelloService(IHelloService helloService) {
this.helloService = helloService;
}
@Override
public String hello(URL url, String name) {
System.out.println("my hello service ");
return helloService.hello(url, name);
}
}
//这是一个具有AOP功能的实现类
public class HelloServiceWrapper implements IHelloService{
private IHelloService helloService;
//构造方法中如果右依赖的扩展点,就会为对每个实例进行包装
public HelloServiceWrapper(IHelloService helloService) {
this.helloService = helloService;
}
@Override
public String hello(URL url, String name) {
System.out.println("before...");
String result = helloService.hello(url, name);
System.out.println("after...");
return result;
}
}
//配置文件 com.learn.dubbo.chapter1.echo.server.spi.IHelloService
helloService1=com.learn.dubbo.chapter1.echo.server.spi.HelloService1
helloService2=com.learn.dubbo.chapter1.echo.server.spi.HelloService2
myHelloService=com.learn.dubbo.chapter1.echo.server.spi.MyHelloService
wrapper=com.learn.dubbo.chapter1.echo.server.spi.HelloServiceWrapper
//调用
IHelloService helloService = ExtensionLoader.getExtensionLoader(IHelloService.class).getDefaultExtension();
URL url1 = new URL("","",0);
System.out.println(helloService.hello(url1,"lisi"));
IHelloService helloService2 = ExtensionLoader.getExtensionLoader(IHelloService.class).getExtension("helloService2");
URL url2 = new URL("","",0);
System.out.println(helloService2.hello(url2,"wangwu"));
IHelloService helloService3 = ExtensionLoader.getExtensionLoader(IHelloService.class).getExtension("myHelloService");
Map p3 = new HashMap<>();
p3.put("helloService","helloService2");
URL url3 = new URL("","",0, p3);
helloService3.hello(url3, "zhaoliu"); - @SPI注解标记一个借口为SPI扩展点
- @Adaptive实现基于URL Bus的自适应机制
- @Active 激活组件
getExtension(beanName)的作用是通过指定的key获取实例对象,整个过程主要分为四步
- 加载配置文件,通过反射得到接口实现类的Class对象并进行缓存
- 创建Class的实例对象
- 通过setter方法进行依赖注入
- 通过构造函数处理Aop
在加载配置文件的过程中,dubbo兼容了java spi,会从META-INF/services、META-INF/dubbo、META-INF/dubbo/internal这三个目录中加载配置文件,并对普通扩展类、自适应扩展类、@Active修饰的扩展类和包装器扩展类分别缓存,方便后续处理,紧接着通过指定的bean名称得到Class对象,然后通过反射创建类的实例对象。
对依赖注入的处理其实很简单,就是得到setter的方法名称后截取掉set,将剩下的内容的首字母小写后作为key再到SPI上下文中找对应的实例对象,然后再通过反射调用setter方法,注入实例对象。aop的处理逻辑是通过构造函数实现的,在解析的过程中dubbo对存储依赖该接口的构造函数的类单独进行了缓存,当通过spi获取实例对象时,最后都会通过反射将真实的实例对象包装到这些Wapper类中,实现一种静态的aop功能。
getAdaptiveExtision()实现了dubbo spi的自适应机制,把URL Bus作为参数的载体。
@SPI
public interface AdaptiveService {
@Adaptive("impl")
void adaptive(URL url, String msg);
}
public class AdaptiveServiceImpl implements AdaptiveService {
@Override
public void adaptive(URL url, String msg) {
System.out.println("msg");
}
}
配置文件:com.learn.dubbo.chapter1.echo.server.spi.AdaptiveService
impl1=com.learn.dubbo.chapter1.echo.server.spi.AdaptiveServiceImpl
调用
AdaptiveService adaptiveService = ExtensionLoader.getExtensionLoader(AdaptiveService.class).getAdaptiveExtension();
Map p5 = new HashMap<>();
p5.put("impl","impl1");
URL url5 = new URL("","",0, p5);
adaptiveService.adaptive(url5, "aaaaa"):
输出:
aaaaa 这里把想要获取的bean的id作为URL中的参数,然后dubbo api就会从URL中获取用@Adaptive注解指定的key从而拿到这个值,底层的实现原理比较简单,dubbo底层会动态生成一个Xxx$Adaptive类,在这个类中,会从url中获取对应的key的值,然后再通过getExtension(name)得到具体的扩展点对象。
package com.learn.dubbo.chapter1.echo.server.spi;
import com.alibaba.dubbo.common.extension.ExtensionLoader;
public class AdaptiveService$Adaptive implements com.learn.dubbo.chapter1.echo.server.spi.AdaptiveService {
public void adaptive(com.alibaba.dubbo.common.URL arg0, java.lang.String arg1) {
if (arg0 == null) throw new IllegalArgumentException("url == null");
com.alibaba.dubbo.common.URL url = arg0;
String extName = url.getParameter("impl");
if(extName == null)
throw new IllegalStateException("Fail to get extension(com.learn.dubbo.chapter1.echo.server.spi.AdaptiveService) name from url(" + url.toString() + ") use keys([impl])");
com.learn.dubbo.chapter1.echo.server.spi.AdaptiveService extension = (com.learn.dubbo.chapter1.echo.server.spi.AdaptiveService)ExtensionLoader.getExtensionLoader(com.learn.dubbo.chapter1.echo.server.spi.AdaptiveService.class).getExtension(extName);
extension.adaptive(arg0, arg1);
}
}上面这段代码是一个字符串,然后再通过动态编译技术编译成字节码。
getActiveExtension()的作用是获取所有被标注了@Active的扩展点
@SPI
public interface IActivateService {
void active();
}
@Activate(order = 1, group = "test")
public class ActiveService1 implements IActivateService {
@Override
public void active() {
System.out.println("Active1");
}
}
@Activate(order = 2, group = "test")
public class ActivateService2 implements IActivateService {
@Override
public void active() {
System.out.println("active2");
}
配置:com.learn.dubbo.chapter1.echo.server.spi.IActivateService
activateService1=com.learn.dubbo.chapter1.echo.server.spi.ActiveService1
activateService2=com.learn.dubbo.chapter1.echo.server.spi.ActivateService2
调用
Map m = new HashMap<>();
m.put("activate1", "activateService1");
m.put("activate2", "activateService2");
URL url6 = new URL("","",0, m);
List activateService = ExtensionLoader.getExtensionLoader(IActivateService.class).getActivateExtension(url6, "activate1,activate2", "test");
for (IActivateService a : activateService) {
a.active();
} Dubbo内置的Filter大量使用了@Active,因为它可以同时加载多个扩展点实例对象,比如限流组件@ExecuteLimitFilter/@ActiveLimitFilter,然后通过group来区分consumer或group。
服务限流
限流的目的是保证系统的可用性,避免因为负载超过系统能够承受的上限造成不可用或雪崩,dubbo提供了两种类型的限流方式,一种是在tcp连接数上限流(connections/accepts),一种是在处理请求的线程数上限流(active/exectes)。在客户端会为每一个服务接口创建多个tcp连接,connections这个属性就是在进行服务引用与服务端创建tcp连接的时候处理的,服务引用是通过DubboProtocol的refer方法实现的。
public Invoker refer(Class serviceType, URL url) throws RpcException {
this.optimizeSerialization(url);
DubboInvoker invoker = new DubboInvoker(serviceType, url,
//创建DubboInvoker的时候,会用到与服务端的TCP连接
this.getClients(url), this.invokers);
this.invokers.add(invoker);
return invoker;
}
private ExchangeClient[] getClients(URL url) {
boolean service_share_connect = false;
//从URL Bus上获取connections参数
int connections = url.getParameter("connections", 0);
if (connections == 0) {
//如果没有设置connections参数,就走共享连接,
//也就是对于一个服务接口只创建一个TCP连接
service_share_connect = true;
connections = 1;
}
ExchangeClient[] clients = new ExchangeClient[connections];
for(int i = 0; i < clients.length; ++i) {
if (service_share_connect) {
clients[i] = this.getSharedClient(url);
} else {
/**
初始化TCP连接,DubboInvoker中如果右多个TCP连接的话,
采用轮训的方式进行调用
protected Result doInvoke(Invocation invocation) throws Throwable {
ExchangeClient currentClient = this.clients[this.index.getAndIncrement() % this.clients.length];
}
*/
clients[i] = this.initClient(url);
}
}
return clients;
} accepts对应的服务端的限流方案,它主要限制的是一个接口对应的NettyServer的客户端连接数的限制。
public class NettyServer extends AbstractServer implements Server {}
AbstractServer:
public void connected(Channel ch) throws RemotingException {
if (!this.isClosing() && !this.isClosed()) {
//这里获取客户端连接数
Collection channels = this.getChannels();
//如果服务端设置了accetps并且客户端连接数比accetps要大,就直接关掉多余的客户端连接
if (this.accepts > 0 && channels.size() > this.accepts) {
logger.error("Close channel " + ch + ", cause: The server " + ch.getLocalAddress() + " connections greater than max config " + this.accepts);
ch.close();
} else {
super.connected(ch);
}
} else {
logger.warn("Close new channel " + ch + ", cause: server is closing or has been closed. For example, receive a new connect request while in shutdown process.");
ch.close();
}
} actives和executes属于限制并发请求数的限流方式,是通过Filter实现的,ActiveLimitFilter和ExecuteLimitFilter。
//在服务端应用
@Activate(group = {"provider"},value = {"executes"})
public class ExecuteLimitFilter implements Filter {
public Result invoke(Invoker invoker, Invocation invocation) throws RpcException {
URL url = invoker.getUrl();
String methodName = invocation.getMethodName();
//获取配置的executes参数
int max = url.getMethodParameter(methodName, "executes", 0);
//如果并发请求数超过了配置的最大数量,直接抛出异常
if (!RpcStatus.beginCount(url, methodName, max)) {
throw new RpcException("Failed to invoke method " + invocation.getMethodName() + " in provider " + url + ", cause: The service using threads greater than 集群容错
集群容错指的是如何避免因为服务提供者不可用或处理过程中出现异常操作对请求响应的异常,dubbo提供了6中集群容错策略,分别是failfast、failover、failsafe、failback、forking和broadcast。dubbo的集群容错策略都是在客户端进行的,由ClusterInvoker完成。

为了保证服务的高可用,一个服务一般会部署两个以上的节点,Cluster的作用是将多个服务实例代表的Invoker合并成ClusterInvoker,ClusterInvoker内部封装的容错和负载均衡,实现了对上层的透明。
failfast
failfast是一种快速失效的容错策略,即发生异常情况后直接返回不再进行重试或其他后续操作,failfast适合非幂等性操作的服务,或者高并发场景(因为在高并发下如果采取其他容错策略的话,会造成计算资源的紧张,容易造成请求的堆积或服务雪崩)。
FailfastClusterInvoker.java
public Result doInvoke(Invocation invocation, List> invokers, LoadBalance loadbalance) throws RpcException {
this.checkInvokers(invokers, invocation);
Invoker invoker = this.select(loadbalance, invocation, invokers, (List)null);
try {
/**
调用远程服务,如果出现异常,直接抛出RpcException,
不足任何后续处理
*/
return invoker.invoke(invocation);
} catch (Throwable var6) {
if (var6 instanceof RpcException && ((RpcException)var6).isBiz()) {
throw (RpcException)var6;
} else {
throw new RpcException(var6 instanceof RpcException ? ((RpcException)var6).getCode() : 0, "Failfast invoke providers " + invoker.getUrl() + " " + loadbalance.getClass().getSimpleName() + " select from all providers " + invokers + " for service " + this.getInterface().getName() + " method " + invocation.getMethodName() + " on consumer " + NetUtils.getLocalHost() + " use dubbo version " + Version.getVersion() + ", but no luck to perform the invocation. Last error is: " + var6.getMessage(), var6.getCause() != null ? var6.getCause() : var6);
}
}
} failover
failover容错策略需要与retries配合使用,由于存在重试,所以接口的调用时长会增大,在使用这种容错策略时,需要适当调整timeout时间。在高并发场景尽量不要使用failover,会造成请求的堆积甚至服务雪崩。
FailoverClusterInvoker.java
public Result doInvoke(Invocation invocation, List> invokers, LoadBalance loadbalance) throws RpcException {
List> copyInvokers = invokers;
this.checkInvokers(invokers, invocation);
String methodName = RpcUtils.getMethodName(invocation);
//获取重试次数,默认是2次,总数在retries的基础上 + 1,因为第一次请求不能算在重试次数上
int len = this.getUrl().getMethodParameter(methodName, "retries", 2) + 1;
//如果retries被设置成负数,对数据进行修正 ※
if (len <= 0) {
len = 1;
}
RpcException le = null;
List> invoked = new ArrayList(invokers.size());
Set providers = new HashSet(len);
for(int i = 0; i < len; ++i) {
if (i > 0) {
this.checkWhetherDestroyed();
//得到最新的可用Invoker
copyInvokers = this.list(invocation);
this.checkInvokers(copyInvokers, invocation);
}
/**
通过LoadBalancer选出一个Invoker进行调用
*/
Invoker invoker = this.select(loadbalance, invocation, copyInvokers, invoked);
invoked.add(invoker);
RpcContext.getContext().setInvokers(invoked);
try {
Result result = invoker.invoke(invocation);
/**
这里将上次出现的异常打印到日志
*/
if (le != null && logger.isWarnEnabled()) {
logger.warn("Although retry the method " + methodName + " in the service " + this.getInterface().getName() + " was successful by the provider " + invoker.getUrl().getAddress() + ", but there have been failed providers " + providers + " (" + providers.size() + "/" + copyInvokers.size() + ") from the registry " + this.directory.getUrl().getAddress() + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version " + Version.getVersion() + ". Last error is: " + le.getMessage(), le);
}
Result var13 = result;
return var13;
} catch (RpcException var18) {
if (var18.isBiz()) {
//如果是业务异常直接抛出去,跳出重试
throw var18;
}
le = var18;
} catch (Throwable var19) {
//如果是其他异常,封装成RcpException并记录
le = new RpcException(var19.getMessage(), var19);
} finally {
providers.add(invoker.getUrl().getAddress());
}
}
throw new RpcException(le.getCode(), "Failed to invoke the method " + methodName + " in the service " + this.getInterface().getName() + ". Tried " + len + " times of the providers " + providers + " (" + providers.size() + "/" + copyInvokers.size() + ") from the registry " + this.directory.getUrl().getAddress() + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version " + Version.getVersion() + ". Last error is: " + le.getMessage(), (Throwable)(le.getCause() != null ? le.getCause() : le));
} failsafe
failsafe这种容错策略简单理解就是直接忽略异常,一般用在处理不重要的数据的场景中。
FailSafeClusterInvoker.java
public Result doInvoke(Invocation invocation, List> invokers, LoadBalance loadbalance) throws RpcException {
try {
this.checkInvokers(invokers, invocation);
Invoker invoker = this.select(loadbalance, invocation, invokers, (List)null);
return invoker.invoke(invocation);
} catch (Throwable var5) {
//出现异常直接记录日志后,返回一个人假的成功结果,没有做任何处理
logger.error("Failsafe ignore exception: " + var5.getMessage(), var5);
return new RpcResult();
}
} failback
failback这种策略是通过把失败的任务添加到定时任务定进行定时的重试。
FailbackClusterInvoker.java
//记录失败的任务
private void addFailed(LoadBalance loadbalance, Invocation invocation, List> invokers, Invoker lastInvoker) {
if (this.failTimer == null) {
synchronized(this) {
if (this.failTimer == null) {
//初始化Timer定时器
this.failTimer = new HashedWheelTimer(new NamedThreadFactory("failback-cluster-timer", true), 1L, TimeUnit.SECONDS, 32, (long)this.failbackTasks);
}
}
}
//创建用于重试的定时任务
FailbackClusterInvoker.RetryTimerTask retryTimerTask = new FailbackClusterInvoker.RetryTimerTask(loadbalance, invocation, invokers, lastInvoker, this.retries, 5L);
try {
//启动定时,每个5秒钟执行一次
this.failTimer.newTimeout(retryTimerTask, 5L, TimeUnit.SECONDS);
} catch (Throwable var7) {
logger.error("Failback background works error,invocation->" + invocation + ", exception: " + var7.getMessage());
}
}
protected Result doInvoke(Invocation invocation, List> invokers, LoadBalance loadbalance) throws RpcException {
Invoker invoker = null;
try {
this.checkInvokers(invokers, invocation);
invoker = this.select(loadbalance, invocation, invokers, (List)null);
return invoker.invoke(invocation);
} catch (Throwable var6) {
logger.error("Failback to invoke method " + invocation.getMethodName() + ", wait for retry in background. Ignored exception: " + var6.getMessage() + ", ", var6);
//开启定时重试
this.addFailed(loadbalance, invocation, invokers, invoker);
return new RpcResult();
}
} forking
并行调用多个服务提供者,只只要有一个返回即算调用成功,适合对实时性要求比较高的幂等性操作。
public Result doInvoke(final Invocation invocation, List> invokers, LoadBalance loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
final List> selected;
final int forks = getUrl().getParameter(FORKS_KEY, DEFAULT_FORKS);
final int timeout = getUrl().getParameter(TIMEOUT_KEY, DEFAULT_TIMEOUT);
//如果forks的值小于0或比服务提供者的数量多,那么选择的范围就是全部的服务提供者
//对应的Invoker
if (forks <= 0 || forks >= invokers.size()) {
selected = invokers;
} else {
//否则,利用负载均衡,选出指定数量的Invoker,参加forking调用
selected = new ArrayList<>();
for (int i = 0; i < forks; i++) {
Invoker invoker = select(loadbalance, invocation, invokers, selected);
if (!selected.contains(invoker)) {
//Avoid add the same invoker several times.
selected.add(invoker);
}
}
}
RpcContext.getContext().setInvokers((List) selected);
//定义一个计数器,用来记录调用失败的数量
final AtomicInteger count = new AtomicInteger();
//定义一个阻塞队列,用于存在每个invoker调用返回的结果
final BlockingQueue broadcast
广播模式,同时调用多个服务提供者,只要有一个返回失败就算失败,通常被用在例如更新每个服务提供者的本地缓存这样的场景中。
public Result doInvoke(final Invocation invocation, List> invokers, LoadBalance loadbalance) throws RpcException {
checkInvokers(invokers, invocation);
RpcContext.getContext().setInvokers((List) invokers);
RpcException exception = null;
Result result = null;
//逐个invoker进行调用,如果有异常则记录下来
for (Invoker invoker : invokers) {
try {
result = invoker.invoke(invocation);
} catch (RpcException e) {
exception = e;
logger.warn(e.getMessage(), e);
} catch (Throwable e) {
exception = new RpcException(e.getMessage(), e);
logger.warn(e.getMessage(), e);
}
}
//如果在调用过程中,有一个异常,就说明本次调用失败了,直接抛出异常
if (exception != null) {
throw exception;
}
//如果没有异常说明所有的ivnoker都调用成功了,返回结果
return result;
} 服务降级
dubbo的服务降级是通过Mock机制实现的(只能响应RpcException),Mock降级主要分为两种,一种是异常降级,一种是强制降级,异常降级指的是在服务调用出现异常的时候进行降级处理,有三种方式,利用Mock对象处理请求、返回null、抛出指定的异常:
在接口所在包下找ServiceNameMock 这种方式要在接口所在包下提供ServiceNameMock,实现该接口并提供降级方案,此时如果调用出现异常dubbo就会用这个类的实例对象进行降级。
直接指定Mock类 这种方式对接口所在包没有明确的限制,其他逻辑与上一种策略相同。
这种方式是在调用异常时直接返回null值。
抛出指定的异常。
强制降级指的是在调用接口的时候,不会调用远程服务,而是直接走降级策略
不调用服务,直接强制走mock逻辑:
mock机制是一种客户端行为,它是通过Dubbo SPI的aop功能织入到正常的调用逻辑的,在Cluster相关的SPI配置文件中有如下的配置:
mock=com.alibaba.dubbo.rpc.cluster.support.wrapper.MockClusterWrapper
failover=com.alibaba.dubbo.rpc.cluster.support.FailoverCluster
failfast=com.alibaba.dubbo.rpc.cluster.support.FailfastCluster
failsafe=com.alibaba.dubbo.rpc.cluster.support.FailsafeCluster
failback=com.alibaba.dubbo.rpc.cluster.support.FailbackCluster
forking=com.alibaba.dubbo.rpc.cluster.support.ForkingCluster
available=com.alibaba.dubbo.rpc.cluster.support.AvailableCluster
switch=com.alibaba.dubbo.rpc.cluster.support.SwitchCluster
mergeable=com.alibaba.dubbo.rpc.cluster.support.MergeableCluster
broadcast=com.alibaba.dubbo.rpc.cluster.support.BroadcastClusterMockClusterWapper作为包装类出现,会对Cluster接口的实例进行包装,当通过Dubbo的ExtensionLoader创建Cluster实例时就会被MockCluster自动包装。
public class MockClusterWrapper implements Cluster {
private Cluster cluster;
public MockClusterWrapper(Cluster cluster) {
this.cluster = cluster;
}
//这里对Invoker包装了一个人MockClusterInvoker
public Invoker join(Directory directory) throws RpcException {
return new MockClusterInvoker(directory, this.cluster.join(directory));
}
}
MockClusterInvoker.java
public Result invoke(Invocation invocation) throws RpcException {
Result result = null;
String value = this.directory.getUrl().getMethodParameter(invocation.getMethodName(), "mock", Boolean.FALSE.toString()).trim();
if (value.length() != 0 && !value.equalsIgnoreCase("false")) {
//如果配置的force:的mock,直接走mock逻辑,不进行远程服务调用
if (value.startsWith("force")) {
if (logger.isWarnEnabled()) {
logger.warn("force-mock: " + invocation.getMethodName() + " force-mock enabled , url : " + this.directory.getUrl());
}
result = this.doMockInvoke(invocation, (RpcException)null);
} else {
/**
如果不是force类型的mock,则先进行远程服务调用
如果出现异常再走Mock逻辑,可以看到Mock只能响应RpcException
对于业务上的自定义异常,不会触发Mock机制
*/
try {
result = this.invoker.invoke(invocation);
} catch (RpcException var5) {
if (var5.isBiz()) {
throw var5;
}
if (logger.isWarnEnabled()) {
logger.warn("fail-mock: " + invocation.getMethodName() + " fail-mock enabled , url : " + this.directory.getUrl(), var5);
}
result = this.doMockInvoke(invocation, var5);
}
}
} else {
//如果没有配置Mock或mock=false,则走正常的逻辑
result = this.invoker.invoke(invocation);
}
return result;
}
private Result doMockInvoke(Invocation invocation, RpcException e) {
Result result = null;
List> mockInvokers = this.selectMockInvoker(invocation);
Object minvoker;
if (mockInvokers != null && !mockInvokers.isEmpty()) {
minvoker = (Invoker)mockInvokers.get(0);
} else {
minvoker = new MockInvoker(this.directory.getUrl());
}
try {
//调用MockInvoker处理业务逻辑
result = ((Invoker)minvoker).invoke(invocation);
} catch (RpcException var7) {
if (!var7.isBiz()) {
throw new RpcException(var7.getCode(), this.getMockExceptionMessage(e, var7), var7.getCause());
}
result = new RpcResult(var7.getCause());
} catch (Throwable var8) {
throw new RpcException(this.getMockExceptionMessage(e, var8), var8.getCause());
}
return (Result)result;
} 分组多版本
dubbo可以通过多版本和多分组进行灰度发布和业务隔离
//多分组
//多版本
实现的原理其实也比较简单,就是在进行服务发布的时候,把分组和版本号加入的servicerKey中,这里分为两个部分,一个是服务导出,一个是处理客户端请求,在DubboProtocol.export中进行服务导出
public Exporter export(Invoker invoker) throws RpcException {
URL url = invoker.getUrl();
//获取服务对应的key
String key = serviceKey(url);
DubboExporter exporter = new DubboExporter(invoker, key, this.exporterMap);
this.exporterMap.put(key, exporter);
...
}
protected static String serviceKey(URL url) {
int port = url.getParameter("bind.port", url.getPort());
//这里加入了版本和分组信息
return serviceKey(port, url.getPath(), url.getParameter("version"), url.getParameter("group"));
} 在处理客户端请求的ChannelHandler是通过重新构建这个serviceKey找到对应的Invoker的
private ExchangeHandler requestHandler = new ExchangeHandlerAdapter() {
public CompletableFuture多协议/注册中心
注册中心是服务治理的核心,它主要有两个功能,一是实现服务注册于服务发现,二是实现服务的配置管理。dubbo支持多种类型的注册中心,比如zookeeper、redis、etcd等。多协议指的是一个服务可以以多种协议对外暴露,这对异构系统的集成场景比较重要。
dubbo对多协议、多注册中心的支持非常简单,就是在服务导出的过程中通过两层的嵌套循环实现的
ServiceConfig.java\
private void doExportUrls() {
List registryURLs = this.loadRegistries(true);
//这里循环处理的是多协议
Iterator var2 = this.protocols.iterator();
while(var2.hasNext()) {
ProtocolConfig protocolConfig = (ProtocolConfig)var2.next();
this.doExportUrlsFor1Protocol(protocolConfig, registryURLs);
}
}
private void doExportUrlsFor1Protocol(ProtocolConfig protocolConfig, List registryURLs) {
if (registryURLs != null && !registryURLs.isEmpty()) {
//这里的迭代处理的时候多注册中心
Iterator var25 = registryURLs.iterator();
while(var25.hasNext()) {
}
}
} 
服务暴露
服务暴露过程主要分为三个主要过程,创建代表服务对象的Invoker、向注册中心注册服务、启动TCP Server监听指定端口上的客户端请求。而服务暴露过程是从ServiceBean开始的,配置的每一个都会被解析成ServiceBean,这个类实现了ApplicationContextListener接口,当spring容器启动完成后,就会触发服务暴露。
public void onApplicationEvent(ContextRefreshedEvent event) {
this.export();
}
public synchronized void export() {
//这里处理延迟暴露
if (this.delay != null && this.delay > 0) {
//通过一个ScheduleExecutorPool实现在指定的延迟实现到期后再进行服务暴露
delayExportExecutor.schedule(this::doExport, (long)this.delay, TimeUnit.MILLISECONDS);
} else {
this.doExport();
}
}
protected synchronized void doExport() {
this.doExportUrls();
}
private void doExportUrls() {
List registryURLs = this.loadRegistries(true);
Iterator var2 = this.protocols.iterator();
//这一层循环的主要作用是处理多协议,每一种协议都要在每个注册中心上注册
while(var2.hasNext()) {
ProtocolConfig protocolConfig = (ProtocolConfig)var2.next();
this.doExportUrlsFor1Protocol(protocolConfig, registryURLs);
}
}
private void doExportUrlsFor1Protocol(ProtocolConfig protocolConfig, List registryURLs) {
if (!"none".equalsIgnoreCase(scope)) {
if (!"remote".equalsIgnoreCase(scope)) {
/**
这里是以Injvm协议将服务导出到本地,
避免在本地调用服务时跨网络
*/
this.exportLocal(url);
}
if (!"local".equalsIgnoreCase(scope)) {
if (logger.isInfoEnabled()) {
logger.info("Export dubbo service " + this.interfaceClass.getName() + " to url " + url);
}
if (registryURLs != null && !registryURLs.isEmpty()) {
/**
这一层循环是处理多注册中心。
*/
Iterator var25 = registryURLs.iterator();
while(var25.hasNext()) {
URL registryURL = (URL)var25.next();
url = url.addParameterIfAbsent("dynamic", registryURL.getParameter("dynamic"));
URL monitorUrl = this.loadMonitor(registryURL);
if (monitorUrl != null) {
url = url.addParameterAndEncoded("monitor", monitorUrl.toFullString());
}
if (logger.isInfoEnabled()) {
logger.info("Register dubbo service " + this.interfaceClass.getName() + " url " + url + " to registry " + registryURL);
}
proxy = url.getParameter("proxy");
if (StringUtils.isNotEmpty(proxy)) {
registryURL = registryURL.addParameter("proxy", proxy);
}
/**
这里是服务导出的第一步:创建业务对象对应的Invoker,默认采用javaassist动态代理来把
业务对象封装到一个匿名的Invoker中
*/
Invoker invoker = proxyFactory.getInvoker(this.ref, this.interfaceClass, registryURL.addParameterAndEncoded("export", url.toFullString()));
DelegateProviderMetaDataInvoker wrapperInvoker = new DelegateProviderMetaDataInvoker(invoker, this);
/**
这里是具体的服务导出过程,包含服务暴露的后两步操作:向注册中心注册和开启TcP监听端口
每一个协议再注册中心注册一次,就对应一个人Exporter实例,所以如果一个服务配置了
多个注册中心多个协议,就会重复暴露多次。
这里的Protocol一开始对应的registy://协议,这个是一个伪协议,根据dubbo spi的自适应机制可以知道
protocl对应的是RegistryProtocol,这个对象里面包含了注册服务和启动TcP NettServer的逻辑
*/
Exporter exporter = protocol.export(wrapperInvoker);
this.exporters.add(exporter);
}
} else {
//这里处理的是直连的场景,即注册中心相关的配置为空
Invoker invoker = proxyFactory.getInvoker(this.ref, this.interfaceClass, url);
DelegateProviderMetaDataInvoker wrapperInvoker = new DelegateProviderMetaDataInvoker(invoker, this);
Exporter exporter = protocol.export(wrapperInvoker);
this.exporters.add(exporter);
}
}
}
RegistryProtocol.java
public class RegistryProtocol implements Protocol {
//这个方法封装了导出的核心逻辑
public Exporter export(Invoker originInvoker) throws RpcException {
//zookeeper://
URL registryUrl = this.getRegistryUrl(originInvoker);
//dubbo://
URL providerUrl = this.getProviderUrl(originInvoker);
URL overrideSubscribeUrl = this.getSubscribedOverrideUrl(providerUrl);
/**
这里创建了一个Listenr,也就是Zookeepr的Watcher,这个watcher在执行subscribe的时候回被触发、
内部根据SPI,通过DubboProtocol.export开启TCP本地端口监听
*/
RegistryProtocol.OverrideListener overrideSubscribeListener = new RegistryProtocol.OverrideListener(overrideSubscribeUrl, originInvoker);
this.overrideListeners.put(overrideSubscribeUrl, overrideSubscribeListener);
providerUrl = this.overrideUrlWithConfig(providerUrl, overrideSubscribeListener);
//这里是以InJvm协议把服务导出到本地
RegistryProtocol.ExporterChangeableWrapper exporter = this.doLocalExport(originInvoker, providerUrl);
Registry registry = this.getRegistry(originInvoker);
URL registeredProviderUrl = this.getRegisteredProviderUrl(providerUrl, registryUrl);
ProviderInvokerWrapper providerInvokerWrapper = ProviderConsumerRegTable.registerProvider(originInvoker, registryUrl, registeredProviderUrl);
boolean register = registeredProviderUrl.getParameter("register", true);
if (register) {
this.register(registryUrl, registeredProviderUrl);
providerInvokerWrapper.setReg(true);
}
//订阅,订阅完成后,机会触发Listener的执行
registry.subscribe(overrideSubscribeUrl, overrideSubscribeListener);
exporter.setRegisterUrl(registeredProviderUrl);
exporter.setSubscribeUrl(overrideSubscribeUrl);
return new RegistryProtocol.DestroyableExporter(exporter);
}
} 下面再来看DubboProtocol.export()方法
public Exporter export(Invoker invoker) throws RpcException {
URL url = invoker.getUrl();
//构造Servicekey,包含group和version
String key = serviceKey(url);
//构造DubboExporter,然后放到DubboProtocol的exporterMap中
DubboExporter exporter = new DubboExporter(invoker, key, this.exporterMap);
this.exporterMap.put(key, exporter);
Boolean isStubSupportEvent = url.getParameter("dubbo.stub.event", false);
Boolean isCallbackservice = url.getParameter("is_callback_service", false);
if (isStubSupportEvent && !isCallbackservice) {
String stubServiceMethods = url.getParameter("dubbo.stub.event.methods");
if (stubServiceMethods != null && stubServiceMethods.length() != 0) {
this.stubServiceMethodsMap.put(url.getServiceKey(), stubServiceMethods);
} else if (this.logger.isWarnEnabled()) {
this.logger.warn(new IllegalStateException("consumer [" + url.getParameter("interface") + "], has set stubproxy support event ,but no stub methods founded."));
}
}
//这里开启一个NettyServer
this.openServer(url);
this.optimizeSerialization(url);
return exporter;
}
private void openServer(URL url) {
String key = url.getAddress();
boolean isServer = url.getParameter("isserver", true);
if (isServer) {
ExchangeServer server = (ExchangeServer)this.serverMap.get(key);
if (server == null) {
synchronized(this) {
server = (ExchangeServer)this.serverMap.get(key);
if (server == null) {
//这里创建一个Server实例
this.serverMap.put(key, this.createServer(url));
}
}
} else {
server.reset(url);
}
}
}
private ExchangeServer createServer(URL url) {
url = url.addParameterIfAbsent("channel.readonly.sent", Boolean.TRUE.toString());
url = url.addParameterIfAbsent("heartbeat", String.valueOf(60000));
String str = url.getParameter("server", "netty");
if (str != null && str.length() > 0 && !ExtensionLoader.getExtensionLoader(Transporter.class).hasExtension(str)) {
throw new RpcException("Unsupported server type: " + str + ", url: " + url);
} else {
url = url.addParameter("codec", "dubbo");
ExchangeServer server;
try {
//用一个ChannelHandler构造一个Server实例,这个ChannelHandler包含了处理请求的核心逻辑
server = Exchangers.bind(url, this.requestHandler);
} catch (RemotingException var5) {
throw new RpcException("Fail to start server(url: " + url + ") " + var5.getMessage(), var5);
}
str = url.getParameter("client");
if (str != null && str.length() > 0) {
Set supportedTypes = ExtensionLoader.getExtensionLoader(Transporter.class).getSupportedExtensions();
if (!supportedTypes.contains(str)) {
throw new RpcException("Unsupported client type: " + str);
}
}
return server;
}
} 总结一下服务导出的过程:
- Spring启动完成发布ContextRefreshEvent事件,触发服务导出;
- 如果配置了延迟暴露,就会初始化一个定时任务在指定的时间后再进行服务暴露;
- 通过两层循环处理多协议、多注册中心的逻辑;
- 把具体的业务对象通过动态代理的方式包装成Invoker(是一个匿名Invoker,不是DubboInvoker);
- 如果导出协议是injvm协议,则直接把服务暴露到本地,如果是远程暴露则往下走;
- 通过RegistryProtocol把服务注册到注册中心,同时注册一个NotifyListener;
- NotifyListener中触发DubboProtocol.export()的调用,启动TCP端口监听;
- DubboProtocol.export()内部会创建一个NettyServer,内部封装了Netty的ServerBootstrap;
- 把Exportor对象缓存到DubbotProtocol内部的exportorMap中;(id=serviceName+group+version)
服务引用
Dubbo中配置的每一个都会被解析成一个ReferenceBean对象,这个类实现了FactoryBean接口,当spring IoC容器进行依赖注入的时候,就会调用它的getObject()方法,触发服务应用逻辑的执行。
ReferenceBean.java
public Object getObject() {
return this.get();
}
public synchronized T get() {
if (this.ref == null) {
this.init();
}
return this.ref;
}
private void init() {
//这个Map是存储参数的容器
Map map = new HashMap();
map.put("side", "consumer");
......
//创建接口的代理对象
this.ref = this.createProxy(map);
}
private T createProxy(Map map) {
//如果是Injvm协议就通过InjvmProtocol.refer方法创建InjvmInvoker,InjvmInvoker内部其实就是从InjvmProtocl内部的exportorsMap中
//通过serviceKey找到服务端对应的Invoker
if (isJvmRefer) {
URL url = (new URL("injvm", "127.0.0.1", 0, this.interfaceClass.getName())).addParameters(map);
this.invoker = refprotocol.refer(this.interfaceClass, url);
} else {
//如果不是injvm协议,并且服务提供者的个数是1个,那么就直接创建DubboInvoker
if (this.urls.size() == 1) {
this.invoker = refprotocol.refer(this.interfaceClass, (URL)this.urls.get(0));
} else {
//这里的protocol类型是RegistryProtocol
invokers.add(refprotocol.refer(this.interfaceClass, url));
//如果服务提供者有多个的话,就通过Cluser把多个DubboInvoker合并成一个ClusterInvoker,内部
//包含了集群容错、负载均衡等的逻辑
//这个cluster是通过SPI动态创建的,默认是FailoverCluster失效转移的集群策略。
this.invoker = cluster.join(new StaticDirectory(invokers));
}
}
/** 最终,通过动态代理把得到的DubboInvoker或ClusterInvoker封装到接口的代理对象中 */
return proxyFactory.getProxy(this.invoker);
} 下面看RegistryProtocol
public Invoker refer(Class type, URL url) throws RpcException {
url = url.setProtocol(url.getParameter("registry", "dubbo")).removeParameter("registry");
Registry registry = this.registryFactory.getRegistry(url);
if (RegistryService.class.equals(type)) {
return this.proxyFactory.getInvoker(registry, type, url);
} else {
Map qs = StringUtils.parseQueryString(url.getParameterAndDecoded("refer"));
String group = (String)qs.get("group");
return group == null || group.length() <= 0 || Constants.COMMA_SPLIT_PATTERN.split(group).length <= 1 && !"*".equals(group) ?
//这里进去
this.doRefer(this.cluster, registry, type, url) : this.doRefer(this.getMergeableCluster(), registry, type, url);
}
}
private Invoker doRefer(Cluster cluster, Registry registry, Class type, URL url) {
//这里是与注册中心的一个连接实例,类似于ZkClient
RegistryDirectory directory = new RegistryDirectory(type, url);
directory.setRegistry(registry);
directory.setProtocol(this.protocol);
Map parameters = new HashMap(directory.getUrl().getParameters());
URL subscribeUrl = new URL("consumer", (String)parameters.remove("register.ip"), 0, type.getName(), parameters);
if (!"*".equals(url.getServiceInterface()) && url.getParameter("register", true)) {
//向consumers目录注册自己
registry.register(this.getRegisteredConsumerUrl(subscribeUrl, url));
}
directory.buildRouterChain(subscribeUrl);
//订阅providers,configurators,routers
directory.subscribe(subscribeUrl.addParameter("category", "providers,configurators,routers"));
//这里用directory构建ClusterInvoker实例,RegistryDirectory实现了NotifyListener接口,会通过
//zookeeper watcher的形式把provider url加载到本地并缓存下来
Invoker invoker = cluster.join(directory);
ProviderConsumerRegTable.registerConsumer(invoker, url, subscribeUrl, directory);
return invoker;
}
RegistryDirectory.java
public void subscribe(URL url) {
this.setConsumerUrl(url);
consumerConfigurationListener.addNotifyListener(this);
this.serviceConfigurationListener = new RegistryDirectory.ReferenceConfigurationListener(this, url);
//这里的this就是一个NotifyListener
this.registry.subscribe(url, this);
}
//这个RegistryDirectory中的notifyListener在registry执行subscribe以后,就会被
//zookeeper触发,
public synchronized void notify(List urls) {
List categoryUrls = (List)urls.stream().filter(this::isValidCategory).filter(this::isNotCompatibleFor26x).collect(Collectors.toList());
this.configurators = (List)Configurator.toConfigurators(UrlUtils.classifyUrls(categoryUrls, UrlUtils::isConfigurator)).orElse(this.configurators);
this.toRouters(UrlUtils.classifyUrls(categoryUrls, UrlUtils::isRoute)).ifPresent(this::addRouters);
//这里获取到了所有的provider的url,并缓存下来,同时把url转换成DubboInvoker并缓存下来
this.refreshOverrideAndInvoker(UrlUtils.classifyUrls(categoryUrls, UrlUtils::isProvider));
}
toInvokers(): 这里用到的就是DubboProtocol.refer方法创建的DubboInvoker
invoker = new RegistryDirectory.InvokerDelegate(this.protocol.refer(this.serviceType, url), url, providerUrl);
DubboProtocol.java
public Invoker refer(Class serviceType, URL url) throws RpcException {
this.optimizeSerialization(url);
DubboInvoker invoker = new DubboInvoker(serviceType, url,
//这里就是为每个DubboInvoker创建与Provider端的TCP连接,并对connections级别的限流进行了处理
this.getClients(url), this.invokers);
this.invokers.add(invoker);
return invoker;
} 总结一下服务引用的逻辑:
- IoC依赖注入触发对ReferenceBean.getObject()的调用,开启服务引用逻辑;
- 如果是Injvm本地调用,则通过InjvmProtocol.refer()方法创建一个InjvmInvoker,否则往下走;
- 通过RegistryProtocol.refer()开启远程服务引用流程;
- 首先创建一个RegistryDirectory,内部封装了zkClient,同时实现了NotifyListener;
- 将当前服务注册到注册中心的的/consumers目录下;
- 订阅/providers,/configurators/routers目录,触发RegistryDirectory(NotifyListener)的notify()方法;
- 内部会得到所有的providers,然后为每个provider创建ExchangeClient并封装到一个DubboInvoker中;
- RegistryDirectory会把provider的信息缓存到本地;
- Cluster根据具体的容错策略把多个DubboInvoker封装到ClusterInvoker中;
- 通过动态代理的方式创建接口的代理对象(内部包含ClusterInvoker)返回给Ioc容器;
负载均衡
dubbo提供上了四种负载均衡策略,分别是random随机策略、roundrobin轮询策略、consistenthash一致性哈希策略和leastactive最小负载策略,其中最小负载策略指的是在集群环境下,如果某个服务处理请求的数量比少,有可能是因为它的处理能力不行导致的,然后dubbo就会尽量少的给他分配负载。
负载均衡的是在ClusterInvoker中发生的,以FailoverClusterInvoker为例:
public Result doInvoke(Invocation invocation, List> invokers, LoadBalance loadbalance) throws RpcException {
List> copyInvokers = invokers;
this.checkInvokers(invokers, invocation);
String methodName = RpcUtils.getMethodName(invocation);
int len = this.getUrl().getMethodParameter(methodName, "retries", 2) + 1;
if (len <= 0) {
len = 1;
}
RpcException le = null;
List> invoked = new ArrayList(invokers.size());
Set providers = new HashSet(len);
for(int i = 0; i < len; ++i) {
if (i > 0) {
this.checkWhetherDestroyed();
//从RegistryDirectory中拿到最新的Invokers
copyInvokers = this.list(invocation);
this.checkInvokers(copyInvokers, invocation);
}
/**
负载均衡:
这里根据LoadBalance选择一个Invoker,具体的LoadBalance实例时通过spi机制根据参数
动态决定的。
*/
Invoker invoker = this.select(loadbalance, invocation, copyInvokers, invoked);
invoked.add(invoker);
RpcContext.getContext().setInvokers(invoked);
try {
Result result = invoker.invoke(invocation);
if (le != null && logger.isWarnEnabled()) {
logger.warn("Although retry the method " + methodName + " in the service " + this.getInterface().getName() + " was successful by the provider " + invoker.getUrl().getAddress() + ", but there have been failed providers " + providers + " (" + providers.size() + "/" + copyInvokers.size() + ") from the registry " + this.directory.getUrl().getAddress() + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version " + Version.getVersion() + ". Last error is: " + le.getMessage(), le);
}
Result var13 = result;
return var13;
} catch (RpcException var18) {
if (var18.isBiz()) {
throw var18;
}
le = var18;
} catch (Throwable var19) {
le = new RpcException(var19.getMessage(), var19);
} finally {
providers.add(invoker.getUrl().getAddress());
}
} 服务调用
服务调用过程总体上可以抽象成DubboInvoker → RpcInvocation → 匿名Invoker,调用开始于业务代码中对接口的调用,由于执行完服务引用后,注入到服务中的接口对象是一个ClusterInvoker的代理对象,所以请求会来到ClusterInvoker的invoke方法,调用的相关信息会封装到Invocation中,包括调用的方法名称、参数类型、参数值以及隐式参数等信息,ClusterInvoker内部首先从RegistryDirectory中获所有provider对应的Invoker列表,然后通过LoadBalance实例从这些Invoker中选择一个,消费端对应的Invoker类型是DubboInvoker,最终调用就会到DubboInvoker中,DubboInvoker内部通过轮询的方式选择出一个ExchangeClient发送请求。
protected Result doInvoke(Invocation invocation) throws Throwable {
RpcInvocation inv = (RpcInvocation)invocation;
String methodName = RpcUtils.getMethodName(invocation);
inv.setAttachment("path", this.getUrl().getPath());
inv.setAttachment("version", this.version);
ExchangeClient currentClient;
/**
如果provider只有一个,就选择这个,如果有多个,则以轮询的方式选择一个,
*/
if (this.clients.length == 1) {
currentClient = this.clients[0];
} else {
currentClient = this.clients[this.index.getAndIncrement() % this.clients.length];
}
try {
//这里判断是否为异步调用
boolean isAsync = RpcUtils.isAsync(this.getUrl(), invocation);
boolean isAsyncFuture = RpcUtils.isReturnTypeFuture(inv);
//这里判断是否为单向的心跳包
boolean isOneway = RpcUtils.isOneway(this.getUrl(), invocation);
int timeout = this.getUrl().getMethodParameter(methodName, "timeout", 1000);
if (isOneway) {
//如果是单向的心跳包,发出去就不管了
boolean isSent = this.getUrl().getMethodParameter(methodName, "sent", false);
currentClient.send(inv, isSent);
RpcContext.getContext().setFuture((Future)null);
//直接返回结果
return new RpcResult();
} else if (isAsync) {
//如果是异步调用,就将Future放到RpcContext上,不进行等待
ResponseFuture future = currentClient.request(inv, timeout);
FutureAdapter然后再通过Transport、Serialize通过底层的NettyClient发送到服务端的NettyServer中,在服务端的DubboProtocol定义了一个处理客户端请求的Handler#ChannelHandler
private ExchangeHandler requestHandler = new ExchangeHandlerAdapter() {
public CompletableFuture在这个Handler中,首先获取调用信息,然后根据调用信息构造serviceKey,再从DubboProtocol中的exportorsMap中找到对应的Invoker进行调用,此时请求就到了服务导出时创建的那个匿名Invoker中
JavaassistProxyFactory.java
public Invoker getInvoker(T proxy, Class type, URL url) {
final Wrapper wrapper = Wrapper.getWrapper(proxy.getClass().getName().indexOf(36) < 0 ? proxy.getClass() : type);
return new AbstractProxyInvoker(proxy, type, url) {
protected Object doInvoke(T proxy, String methodName, Class[] parameterTypes, Object[] arguments) throws Throwable {
return wrapper.invokeMethod(proxy, methodName, parameterTypes, arguments);
}
};
} 在这个人匿名invoker中根据Invocation中的调用信息反射调用业务对象,然后再通过Exchange、Transport、Serialize组件将结果返回给客户端。
总结一下服务调用的过程:
- 消费端发起对接口的调用;
- 由于业务代码中拿到的是封装了ClusterInvoker的代理对象,所以请求会来到ClusterInvoker中(包含了Mock);
- ClusterInvoker的invoke方法内部首先通过LoadBalancer选择一个provider对应的DubboInvoker;
- 然后再调用这个DubboInvoker的invoke方法;
- 内部会把请求参数封装成RpcInvocation,然后用随机的方式从DubboInvokder中选择一个ExchangeClient向服务端发送请求;
- 服务端定义的ChannelHandler中手电拿到请求参数RPCInvocation,然后从DubboProtocol的exportorsMap中找到服务对象对应的Invoker;
- 在对这个Invoker进行调用,得到结果后原路返回;
double协议
下面这张图是官网给出来的dubbo协议的组成图

在dubbo协议中,用16个字节(0-127 一共128个比特位)来定义协议头,下面简单说明一个每个部分的含义
0 ~ 15 bit:存储魔法数字,dubbo用这个魔法数字标识来解决tcp中的粘包/拆包问题
16 bit:数据包的类型,0位response,1为request
17 bit:调用方式,0为单向调用,1为双向调用(dubbo进行优雅停机时发送的readonly消息中,该bit为空)
18 bit:事件标识,0位请求/响应包,1位心跳包
19 ~ 23 bit:是序列化器id,用来统一consumer和provider的消息序列化方式,例如2为Hessian2,3为Java
24 ~ 31 bit:状态标识,例如20为OK,30位Client_timeout
32 ~ 95 bit:请求编号
96 ~ 127 bit:消息体长度
Filter原理
过滤器是dubbo中的一个非常重要的组件,功能类似于java web中的filter或spring mvc中的interceptor,对请求被处理的前后进行拦截,很多功能都是基于过滤器来做的,比如access log、monitor、executor limit等。
dubbo的过滤器实际上是通过SPI的aop功能实现的,内部提供了一个ProtocolFilteWapper类,实现了Protocol接口。
//实现了Protocol接口
public class ProtocolFilterWrapper implements Protocol {
private final Protocol protocol;
/**
这里是重点:遵循了Dubbo SPI 的AOP规范,在构造函数中依赖Protocol组件
**/
public ProtocolFilterWrapper(Protocol protocol) {
if (protocol == null) {
throw new IllegalArgumentException("protocol == null");
} else {
this.protocol = protocol;
}
}
/**
在服务导出和服务引用时,调用了buildInvokerChain方法对Invoker进行包装
**/
public Exporter export(Invoker invoker) throws RpcException {
return "registry".equals(invoker.getUrl().getProtocol()) ? this.protocol.export(invoker) : this.protocol.export(buildInvokerChain(invoker, "service.filter", "provider"));
}
public Invoker refer(Class type, URL url) throws RpcException {
return "registry".equals(url.getProtocol()) ? this.protocol.refer(type, url) : buildInvokerChain(this.protocol.refer(type, url), "reference.filter", "consumer");
}
private static Invoker buildInvokerChain(final Invoker invoker, String key, String group) {
final Invoker last = invoker;
// 这里通过SPI机制加载所有被激活的Filter,注意这里的group,对应了@Active注解中的group
List filters = ExtensionLoader.getExtensionLoader(Filter.class).getActivateExtension(invoker.getUrl(), key, group);
if (!filters.isEmpty()) {
/**
这里的遍历顺序可以留意一下,是倒序遍历的
例如有 filter a b c,invoker 遍历顺序是
c - invoker , b - c - invoker, a - b - c - invoker,这样就可以保证最终的执行顺序是 a - b - c invoker了 。
*/
for(int i = filters.size() - 1; i >= 0; --i) {
final Filter filter = (Filter)filters.get(i);
last = new Invoker() {
public Class getInterface() {
return invoker.getInterface();
}
public URL getUrl() {
return invoker.getUrl();
}
public boolean isAvailable() {
return invoker.isAvailable();
}
//把所有的Filter层层包装在原始的Invoker外面
public Result invoke(Invocation invocation) throws RpcException {
return filter.invoke(last, invocation);
}
public void destroy() {
invoker.destroy();
}
public String toString() {
return invoker.toString();
}
};
}
}
return last;
}
} 内部重写了export和refer方法,内部增加了包装Filter的逻辑
优雅停机
dubbo的优雅停机是通过jvm的shutdown hook实现的,当向java进程发送kill -9信号时,停机逻辑就会被shutdown hook执行。为了确保业务的正确性,不能直接将所有正在执行的任务停掉,可以说优雅停机是分布式开发框架的一个必须的功能,dubbo在停机的时候,主要做了三件事:
- 向服务注册中心取消注册信息,这样注册中心就可以通知到consumer;
- 向consumer发送readonly消息;
- 不在接收新的请求,并等待正在执行的任务执行完成;
之所以向consumer发送readonly消息,主要是因为服务从注册中心取消到被consumer响应需要一定的时间,而在这个时间内有可能provider已经停机了,为了让consumer尽快感知到,所以就发了一个消息过去,以最快的速度告诉consumer不要在发新的请求过来了。
总结
Dubbo是一个分布式服务开发框架,提供了服务发现与服务注册,能够实现跨进程调用。从微观层面看,Dubbo的SPI扩展点机制和URL数据总线是框架设计的核心,实现了微内核架构和动态组合组件的能力。作为分布式开发框架,Dubbo在提供跨进程调用这一最核心功能的基础上,还提供了一系列的分布式系统所面临的核心问题的解决方案,例如配置统一管理、集群容错、负载均衡、服务降级、服务限流等功能。
Dubbo中的核心概念是Invoker,每个服务提者供和和服务消费者都是一个Invoker,服务提供者Invoker包含了真实的服务对象,服务消费者Invoker代理了服务接口,封装了Tcp通信功能,通过InvokerInvocationHandler创建Invocation,两者通过Invocation传递信息,从纵向看,dubbo包含了Interface、Config、Proxy、Cluster、Protocol、Monitor、Exchange、Transport和Serialize,
- Interface是接口层,作为dubbo与业务代码交互的入口,Config是配置层,每个或都会被解析成Config;
- Proxy是代理层,主要作用是为业务对象或服务接口创建代理对象,代理对象内部封装了远程通信能力;
- Cluster是集群层,主要针对服务消费者,内部提供了容错、路由、负载均衡的能力;
- Protocol是协议层,协议层从逻辑上理解是传输数据的转换规则,但从代码层面它与SPI配合串联起了各种核心逻辑;
- Exchange主要值将请求和响应封装成Request和Response对象;
- Transport层封装了底层通信能力,例如Netty、Mina、Http、Rest等;
- Serialize是序列化层,对通过网络接收和发送的数据进行序列化和反序列化;