【数据分析】利用 Python 分析了某化妆品企业的销售情况,我得出的结论是?...
作者:Cherich_sun
来源:公众号「杰哥的IT之旅」ID:Jake_Internet
本文为读者投稿
【导语】本篇文章是关于某化妆品企业的销售分析。从分析思路思路开始带大家一步步的用python进行分析,找出问题,并提出解决方案的整个流程。
需求:希望全面了解此某妆品企业的销售情况,帮助企业运营领导层了解企业整体销售运营情况及商品销售情况,为该企业的营销策略提供相对应的建议和销售策略。
业务分析流程
1、 场景(诊断现状)
对象:用户;销售
关注点:找到影响销售的增长因素
目标:发现问题&提出解决方案
2、需求拆解
分析销售趋势,找到影响企业营收增长的商品或区域
按月份销售趋势图(整体)
商品销售额对比(一级、二级,找出最低、最高)
区域销售额对比(下钻:区、省,找出最低、最高)
探索不同商品的销售状况,为企业的商品销售,提出策略建议
不同月份的各个产品的销售额占比情况
产品相关分析
分析用户特征、购买频率、留存率等
购买频率分布
复购率(重复购买用户数量(两天都有购买过算重复)/用户数量)
同期群分析(按月)
3、代码实现
获取数据(excel)
为某化妆品企业 2019 年 1 月-2019 年 9 月每日订单详情数据和企业的商品信息数据,包括两个数据表,销售订单表和商品信息表。其中销售订单表为每个订单的情况明细,一个订单对应一次销售、一个订单可包含多个商品。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.family'] = 'SimHei'
import numpy as np
import warnings
warnings.filterwarnings("ignore")
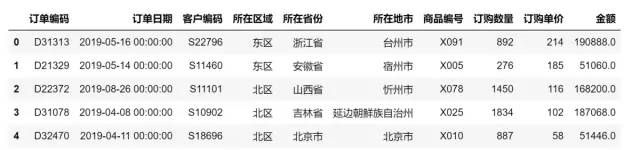
data = pd.read_excel('C:/Users/cherich/Desktop/日化.xlsx',encoding='gbk')
data.head()
data_info = pd.read_excel('C:/Users/cherich/Desktop/日化.xlsx',encoding='gbk',sheet_name='商品信息表')
data_info

数据清洗和加工
data = data.dropna()
# 订购数量结尾有字符'个'
data['订购数量'] = data['订购数量'].apply(lambda x:str(x)[:-1] if str(x)[-1] == '个' else x)
data['订购数量'] = data['订购数量'].astype(int)
# 订购数量结尾有字符'元'
data['订购单价'] = data['订购单价'].apply(lambda x:str(x)[:-1] if str(x)[-1] == '元' else x)
data['订购单价'] = data['订购单价'].astype(int)
# 日期里有特殊字符 2019#3#11
def proess_date(df):
pos = str(df).find('#')
if pos!= -1:
df = str(df).split('#')
return df[0]+'-'+df[1]+'-'+df[2]
else:
return df
# res = proess_date(df ='2019#3#11')
data['订单日期'] = data['订单日期'].apply(proess_date)
data['订单日期'] = data['订单日期'].apply(lambda x:str(x).replace('年','-').replace('月','-') if '年' in str(x) else x )
data['订单日期'] = pd.to_datetime(data['订单日期'])
#data.info()
data = data[data.duplicated()==False]
data['所在省份'].nunique()
data['月份'] = data['订单日期'].apply(lambda x:str(x).split('-')[1])
data

数据可视化
# 两张表数据合并
total_data = pd.merge(data,data_info,on='商品编号',how='left')
total_data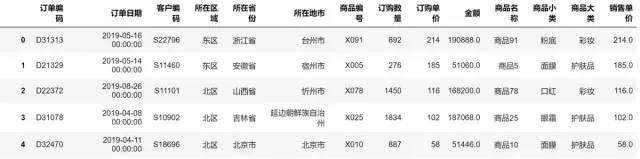
groups = data.groupby('月份')
x = [each[0] for each in groups]
y = [each[1].金额.sum() for each in groups]
z = [each[1].金额.count() for each in groups]
money_mean = data.金额.sum()/9
order_mean = data.金额.count()/9
plt.figure(figsize=(18, 10), dpi=80)
plt.subplot(221)
plt.plot(x, y,linewidth=2)
plt.axvspan('07', '08', color='#EE7621', alpha=0.3)
plt.axhline(money_mean, color='#EE7621', linestyle='--',linewidth=1)
plt.title("每月销售额趋势图",color='#4A708B',fontsize=24)
plt.ylabel("金额/(亿)",fontsize=16)
plt.subplot(222)
plt.plot(x, z, linewidth=2, color = '#EE7621')
plt.axvline('07', color='#4A708B', linestyle='--',linewidth=1)
plt.axhline(order_mean, color='#4A708B', linestyle='--',linewidth=1)
plt.title("每月订单量趋势图",color='#4A708B',fontsize=24)
plt.ylabel("订单/(单)",fontsize=16)
plt.show()
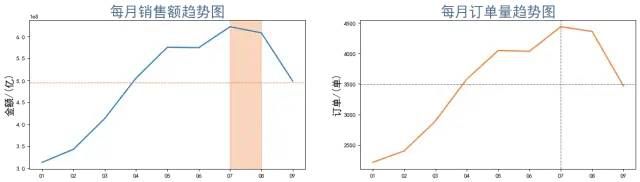
图表说明:从整体来看,销售额和订单量从4月开始大幅度上升,均高于均值;8月份开始呈下降趋势,处于均值水平。
groups_category= total_data.groupby(['月份','商品大类'])
category1 = []
category2 = []
for i,j in groups_category:
# print(i,j.月份.count())
if i[1]=='彩妆':
category1.append(j.金额.sum())
else:
category2.append(j.金额.sum())
labels = x
xticks = np.arange(len(labels))
width = 0.5
p = np.arange(len(labels))
fig, ax = plt.subplots(figsize=(18,8))
rects1 = ax.bar(p - width/2, category1,width, label='彩妆',color='#FFEC8B')
rects2 = ax.bar(p + width/2, category2, width, label='护肤品',color='#4A708B')
ax.set_ylabel('销售额/(亿)')
ax.set_title('每月护肤品和彩妆的销售额对比图(大类)')
ax.set_xticks(xticks)
ax.set_xticklabels(labels)
ax.legend()
plt.show()
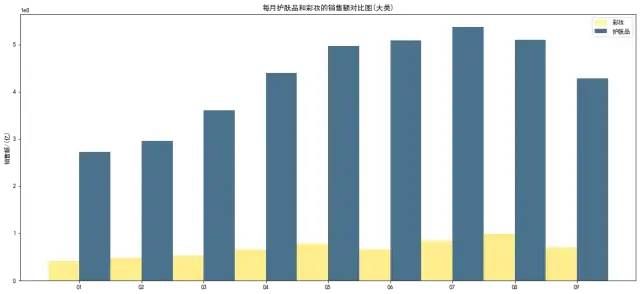
图表说明:护肤品需求满足大多数人,明显高于彩妆。并且5月—8月是护肤品需求旺季。相比彩妆的变化不明显。
groups_categorys= total_data.groupby('商品小类')
x = [each[0] for each in groups_categorys]
y = [each[1].金额.sum() for each in groups_categorys]
fig = plt.figure(figsize=(18,8),dpi=80)
plt.title('各个品类的销售额对比图',color='#4A708B',fontsize=24)
plt.ylabel('销售额(元)',fontsize=15)
colors = ['#6699cc','#4A708B','#CDCD00','#DAA520','#EE7621','#FFEC8B','#CDCD00','#4A708B','#6699cc','#DAA520','#4A708B','#FFEC8B']
for i, group_name in enumerate(groups_categorys):
lin1 =plt.bar(group_name[0], group_name[1].金额.sum(),width=0.8,color=colors[i])
for rect in lin1:
height = rect.get_height()
plt.text(rect.get_x()+rect.get_width()/2, height+1, int(height),ha="center",
fontsize=12)
plt.xticks(fontsize=15)
plt.grid()
plt.show()
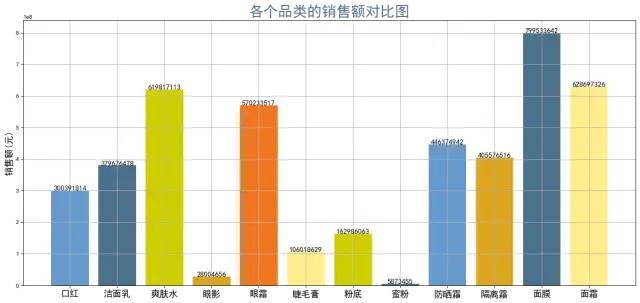
图表说明:面膜的销售额第一,其次是面霜、爽肤水。销售额最低的是蜜粉,眼影。
total_data = total_data.dropna()
total_data['所在区域'] = total_data['所在区域'].apply(lambda x:str(x).replace('男区','南区').replace('西 区','西区'))
groups_area= total_data.groupby(['所在区域','商品小类'])
results = {}
for i,j in groups_area:
money = int(j.金额.sum())
if i[0] in results.keys():
results[i[0]][i[1]] = money
else:
results[i[0]] = {}
for cate in category_names:
results[i[0]][cate] = 0
results[i[0]]['口红'] = money
results= {key_data:list(values_data.values()) for key_data,values_data in results.items()}
def survey1(results, category_names):
labels = list(results.keys())
data = np.array(list(results.values()))
data_cum = data.cumsum(axis=1)
category_colors = plt.get_cmap('RdYlGn')(
np.linspace(0.15, 0.85, data.shape[1]))
fig, ax = plt.subplots(figsize=(25,8))
ax.invert_yaxis()
ax.xaxis.set_visible(False)
ax.set_xlim(0, np.sum(data, axis=1).max())
for i, (colname, color) in enumerate(zip(category_names, category_colors)):
widths = data[:, i]
starts = data_cum[:, i] - widths
ax.barh(labels, widths, left=starts, height=0.5,
label=colname, color=color)
xcenters = starts + widths / 2
r, g, b, _ = color
text_color = 'white' if r * g * b < 0.5 else 'darkgrey'
for y, (x, c) in enumerate(zip(xcenters, widths)):
ax.text(x, y, str(int(c)), ha='center', va='center',color=text_color)
ax.legend(ncol=len(category_names), bbox_to_anchor=(0, 1),
loc='lower left', fontsize='small')
return fig, ax
survey1(results, category_names)
plt.show()
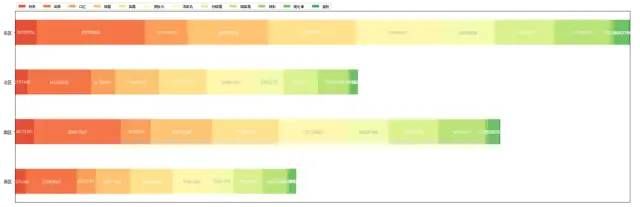
图表说明:东部地区占市场份额的35%左右,份额最低的是西部地区。
area_names = list(total_data.商品小类.unique())
groups_priv= total_data.groupby(['所在省份','商品小类'])
results = {}
for i,j in groups_priv:
money = int(j.金额.sum())
if i[0] in results.keys():
results[i[0]][i[1]] = money
else:
results[i[0]] = {}
for cate in category_names:
results[i[0]][cate] = 0
results[i[0]]['口红'] = money
results= {key_data:list(values_data.values()) for key_data,values_data in results.items()}
def survey2(results, category_names):
labels = list(results.keys())
data = np.array(list(results.values()))
data_cum = data.cumsum(axis=1)
category_colors = plt.get_cmap('RdYlGn')(
np.linspace(0.15, 0.85, data.shape[1]))
fig, ax = plt.subplots(figsize=(25,20))
ax.invert_yaxis()
ax.xaxis.set_visible(False)
ax.set_xlim(0, np.sum(data, axis=1).max())
for i, (colname, color) in enumerate(zip(category_names, category_colors)):
widths = data[:, i]
starts = data_cum[:, i] - widths
ax.barh(labels, widths, left=starts, height=0.5,
label=colname, color=color)
xcenters = starts + widths / 2
ax.legend(ncol=len(category_names), bbox_to_anchor=(0, 1),
loc='lower left', fontsize='small')
return fig, ax
survey2(results, area_names)
plt.show()
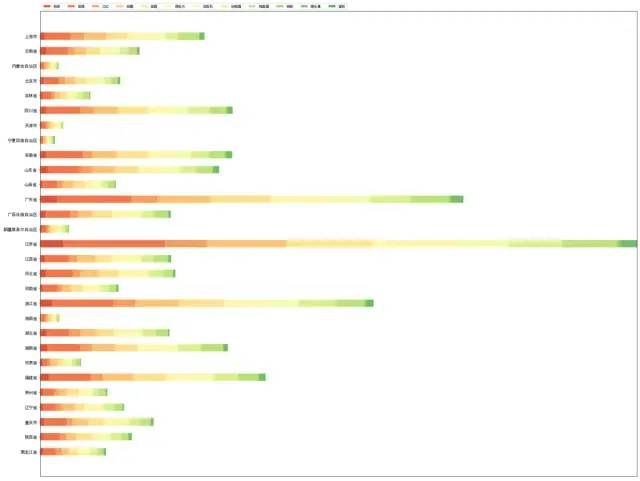
图表说明:江苏销售额第一,其次是广东省;销售额最低的是宁夏、内蒙、海南
import numpy as np
import matplotlib.pyplot as plt
category_names = list(total_data.商品小类.unique())
groups_small_category= total_data.groupby(['月份','商品小类'])
results = {}
for i,j in groups_small_category:
money = int(j.金额.sum())
if i[0] in results.keys():
results[i[0]][i[1]] = money
else:
results[i[0]] = {}
for cate in category_names:
results[i[0]][cate] = 0
results[i[0]]['口红'] = money
results= {key_data:list(values_data.values()) for key_data,values_data in results.items()}
def survey(results, category_names):
labels = list(results.keys())
data = np.array(list(results.values()))
data_cum = data.cumsum(axis=1)
category_colors = plt.get_cmap('RdYlGn')(
np.linspace(0.15, 0.85, data.shape[1]))
fig, ax = plt.subplots(figsize=(25,8))
ax.invert_yaxis()
ax.xaxis.set_visible(False)
ax.set_xlim(0, np.sum(data, axis=1).max())
for i, (colname, color) in enumerate(zip(category_names, category_colors)):
widths = data[:, i]
starts = data_cum[:, i] - widths
ax.barh(labels, widths, left=starts, height=0.5,
label=colname, color=color)
xcenters = starts + widths / 2
# r, g, b, _ = color
# text_color = 'white' if r * g * b < 0.5 else 'darkgrey'
# for y, (x, c) in enumerate(zip(xcenters, widths)):
# ax.text(x, y, str(int(c)), ha='center', va='center')
ax.legend(ncol=len(category_names), bbox_to_anchor=(0, 1),
loc='lower left', fontsize='small')
return fig, ax
survey(results, category_names)
plt.show()
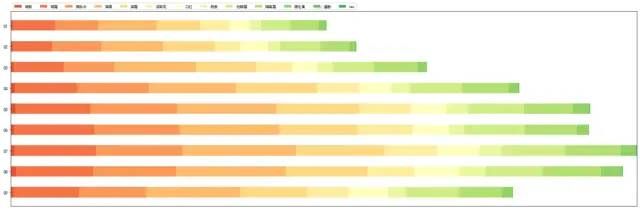
图表说明:眼霜、爽肤水、面膜:4,5,6,7,8月份需求量最大;粉底、防晒霜、隔离霜、睫毛膏、蜜粉1,2,3月份需求量最大。
data_user_buy=total_data.groupby('客户编码')['订单编码'].count()
data_user_buy
plt.figure(figsize=(10,4),dpi=80)
plt.hist(data_user_buy,color='#FFEC8B')
plt.title('用户购买次数分布',fontsize=16)
plt.xlabel('购买次数')
plt.ylabel('用户数')
plt.show()
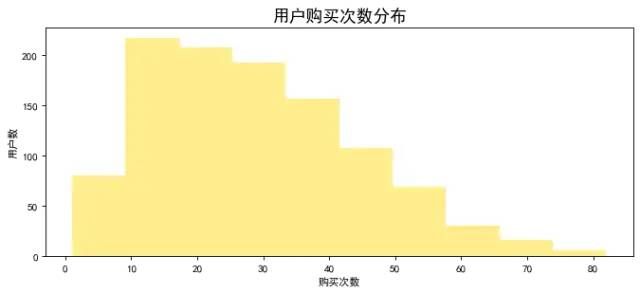
图表说明:大部分用户购买次数在10次-35次之间,极少部分用户购买次数80次以上
date_rebuy=total_data.groupby('客户编码')['订单日期'].apply(lambda x:len(x.unique())).rename('rebuy_count')
date_rebuy
print('复购率:',round(date_rebuy[date_rebuy>=2].count()/date_rebuy.count(),4))
![]()
total_data['时间标签'] = total_data['订单日期'].astype(str).str[:7]
total_data = total_data[total_data['时间标签']!='2050-06']
total_data['时间标签'].value_counts().sort_index()
total_data = total_data.sort_values(by='时间标签')
month_lst = total_data['时间标签'].unique()
final=pd.DataFrame()
final
#引入时间标签
for i in range(len(month_lst)-1):
#构造和月份一样长的列表,方便后续格式统一
count = [0] * len(month_lst)
#筛选出当月订单,并按客户昵称分组
target_month = total_data.loc[total_data['时间标签']==month_lst[i],:]
target_users = target_month.groupby('客户编码')['金额'].sum().reset_index()
#如果是第一个月份,则跳过(因为不需要和历史数据验证是否为新增客户)
if i==0:
new_target_users = target_month.groupby('客户编码')['金额'].sum().reset_index()
else:
#如果不是,找到之前的历史订单
history = total_data.loc[total_data['时间标签'].isin(month_lst[:i]),:]
#筛选出未在历史订单出现过的新增客户
new_target_users = target_users.loc[target_users['客户编码'].isin(history['客户编码']) == False,:]
#当月新增客户数放在第一个值中
count[0] = len(new_target_users)
#以月为单位,循环遍历,计算留存情况
for j,ct in zip(range(i + 1,len(month_lst)),range(1,len(month_lst))):
#下一个月的订单
next_month = total_data.loc[total_data['时间标签'] == month_lst[j],:]
next_users = next_month.groupby('客户编码')['金额'].sum().reset_index()
#计算在该月仍然留存的客户数量
isin = new_target_users['客户编码'].isin(next_users['客户编码']).sum()
count[ct] = isin
#格式转置
result = pd.DataFrame({month_lst[i]:count}).T
#合并
final = pd.concat([final,result])
final.columns = ['当月新增','+1月','+2月','+3月','+4月','+5月','+6月','+7月','+8月']
result = final.divide(final['当月新增'],axis=0).iloc[:]
result['当月新增'] = final['当月新增']
result.round(2)
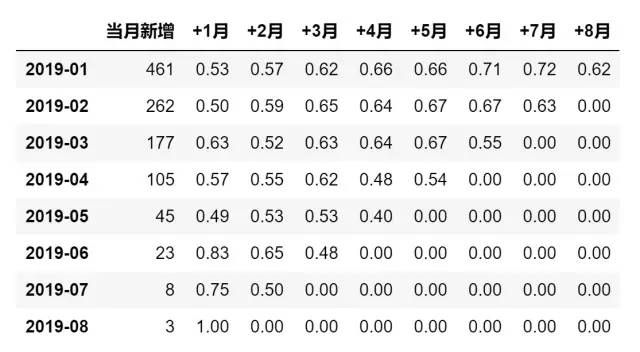
同期群分析
图表说明:由新增用户情况看,新用户逐月明显减少;留存率在1月-5月平均在50%,6月-8月留存率上升明显。
结论与建议
1、从销售额趋势来看,整体是上升趋势,但是从8月份销售额突然下降,可能因为到淡季,需进一步确认原因;
2、商品销售额,用户对护肤品具有强烈的需求,尤其是面膜,爽肤水、面霜、眼霜。较低需求的是蜜粉。可以把高需求产品,组合成礼盒等套装活动;
3、商品销售建议:眼霜、爽肤水、面膜:4,5,6,7,8月需求最大;粉底、防晒霜、隔离霜、睫毛膏、蜜粉1,2,3月需求最大。以上说明用户购买特定产品具有周期性;
4、从地域来看,东部地区是消费的主力军,其中江苏省、广东省、浙江省的销售额最大。可以增大市场投放量;也可以考虑在该地区建仓,节省物流等成本;
5、用户:重点维护购买次数在10次-35次之间的用户群体;
6、留存率在99%,证明用户对产品有一定的依赖性;
7、从同期群分析来看,新用户明显减少,应考虑拉新,增加平台新用户(主播带货等);

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: