CentOS 6虚拟机Hadoop安装教程
前言
本人初学hadoop,在安装配置环境时发现网上大部分博客的教程都不太完善,所以我结合了这些博客内容和老师的讲解写了下面这一份教程,这些操作都是本人经过尝试确认过没有问题的操作(如果有问题的话希望大家能够指出 )在安装中有什么注意点我都会提,希望能够对各位有帮助
在 h a d o o p hadoop hadoop集群配置时,需要至少两台机子,但有些配置都是相同的,所以以下操作可以在Master主机完成后用虚拟机的克隆即可,之后只需要修改几个配置即可,这些在后面内容都有说明
下面是具体操作
1、创建hadoop用户
su # 以root用户登陆
# useradd -m hadoop -s /bin/bash # 创建新用户hadoop
passwd hadoop #修改hadoop用户的密码
2、虚拟机网络配置
1、查看虚拟机的ip、子网掩码和网关
VMware顶部查看网络编辑器

查看VMnet8的子网ip和子网掩码
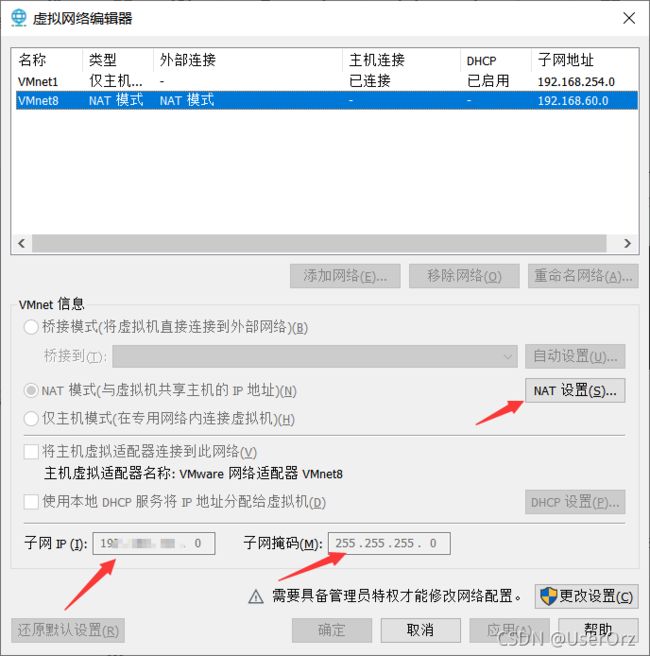
点击NAT设置,记住网关,这些后面都是要用的

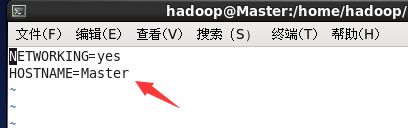
2、修改主机名
主机名在每台机子都不一样,例如我叫Master,Slave1,Slave2,这些名字可以任意,注意区分每个节点的名字,这里可以先在一台机子上修改,后面克隆虚拟机后再修改即可。
vi /etc/sysconfig/network
3、配置ip地址
(1)查看网卡名
ifconfig -a

(2)查看mac地址
cat /etc/udev/rules.d/70-persistent-net.rules
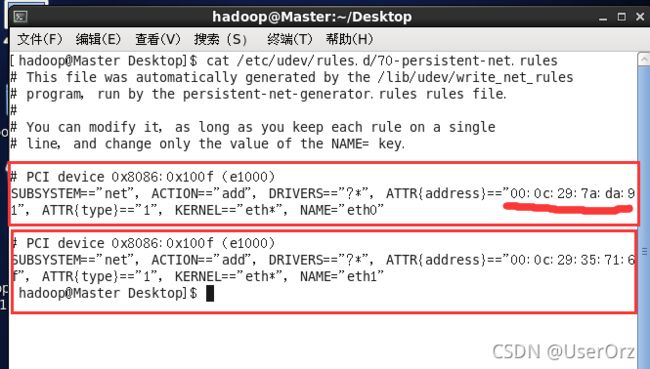
如果是克隆过来的虚拟机可能会发现多了块网卡,记住下面的eth1的mac地址,划线部分是原虚拟机的mac地址
(3)删除多余的mac地址信息
vi /etc/udev/rules.d/70-persistent-net.rules
把下面圈住的内容的eth1改成eht0,另一个删除
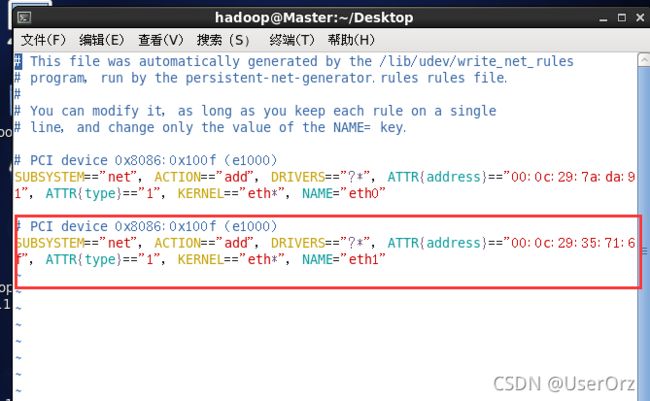
(4)修改ip地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
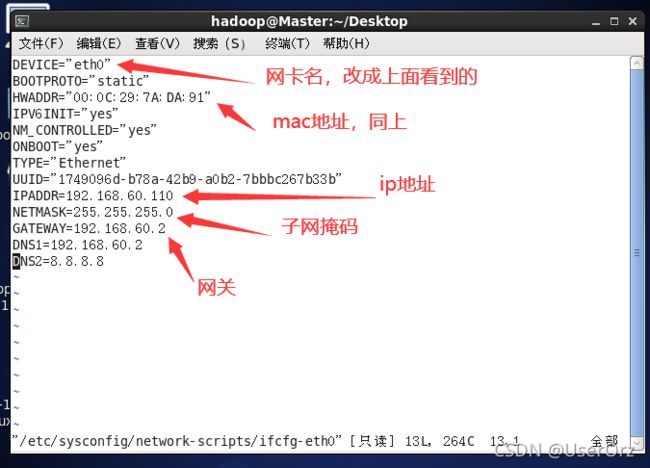
注意ip地址要和上面查看的相同,最后这个 . 110 .110 .110可以是任意的,注意不要和其他ip冲突了
几台机子的末尾要不同,例如我这里是 . 110 , . 111 .110,.111 .110,.111和 . 112 .112 .112
网卡名、mac地址、子网掩码和网关都是填查看到的,DNS1和网关填一样的
其他的除了UUID不要动,都改成我上面的,没有就加上
4、修改节点的IP映射:
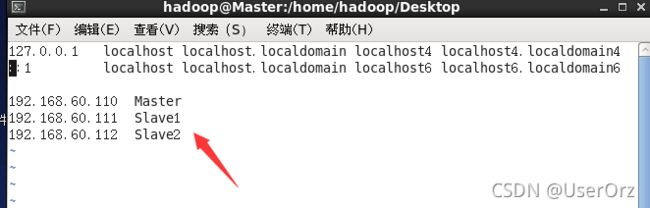
sudo vim /etc/hosts
第一二行是系统原有的,如果有多余的要删除
添加的信息左边对应上面修改的ip地址,右边是主机名,修改完成后需要重启一下
记得添加所有的机子ip和对应的主机名
5、重启网卡
service network restart

6、关闭防火墙
chkconfig iptables off
7、检查是否成功配置
配置好后执行下如下命令,如果ping不通后面操作无法执行
ping www.baidu.com
3、安装java环境
(1)查看jdk版本
CentOS一般是自带java环境的,如果想查看当前jdk版本可以用下面的命令
java -version
或
rpm -qa | grep jdk
如果没有显示就代表没有安装java环境
(2)卸载jdk
先用which java查看安装路径
which java
卸载java
rm -rf /usr/java/
卸载完成之后查看是否卸载完毕
java -version
java
javac
(3)下载安装jdk
- 可以使用yum命令下载,后面跟的是版本号
sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
过程中会让输入[y/n]一直按y即可
如果你的yum用不了,那是centos6的支持给官方停掉了,可以看这个博客解决
https://zhuanlan.zhihu.com/p/338873211
- 也可以在主机下好后CTRL+CV粘贴进入
下好的gz包直接双击安装即可
(4)执行下面命令查看安装路径
rpm -ql jdk1.8.0_60 | grep '/bin/javac'

(5)配置java环境变量
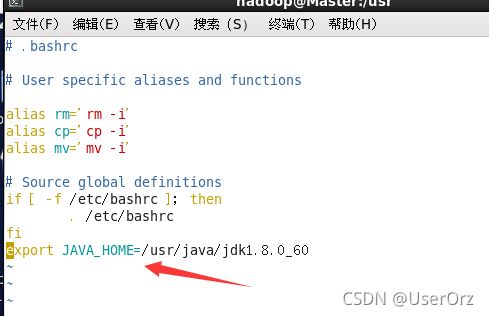
vim ~/.bashrc
在文件的最后一行加上JDK的路径
export JAVA_HOME=/usr/java/jdk1.8.0_60
使上面的设置生效
source ~/.bashrc
最后检查一下是否设置正确
echo $JAVA_HOME
java -version
$JAVA_HOME/bin/java -version # 与直接执行 java -version 一样
4、下载Hadoop
这里我是下好后ctrl+cv粘贴到虚拟机内
所以直接解压安装即可
$ sudo tar -zxf /home/hadoop/Desktop/hadoop-2.6.0-cdh5.11.2.tar.gz -C /usr/local # 解压到/usr/local中,也可以选择其他路径,要记住这个路径
$ cd /usr/local/
$ sudo mv /home/hadoop/Desktop/hadoop-2.6.0-cdh5.11.2 /home/hadoop/Desktop/hadoop # 将文件夹名改为hadoop
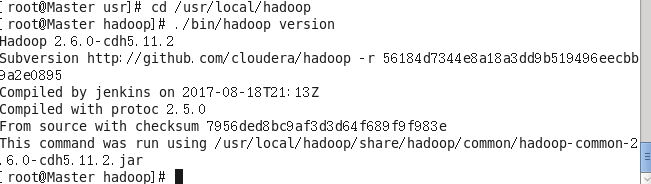
Hadoop解压后即可使用,下面命令检查Hadoop是否可用
cd /usr/local/hadoop
./bin/hadoop version
如果可用会输出下面的信息
5、Hadoop集群配置
(1)配置环境变量
vi /etc/profile
在文件最后一行添加hadoop的路径,注意这里/usr/local是解压hadoop选择的路径
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
(2)修改分布式环境配置文件
分布式环境需要修改 slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 这五个文件才能正常启动
- 进入配置文件所在目录
cd /usr/local/hadoop/etc/hadoop/

可以看到要修改的五个文件都在这,这里hadoopdata是后面创建的,开始并没有
这里要创建几个文件夹,后面配置文件要用
mkdir hadoopdata
cd hadoopdata
mkdir nn dn yarn log
#ls查看是否创建成功
- 修改 core-site.xml的配置
vi core-site.xml
进入文件,将configuration内的内容改为下面的
<configuration>
<property>
<name>fs.defaultFS</name> #hdfs访问的唯一入口
<value>hdfs://Master:8020</value> #Master是集群的入口
</property>
</configuration>
- 修改hdfs-site.xml的配置
vi hdfs-site.xml
进入文件,将configuration内的内容改为下面的 ,要注意hadoop的安装路径改成自己的路径
<configuration>
<property>
<name>dfs.permissions.superusergroup</name>#超级用户组,设置权限方便
<value>hadoop</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value> /usr/local/hadoop/etc/hadoop/hadoopdata/nn</value> #hadoop的安装目录
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value> /usr/local/hadoop/etc/hadoop/hadoopdata/dn</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>Master:50070</value>
<description>
The address and the base port on which the dfsNameNode Web UI will listen.
</description>
</property>
<property>
<name>dfs.secondary.http-address</name>
<value>Slave2:50090</value>
<description>
The address and the base port on which the dfsNameNode Web UI will listen.
</description>
</property>
</configuration>
- 修改mapred-site.xml的配置
因为开始只提供了一个mapred-site.xml.template模板,所以要新建一个mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml #拷贝文件
vi hdfs-site.xml
进入文件,将configuration内的内容改为下面的
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 修改yarn-site.xml的配置
vi yarn-site.xml
进入文件,将configuration内的内容改为下面的 ,要注意hadoop的安装路径改成自己的路径
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Slave2</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,
$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,
$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,
$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*
</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value> /usr/local/hadoop/etc/hadoop/hadoopdata/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value> /usr/local/hadoop/etc/hadoop/hadoopdata/yarn/logs</value>
</property>
<property>
<name>yarn.log.aggregation-enable</name>
<value>true</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/usr/local/hadoop/etc/hadoop/hadoopdata/log/hadoop-yarn/apps</value>
</property>
</configuration>
- 将主机名添加进slaves
vi slaves
添加所有的机子的主机名
Master
Slave1
Slave2
ps:这五个文件的修改是否成功要等克隆完虚拟机才能验证,所以最好检查几遍
如果克隆后出现错误可以现在一台机子修改,使用scp命令将hadoopdata发送到其他机子
scp /usr/local/hadoop/etc/hadoop/hadoopdata hadoop@Salve1:/usr/local/hadoop/etc/hadoop/
‘@’后面的是发送到哪台机子的主机名,‘:’后的是送到的具体目录
(3)克隆虚拟机
到这里单机版的Hadoop就安装完成了,使用虚拟机克隆另外两台机子

克隆是傻瓜式的下一步即可,注意这里要选择完整克隆(我没有尝试过链接克隆

克隆完成后只需要修改下面几个配置文件即可
- 改/etc/sysconfig/network的主机名
- 改/etc/sysconfig/network-scripts/ifcfg-eth0的IP和网卡
- 重启网卡后检查能否ping通
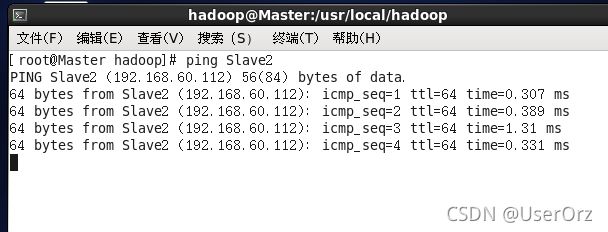
完成后在各结点使用如下命令,如果不能ping通检查各机子ip配置
ping Master
ping Slave1
ping Slave2
按ctrl+c 停止ping命令
例如我在Master上ping Slave2
(4)ssh无密码登陆
这个操作是要让 Master 节点可以无密码 SSH 登陆到各个 Slave 节点上
注意这里要区分root用户和hadoop用户,每个用户生成的key都只能让自己使用
在hadoop用户下输入下面命令,之后按回车和y即可。这一步所有机子都要执行
ssh-keygen -t rsa

可以看到key保留到了/home/hadoop/.ssh/下
在Slave1和Slave2执行
scp /home/hadoop/.ssh/id_rsa.pub hadoop@Master:/home/hadoop/.ssh/id_rsa.pub1 #Slave1执行
scp /home/hadoop/.ssh/id_rsa.pub hadoop@Master:/home/hadoop/.ssh/id_rsa.pub2 #Slave2执行
接下来在Master机子下执行,这一步使所有主机相互信任(不需要密码登陆)
cd /home/hadoop/.ssh
cat id_rsa.pub* > authorized_keys
scp /home/hadoop/.ssh/authorized_keys hadoop@Slave1:/home/hadoop/.ssh/authorized_keys
scp /home/hadoop/.ssh/authorized_keys hadoop@Slave2:/home/hadoop/.ssh/authorized_keys
最后修改文件权限,在所有机子上执行
chmod 700 /home/hadoop/.ssh
chmod 600 /home/hadoop/.ssh/authorized_keys
接下来验证是否操作成功,如果相互都能免密登陆就完成了
ssh Master
ssh Slave1
ssh Slave2
!!!注意这只是在hadoop用户下相互免密登陆,在root用户下要按照上述流程再操作一遍
(5)格式化namenode
这里只需要在主机Master上操作,成功后会出现下面图片的Exiting with status 0,如果没有需要检查那五个配置文件
hadoop namenode -format

(6)启动hadoop相关服务
Master操作
cd /usr/local/hadoop/sbin
./hadoop-daemon.sh start namenode
./hadoop-daemon.sh start datanode
./yarn-daemon.sh start nodemanager
检查是否开启成功,后面几个的检查同理
jps

如果有这几个进程说明启动成功,如果启动失败去检查那五个配置文件
Slave1操作
可以直接在Slave1上操作,也可以通过ssh链接Slave1,如果连接使用下面命令
ssh Slave1
cd /usr/local/hadoop/sbin
./hadoop-daemon.sh start datanode
./hadoop-daemon.sh start secondarynamenode
./yarn-daemon.sh start nodemanager
Slave2操作
`
cd /usr/local/hadoop/sbin
./hadoop-daemon.sh start datanode
./yarn-daemon.sh start nodemanager
./yarn-daemon.sh start resourcemanager
(7)验证集群是否配置成功
Master节点在浏览器中输入
http:Master:50070
如果出现下面这样的页面说明配置成功
