Redis之底层数据结构
一 Redis数据结构
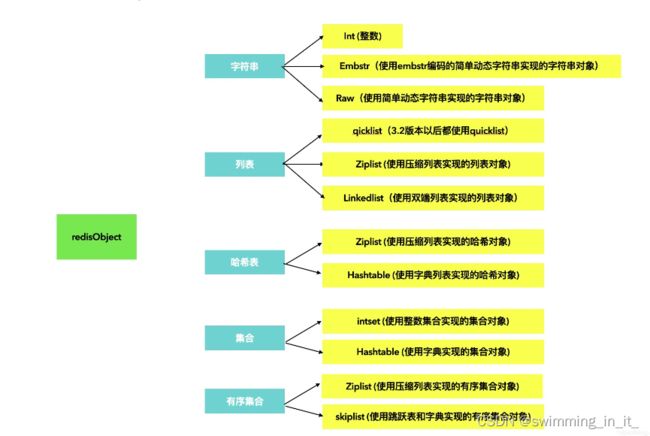
Redis底层数据结构有三层意思:
- 从Redis本身数据存储的结构层面来看,Redis数据结构是一个HashMap。
- 从使用者角度来看,Redis的数据结构是String,List,Hash,Set,Sorted Set。
- 从内部实现角度来看,Redis的数据结构是ict,sds,ziplist,quicklist,skiplist,intset。
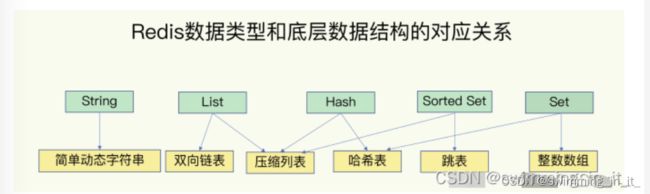
这五种数据类型分别对应以下几种数据结构:

如图所示:
- String的底层是:简单动态字符串
- List的底层是:双向链表和压缩列表。
- Hash的底层是:压缩链表和哈希表
- Set底层是:整数数组和哈希表。
- Sort Set底层是:压缩链表和跳表。
1.Redis哈希表如何实现
Redis是一个k-v的数据库。为了实现从key到value的快速访问,Redis使用了一个哈希表来保存所有的键值对。
- 一个哈希表,本身就是一个数组,数组的每个元素称为一个哈希桶。
- 不管是键类型还是值类型,哈希桶内的元素保存的都不是值本身,而是指向具体值的指针。
如下图中可以看到,哈希桶中的entry元素中保存了key和value指针,分别指向了实际的键和值,这样一来,即使值是一个集合,也可以通过*value指针被查找到:
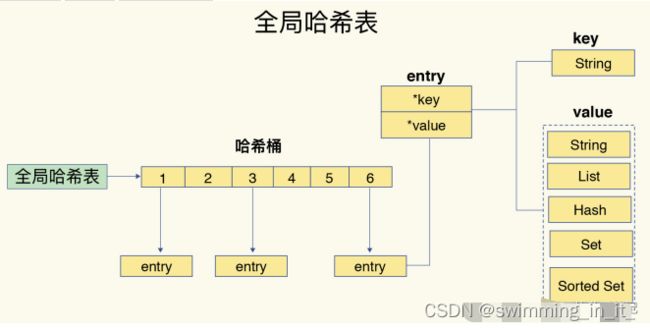
因为这个哈希表保存了所有的键值对,所以,它也叫做全局哈希表。
- 哈希表的最大好处就是让我们可以用O(1)的时间复杂度来快速查找到键值对----我们只需要计算键的哈希值,就可以知道它对应的哈希桶位置,然后就可以访问相应的entry元素。
- 这个查找过程主要依赖于哈希计算,和数据量的多少并没有直接关系。也就是说,不管哈希表里有10万个键还是 100 万个键,我们只需要一次计算就能找到相应的键。
- 也就是说,整个数据库就是一个全局hash表,而hash表的时间复杂度就是O(1),只需要计算每个键的hash值,就知道对应的hash桶的位置,定位桶里面的entry找到对应数据,这个也是redis块的原因之一。
2.Redis哈希冲突
1,什么是hash冲突?
哈希冲突,也就是指,两个key的哈希值和哈希桶计算对应关系时,正好落在了同一个哈希桶中。毕竟,哈希桶的个数通常要少于key的数量,hash冲突是不可避免。
2,hash冲突如何解决?
Redis解决哈希冲突的方式,就是链式哈希:所谓的链式哈希,就是指同一个哈希桶中的多个元素用一个链表来保存,它们之间一次用指针连接。如下图:
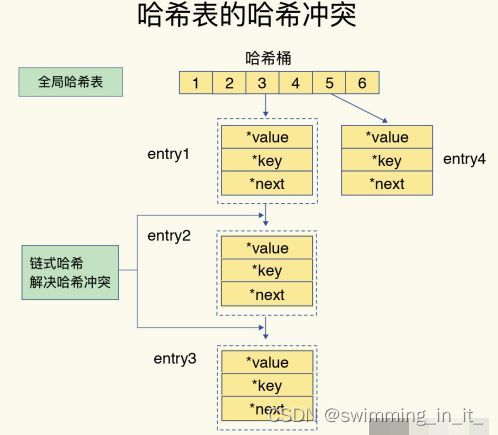
图中的entry1、entry2 和 entry3 都需要保存在哈希桶 3 中,导致了哈希冲突。此时,entry1 元素会通过一个next指针指向 entry2,同样,entry2 也会通过next指针指向entry3。这样一来,即使哈希桶 3 中的元素有 100 个,我们也可以通过 entry 元素中的指针,把它们连起来。这就形成了一个链表,也叫作哈希冲突链。
3,渐进式rehash
上面说过,哈希冲突的解决办法是hash链表,但是hash链表中如果hash冲突链越来越长,肯定会导致redis的性能下降,解决办法是什么尼?也就是渐进式rehash。
为了使得rehash操作更加高效,redis默认使用了两个全局哈希表:哈希表1和哈希表2.一开始,当你刚插入数据时,默认使用哈希表1,此时的哈希表2并没有被分配空间。随着数据逐步增多,redis开始执行rehash,这个过程分为三步:
- 把哈希表2分配更大的空间,比如是当前哈希表1大小的两倍
- 把哈希表1中的数据重新映射并拷贝到哈希表2中
- 释放哈希表1的空间
至此,我们就可以从哈希表1切换到哈希表2,用增大的哈希表2保存更多的数据,而原来的哈希表1操作留作下一次rehash扩容备用。
上面步骤有一个问题,那就是第二步涉及大量的数据拷贝,如果一次性把哈希表1中的数据都迁移完,会造成redis线程阻塞,无法服务其他请求。此时,redis就无法快速访问数据了。为了避免这个问题,redis采用了渐进式rehash。
简单来说就是在第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的entries。如下图所示:
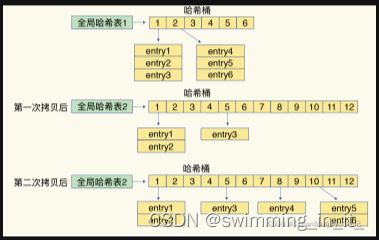
这样就巧妙地把一次性大量拷贝的开销,分摊到了多次处理请求的过程中,避免了耗时操作,保证了数据的快速访问。另外,渐进式rehash执行时,除了根据键值对的操作来进行数据迁移,redis本身还会有一群定时任务在执行rehash,如果没有键值对操作,这个定时任务会周期性的搬移一些数据到新的哈希表中。
二 Redis中value的内部实现数据结构
redis是通过对象来表示存储的数据的,redis 也是键值对存储的方式,那么每存储一条数据,redis至少会生成2个对象,一个是redisObject,用来描述具体数据的类型的,比如用的是那种数据类型,底层用了哪种数据结构,还有一个对象就是具体存储的数据。 这个存储对象数据就是通过redisObject这个对象的指针来指引的。
由于不同的数据类型,是有不同的内部实现且互相交叉的,具体如图所示:
下面我们将分开介绍简单动态字符串,双向列表,压缩列表,哈希表,跳表和整数数组。
1.RedisObject对象解析
上面说过redis本身在存储数据的时候会产生一个redisObject对象用来存储当前key对应的value的数据类型。其结构如下:
typedef struct redisObject
{
unsigned type:4;
unsigned encoding:4;
//对象最后一次被访问的时间
unsigned lru:REDIS_LRU_BITS;
/* lru time (relative to server.lruclock) */
int refcount;
//指向底层实现数据结构的指针
void *ptr;
} robj;
其中具体的值含义如下:
1,type: 字段表示value的对象类型,占4byte。目前包括REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。在执行 type key的时候能查看到对应的类型:

2,encoding 表示对象的内部编码,占4个比特。对于redis支持的每种类型都至少有两种编码,对于字符串有int、embsre、row三种
通过encoding属性,redis可以根据不同的使用场景来对对象使用不同的编码,大大提高的redis的灵活性和效率。命令:object encoding key;
3,lru: 记录对象最后一次被访问的时间,当配置了maxmemory和maxmemory-policy=valatile-lru | allkeys-lru时,用于辅助LRU算法删除键数据。可以使用 object idletime {key} 命令在不更新lru字段情况下查看当前键的空闲时间。开发提示:可以使用scan + object idletime 命令批量查询哪些键长时间未被访问,找出长时间不访问的键进行清理降低内存占用。
4,refcount字段: 记录当前对象被引用的次数,用于通过引用次数回收内存,当refcount=0时,可以安全回收当前对象空间。使用object refcount {key} 获取当前对象引用。当对象为整数且范围在[0-9999]时,Redis可以使用共享对象的方式来节省内存。具体细节见之后共享对象池部分。
5,ptr字段: 与对象的数据内容相关,如果是整数直接存储数据,否则表示指向数据的指针。Redis在3.0之后对值对象是字符串且长度<=39字节的数据,内部编码为embstr类型,字符串sds和redisObject一起分配,从而只要一次内存操作。开发提示:高并发写入场景中,在条件允许的情况下建议字符串长度控制在39字节以内,减少创建redisObject内存分配次数从而提高性能。eg:一个代表string的robj,它的ptr可能指向一个sds结构;一个代表list的robj,它的ptr可能指向一个quicklist。
2.SDS:简单动态字符串
1,实现原理
在c语音中,定义的字符串是不可被修改的,因此redis设计了可变的字符串长度对象,接SDS(simple dynamic string),实现原理:
struct sdshdr{
//记录buf数组中已存的字节数量,也就是sds保存的字符串长度
int len;
// buf数组中剩余可用的字节数量
int free;
//字节数组,用来存储字符串的
char buf[];
}
参数解析:
- len : 保存的字符串长度。获取字符串的长度就是O(1)
- free:剩余可用存储字符串的长度
- buf:保存字符串
这样设计的优点:
1):当用户修改字符串时sds api会先检查空间是否满足需求,如果满足,直接执行修改操作,如果不满足,将空间修改至满足需求的大小,然后再执行修改操作
2):空间预分配
- 如果修改后的sds的字符串小于1MB时(也就是len的长度小于1MB),那么程序会分配与len属性相同大小的未使用空间(就是再给未使用空间free也分配与len相同的空间) 例:字符串大小为600k,那么会分配600k给这个字符串使用,再分配600k的free空间在那。
- 惰性空间释放,当缩短sds的存储内容时,并不会立即使用内存重分配来回收字符串缩短后的空间,而是通过free将空闲的空间记录起来,等待将来使用。真正需要释放内存的时候,通过调用api来释放内存
- 通过空间预分配操作,redis有效的减少了执行字符串增长所需要的内存分配次数
- 如果修改后sds大于1MB时(也就是len的长度大于等于1MB),那么程序会分配1MB的未使用空间 例:字符串大小为3MB,那么会分配3MB给这个字符串使用,再分配1MB的free空间在那。
2,不同的编码实现
查看key的编码:object encoding key

1)int (REDIS_ENCODING_INT)整数值实现:
存储的数据是整数时,redis会将键值设置为int类型来进行存储,对应的编码类型是REDIS_ENCODING_INT。
2)embstr(REDIS_ENCODING_EMBSTR)
由sds实现 ,字节数 <= 39。存储的数据是字符串时,且字节数小于等于39 ,用的是embstr
优点:
1、创建字符串对象由两次变成了一次
2、连续的内存,更好的利用缓存优势
缺点:
1、由于是连续的空间,所以适合只读,如果修改的话,就会变成raw
2、由于是连续的空间,所以值适合小字符串
3)raw (REDIS_ENCODING_RAW)
由sds实现。字节数 > 39
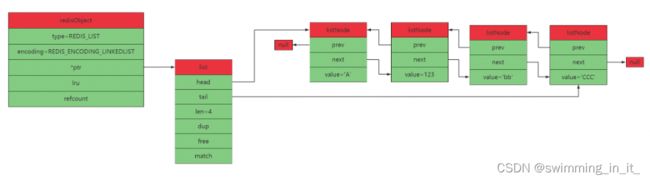
3.双向链表(LinkedList)
1,List结构:
typedef struct list {
listNode *head;
listNode *tail;
unsigned long len;
void *(*dup) (void *ptr);
void (*free) (void *ptr);
int (*match) (void *ptr,void *key);
} list;
其中:
head:表头节点
tail:表尾节点
len:包含的节点数量
(*dup)函数:节点值复制函数
(*free)函数:节点值释放函数
(*match)函数:节点值比较函数,比较值是否相等
2,ListNode链表节点结构:
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
其中:
prev:前置节点
next:后置节点
value:当前节点的值
3,linkedlist结构
拥有4个节点的linkedlist示意图如下:
4,总结:
- 双端:链表节点带有prev和next指针,获取某个节点的前置节点和后置节点的复杂度都是O(n)。
- 无环:表头节点的prev指针和表尾节点的next指针都指向NULL,对链表的访问以NULL为终点。
- 带表头指针和表尾指针:通过list结构的head指针和tail指针,程序获取链表的表头节点和表尾节点的复杂度为O(1)。
- 带链表长度计数器:程序使用list结构的len属性来对list持有的节点进行计数,程序获取链表中节点数量的复杂度为O(1)。
- 多态:链表节点使用void*指针来保存节点值,可以保存各种不同类型的值。
4.压缩列表(zipList)
1,使用场景
适用于长度较小的值,因为他是由连续的空间实现的。存取的效率高,内存占用小,但由于内存是连续的,在修改的时候要重新分配内存
在数据量比较小的时候使用的是ziplist
当list对象同时满足以下两个条件是,使用的ziplist编码
- list对象保存的所有字符串元素长度都小于64字节
- list对象保存的元素数量小于512个(redis版本3.2之前)之后是128个
2,ZipList结构
struct ziplist<T> {
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点
int16 zllength; // 元素个数
T[] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N)
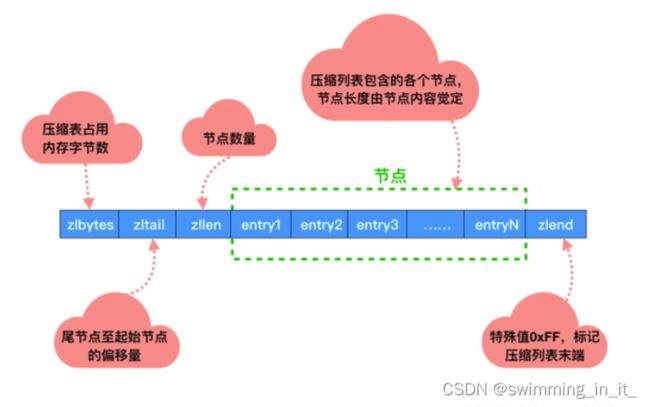
3,entry结构如下:
struct entry {
int<var> previous_entry_length; //前一个entry的字节长度
int<var> encoding; //当前元素编码类型
optional byte[] content; //当前元素内容
}
previous_entry__length记录前一个节点的长度,所以程序可以通过指针运算(当前节点的起始位置-previous_entry__length得到上一个节点的起始位置。),压缩列表从表尾遍历操作就是通过这个原理实现的。encoding属性记录节点的content属性所保存数据的类型以及长度。content保存节点的内容,可以是整数或者是字节数组。
当前entry的总字节数 = 下一个entry的previous_entry_length的值 = previous_entry_length字节数 + encoding字节数 + content字节数
- 如果前一节点的长度小于254字节,那么previous_entry__length属性的长度为1字节:前一节点的长度就保存在这一字节里面。
- 如果前一节点的长度大于等于254字节,那么previous_entry__length属性的长度为5字节:其属性的第一字节会被设置为0xFE(十进制254),而之后的四个字节长度则用于保存前一节点的长度。
4,连锁更新
连锁更新是由于previous_entry_length造成的。现在考虑这样一种情况:在一个压缩列表中,有多个连续的,长度介于250字节到253字节之间的节点e1-eN,如下图

因为e1到eN的长度都介于250字节到253字节之间,所以它们的previous_entry__length均为1字节。现在将一个长度大于254字节的节点插入到e1前面,如下图:

因为newE的长度大于254字节,所以他后面的e1的previous_entry__length长度需要从1字节变为5字节。但是由于e1原本的长度为250字节到253字节之间,这样子扩展后,长度必然超过254字节,就会导致后面的e2的previous_entry__length也需要改变…以此类推,后面的节点的previous_entry__length都需要扩展。Redis将这种特殊情况下产生的连续多次空间扩展操作称之为"连锁更新"。除了插入节点会发生"连锁更新"。删除节点也会,如下图:
 假设small及后面的节点的长度都介于250-253字节,big长度大于254字节,现在把samll删除了,导致e1的previous_entry__length需要扩展,后面依此类推,这样就会发生"连锁更新"。
假设small及后面的节点的长度都介于250-253字节,big长度大于254字节,现在把samll删除了,导致e1的previous_entry__length需要扩展,后面依此类推,这样就会发生"连锁更新"。
因为连锁更新在最坏的情况下需要对压缩列表执行N次空间重分配,而每次空间重分配的最坏复杂度为O(N),所以连锁更新的最坏复杂度为O(N^2)
5.quickList类型
1,quicklist简介
Redis 中的 list 数据类型在版本 3.2 之前,其底层的编码是 ziplist 和 linkedlist 实现的,但是在版本 3.2 之后,重新引入了一个 quicklist 的数据结构,list 底层都由 quicklist 实现。
在早期的设计中, 当 list 对象中元素的长度比较小或者数量比较少的时候,采用 ziplist 来存储,当 list 对象中元素的长度比较大或者数量比较多的时候,则会转而使用双向列表 linkedlist 来存储。
快速列表 quicklist 可以看成是用双向链表将若干小型的 ziplist 连接到一起组成的一种数据结构。
说白了就是把 ziplist 和 linkedlist 结合起来。每个双链表节点中保存一个 ziplist,然后每个 ziplist 中存一批list 中的数据(具体 ziplist 大小可配置),这样既可以避免大量链表指针带来的内存消耗,也可以避免 ziplist 更新导致的大量性能损耗,将大的 ziplist 化整为零。
2,zipList和linkedList的优缺点
双端链表 linkedlist 便于在表的两端进行 push 和 pop 操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
压缩列表 ziplist 存储在一段连续的内存上,所以存储效率很高。但是,它不利于修改操作,插入和删除操作需要频繁的申请和释放内存。特别是当 ziplist 长度很长的时候,一次 realloc 可能会导致大批量的数据拷贝。
因此,在 Redis3.2 以后,采用了 quicklist,quicklist 是综合考虑了时间效率与空间效率而引入的新型数据结构。
3,quickList的极端情况
情况一: 当 ziplist 节点过多的时候,quicklist 就会退化为双向链表。效率较差;效率最差时,一个 ziplist 中只包含一个 entry,即只有一个元素的双向链表。(增加了查询的时间复杂度)
情况二: 当 ziplist 元素个数过少时,quicklist 就会退化成为 ziplist,最极端的时候,就是 quicklist 中只有一个 ziplist 节点。(当增加数据时,ziplist 需要重新分配空间)
所以说:quicklist 其实就是综合考虑了时间和空间效率引入的新型数据结构。(使用 ziplist 能提高空间的使用率,使用 linkedlist 能够降低插入元素时的时间)
4,quickList结构
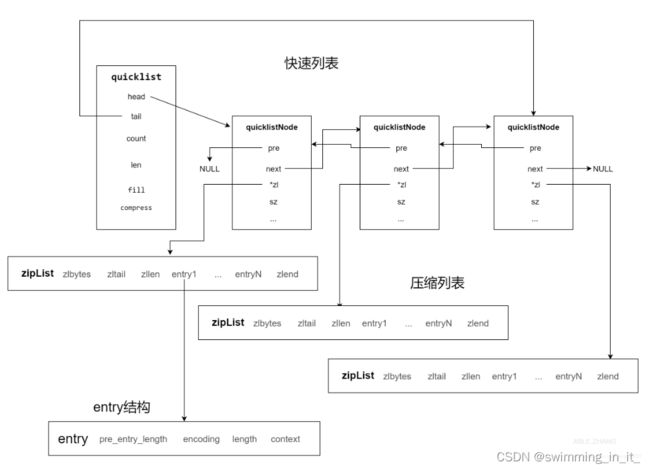
quicklist 作为一个链表结构,在它的数据结构中,是定义了整个 quicklist 的头、尾指针,这样一来,可以通过 quicklist 的数据结构,来快速定位到 quicklist 的链表头和链表尾。
typedef struct quicklist {
quicklistNode *head; // quicklist的链表头
quicklistNode *tail; // quicklist的链表尾
unsigned long count; // 所有ziplist中的总元素个数
unsigned long len; // quicklistNodes的个数
int fill : QL_FILL_BITS; // 单独解释
unsigned int compress : QL_COMP_BITS; // 具体含义是两端各有compress个节点不压缩
...
} quicklist;
fill用来指明每个quicklistNode中ziplist长度,当fill为正数时,表明每个ziplist最多含有的数据项数,当fill为负数时,如下:
- Length -1: 4k,即ziplist节点最大为4KB
- Length -2: 8k,即ziplist节点最大为8KB
- Length -3: 16k …
- Length -4: 32k
- Length -5: 64k
fill取负数时,必须大于等于-5。可以通过Redis修改参数list-max-ziplist-size配置节点所占内存大小。实际上每个ziplist节点所占的内存会在该值上下浮动。默认:list-max-ziplist-size -2
考虑quicklistNode节点个数较多时,我们经常访问的是两端的数据,为了进一步节省空间,Redis允许对中间的quicklistNode节点进行压缩,通过修改参数list-compress-depth进行配置,即设置compress参数,该项的具体含义是两端各有compress个节点不压缩。默认:list-compress-depth 0
5,quickListNode结构
typedef struct quicklistNode {
struct quicklistNode *prev; //前一个quicklistNode
struct quicklistNode *next; //后一个quicklistNode
unsigned char *zl; //quicklistNode指向的ziplist
unsigned int sz; //ziplist的字节大小
unsigned int count : 16; //ziplist中的元素个数
unsigned int encoding : 2; //编码格式,1:原生字节数组,2:使用LZF压缩存储
unsigned int container : 2; //container为quicklistNode节点zl指向的容器类型:1代表none,2代表使用ziplist存储数据
unsigned int recompress : 1; //代表这个节点之前是否是压缩节点,若是,则在使用压缩节点前先进行解压缩,使用后需要重新压缩,此外为1,代表是压缩节点;
unsigned int attempted_compress : 1; //数据能否被压缩,测试时使用;
unsigned int extra : 10; //预留的bit位
} quicklistNode;
6,quickListEntry结构
typedef struct quicklistEntry {
const quicklist *quicklist;//quicklist指向当前元素所在的quicklist;
quicklistNode *node;//node指向当前元素所在的quicklistNode结构;
unsigned char *zi;//zi指向当前元素所在的ziplist;
unsigned char *value;//value指向该节点的字符串内容;
long long longval;//为该节点的整型值;
unsigned int sz;//代表该节点的大小,与value配合使用;
int offset;//明该节点相对于整个ziplist的偏移量,即该节点是ziplist第多少个entry
} quicklistEntry;
7,quicklistIter结构
在redis的quicklist结构中,实现了自己的迭代器,用于遍历节点。
//quicklist的迭代器结构
typedef struct quicklistIter {
const quicklist *quicklist;//指向所属的quicklist的指针
quicklistNode *current;//指向当前迭代的quicklist节点的指针
unsigned char *zi;//指向当前quicklist节点中迭代的ziplist
long offset; //当前ziplist结构中的偏移量 /* offset in current ziplist */
int direction;//迭代方向
} quicklistIter;
8,数据压缩
quicklist每个节点的实际数据存储结构为ziplist,这种结构的主要优势在于节省存储空间。为了进一步降低ziplist所占用的空间,Redis允许对ziplist进一步压缩,Redis采用的压缩算法是LZF,压缩过后的数据可以分成多个片段,每个片段有2部分:
- 一部分是解释字段,另一部分是存放具体的数据字段。
- 解释字段可以占用1~3个字节,数据字段可能不存在。
解释字段|数据|…|解释字段|数据
LZF压缩的数据格式有3种,即解释字段有3种:
- 000LLLLL:字面型,解释字段占用1个字节,数据字段长度由解释字段后5位决定;L是数据长度字段,数据长度是长度字段组成的字面值加1。例如:0000 0001代表数据长度为2
- LLLooooo oooooooo:简短重复型,解释字段占用2个字节,没有数据字段,数据内容与前面数据内容重复,重复长度小于8;L是长度字段,数据长度为长度字段的字面值加2, o是偏移量字段,位置偏移量是偏移字段组成的字面值加1。例如:0010 0000 0000 0100代表与前面5字节处内容重复,重复3字节。
- 111ooooo LLLLLLLL oooooooo:批量重复型,解释字段占3个字节,没有数据字段,数据内容与前面内容重复;L是长度字段,数据长度为长度字段的字面值加9, o是偏移量字段,位置偏移量是偏移字段组成的字面值加1。例如:1110 0000 0000 0010 0001 0000代表与前面17字节处内容重复,重复11个字节。
//quicklistLZF结构:
typedef struct quicklistLZF {
unsigned int sz;//该压缩node的的总长度
char compressed[];//压缩后的数据片段(多个),每个数据片段由解释字段和数据字段组成
} quicklistLZF;
//当前ziplist未压缩长度存在于quicklistNode->sz字段中
//当ziplist被压缩时,node->zl字段将指向quicklistLZF
1)压缩:
LZF数据压缩的基本思想是:数据与前面重复的,记录重复位置以及重复长度,否则直接记录原始数据内容。
压缩算法的流程如下:遍历输入字符串,对当前字符及其后面2个字符进行散列运算,如果在Hash表中找到曾经出现的记录,则计算重复字节的长度以及位置,反之直接输出数据。
/*
* compressed format
*
* 000LLLLL ; literal, L+1=1..33 octets
* LLLooooo oooooooo ; backref L+1=1..7 octets, o+1=1..4096 offset
* 111ooooo LLLLLLLL oooooooo ; backref L+8 octets, o+1=1..4096 offset
*/
unsigned int
lzf_compress (const void *const in_data, unsigned int in_len, void *out_data, unsigned int out_len)
2)解压缩
根据LZF压缩后的数据格式,可以较为容易地实现LZF的解压缩。需要注意的是,可能存在重复数据与当前位置重叠的情况,例如在当前位置前的15个字节处,重复了20个字节,此时需要按位逐个复制。
unsigned int
lzf_decompress (const void *const in_data, unsigned int in_len, void *out_data, unsigned int out_len)
9,基本操作
1)插入元素
API定义:
/* Insert a new entry before or after existing entry 'entry'.
*
* If after==1, the new value is inserted after 'entry', otherwise
* the new value is inserted before 'entry'. */
REDIS_STATIC void _quicklistInsert(quicklist *quicklist, quicklistEntry *entry, void *value, const size_t sz, int after)
其中,参数after用于控制在entry之前或者之后插入。正因为 quicklist 采用了链表结构,所以当插入一个新的元素时,quicklist 首先就会检查插入位置的 ziplist 是否能容纳该元素,这是通过 _quicklistNodeAllowInsert 函数来完成判断的。
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) {
if (unlikely(!node))
return 0;
int ziplist_overhead;
/* size of previous offset */
if (sz < 254)
ziplist_overhead = 1;
else
ziplist_overhead = 5;
/* size of forward offset */
if (sz < 64)
ziplist_overhead += 1;
else if (likely(sz < 16384))
ziplist_overhead += 2;
else
ziplist_overhead += 5;
/* new_sz overestimates if 'sz' encodes to an integer type */
unsigned int new_sz = node->sz + sz + ziplist_overhead;
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill)))
return 1;
else if (!sizeMeetsSafetyLimit(new_sz))
return 0;
else if ((int)node->count < fill)
return 1;
else
return 0;
}
_quicklistNodeAllowInsert 函数会计算新插入元素后的大小(new_sz),这个大小等于 quicklistNode 的当前大小(node->sz)、插入元素的大小(sz),以及插入元素后 ziplist 的 prevlen 占用大小。在计算完大小之后,_quicklistNodeAllowInsert 函数会依次判断新插入的数据大小(sz)是否满足要求,即单个 ziplist 是否不超过 8KB,或是单个 ziplist 里的元素个数是否满足要求。
只要这里面的一个条件能满足,quicklist 就可以在当前的 quicklistNode 中插入新元素,否则 quicklist 就会新建一个 quicklistNode,以此来保存新插入的元素。这样一来,quicklist 通过控制每个 quicklistNode 中,ziplist 的大小或是元素个数,就有效减少了在 ziplist 中新增或修改元素后,发生连锁更新的情况,从而提供了更好的访问性能。
2)删除元素:
quicklist对于元素删除提供了删除单一元素以及删除区间元素2种方案。
1]:删除单一元素 :可以使用quicklist对外的接口quicklistDelEntry实现,也可以通过quicklistPop将头部或者尾部元素弹出。quicklistDelEntry函数调用底层quicklistDelIndex函数,该函数可以删除quicklistNode指向的ziplist中的某个元素,其中p指向ziplist中某个entry的起始位置。
quicklistPop可以弹出头部或者尾部元素,具体实现是通过ziplist的接口获取元素值,再通过上述的quicklistDelIndex将数据删除
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry) {
quicklistNode *prev = entry->node->prev;
quicklistNode *next = entry->node->next;
// 底层仍然通过quicklistDelIndex删除
int deleted_node = quicklistDelIndex((quicklist *)entry->quicklist,
entry->node, &entry->zi);
/* after delete, the zi is now invalid for any future usage. */
iter->zi = NULL;
/* If current node is deleted, we must update iterator node and offset. */
if (deleted_node) {
if (iter->direction == AL_START_HEAD) {
iter->current = next;
iter->offset = 0;
} else if (iter->direction == AL_START_TAIL) {
iter->current = prev;
iter->offset = -1;
}
}
}
2]:删除区间元素 :quicklist提供了quicklistDelRange接口,该函数可以从指定位置删除指定数量的元素
int quicklistDelRange(quicklist *quicklist, const long start, const long count)
start为需要删除的元素的起始位置,count为需要删除的元素个数。返回0代表没有删除任何元素,返回1并不代表删除了count个元素,因为count可能大于quicklist所有元素个数,故而只能代表操作成功。
总体删除逻辑为: 不管什么方式删除,最终都会通过ziplist来执行元素删除操作。先尝试删除该链表节点所指向的ziplist中的元素,如果ziplist中的元素已经为空了,就将该链表节点也删除掉。
3) 更改元素:
quicklist更改元素是基于index,主要的处理函数quicklistReplaceAtIndex。其基本思路是先删除原有元素,之后插入新的元素。quicklist不适合直接改变原有元素,主要由于其内部是ziplist结构,ziplist在内存中是连续存储的,当改变其中一个元素时,可能会影响后续元素。故而,quicklist采用先删除后插入的方案。
/* Replace quicklist entry at offset 'index' by 'data' with length 'sz'.
*
* Returns 1 if replace happened.
* Returns 0 if replace failed and no changes happened. */
int quicklistReplaceAtIndex(quicklist *quicklist, long index, void *data,
int sz) {
quicklistEntry entry;
if (likely(quicklistIndex(quicklist, index, &entry))) {
/* quicklistIndex provides an uncompressed node */
entry.node->zl = ziplistDelete(entry.node->zl, &entry.zi);
entry.node->zl = ziplistInsert(entry.node->zl, entry.zi, data, sz);
quicklistNodeUpdateSz(entry.node);
quicklistCompress(quicklist, entry.node);
return 1;
} else {
return 0;
}
}
4)查找元素:
quicklist查找元素主要是针对index,即通过元素在链表中的下标查找对应元素。基本思路是,首先找到index对应的数据所在的quicklistNode节点,之后调用ziplist的接口函数ziplistGet得到index对应的数据,源码中的处理函数为quicklistIndex。
int quicklistIndex(coquicklistnst quicklist *quicklist, const long long idx,
quicklistEntry *entry) {
quicklistNode *n;
unsigned long long accum = 0;
unsigned long long index;
int forward = idx < 0 ? 0 : 1; /* < 0 -> reverse, 0+ -> forward */
...
// 这里是在定位具体是在哪个quicklist节点
while (likely(n)) {
if ((accum + n->count) > index) {
break;
} else {
D("Skipping over (%p) %u at accum %lld", (void *)n, n->count,
accum);
accum += n->count;
n = forward ? n->next : n->prev;
}
}
...
// 最终还是利用ziplist获取元素
ziplistGet(entry->zi, &entry->value, &entry->sz, &entry->longval);
/* The caller will use our result, so we don't re-compress here.
* The caller can recompress or delete the node as needed. */
return 1;
}
idx为需要查找的下标,结果写入entry,返回0代表没有找到,1代表找到。其中idx可正可负,负数时代表从后往前找。遍历的逻辑还是比较简单,仍然是链表 + ziplist特性,不同的是每个链表节点存有ziplist元素个数,因此可以快速定位到目标链表节点,然后再通过ziplist的ziplistGet方法查询目标元素。
10,总结
总结
基于ziplist存在的问题,要避免ziplist列表太大问题,因此将大ziplist分成一系列小的ziplist是一种思路。quicklist是由链表组成的结构,其中每个链表节点中都存在一个ziplist。是由ziplist改进而来,充分利用链表 + ziplist特性
- quicklist是一个双端队列,在队首和队尾添加元素十分方便,时间复杂度O(1)
- quicklist的节点ziplist越小,越有可能造成更多的内存碎片。极端情况下,一个ziplist只有一个数据entry,也就退化成了linked list
- quicklist的节点ziplist越大,分配给ziplist的连续内存空间越困难。极端情况下,一个quicklist只有一个ziplist,也就退化成了ziplist因此,合理配置参数显得至关重要,不同场景可能需要不同配置;redis提供list-max-ziplist-size参数进行配置,默认-2,表示每个ziplist节点大小不超过8KB
6.哈希表(hashTable)
hashtable 编码的哈希对象使用字典dictht作为底层实现。字典是一种保存键值对的数据结构。下面来介绍下具体使用。
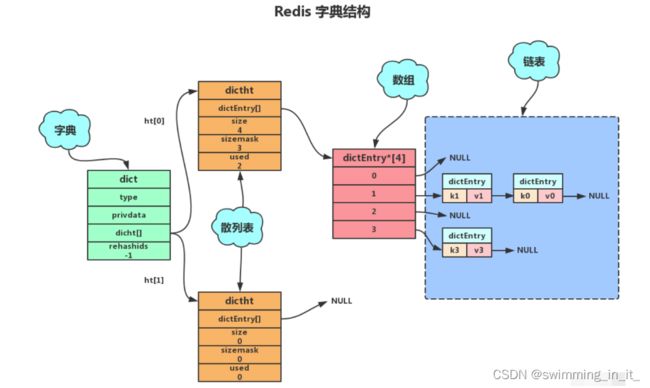
1,dict字典
// 字典 数据结构
typedef struct dict {//管理两个dictht,主要用于动态扩容。
//类型特定函数
dictType *type;
//私有数据:指向特定数据类型的数组;
void *privdata;
// 哈希表:包含了两个哈希表的数组,其中一个ht[0]保存哈希表,ht[1]只会在对ht[0]进行rehash时使用
dictht ht[2];
// rehash索引,当rehash不再进行是,值为 -1
long rehashidx; /* 扩容标志rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
2,dictht散列表
//定义一个hash桶,用来管理hashtable
typedef struct dictht {
// hash表数组,所谓的桶:其中一个数组元素都是一个指向哈希表节点的指针,每一个哈希表节点都保存了一对键值对。
dictEntry **table;
// hash表大小,元素个数
unsigned long size;
// hash表大小掩码,用于计算索引值,值总是size -1
unsigned long sizemask;
// 该hash表已有的节点数量
unsigned long used;
} dictht;
3,dictEntry散列表节点
//hash节点
typedef struct dictEntry {
//键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 指向下一个节点,解决碰撞冲突
struct dictEntry *next;
} dictEntry;
4,哈希冲突
具体解决方案和一.2中的哈希冲突解决办法一致
7.跳表(skiplist)
跳跃表(skiplist)是一种有序的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
Redis的跳跃表由zskiplistNode和zskiplist两个结构定义,zskiplistNode结构表示跳跃表节点,zskiplist保存跳跃表节点相关信息,比如节点的数量,以及指向表头和表尾节点的指针等。
1,zskiplist
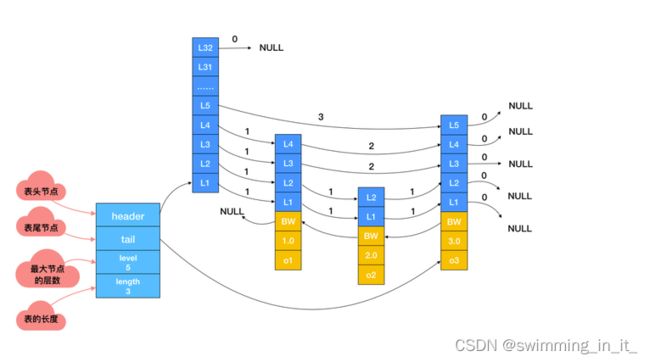
实际上,仅靠多个跳跃表节点就可以组成一个跳跃表,但是Redis使用了zskiplist结构来持有这些节点,这样就能够更方便地对整个跳跃表进行操作。比如快速访问表头和表尾节点,获得跳跃表节点数量等等。zskiplist结构定义如下:
typedef struct zskiplist {
// 表头节点和表尾节点
struct skiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 最大层数
int level;
} zskiplist;
2, zskiplistNode
typedef struct zskiplistNode {
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
下图是一个层高为5,包含4个跳跃表节点(1个表头节点和3个数据节点)组成的跳跃表:
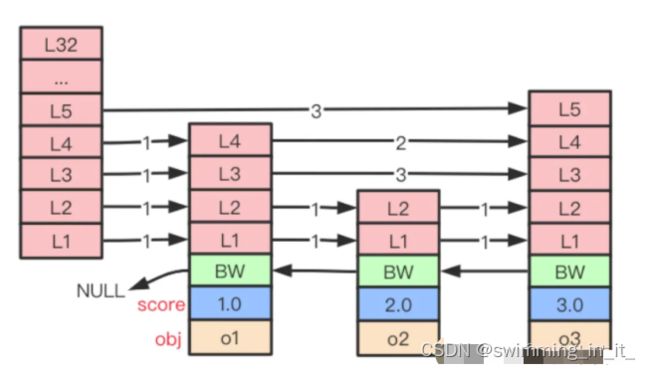
- 每次创建一个新的跳跃表节点的时候,会根据幂次定律(越大的数出现的概率越低)随机生成一个1-32之间的值作为当前节点的"层高"。每层元素都包含2个数据,前进指针和跨度。 前进指针:每层都有一个指向表尾方向的前进指针,用于从表头向表尾方向访问节点。 跨度:层的跨度用于记录两个节点之间的距离。
- 后退指针(BW) 节点的后退指针用于从表尾向表头方向访问节点,每个节点只有一个后退指针,所以每次只能后退一个节点。
- 分值和成员 节点的分值(score)是一个double类型的浮点数,跳跃表中所有节点都按分值从小到大排列。节点的成员(obj)是一个指针,指向一个字符串对象。在跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点的分值确实可以相同。
需要注意的是,表头节点不存储真实数据,并且层高固定为32,从表头节点第一个不为NULL最高层开始,就能实现快速查找。
8.整数集合(intset)
整数集合(intset)是Redis用于保存整数值的集合抽象数据结构,它可以保存类型为int16_t、int32_t或者int64_t的整数值,并且保证集合中的数据不会重复。Redis使用intset结构表示一个整数集合。
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
contents数组是整数集合的底层实现:整数集合的每个元素都是contents数组的一个数组项,各个项在数组中按值大小从小到大有序排列,并且数组中不包含重复项。虽然contents属性声明为int8_t类型的数组,但实际上,contents数组不保存任何int8_t类型的值,数组中真正保存的值类型取决于encoding。如果encoding属性值为INTSET_ENC_INT16,那么contents数组就是int16_t类型的数组,以此类推。
当新插入元素的类型比整数集合现有类型元素的类型大时,整数集合必须先升级,然后才能将新元素添加进来。这个过程分以下三步进行。
- 根据新元素类型,扩展整数集合底层数组空间大小。
- 将底层数组现有所有元素都转换为与新元素相同的类型,并且维持底层数组的有序性。
- 新元素添加到底层数组里面。
还有一点需要注意的是,整数集合不支持降级,一旦对数组进行了升级,编码就会一直保持升级后的状态。
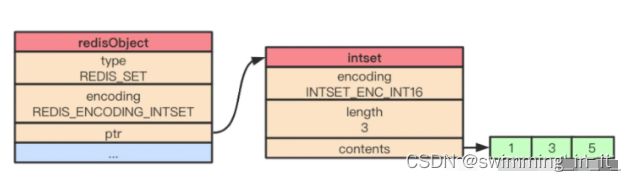
举个栗子,当我们执行SADD numbers 1 3 5向集合对象插入数据时,该集合对象在内存的结构如下:
10.小结
redis的底层数据结构,既包括redis中用来保存每个键和值的全局哈希表结构,也包括了支持集合类型实现的双向链表、压缩列表、整数数组、哈希表和跳表这五大底层结构。
redis为什么能够快速的操作键值对呢?
- 一方面是因为O(1)复杂度的哈希表被广泛使用,包括String、Hash、Set,它们的操作复杂度基本有哈希表决定
- 另一方面,sorted set也采用了O(logN)复杂度的跳表。
- 不过,集合类型的范围操作,因为要遍历底层数据结构,复杂度通常是O(N)。怎么解决呢?可以使用其他命令来替代,比如可以用SCAN来代替,避免在redis内部产生费时的全集合遍历操作。
- 而对于复杂度比较高的list类型,它的底层实现结构是双向链表和压缩列表,其操作的时间复杂度都是O(N),因此,建议因地制宜地使用 List 类型。例如,既然它的 POP/PUSH 效率很高,那么就将它主要用于 FIFO 队列场景,而不是作为一个可以随机读写的集合。