再探pytorch的Dataset和DataLoader
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
本文从分类、检测、分割三大任务的角度来剖析pytorch得dataset和dataloader源码,可以让初学者深刻理解每个参数的由来和使用,并轻松自定义dataset。
思考:在探究Dataset和DataLoader之前,需要明白一个事情,就是当我们不管做是分类、检测还是分割任务时,我们的数据集一定由很多张图片组成的,形状大小各异;那麽我们在使用pytorch时,图片是怎么以一个batch的形式进行打包的呢,形状不同怎么处理,数据格式有什么要求,Dataset类中的初始化参数transform如何自定义,并是怎么调用的,在哪里调用?训练时如何取出DataLoader中的数据的?带着种种疑问,开始Dataset和DataLoader的探索之旅吧!
Dataset探究
Dataset的定义
问题1:Dataset到底是什么,如何去调用?
我们通常见到的Dataset的定义如下图,VOCSegmentation()在这里其实是一个类。
voc_train = VOCSegmentation('F:\pytorch_yolov3\yolo3-pytorch',year='2007',image_set='train',transform=transform,target_transform=target_transform)自定义得Dataset类中,必有三个函数:__init__(),__getitem__(),__len__()函数,
__init__(self,...):是几乎类中都会有的一个初始化函数,会在类进行实例化时初始化一些变量,供类中其他函数使用
__getitem__(self, index):是python得magic method,一般如果想通过使用索引访问元素时,就可以在类中定义这个方法。
__len__():返回数据集的长度
凡是在类中定义了这个__getitem__ 方法,那么它的实例对象(假定为p),可以像这样p[key] 取值,当实例对象做p[key] 运算时,会调用类中的方法__getitem__。
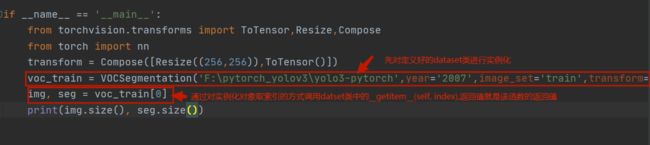
返回值为处理过后的img和seg
class VOCSegmentation(Dataset):
def __init__('F:\pytorch_yolov3\yolo3-pytorch',year='2007',image_set='train',transform=transform,target_transform=target_transform):
pass
def __getitem__(self, index):
pass
def __len__(self):
pass分类任务的Dataset
自定义分类Dataset
class MyDataset(Dataset): # 继承Dataset类
def __init__(self, txt_path, transform=None, target_transform=None): # 定义txt_path参数
fh = open(txt_path, 'r') # 读取txt文件
imgs = [] # 定义imgs的列表
for line in fh:
line = line.rstrip() # 默认删除的是空白符('\n', '\r', '\t', ' ')
words = line.split() # 默认以空格、换行(\n)、制表符(\t)进行分割,大多是"\"
imgs.append((words[0], int(words[1]))) # 存放进imgs列表中
self.imgs = imgs # 最主要就是要生成这个list, 然后DataLoader中给index,通过getitem读取图片数据
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index] # fn代表图片的路径,label代表标签
img = Image.open(fn).convert('RGB') # 像素值 0~255,在transfrom.totensor会除以255,使像素值变成 0~1 参考:https://blog.csdn.net/icamera0/article/details/50843172
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.imgs) # 返回图片的数量官方的MNIST类
def __init__(self, root, train=True, transform=None, download=False)
参数解析:
root:为数据集的路径,如果没找到本地路径,配合download使用,可以将download设置为True,会从网上为你下载数据
train:是一个boolean类型参数,用来定义数据使用的时train数据集还是test数据集,如果train为True,就会将train数据集路径加载进来,供后面读取数据使用。
download:boolean类型参数,如果为True,就会直接跳过本地数据集,去网上下载,下载后存放在当前工程目录下。
transform:可以是一个实例化对象,也可以使用torchvison.transforms.Compose来包裹一个含有多个实例化转换类对象的列表
注意:非常重要的是掌握transform参数需要的参数类型是什么,后面方便自己自定义transform,在自定义tranform前,先来看看pytorch官方自己定义的一些变换方法吧(变换都在torchvison.transforms.transforms.py中)。
transform解析
class CenterCrop(object):
"""Crops the given PIL Image at the center.
Args:
size (sequence or int): Desired output size of the crop. If size is an
int instead of sequence like (h, w), a square crop (size, size) is
made.
"""
def __init__(self, size):
if isinstance(size, numbers.Number):
self.size = (int(size), int(size))
else:
self.size = size
def __call__(self, img):
"""
Args:
img (PIL Image): Image to be cropped.
Returns:
PIL Image: Cropped image.
"""
return F.center_crop(img, self.size)
def __repr__(self):
return self.__class__.__name__ + '(size={0})'.format(self.size)以CenterCrop为例,可以看出是类的实现。类中包含三个方法
__init__(self, size):用于初始化必要的变量
__call__(self, img):为python的magic方法,在类中实现这一方法可以使该类的实例(对象)像函数一样被调用。默认情况下该方法在类中是没有被实现的。使用callable()方法可以判断某对象是否可以被调用。
__repr__(self):支持打印功能,可以使用print(实例化对象),返回变换类名包括初始化的一些参数信息。
class People(object):
def __init__(self,name):
self.name=name
def __call__(self):
print("hello "+self.name)
a = People('无忌!')
a.__call__() # 调用方法一
a() # 调用方法二
#两种调用方法等价
#__call__()方法的作用其实是把一个类的实例化对象变成了可调用对象,
#也就是说把一个类的实例化对象变成了可调用对象,只要类里实现了__call__()方法就行。
#如当类里没有实现__call__()时,此时的对象p 只是个类的实例,不是一个可调用的对象,
#当调用它时会报错:‘Person’ object is not callable.注意: __call__(self, img)方法中的参数是img,即图像,格式为PIL Image,所以一般是对图像做完各种图像变换之后再进行ToTensor()和Normalize()操作,顺序很重要,否则会报数据类型错误。__call__(self,img)的具体实现F.center_crop(img, self.size)在torchvision.transforms.functional.py中。
问题:transforms中的compose为何可以以列表的形式接受各种变换
代码解析
class Compose(object):
"""Composes several transforms together.
Args:
transforms (list of ``Transform`` objects): list of transforms to compose.
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])
"""
def __init__(self, transforms):
#先批量初始化变换方法
self.transforms = transforms
def __call__(self, img):
#__call__方法是python的魔法方法,会
#遍历list,得到第一个transforms.CenterCrop(10),每一个变换都是一个类,CenterCrop(10)
#对中心裁剪类进行了实例化,真正调用__call__()方法是在,__getitem__(self, index)方法中
#self.transform(img),返回变换后的img(循环顺序调用,像是一个管道,img从一边输入,从另一边
#另一边输出,输出的图像已经变成了我们想要的模样)
for t in self.transforms:
img = t(img)
return imgDataLoader
DataLoader的定义
问题:DataLoader到底是什么?
DataLoader也是以 类的方式实现的, DataLoader是一个可迭代对象,其类中实现了__iter__方法,因此在实例化DataLoader后,可以通过for循环的方式来迭代获取打包后的batch数据,在使用for循环遍历DataLoader时,会调用DataLoader里的__iter__方法,返回一个_SingleProcessDataLoaderIter(self)迭代器,后面每次迭代时会调用__next__方法获得下一批数据.
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, multiprocessing_context=None):参数解析:
dataset:自定义的数据集
batch_size:每次喂入网络几张图
shuffle:数据是否乱序
sampler:一个采样器
batch_sampler:以sampler为参数,在遍历dataloader时,会对采样器进行迭代产生一个batch的index
num_workers:使用几个进程来加载数据,默认是0,由主进程来加载数据
collate_fn:主要用来打包通过一个batch的index取到的数据,将img,target分开打包成tensor
collate_fn的参数可以自定义实现,因为pytorch官方提供的collate_fn函数只是将数据简单stack在一起,如果需要实现一些其他功能,可以自行定义,然后作为参数传给collate_fn.
DataLoader案例

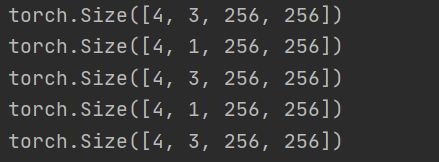
Dataset和DataLoader的关系


参考文献:
https://blog.51cto.com/u_15274944/2921682
https://zhuanlan.zhihu.com/p/35698470
https://zhuanlan.zhihu.com/p/27661382
https://zhuanlan.zhihu.com/p/359998425
https://blog.csdn.net/qq_28057379/article/details/115427052
https://zhuanlan.zhihu.com/p/30385675
https://cloud.tencent.com/developer/article/1728103
https://ai.deepshare.net/p/t_pc/course_pc_detail/video/v_5e1694ec1470e_SJ7JwMgA?product_id=p_5d552aea89dd9_CWCmRNUu&type=5