安卓机器学习框架学习:Android Neural Networks API (NNAPI)
Android Neural Networks API (NNAPI)
简介:
1、Android Neural Networks API (NNAPI) 是一个 Android C API,在 Android 设备上实现机器学习;
2、NNAPI 旨在为更高层级的机器学习框架(如 TensorFlow Lite 和 Caffe2)提供一个基本功能层,用来建立和训练神经网络;
3、搭载 Android 8.1(API 级别 27)或更高版本的所有 Android 设备上都提供该 API。
4、NNAPI 支持通过将 Android 设备中的数据应用到先前训练的开发者定义的模型来进行推断。
在设备上进行推断具备诸多优势:
- 延迟:您不需要通过网络连接发送请求并等待响应。例如,这对处理从相机传入的连续帧的视频应用至关重要。
- 可用性:即使在网络覆盖范围之外,应用也能运行。
- 速度:专用于神经网络处理的新硬件提供的计算速度明显快于单纯的通用 CPU。
- 隐私:数据不会离开 Android 设备。
- 费用:所有计算都在 Android 设备上执行,不需要服务器。
开发者还应在以下几个方面做出权衡取舍:
- 系统利用率:评估神经网络涉及大量的计算,而这可能会增加电池电量消耗。如果您担心自己的应用耗电量会增加(尤其是对于长时间运行的计算),应考虑监控电池运行状况。
- 应用大小:应注意模型的大小。模型可能会占用数 MB 的空间。如果在您的 APK 中绑定较大的模型会对用户造成过度影响,那么您可能需要考虑在应用安装后下载模型、使用较小的模型或在云端运行计算。NNAPI 未提供在云端运行模型的功能。
NNAPI 使用四个主要抽象概念:
-
模型:由数学运算和通过训练过程学习到的常量值构成的计算图。这些运算特定于神经网络。它们包括二维 (2D) 卷积、逻辑 (sigmoid) 激活函数、修正线性 (ReLU) 激活函数等。创建模型是一项同步操作。成功创建后,便可在线程和编译之间重用模型。在 NNAPI 中,模型表示为
ANeuralNetworksModel实例。 -
编译:表示用于将 NNAPI 模型编译到更低级别代码中的配置。创建编译是一项同步操作。成功创建后,便可在线程和执行之间重用编译。在 NNAPI 中,每个编译都表示为一个
ANeuralNetworksCompilation实例。 -
内存:表示共享内存、内存映射文件和类似内存缓冲区。使用内存缓冲区可让 NNAPI 运行时更高效地将数据传输到驱动程序。应用一般会创建一个共享内存缓冲区,其中包含定义模型所需的每个张量。您还可以使用内存缓冲区来存储执行实例的输入和输出。在 NNAPI 中,每个内存缓冲区均表示为一个
ANeuralNetworksMemory实例。 -
执行:用于将 NNAPI 模型应用到一组输入并收集结果的接口。执行可以同步执行,也可以异步执行。
对于异步执行,多个线程可以等待同一执行。此执行完成后,所有线程都被释放。在 NNAPI 中,每次执行均表示为一个
ANeuralNetworksExecution实例。
运行时:
1、**NNAPI 应由机器学习库、框架和工具调用,这样可让开发者在设备外训练他们的模型,并将其部署在 Android 设备上。2、应用一般不会直接使用 NNAPI,而会使用更高层级的机器学习框架。**这些框架进可以使用 NNAPI 在受支持的设备上执行硬件加速的推断运算。
根据应用的要求和 Android 设备的硬件功能,Android 的神经网络运行时可以在可用的**设备上处理器(包括专用的神经网络硬件、图形处理单元 (GPU) 和数字信号处理器 (DSP))**之间高效地分配计算工作负载。对于缺少专用供应商驱动程序的 Android 设备,NNAPI 运行时将在 CPU 上执行请求。
所示为 NNAPI 的简要系统架构。

编程模型:
若要使用 NNAPI 执行计算:
1、先构造一张有向图来定义要执行的计算。
2、此计算图与输入数据(例如,从机器学习框架传递过来的权重和偏差)相结合,构成 NNAPI 运行时求值的模型。

编程示例:
实现这样的计算图:
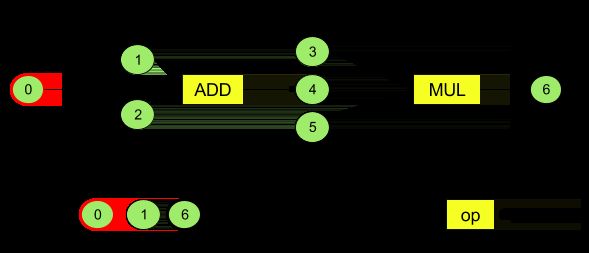
1、内存基础:
为 NNAPI 运行时提供对此类数据的高效访问途径,调用 ANeuralNetworksMemory_createFromFd() 函数并传入已打开的数据文件的文件描述符来创建 ANeuralNetworksMemory 。训练权重和偏差数据可能存储在一个文件中。
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
使用原生硬件缓冲区,可以将原生硬件缓冲区用于模型输入、输出和常量运算数值。在某些情况下,NNAPI 加速器可以访问 AHardwareBuffer 对象,而无需驱动程序复制数据。
// Configure and create AHardwareBuffer object
AHardwareBuffer_Desc desc = ...
AHardwareBuffer* ahwb = nullptr;
AHardwareBuffer_allocate(&desc, &ahwb);
// Create ANeuralNetworksMemory from AHardwareBuffer
ANeuralNetworksMemory* mem2 = NULL;
ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
//free
ANeuralNetworksMemory_free(mem2);
2、模型创建、编译、执行;
运算数规范:
-
添加运算数的顺序无关紧要。例如,模型输出运算数可能是添加的第一个运算数。重要的是在引用运算数时使用正确的索引值。
-
运算数具有类型。这些类型在运算数添加到模型时指定;
-
一个运算数不能同时用作模型的输入和输出;
-
每个运算数必须是一项运算的模型输入、常量或输出运算数;
运算规范:
运算指定要执行的计算。每项运算都由下面这些元素组成:
- 运算类型(例如,加法、乘法、卷积);
- 运算用于输入的运算数索引列表;
- 运算用于输出的运算数索引列表;
基本步骤:注意中间还可以进行很多配置
1、创建模型:
2、运算数添加到模型:
3、设置权重和偏差值;
4、添加运算;
5、设置输入和输出;
6、完成模型定义;
7、编译模型;
8、设置执行的设备和编译缓存;
9、执行模型;
10、最后一步,清理内存等资源;
//1、创建模型:
ANeuralNetworksModel* model = NULL;
ANeuralNetworksModel_create(&model);
//2、运算数添加到模型:
// In our example, all our tensors are matrices of dimension [3][4]
ANeuralNetworksOperandType tensor3x4Type;
tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32;
tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors
tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors
tensor3x4Type.dimensionCount = 2;
uint32_t dims[2] = {3, 4};
tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers
ANeuralNetworksOperandType activationType;
activationType.type = ANEURALNETWORKS_INT32;
activationType.scale = 0.f;
activationType.zeroPoint = 0;
activationType.dimensionCount = 0;
activationType.dimensions = NULL;
// 添加7个运算数
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1
ANeuralNetworksModel_addOperand(model, &activationType); // operand 2
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4
ANeuralNetworksModel_addOperand(model, &activationType); // operand 5
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6
//3、设置权重和偏差值
// In our example, operands 1 and 3 are constant tensors whose values were
// established during the training process
const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize
ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor);
ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5
int32_t noneValue = ANEURALNETWORKS_FUSED_NONE;
ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue));
ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));
//4、添加运算
// 两种运算,和以及乘
// The first consumes operands 1, 0, 2, and produces operand 4
uint32_t addInputIndexes[3] = {1, 0, 2};
uint32_t addOutputIndexes[1] = {4};
ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6
uint32_t multInputIndexes[3] = {3, 4, 5};
uint32_t multOutputIndexes[1] = {6};
ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);
//5、设置输入和输出
// 输入: (0) 和 输出: (6)
uint32_t modelInputIndexes[1] = {0};
uint32_t modelOutputIndexes[1] = {6};
ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
//6、完成模型定义
ANeuralNetworksModel_finish(model);
//7、编译模型
ANeuralNetworksCompilation* compilation;
ANeuralNetworksCompilation_create(model, &compilation);
//8、设置执行的设备和编译缓存
//优化低功耗
ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
//设置编译缓存
ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
//完成编译
ANeuralNetworksCompilation_finish(compilation);
//9、执行模型
// Run the compiled model against a set of inputs
ANeuralNetworksExecution* run1 = NULL;
ANeuralNetworksExecution_create(compilation, &run1);
//指定读取输入值,可以是用户缓冲区或已分配的内存空间读取输入值。
// Set the single input to our sample model. Since it is small, we won't use a memory buffer
float32 myInput[3][4] = { ...the data... };
ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
//设置写入输出值,写入用户缓冲区或已分配的内存空间。
float32 myOutput[3][4];
ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
//开始执行,等待可以在不同于开始执行的线程上完成。
// For our example, we have no other work to do and will just wait for the completion
ANeuralNetworksEvent_wait(run1_end);
ANeuralNetworksEvent_free(run1_end);
ANeuralNetworksExecution_free(run1);
//可以选择通过使用同一编译实例将不同的输入集应用于已编译的模型,从而创建新的 ANeuralNetworksExecution 实例。
//10、最后一步,清理内存等资源
// Cleanup
ANeuralNetworksCompilation_free(compilation);
ANeuralNetworksModel_free(model);
ANeuralNetworksMemory_free(mem1);
参考:
1、Neural Networks API | Android NDK | Android Developers (google.cn)
2、ndk-samples/nn-samples at main · android/ndk-samples (github.com)