Lambda架构
Lambda架构->实时数仓
目前大数据架构已经走向了数据湖时代,无论是单纯的批处理模式,还是同时支持实时和离线数据处理的Lambda架构都已经过时。均不再适应现在大数据的业务发展需要。
一 Lambda架构
相信现在还有很多公司公司的数据架构仍然是Lambda架构,它解决了这些公司大数据的离线和实时数据处理,一个典析的Lambda架构如下图所示:

Lambda架构
从底层的数据源开始,通过Kafka、Flume等大数据组件,将各种各样的数据同步到大数据平台,然后分成两条线进行计算。一条线进入离线批量数据处理平台(Spark、Hive、MapReduce等),去计算T+1或者H+1的业务指标,这些指标需要T+1或者H+1才能看到;另外一条线是进入到实时数据处理平台(Flink、SparkStreaming等),去计算实时统计指标。
经过多年的发展,Lambda架构比较稳定,能满足过去的应用场景。但是它有很多致命的弱点:
1.1 数据口径不一致问题
因为离线和实时计算走的是两个完全不同的代码,算出来的结果往往不同,可能会当天看到一个结果数据,第二天发现数据变成了。
1.2 T+1离线严重超时
像新浪微博这种体量的公司,每天有400TB+的数据写入大数据平台,而且数据在不断地增加。我们经常会发现在夜间3-4个小时内,离线程序执行不完,不能保证数据在上班之前准时生成。尤其是在夜间发生故障之后,白天的数据产出时间更加难以把控。
1.3 需要维护两套代码
每次数据源有变化,或者业务方有新的需求。都要修改两次业务逻辑代码,既要修改离线的ETL任务,又要修改流式任务,开发周期很长(工作量是双倍),人力成本比较大。
为了解决Lambda架构的痛点,就产生了Kappa架构,相信大家对这个架构也非常熟悉。
二 Kappa架构
针对Lambda架构需要维护两套程序的缺点,后面产生了Kappa架构。Kappa架构的核心思想是,改进流计算系统来解决全量数据,让实时和离线处理过程采用同一套代码。Kappa架构的初衷是,只有在必要的时候才会对历史数据进行重新计算。下图是Kappa架构模型:
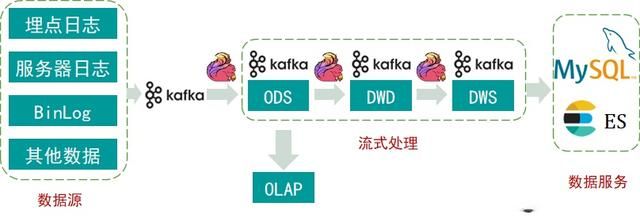
Kappa架构
Kappa架构也不是完美的,它也有很多问题。
2.1 链路更加混乱复杂
首先,我们需要借用Kafka来构建实时场景,但是如果需要对ODS层数据做进一步的分析时,就要接入Flink计算引擎把数据写入到DWD层的Kafka,同样也会将一部分结果数据写入到DWS层的Kafka。但是,如果想做简单的数据分析时,又要将DWD和DWS层的数据写入到ClickHouse、ES、MySQL或者是Hive里做进一步分析,这无疑带来了链路的复杂性。
2.2 数据一致性受到挑战
其次,Kappa架构是严重依赖于消息队列的,我们知道消息队列本身的准确性严格依赖它上游数据的顺序,但是,消息队列越多,发生乱序的可能性越大。通常情况下,ODS层的数据是绝对准确的,把ODS层数据经过计算之后写入到DWD层时就会产生乱序,DWD到DWS更容易产生乱序,这样的数据不一致性问题非常大。
那么有没有一种架构,既能满足实时性的需求,又能满足离线计算的需求,同时还能减轻运营开发成本?解决Kappa架构的痛点呢?
2.3 实时数据仓库建设需求
是否有一种技术,既能够保证数据高效的回溯能力,支持数据更新,又能够实现数据的流批读写,并且还能够实现分钟级别的数据接入。
这也是建设实时数据仓库的迫切需要,实际上需要对Kappa架构进行改进升级,以解决Kappa架构中遇到的问题,接下来我们会进一步探讨数据湖技术–Iceberg。

实时数仓的要求
三 Flink+Iceberg构建实时数仓
3.1 准实时数据仓库分析系统
我们知道Iceberg支持读写分离,又支持并发读、增量读、合并小文件,而且还能做到秒级/分钟级的数据延迟。我们基于Iceberg这些优势,采用Flink+Iceberg的方式构建了流批一体化的实时数据仓库。

Flink+Iceberg架构
在数据仓库处理层,可以用 presto 进行一些简单的查询,因为 Iceberg 支持 Streaming read,所以在系统的中间层也可以直接接入 Flink,直接在中间层用 Flink 做一些批处理或者流式计算的任务,把中间结果做进一步计算后输出到下游。
3.2 采用Iceberg替代Kafka实时数仓的优劣势
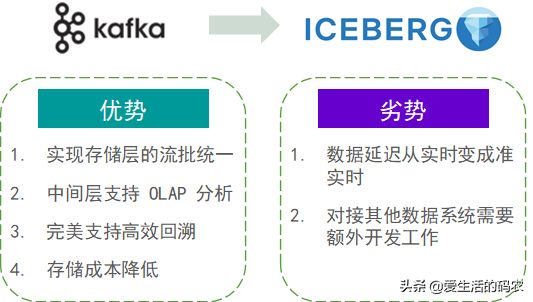
升级后的问题
四 未来规划
4.1 Iceberg 内核能力提升
Row-level delete 功能。目前社区还不支持行级别的删除功能,Iceberg 当前只支持 copy on write 的 update 的能力。如果要真正地构建一个实时数据仓库,还是需要一个高效的 merge on read 的 update 能力。我们会继续根据社区的更新动态,逐步迭代升级。建立统一索引加速数据检索。期待社区会有一个完善的统一索引加速功能。4.2 内部大数据平台升级
希望借助Alluxio构建一个数据湖加速功能,以便在查询层实现秒级分析功能。
建立自动Schema建表的功能。
和所有业务系统打通,逐步迁移完成所有业务线的数据湖建设。
能,以便在查询层实现秒级分析功能。
建立自动Schema建表的功能。
和所有业务系统打通,逐步迁移完成所有业务线的数据湖建设。