利用python提取视频中的字幕
利用python提取视频中的字幕
``
一、导包
import base64
import os
import cv2
import requests
import aip
from aip import AipOcr
1.cv2报错
解决办法:打开Anaconda Prompt,输入pip install opencv-python,等待安装。
-
aip报错
解决办法:pip install baidu-aip -
在pycharm中使用anaconda包
File–> Settings–>Project Interpreter
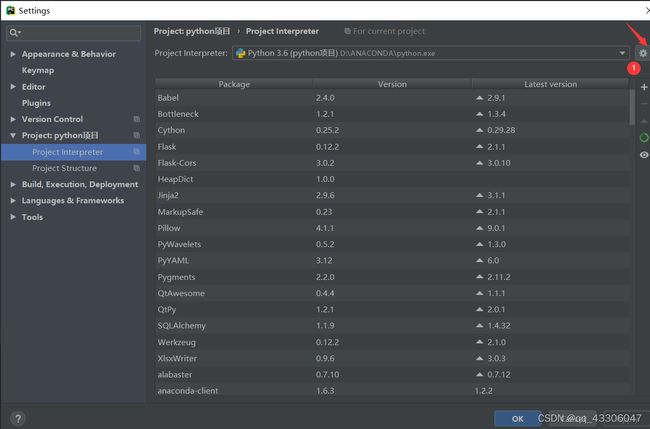
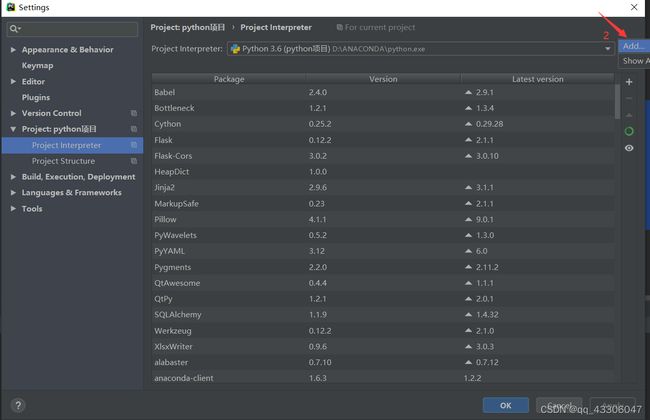
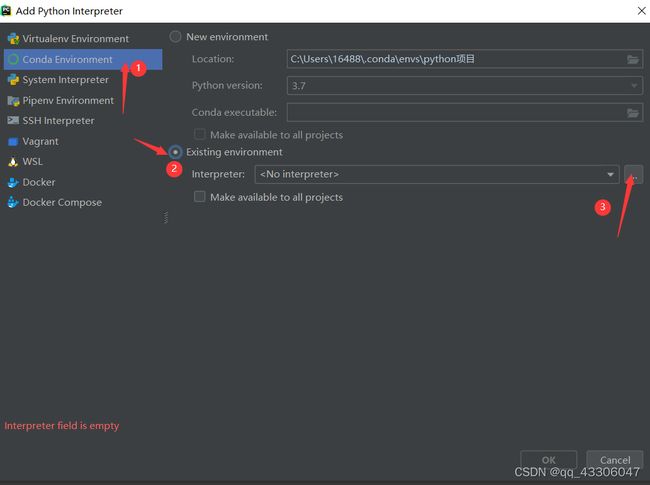
找到Anacondad的安装路径中的python.exe就OK了。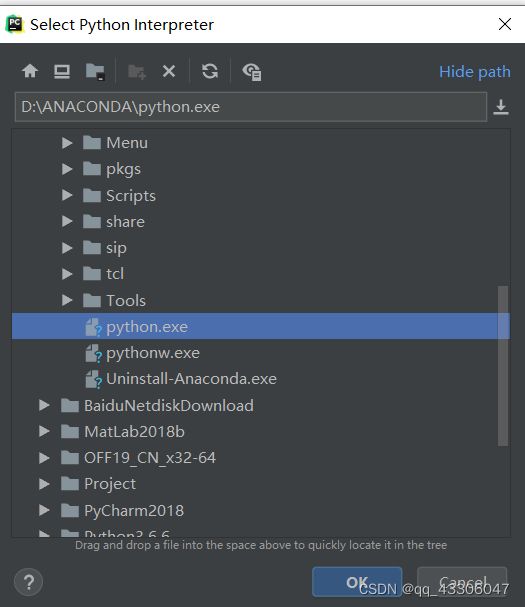
二、解析视频
将视频间隔10帧取图片
def VLink():
video_path = 'D:/Resource/MaxFish.mp4' # 视频地址
images_path = 'D:/Resource/images/' # 图片输出文件夹
interval = 10 # 每间隔10帧取一张图片
num = 1
vid = cv2.VideoCapture(video_path)#打开这个视频
while vid.isOpened():
is_read, frame = vid.read() #按帧读取视频 frame是读取图像 is_read是布尔值。文件读取到结尾返回FALSE
if is_read:
file_name = num
cv2.imwrite(images_path + str(file_name) + '.jpg', frame)
cv2.waitKey(1)
num += 1
else:
break
结果:

三、截取字幕
将图片中的字幕部分截取出来
def tailor(path1,path2,begin ,end,step_size):
for i in range(begin,end,step_size):
fname1 = path1%str(i)
print(fname1)
img = cv2.imread(fname1) #像素
print(img.shape)
cropped = img[650:720, 300:1024] # 裁剪坐标为[y0:y1, x0:x1]
imgray = cv2.cvtColor(cropped, cv2.COLOR_BGR2GRAY)
thresh = 200
ret, binary = cv2.threshold(imgray, thresh, 255, cv2.THRESH_BINARY)
binary1 = cv2.bitwise_not(binary)
cv2.imwrite(path2 % str(i), binary1)
cropped = img[650:720, 300:1024]这里的截取可能因为照片的大小不同而不同,可以编辑照片,看一下适合字幕截取的位置。例如:
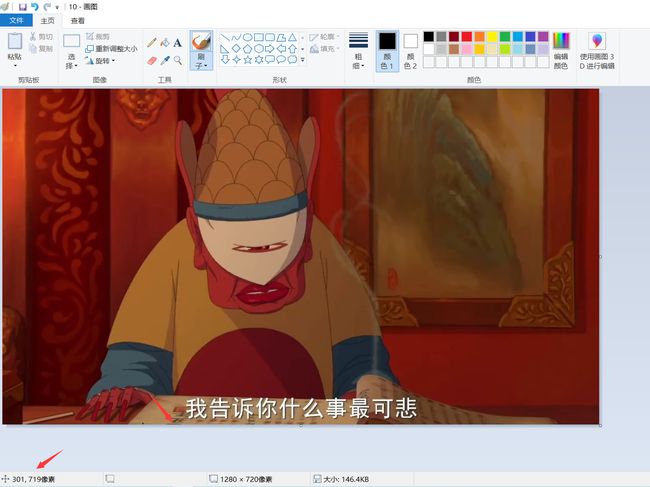
通过 鼠标的移动知道截取图片的位置。
结果: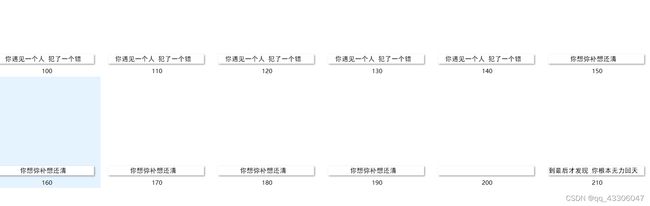
四、解析图片
解析图片,获得字幕,保存在TXT文档中。
1、
def subtitle(fname,begin,end,step_size):
array =[] #定义一个数组用来存放words
for i in range(begin,end,step_size):
fname1 = fname % str(i) #字幕image D:/Resource/images/img_subtitle/100.jpg
with open(fname1, 'rb') as fp:
image = base64.b64encode(fp.read())
try:
results = requestApi(image)["words_result"] #调用requestApi函数,获取json字符串中的words_result
for item in results:
print(results)
array.append(item['words'])
except Exception as e:
print(e)
text=''
result = list(set(array)) # 去重
result.sort(key=array.index) # 排序
for item in result:
text +=item+'\n'
2、
# 定义一个函数,用来访问百度API,
def requestApi(img):
general_word_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
params = {"image": img,
"language_type": "CHN_ENG"}
access_token = '24.80669db308b385e6f913e40b3fe604d1.2592000.1651237616.282335-25877315'
request_url = general_word_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
results = response.json()
return results
百度智能云:
网址:https://login.bce.baidu.com
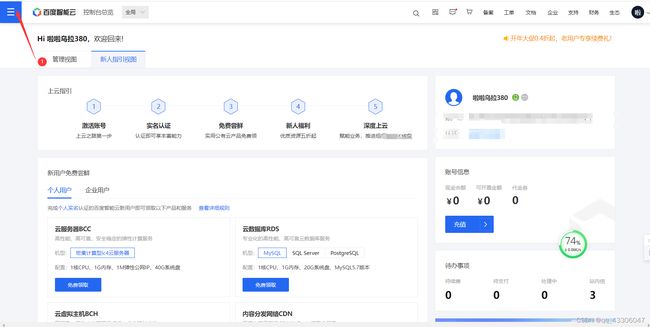
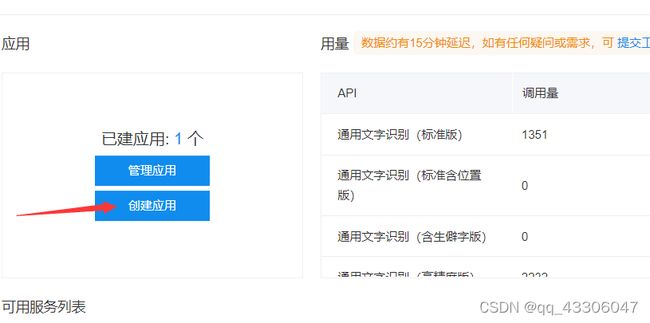
点击创建应用,写个名称就创建成功了。

在这里可以看见API Key和Secret Key,我们需要用这两个参数获取
点击左边的导航栏的技术文档---->API文档----->通用场景文字识别------>可以选择标准版
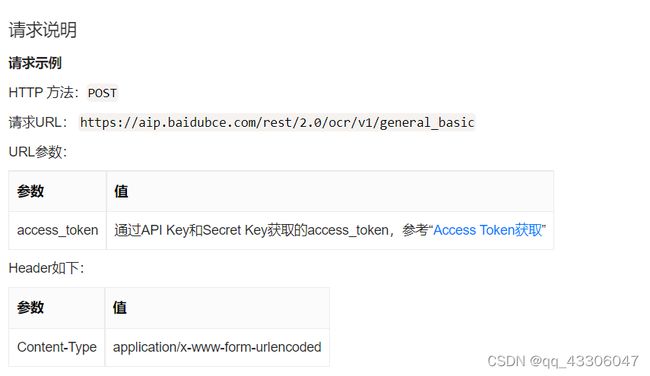
告诉了我们了如何获取Access Token。
复制链接:https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=mGAOwUKl42RM93TAWEmHZ3ff&client_secret=RGlbvPF49FGpqLiMVhFow1xfXp4EAvWAA&
这里的grant_type固定为client_credentials
client_id === API Key
client_secret == Secret Key
![]()
将你自己申请的API Key和Secret Key替换掉就可以了,回车获得access_token

这样就可以了。
如果想在代码中查找access_token。可以如下:
def get_access_token():
url = 'https://aip.baidubce.com/oauth/2.0/token'
data = {
'grant_type': 'client_credentials', # 固定值
'client_id': 'eFGwDIb*******HucbnPr', # API Key
'client_secret': 'XPxWT2L********PFVCKS6PVih' # Secret Key
}
res = requests.post(url, data=data)
res = res.json()
print(res)
access_token = res['access_token']
return access_token
问题:KeyError: ‘words_result’
解决办法:
(1)进入百度智能云,点击领取免费资源
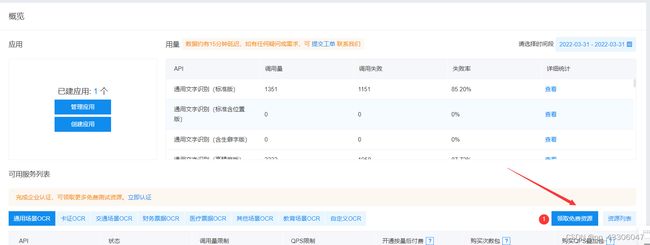
(2)进入后,会有一个通用场景识别,选择“全部”,然后进行领取(这里因为我已经领过了,所以就没有显示了);

(3)领取后,回到刚刚那个界面,查看“资源列表”,可以看到自己已经领取的资源;

(4)如果使用后还出现这种情况,搜索:https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic?access_token=24.80669db308b385e6f913e40b3fe604d1.2592000.1651237616.282335-25877322
查看出现的数字:

如果是17,可以实名认证,就会增加调用量。
3、
在D:/Resource/下创建一个subtitle.txt,将提取出来的字幕写进去。
#创建文本
def text_create( msg):
full_path = "D:/Resource/subtitle.txt" # 也可以创建一个.doc的word文档
file = open(full_path, 'w',encoding='utf-8')
file.write(msg)
file.close()

五 、主函数
if __name__ == '__main__':
path1 = 'D:/Resource/images/%s.jpg' # 视频转为图片存放的路径(帧)
path2 = 'D:/Resource/images/img_subtitle/%s.jpg' # 图片截取字幕后存放的路径
print("""
1..裁剪视频
2.图片裁剪
3.提取字幕
""")
choose = input()
begin = 100
end = 1000
step_size = 10
if choose == '1': #视频中提取图片
VLink()
if choose == '2': #提取字幕
tailor(path1, path2, begin, end, step_size)
if choose == '3': #提取字
subtitle(path2, begin, end, step_size)
借鉴:https://blog.csdn.net/qq_39783601/article/details/105748486