智能选路系统与架构
01 背景
阿里云作为亚太第一云厂商,需要服务各种各样的细分领域客户,例如 3C、游戏、网页加速等客户。近年来,随着视频咨询类客户的蓬勃发展(头条),低延迟、高可用的全球网络需求也越来越旺盛。因此,在“全站加速”架构设计之初,就需要考虑如何为海量客户构建差异化的低延迟网络。

阿里云目前已经建设有 2800+个全球节点,但这些节点的带宽能力、互联互通能力、对 TCP/QUIC 等传输协议兼容能力都不尽相同。因此,如何在这种复杂的、多维约束的网络环境中选择合适的网络通道(即智能选路),就变得十分重要了。
02 海量客户的智能选路
从图论的角度看,CDN 节点、客户源站类似于图中的节点(node),节点间网络、回源网络类似于图中的 edge,由这两者组成的有向图 G(node, edge),就是智能选路需要求解的全集。
所以智能选路系统本质上是:在有向图 G 中寻找最“短”路径的过程。虽然这个“短”会叠加上很多定语,例如:在带宽允许的情况下,在跳数限制的情况下(因为跳数越多,成本越高)。但为了简化问题,可以先不考虑这些定语,即无限资源场景下的智能选路。这在产品上线早期,客户少、带宽等资源占用少的时候,是比较适用的。
1.最短路径
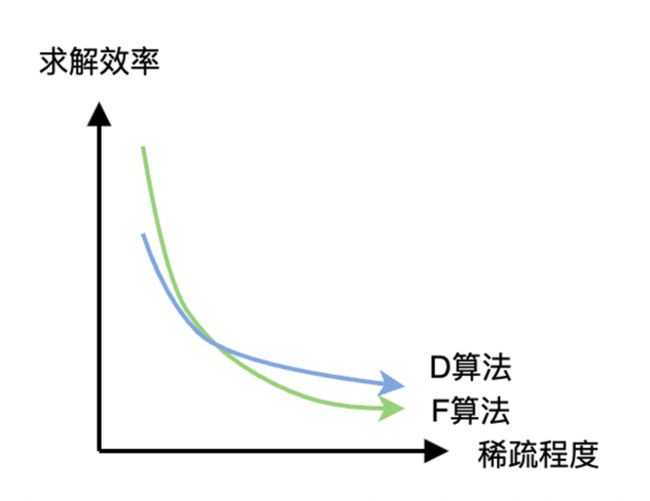
介绍智能选路系统绕不开的一点,就是最短路径算法的选型。考虑到实际公网中,是不会存在负权重的场景,因此只需要在 Dijkstra(单源最短路径,以下简称 D 算法)、Floyd(多源最短路径,以下简称 F 算法)中选择即可。
乍一看,要解决海量客户的智能选路问题,似乎就应该选择 F 算法,但仔细想想其实应该组合使用。智能选路是要解决客户端到源站的最短路径问题,它是不需要计算不同源站间的最短距离的,即它不是一个 P2P 的选路问题。随着客户源站数量的不断增长,算法所需的邻接矩阵会越来越稀疏,这时候 D 算法的性能优势就展现出来了。
当然 F 算法也不是一无是处的。把智能选路分解为 2 个子问题:CDN 节点间最短问题 + 回源网络最短问题,考虑 CDN 节点间网络是强连通的稠密网络,因此求解过程用 F 算法会比 D 算法更快。在求解全链路最短问题是时再使用 D 算法。这种算法组合能获取 1 个数量级的计算耗时缩短(当然,提升多少其实也取决于客户源站数量级)。
2.多样路径

从高可用(即系统稳定性)的角度看,任意 2 点间只给出 1 条最短路径是不够的。因为一旦这条路径上的光线被挖断、节点因故障下线等影响,都会导致客户服务的短时间不可用。
上述影响是比较常见,也比较容易设想到的问题,但其实还有数据延迟(时间)问题,因为智能选路系统构建的网络拓扑不可能是完全实时的,总是有一定延迟存在的。如果 T-1 时刻的网络较好,但 T 时刻网络异常时,智能选路系统用 T-1 时刻的网络拓扑计算的选路结果肯定是有问题的,而网络异常又是难以预测的,因此增加冗余的路径就显得极为重要了。
所以原则上,最少要同时提供 2 条相对较短的路径。这在学术上一般称之为 k-shortest 路径问题。直接套用学术界的算法会有一些比较糟糕的问题:1)只要 k 是大于 1 的值,求解耗时一般呈指数级上涨,会导致计算太慢(即故障切换时也慢);2)学术届一般都是考虑严格意义的第 2 短、第 3 短路径等,不考虑路径重叠的问题。在实际公网传输的场景中,一旦挖断的光纤是主备路径的公共段,还是会导致客户服务的短时不可用。因此需要工程化的高效的、多样的备路径能被筛选出来。
3.分层聚合
随着客户源站接入的越来越多,智能选路系统的算力越来越捉襟见肘。虽然可以通过系统横向扩容,通过集群化的方式解决规模问题,但扩容总是面临预算、周期等因素的影响,不太可能一蹴而就。因此还是要持续优化算法
直觉的高速网络通道的选择过程,其实和菜鸟的快递运输过程、高德的路径导航过程是高度类似的。所以,当人来选择北京到杭州的最快、最短路径时,一般都是找 1 个最近的高速路口,先上高速,然后再找 1 个距离杭州近的高速路口下。几乎不会考虑省道、县道等若干段路径的组合,经验上也是高速更快的。
这种可解释性非常好的直觉选路策略给了 2 个启示:1)应尽量选择高速公路,在公网上相对应的就是专线及能被双边加速的路径。单边加速的路径应该尽可能短,哪怕这部分路径有一些南辕北辙也没关系,长链路上“高速公路”上的加速效果是完全能超过这部分损失的;2)没有必要为北京东城区、海淀区的不同客户,分配不同的到杭州路径。换句话说:新接入的北京电信的客户源站,其实上可以直接复用其他北京电信客户的智能选路结果,没有必要重复算(一般算出来的也是一样的)。
03 多维约束的智能选路
上述内容主要介绍了“无限资源场景”下的智能选路。随着客户数量的增多、客户自有带宽量的上涨,“无限资源”的简化场景就不太适用了。因此需要考虑多种不同维度的限制,保证智能选路系统在有限范围内,选择合适的路径。即“有限资源场景”的智能选路。
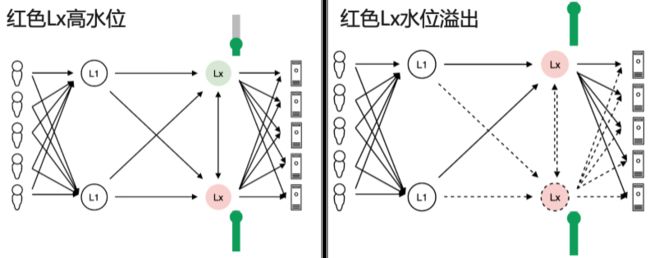
1.节点约束
在前文背景中也介绍了,节点带宽能力是在采购环节就决定了,用量超过上限必然会带来不可用、错误、延迟等各种异常问题。因此需要在智能选路时考虑节点容量(包括但不限于带宽、CPU 等)。
这种带限制的路径规划问题,要么使用贪心策略:优先计算一部分客户的最短路径,扣减相关资源占用后,继续下一部分客户的路径计算;要么使用运筹优化:设定最小化目标(例如:最小化全局延迟),并加入多种约束条件后,导入求解器求解。贪心策略适用于有明确优先级划分的场景,设计上就是低优先级避让高优先级,可解释性好;运筹优化适用于无优先级场景。
所以需要根据不同业务场景,选择不同规划算法,甚至可能是组合使用。在计算规模非常大,无法实时(分钟级)计算时,还需要邻域搜索等局部更新算法。
2.网络约束
公网中绝大部分流量都是 TCP 的,因此公网的中间设备往往对 TCP 有很多 QOS 的优待。相比较 UDP 的相关优化就很少,会被限速,甚至在高水位运行的网络中,还存在降低 UDP 转发优先级给 TCP 让路的行为。
因此节点间传输使用 QUIC 协议就需要“小心翼翼”,既要关注历史 UDP 峰值,观察在大流量时的延迟指标是否有明显“非预期”的下滑,选路时也要多多使用这种大流量“无损”的 UDP 管道,从而保证对客户服务的稳定。
3.波动约束
通过实时的网络探测来量化节点间网络距离是常见的,与此同时,网络探测值也是带有噪声的。无论是来自节点内不同机器的负载轻微差异,还是公网中必然存在的轻微波动,都有可能间接导致智能选路结果的变化。从纯粹算法、图论的角度看是没问题的,因为每一轮算法的输出结果都是独立于上一轮的,即完全基于静态快照式的选路。
网络流量完全参考快照式选路结果来传输,是 100%无损的么?并不是的。对于绝大部分有连接的 TCP 来说,新的路径就意味着新的 TCP 连接建立,必然有握手的开销。如果上层跑的是 HTTPS 流量,还有 SSL 握手等更大的开销。一方面这些握手有带宽成本的上涨,另一方面非 0-rrt 管道就意味着“慢”。所以,为了 3-5ms 的理论距离缩短,付出 30-50ms 的额外握手开销是得不偿失的。
所以,连接池、TFO 等 0-rtt 网络传输技术,反向要求智能选路结果是稳定的(即依赖上一轮选路结果的)。简单理解就是只有在网络明显劣化、节点故障下线时,才快速切换。即非必要,不切换。
当然,在必须要切换的场景中,也是需要思考并设计合理的阻尼的。例如在单节点故障下线场景,对于流量切出的要求是:下一轮计算必须 100%完成切出;而对于流量切入(次短 or 备路径)的要求则不是那么严格,即流量可以分摊到次短、次次短等多条路径上。这主要是考虑次短路径全量承接,会导致瞬时新建连接洪峰,极容易打满 TCP 半连接队列,造成 syn 包重传等加速性能的劣化。
上述波动限制,还仅仅只是考虑了动态请求(所有请求都到达源站)的加速过程。考虑静态请求(节点缓存有概率能命中,不需要所有请求到达源站)的加速过程,对路径波动的容忍度更低。因为新路径上一开始的命中率是 0%,而老路径上是 XX%。所以路径切换最好发生在缓存快要过期的时刻,这对海量缓存的实时统计,智能选路的精准切换提出了更高要求。
4.手动约束
无论是开发的早期阶段,需要手动调试系统的能力(或工具),还是在开发后的交付阶段,需要提供故障逃逸的人为介入手段。因为需要在完全自动化智能选路系统中,在一些关键节点或环节,加入人为操控是非常必要的,就像世界上自动化程度极高的波音客机的自动驾驶,仍然保留了手动驾驶模式,以防止在极端恶劣情况、系统设计中非预期情况下,由人判断,由人决策。
综上,智能选路系统是从一个有向图的最短路径算法集,逐步发展并完善成一个能为海量客户实时构建多维约束的低延迟、高可用网络的算法平台。