Flink (二) 运行架构
一、运行流程
- 当用户提交完job之后,就交给分发器,分发器就会启动并将应用移交给一个JobManager去做管理
- JobManager是整个调度的核心,启动它并把当前应用提交。JobManager会对当前任务进行分析需要多少个task任务,需要多少个slots资源去执行,进行并行度调整,得到跑在taskManager上的执行图。
- JobManager向ResourceManager去做请求slots,RM去启动taskManager,它把自己的slots向ResourceManager去注册(告诉它每个taskManager有多少slots,空闲、可利用的有多少个),如果资源够RM向TaskManager发出提供slots的指令。
- TaskManager给JobManager提供slots,JobManager给它分发任务,告诉它在slots中要执行的任务。
- TaskManager之间交换数据执行任务。
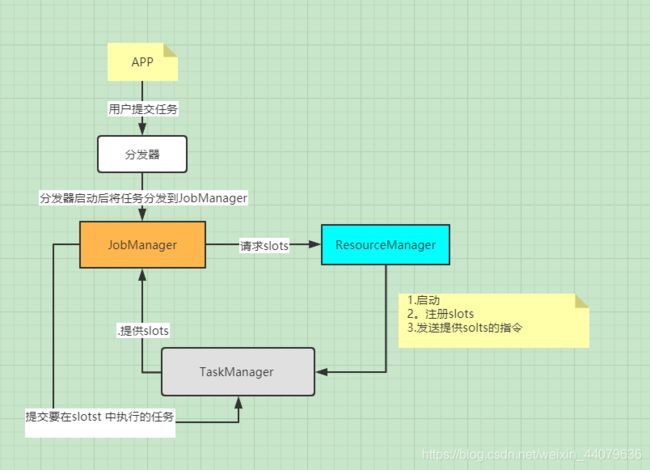
二、运行时组件介绍:

Flink运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:作业管理器(JobManager)、资源管理器(ResourceManager)、任务管理器(TaskManager)和分发器(Dispatcher)。因为Flink是用Java和Scala实现的,所以所有组件都会运行在Java虚拟机上。
1. 作业管理器(JobManager)
作业管理器,说白了就是管理你提交的任务,决定让这个任务怎么运行。主要做的工作有分配任务,调度管理资源、checkpoint触发持久化到硬盘等操作。
在JobManager接收到自己要执行的任务的时候会分析jar包,得知:有多少个任务task、需要多少个slot去执行,向资源管理器去申请资源。
它会转换成一个执行图,JobManager会向资源管理器请求运行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图发到真正运行它们的TaskManager上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
2.任务管理器(TaskManager)
taskmanager中的计算资源(内存和cpu)内存划分出的每一部分叫一个slot(最小化资源单位)。
TaskManager的个数 * slots的数量 整个集群中能够提供的总数,即静态的并行计算的能力。
启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。
3.资源管理器(ResourceManager)
管理集群中的资源slot。主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是Flink中定义的处理资源单元。Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,以及standalone部署。当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
4.分发器(Dispatcher)
当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。
5.Clients
Flink中的Client并不是集群计算的一部分,Client仅仅准备和提交dataflow给JobManager。提交完成之后,可以直接退出,也可以保持连接以接收执行进度,因此Client并不负责任务执行过程中调度。Client可以作为触发执行的Java/Scala程序的一部分运行,也可以在命令行窗口中运行。
类似Spark中的Driver,但又特别不同,因为Spark Driver负责任务调度和恢复
6。总结
- JobManager:管理提提交的任务
- taskManager :具体执行任务的打工人
- Task:等价spark中的Stage,每个Task都有若个Subtask。会把task划分成对个subTask (根据有几个并行度就可以划分为几个)
- subTask : 等价于一个线程,是Task中的一个子任务
- 算子链:通过一定的规则将算子连接在一起,形成的结果称为Task
- Operator Chain-:将多个算子归并到一个Task的机制,归并原则类似于SparkRDD的宽窄依赖
三、Task Slots and Resources
slots就是资源分配管理固定大小的资源,按独立的内存划分。每个slot上单独执行一个任务。slot的数量决定TaskManager并行处理的能力。
每一个TaskManager是一个JVM进程,可以执行一个或者多个子任务(Thread/SubTask)。为了 控制Worker节点能够接收多少个Task任务,提出了所谓Task slot用于表达一个计算节点的每个Task slot表示的是TaskManager计算资源的固定子集。
例如,一个TaskManager拥有3个Task slot,则每个Task slot占用TaskManager所管理内存资源的1/3。每个Job启动的时候都拥有固定的Task Slot,这些被分配的Task Slot资源只能被当前job的所有Task使用,不同Job的Task之间不存在资源共享和抢占问题。计算能力(每个计算节点至少有一个Task slot)。
但是每个Job会被拆分成若干个Task,每个Task由若干个SubTask构成(取决于Task并行度)。默认Task slot所对应的内存资源只能在同一个Job下的不同Task的subtask间进行共享,也就意味着同一个Task的不同subtask不能运行在同一个Taskslot中。
如果同一个Job下的不同Task的subtask间不能共享slot,就会造成非密集型subtask的阻塞,从而浪费内存。
- 非密集型任务:source()/map()。操作占用内存量小
- 密集型任务:keyBy()/window()/apply()。操作过程中涉及shuffle,会占用大量内存
因此,Flink的底层设计为同一Job下的不同Task的subtask间共享slot。可以将并行度调整从而充分利用资源。将上述示例的并行度从2调整为6,Flink底层会确保heavy subtasks 均衡分布于TaskManager之间的slots
总结:同一个Job下的不同Task的subtask间进行共享
- 首先用户会发送过来一个job,然后将这个job交给TaskManager执行
- 一个TaskManager会根据并行度将整个TaskManager的资源划分成若干个TaskSlot,假设是3个Task slot,则每个Task slot占用TaskManager所管理内存资源的1/3。
- 一个job到了TaskManager中会被分成对个Task
- 那同一个job的Task必然不能放在同一个Task slot中执行了,由于任务类型的不同造成不同task所需要的资源的量也不同,有的消耗的资源量大,有的消耗的少,如果把同一个job的task都放在一个TaskManager的同一个Task slot中执行的话,可能整个task slot的资源不够用,而其他两个Taskslot的资源用不完。所以他将同一个job的同一个Task任务放在不同的task slot中执行,这样就不造成上述问题了
四、Checkpoint/Savepoints
持久化,说的是两种不同的持久化方式,Checkpoint自动持久化。和Savepoints手动持久化
checkpoint
checkpoint是由flink定期的,自动的进行数据的持久化(把状态中的数据写入到磁盘(HDFS))。新的checkpoint执行完成之后,会把老的checkpoint丢弃掉
Savepoints
Savepoint是手动触发的checkpoint,它获取程序的快照并将其写入state backend。可以通过命令在任何的时间点上进行数据的持久化
区别:
Checkpoint依赖于常规的检查点机制:在执行过程中个,程序会定期在TaskManager上快照并且生成checkpoint。为了恢复,只需要最后生成的checkpoint。旧的checkpoint可以在新的checkpoint完成后安全地丢弃。
Savepoint与上述的定期checkpoint类似,只是他们由用户触发,并且在新的checkpoint完成时不会自动过期。Savepoint可以通过命令行创建,也可以通过REST API在取消Job时创建。
五、State Backends
说的是持久化状态的数据存放在哪
Flink是一个基于状态计算的流计算引擎。存储的key/value状态索引的确切数据结构取决于所选的State Backends.除了定义保存状态的数据结构外,State Backend还实现了获取key/value状态时间点快照 并且将该快照储存为checkpoint一部分的逻辑。
Flink中定义了三种State Backend
- The MemoryStateBackend:内存
- The FsStateBackend:文件系统,比如hdfs
- The RocksDBStateBackend:DB
就是说数据可以存在内存中,也可以存在HDFS中,也可以存在数据库中
