利用支持向量机(SVM)进行分类的Matlab实现
文章目录
- 前言
- 一、支持向量机是什么?
- 二、步骤
-
- 1.构建特征矩阵和类标签
- 2.使用fitcsvm函数训练svm
- 3.使用predict函数验证svm
- 4.完整代码
- 总结
前言
看到目前博客上的支持向量机的matlab代码都是从底层原理开始编起,这对单纯想使用支持向量机实现一个简单的分类的人来说十分不友好,其实matlab内已有封装好的支持向量机代码,本文简单记录一下如何使用。
一、支持向量机是什么?
对于一个二分类任务来说,支持向量机的目的是寻找一个最优超平面,使得样本在超平面的两侧,在边界(图中虚线)上的样本被叫做支持向量。
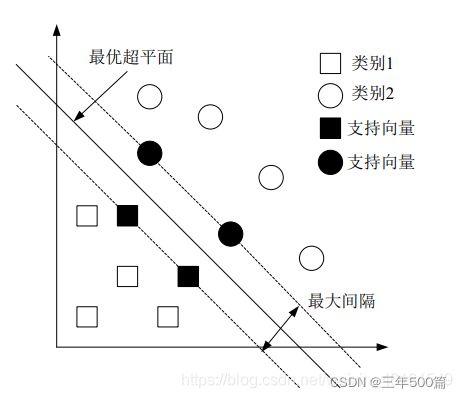
那么要想实现一个分类任务,支持向量机的输入和输出分别是什么呢?作为一种监督学习的算法,每个样本肯定要有标签,也就是该样本到底是哪一类;要进行分类,那每个样本都要有自己的特征,当然这个特征可以有很多个,所以SVM的输入是特征矩阵以及类标签。
二、步骤
1.构建特征矩阵和类标签
这里以matlab中的鸢尾花数据集为例进行说明,load fisheriris导入鸢尾花数据集,导入的变量有meas和species两个,其中meas是150*4的矩阵,表示有150个样本,每个样本有4个特征;species是一个元胞数组,存放的是鸢尾花的类型,有’setosa’,'versicolor’和’virginica’三类鸢尾花, 由于本文实现二分类,故把第三类virginica删除。
load fisheriris %加载鸢尾花数据集
meas(101:150,:)=[]; %删除virginica类
species(101:150,:)=[];
2.使用fitcsvm函数训练svm
上一步中已经构造好了样本的特征矩阵和样本的标签,使用fitcsvm函数可以训练支持向量机模型。
SVMModel = fitcsvm(meas,species)
下图是训练好的支持向量机

3.使用predict函数验证svm
使用predict函数可以检验svm的准确性,选择90%的样本用于训练,10%的样本用于测试。
CVSVMModel = fitcsvm(meas,species,'Holdout',0.1); %随机选择10%的样本用于测试
CompactSVMModel = CVSVMModel.Trained{1};
testInds = test(CVSVMModel.Partition); % 提取那10%用于测试的部分的下标
dataTest = meas(testInds,:); % 提取那10%用于测试的部分的数据集
labelTest = species(testInds,:); % 提取那10%用于测试的部分的标签
label_predict = predict(CompactSVMModel,dataTest);
label_predict中存放的便是预测结果,可以与labelTest进行比较,检验预测结果的正确性。
可以用表格的方式进行可视化
table(labelTest,label_predict,score(:,2),'VariableNames',...
{'TrueLabel','PredictedLabel','Score'})
结果如下:

可以看到,对于测试集的所有样本,分类均是正确的。
4.完整代码
clc
clear
load fisheriris
meas(101:150,:)=[];
species(101:150,:)=[];
CVSVMModel = fitcsvm(meas,species,'Holdout',0.1); %随机选择10%的样本用于测试
CompactSVMModel = CVSVMModel.Trained{1};
testInds = test(CVSVMModel.Partition); % 提取那10%用于测试的部分的下标
dataTest = meas(testInds,:); % 提取那10%用于测试的部分的数据集
labelTest = species(testInds,:); % 提取那10%用于测试的部分的标签
label_predict = predict(CompactSVMModel,dataTest);
table(labelTest,label_predict,'VariableNames',...
{'TrueLabel','PredictedLabel'})
总结
本文利用matlab自带的函数实现了一个简单的SVM二分类问题,更多内容,可以在命令行中输入doc svm,打开帮助文档进行学习。