【ShardingSphere】Sharding JDBC & Sharding Proxy 应用
1. 概述
1.1 ShardingSphere
- 开源的分布式数据库中间件解决方案
- 有三个产品 Sharding-JDBC、Sharding-Proxy、Proxy-Sidecar
- 定义为关系型数据库中间件,合理在分布式环境下使用关系型数据库操作
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
1.2 分库分表
1.2.1 为什么要分库分表?
问题引入:
电商平台,关系型数据库存有商品表、店铺表。随着业务量不断增加,数据库中数据不断增多,表中 数据量也会越来越大,再做增删改查操作时,性能会受到影响。
数据库数量不可控,业务随着时间发展,造成表的数据越来越多,如果再去对数据库表 crud 操作时候,造成性能问题。
解决方案:
- 从硬件上解决(无法从根本上解决问题)
- 分库分表处理
1.2.2 什么是分库分表?
分库分表:为了解决由于数据量过大而造成数据库性能降低问题,对数据库、数据表进行拆分。
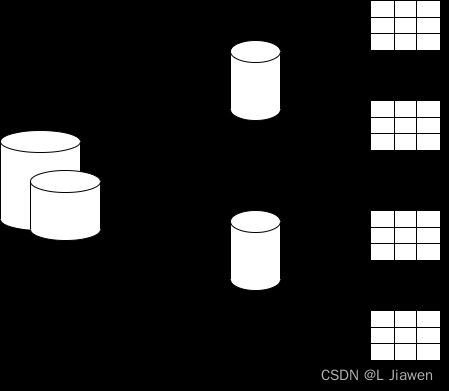
- 数据库拆分
- 为商品建立DB(表拆分)
- 商品表1
- 商品表2
- 为商家建立DB(表拆分)
- 商家表1
- 商家表2
- 为商品建立DB(表拆分)
1.2.3 分库分表的方式
1)垂直切分
① 垂直分表(按 “字段” 分割)
将原数据表中的数据,按照 字段 分配至多个新表。
优点:
- 基本信息、扩展信息分离查询,减少I/O量
- 基本信息、扩展信息分离修改,无需锁定整张表

分表后,多张信息表在同一数据库中,数据库I/O量增加,压力增大,需进行分库处理。
② 垂直分库(按 “业务” 划分)
把单一的数据库,按照业务进行划分,做到专库专用。

2)水平切分
按一定数据规模对数据库/表进行切分(eg. 10000条数据)
① 水平分库
保留数据库表结构,并按照一定判定原则 (取模),对数据库进行拆分。

数据库拆分数据过多,会导致难以维护,所以我们在进一步分割时,应对数据表进行分割。
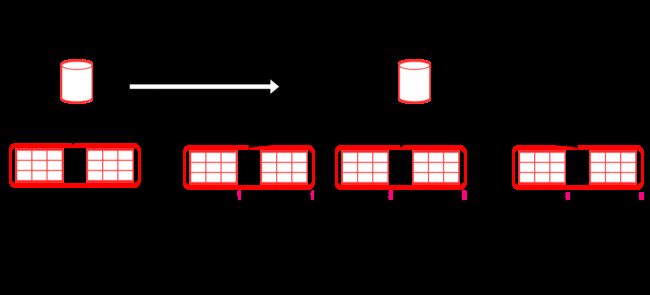
② 水平分表
保留数据表结构,并按照一定判定原则 (取模),对同一数据库的数据表进行叠复。
1.2.4 分库分表应用
- 在数据库设计时,考虑垂直分库/分表。
- 随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理、读写分离、索引等。若无法根本解决问题,再考虑做水平分库/分表。
1.2.5 分库分表问题
- 跨节点连接查询问题(分页、排序)

- 多数据源管理问题
2. Sharding-JDBC
2.1 概述
轻量级Java框架,增强版的JDBC驱动
Sharding-JDBC并不做分库分表操作,而是操作已经完成分库分表的数据库。
-
主要功能:数据分片、读写分离
-
主要目的:简化对分库分表之后数据的操作
轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:Druid, DBCP, C3P0 , HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。

2.2 搭建环境
2.3 水平分表
2.3.1 搭建环境
SpringBoot + MyBatisPlus + Sharding-JDBC + Druid 连接池
① 引入依赖:
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.5.8version>
<relativePath/>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.2.6version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.26version>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.4.2version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.20version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
② 按照水平分表方式,创建数据库/表
-
创建数据库 commodity_db
-
在数据库中创建两张表 commodity_tab_1、commodity_tab_2
-
约定规则:id -> 偶数 commodity_tab_1、奇数 commodity_tab_2
CREATE DATABASE IF NOT EXISTS `commodity_db` CHARACTER SET utf8mb4;
USE `commodity_db`;
CREATE TABLE commodity_tab_1 (
commodity_id BIGINT(20) PRIMARY KEY,
commodity_name VARCHAR(20) NOT NULL,
commodity_user_id BIGINT(20) NOT NULL,
commodity_status VARCHAR(10) NOT NULL
);
CREATE TABLE commodity_tab_2 (
commodity_id BIGINT(20) PRIMARY KEY,
commodity_name VARCHAR(20) NOT NULL,
commodity_user_id BIGINT(20) NOT NULL,
commodity_status VARCHAR(10) NOT NULL
);
③ 编写代码实现对分库分表数据的操作
项目结构:

实体类Commodity:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Commodity {
@TableId("commodity_id")
private Long id;
@TableField("commodity_name")
private String name;
@TableField("commodity_user_id")
private Long userID;
@TableField("commodity_status")
private String status;
}
映射接口ICommodityMapper:
@Repository
public interface ICommodityMapper extends BaseMapper<Commodity> {
}
main方法:
@MapperScan("com.ljw.shardingjdbcdemo.mapper")
@SpringBootApplication
public class ShardingJdbcDemoApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingJdbcDemoApplication.class, args);
}
}
④ 配置 Sharding-JDBC 分片策略
官网 - 分片策略
行表达式 $->{…}
行表达式:
一种特殊的表达式,用于在 Sharding-JDBC 中配置分片策略花括号中可填入数字,代表分片在名称上的区别。
(eg. xx_$->{1…2} 代表,名称为xx_1 / xx_2 的数据库/表)
在项目 applicaiton.properties 中配置:
完整配置:
# 允许一个实体类对应两张表 (覆盖)
spring.main.allow-bean-definition-overriding=true
# Sharing-JDBC分片策略
# 配置数据源起别名
spring.shardingsphere.datasource.names=d1
# 配置数据源具体内容,包含连接池、驱动、地址、用户名、密码 (使用 Mybatis Plus 可更换为 HikariCP)
spring.shardingsphere.datasource.d1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.d1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.d1.url=jdbc:mysql://[ip地址]:3306/commodity_db?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.d1.username=root
spring.shardingsphere.datasource.d1.password=123
# 指定 commodity 表的分布情况,配置 表的位置、名称(commodity表示规则) course_tab_1 course_tab_2
spring.shardingsphere.sharding.tables.commodity.actual-data-nodes=d1.course_tab_$->{1..2}
# 指定 commodity 表里主键生成策略(commodity表示规则) SNOWFLAKE(❄雪花算法:生成随机唯一ID策略)
spring.shardingsphere.sharding.tables.commodity.key-generator.column=commodity_id
spring.shardingsphere.sharding.tables.commodity.key-generator.type=SNOWFLAKE
# 指定分片策略 约定 commodity_id:偶数 -> commodity_tab_1 / 奇数 -> commodity_tab_2
spring.shardingsphere.sharding.tables.commodity.table-strategy.inline.sharding-column=commodity_id
spring.shardingsphere.sharding.tables.commodity.table-strategy.inline.algorithm-expression=commodity_tab_$->{commodity_id % 2 + 1}
# 打开SQL输出日志
spring.shardingsphere.props.sql.show=true
※ 【可能出现的问题】
< 1 > Sharding JDBC 版本过高

版本号的问题:更改为 4.0.0-RC1就不会出现这个错误
< 2 > 允许一个实体类对应两张表
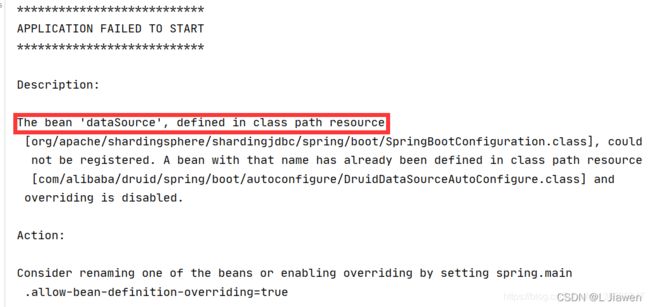
在 application.properties 增加一行配置就可以解决:
- 解决一个实体类无法对应两张表,做一个覆盖操作
# 允许一个实体类对应两张表 (覆盖)
spring.main.allow-bean-definition-overriding=true
< 3 > JDK 版本 > 8
由于JDK 版本过高 (version> 8),会导致以下错误:
java.lang.ClassNotFoundException: javax.xml.bind.JAXBException
错误分析:
JAXB API是java EE 的API,因此在java SE 9.0 中不再包含这个 Jar 包。
java 9 中引入了模块的概念,默认情况下,Java SE中将不再包含java EE 的Jar包
而在 java 6/7 / 8 时关于这个API 都是捆绑在一起的
两种解决方案:
-
降低JDK 9 版本到 JDK 1.8

-
手动/Maven/Gradle 加入这些依赖Jar包
-
手动导入 Jar包
-
Maven项目添加如下依赖:
<dependencies> <dependency> <groupId>javax.xml.bindgroupId> <artifactId>jaxb-apiartifactId> <version>2.3.0version> dependency> <dependency> <groupId>com.sun.xml.bindgroupId> <artifactId>jaxb-implartifactId> <version>2.3.0version> dependency> <dependency> <groupId>com.sun.xml.bindgroupId> <artifactId>jaxb-coreartifactId> <version>2.3.0version> dependency> <dependency> <groupId>javax.activationgroupId> <artifactId>activationartifactId> <version>1.1.1version> dependency> dependencies> -
Gradle项目添加如下依赖:
dependencies { // JAX-B dependencies for JDK 9+ implementation "javax.xml.bind:jaxb-api:2.3.0" implementation "com.sun.xml.bind:jaxb-core:2.3.0" implementation "com.sun.xml.bind:jaxb-impl:2.3.0" implementation "javax.activation:activation:1.1.1" }
-
2.3.2 分片策略
主键生成策略
sharding-jdbc提供了两种主键生成策略UUID、SNOWFLAKE。
默认使用SNOWFLAKE,还抽离出分布式主键生成器的接口org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator,方便用户自行实现自定义的自增主键生成器。
public class SimpleShardingKeyGenerator implements ShardingKeyGenerator {
private AtomicLong atomic = new AtomicLong(0);
@Getter
@Setter
private Properties properties = new Properties();
@Override
public Comparable<?> generateKey() {
return atomic.incrementAndGet();
}
@Override
public String getType() {
//声明类型
return "SIMPLE";
}
}
2.3.3 最终测试
① 添加商品
测试类:
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class ShardingJdbcDemoApplicationTests {
// 注入Mapper
@Autowired
private ICommodityMapper commodityMapper;
// 添加课程的方法
@Test
public void addCommodities() {
for (int i = 0; i < 10; i++) {
Commodity commodity = new Commodity(
null,
"Game" + i,
100L,
"Normal");
commodityMapper.insert(commodity);
}
}
}
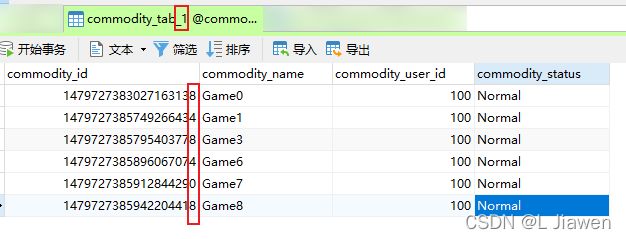
测试结果:
- 通过测试

- 数据表
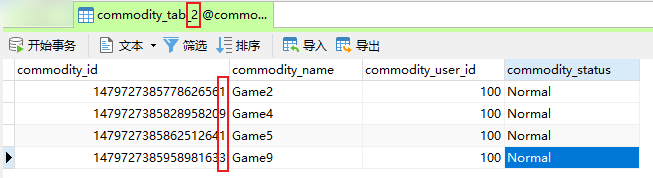
② 查询商品
测试类:
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class ShardingJdbcDemoApplicationTests {
// 注入Mapper
@Autowired
private ICommodityMapper commodityMapper;
// 查询课程的方法——主键PK
@Test
public void findCommodities(){
// 条件构造器
QueryWrapper<Commodity> wrapper = new QueryWrapper<>();
wrapper.eq("commodity_id",1479727385778626561L);
// wrapper.eq("commodity_id",1479727383027163138L);
// 查询
Commodity commodity = commodityMapper.selectOne(wrapper);
// 打印
System.out.println(commodity);
}
}
测试结果:
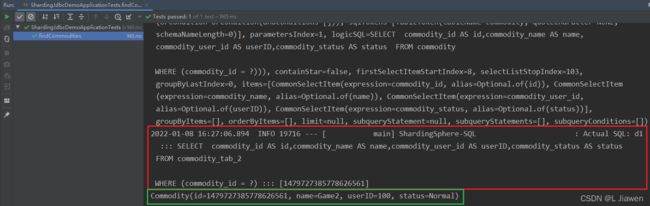
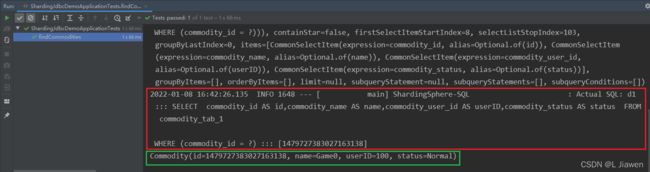
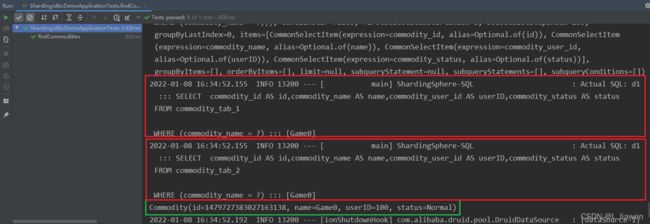
查询非策略相关字段,无论表 顺序先后,总会遍历所有表:
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class ShardingJdbcDemoApplicationTests {
// 注入Mapper
@Autowired
private ICommodityMapper commodityMapper;
// 查询课程的方法——非主键
@Test
public void findCommodities(){
// 条件构造器
QueryWrapper<Commodity> wrapper = new QueryWrapper<>();
wrapper.eq("commodity_name","Game2"); // commodity_tab_2
// wrapper.eq("commodity_name","Game0"); // commodity_tab_1
// 查询
Commodity commodity = commodityMapper.selectOne(wrapper);
// 打印
System.out.println(commodity);
}
}

2.4 水平分库
约定规则:
- 数据库:user_id:偶数,数据添加至commodity_db_1库;奇数,数据添加至commodity_db_2库。
- 数据表:commodity_id:偶数,数据添加至commodity_tab_1表;奇数,数据添加至commodity_tab_2表。
2.4.1 搭建环境
由于前面已经导入依赖,并创建项目,我们将在以前的基础上,对配置进行重构,所以步骤调整至两步。
① 按照为分库分表方式,创建数据库
创建 commodity_db_1 数据库:
CREATE DATABASE IF NOT EXISTS `commodity_db_1` CHARACTER SET utf8mb4;
USE `commodity_db`;
CREATE TABLE commodity_tab_1 (
commodity_id BIGINT(20) PRIMARY KEY,
commodity_name VARCHAR(20) NOT NULL,
commodity_user_id BIGINT(20) NOT NULL,
commodity_status VARCHAR(10) NOT NULL
);
CREATE TABLE commodity_tab_2 (
commodity_id BIGINT(20) PRIMARY KEY,
commodity_name VARCHAR(20) NOT NULL,
commodity_user_id BIGINT(20) NOT NULL,
commodity_status VARCHAR(10) NOT NULL
);
创建 commodity_db_2 数据库:
CREATE DATABASE IF NOT EXISTS `commodity_db_2` CHARACTER SET utf8mb4;
USE `commodity_db`;
CREATE TABLE commodity_tab_1 (
commodity_id BIGINT(20) PRIMARY KEY,
commodity_name VARCHAR(20) NOT NULL,
commodity_user_id BIGINT(20) NOT NULL,
commodity_status VARCHAR(10) NOT NULL
);
CREATE TABLE commodity_tab_2 (
commodity_id BIGINT(20) PRIMARY KEY,
commodity_name VARCHAR(20) NOT NULL,
commodity_user_id BIGINT(20) NOT NULL,
commodity_status VARCHAR(10) NOT NULL
);
② 配置 Sharding-JDBC 分片策略
# 一个实体类对应两张表 (覆盖)
spring.main.allow-bean-definition-overriding=true
# Sharing-JDBC分片策略
# 配置数据源起别名:水平分库,两个数据源
spring.shardingsphere.datasource.names=d1,d2
# 配置第1个数据源:具体内容,包含连接池、驱动、地址、用户名、密码
spring.shardingsphere.datasource.d1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.d1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.d1.url=jdbc:mysql://192.168.1.132:3306/commodity_db_1?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.d1.username=root
spring.shardingsphere.datasource.d1.password=123
# 配置第2个数据源:具体内容,包含连接池、驱动、地址、用户名、密码
spring.shardingsphere.datasource.d2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.d2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.d2.url=jdbc:mysql://192.168.1.132:3306/commodity_db_2?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.d2.username=root
spring.shardingsphere.datasource.d2.password=123
# 指定 commodity 数据库、数据表的分布情况,配置 库/表的位置、名称(commodity表示规则) course_tab_1 course_tab_2
# d1 d2 commodity_db_1 commodity_db_2
spring.shardingsphere.sharding.tables.commodity.actual-data-nodes=d$->{1..2}.commodity_tab_$->{1..2}
# 指定 commodity 表里主键生成策略(commodity表示规则) SNOWFLAKE(❄雪花算法:生成随机唯一ID策略)
spring.shardingsphere.sharding.tables.commodity.key-generator.column=commodity_id
spring.shardingsphere.sharding.tables.commodity.key-generator.type=SNOWFLAKE
# [两种方法]指定数据库分片策略 约定 commodity_user_id:偶数 -> d1(commodity_db_1) / 奇数 -> d2(commodity_db_2)
#1、 针对数据库中所有表
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=commodity_user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=d$->{commodity_user_id % 2 + 1}
#2、 针对数据库中 commodity 相关表
spring.shardingsphere.sharding.tables.commodity.database-strategy.inline.sharding-column=commodity_user_id
spring.shardingsphere.sharding.tables.commodity.database-strategy.inline.algorithm-expression=d$->{commodity_user_id % 2 + 1}
# 指定数据表分片策略 约定 commodity_id:偶数 -> commodity_tab_1 / 奇数 -> commodity_tab_2
spring.shardingsphere.sharding.tables.commodity.table-strategy.inline.sharding-column=commodity_id
spring.shardingsphere.sharding.tables.commodity.table-strategy.inline.algorithm-expression=commodity_tab_$->{commodity_id % 2 + 1}
# 打开SQL输出日志
spring.shardingsphere.props.sql.show=true
2.4.2 最终测试
① 添加商品
测试类:
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class ShardingJdbcDemoApplicationTests {
// 注入Mapper
@Autowired
private ICommodityMapper commodityMapper;
// 添加课程的方法
@Test
public void addCommodities() {
for (int i = 0; i < 10; i++) {
Commodity commodity = new Commodity(
null,
"Game" + i,
100L + i,
"Normal");
commodityMapper.insert(commodity);
}
}
}
测试结果:
-
通过测试:

-
数据表:



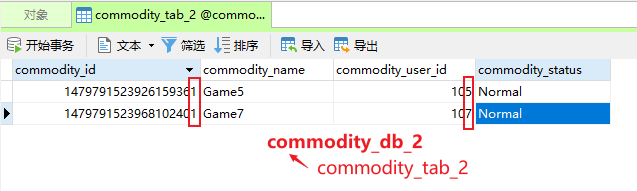
② 查询商品
测试类:
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class ShardingJdbcDemoApplicationTests {
// 注入Mapper
@Autowired
private ICommodityMapper commodityMapper;
// 查询课程的方法
@Test
public void findCommodities(){
// 条件构造器
QueryWrapper<Commodity> wrapper = new QueryWrapper<>();
wrapper.eq("commodity_id",1479791523850661890L);
wrapper.eq("commodity_user_id",101L);
Commodity commodity = commodityMapper.selectOne(wrapper);
System.out.println(commodity);
}
}
测试结果:

2.5 垂直分库
2.5.1 分析数据库
根据业务,进行垂直分库,做到专库专表
2.5.2 创建数据库
按照垂直分库方式,创建数据库user_db:
CREATE DATABASE IF NOT EXISTS `user_db` CHARACTER SET utf8mb4;
USE `user_db`;
CREATE TABLE user_tab (
user_id BIGINT(20) PRIMARY KEY,
user_name VARCHAR(20) NOT NULL,
user_status VARCHAR(10) NOT NULL
);
2.5.3 编写代码
实体类User:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
@TableId("user_id")
private Long id;
@TableField("user_username")
private String username;
@TableField("user_status")
private String status;
}
映射接口IUserMapper:
@Repository
public interface IUserMapper extends BaseMapper<User> {
}
2.5.4 配置属性
在 application.properties中进行配置:
# 一个实体类对应两张表 (覆盖)
spring.main.allow-bean-definition-overriding=true
# Sharing-JDBC分片策略
# 配置数据源起别名:水平分库,两个数据源
spring.shardingsphere.datasource.names=d5
# 配置第3个数据源:具体内容,包含连接池、驱动、地址、用户名、密码
spring.shardingsphere.datasource.d5.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.d5.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.d5.url=jdbc:mysql://192.168.1.132:3306/user_db?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.d5.username=root
spring.shardingsphere.datasource.d5.password=123
# 配置垂直分库:专库专表 user_db : user_tab(user表示规则)
spring.shardingsphere.sharding.tables.user.actual-data-nodes=d$->{5}.user_tab
# 指定 user 表里主键生成策略(user表示规则) SNOWFLAKE(❄雪花算法:生成随机唯一ID策略)
spring.shardingsphere.sharding.tables.user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
# 针对 user 指定数据表、字段
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_tab
2.5.5 最终测试
① 添加用户
测试类:
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class ShardingJdbcDemoApplicationTests {
// 注入Mapper
@Autowired
private IUserMapper userMapper;
// 添加用户的方法
@Test
public void addUsers() {
User user = new User(
null,
"Mike",
"Normal"
);
userMapper.insert(user);
}
}
测试结果:
-
测试成功:

-
数据库:
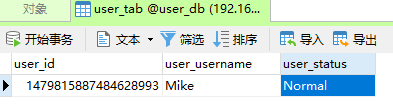
② 查询用户
测试类:
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class ShardingJdbcDemoApplicationTests {
// 注入Mapper
@Autowired
private IUserMapper userMapper;
@Test
// 查询用户的方法
public void findUsers() {
// 条件构造器
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.eq("user_id", 1479815887484628993L);
User user = userMapper.selectOne(wrapper);
System.out.println(user);
}
}
测试结果:

2.6 公共表 — 广播
公共表:
- 存储固定数据的表,表数据很少发生变化,查询时候经常进行关联
- 在每个数据库中创建出相同结构公共表
2.6.1 创建公共表
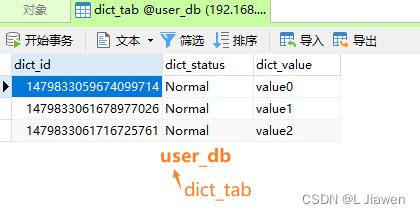
在3个数据库中,分别创建公共表 dict_tab:
CREATE TABLE dict_tab (
dict_id BIGINT(20) PRIMARY KEY,
dict_status VARCHAR(100) NOT NULL,
dict_value VARCHAR(100) NOT NULL
)
2.6.2 配置属性
在 application.properties 配置文件中添加以下属性:
# 配置公共表
spring.shardingsphere.sharding.broadcast-tables=dict_tab
# 指定 dict 表里主键生成策略(dict表示规则) SNOWFLAKE(❄雪花算法:生成随机唯一ID策略)
spring.shardingsphere.sharding.dict.user.key-generator.column=dict_id
spring.shardingsphere.sharding.dict.user.key-generator.type=SNOWFLAKE
# 针对 dict 指定数据表、字段
spring.shardingsphere.sharding.dict.user.table-strategy.inline.sharding-column=dict_id
spring.shardingsphere.sharding.dict.user.table-strategy.inline.algorithm-expression=dict_tab
2.6.4 编写代码
实体类 Dict:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Dict {
@TableId("dict_id")
private Long id;
@TableField("dict_status")
private String status;
@TableField("dict_value")
private String value;
}
映射接口 IDictMapper:
@Repository
public interface IDictMapper extends BaseMapper<Dict> {
}
2.6.5 最终测试
注入Mapper:
// 注入Mapper
@Autowired
private IDictMapper dictMapper;
① 添加操作
测试方法:
// 添加操作
@Test
public void addDictByBroadcast() {
for (int i = 0; i < 3; i++) {
Dict dict = new Dict(
null,
"Normal",
"value" + i
);
dictMapper.insert(dict);
}
}
※【可能出现的问题】

出现这个问题的原因:我们既没有在 配置文件(application.properties) 中指定表名称,也没有在实体类上加注解标注 表名称。
而公共表,因采用广播模式,所有数据源参与CRUD操作,故无法确定数据源,因在实体类上指定标表名称。
解决方法:
- 在实体类上加上注解
@TableName("dict_tab")
测试结果:
-
测试成功

-
数据库
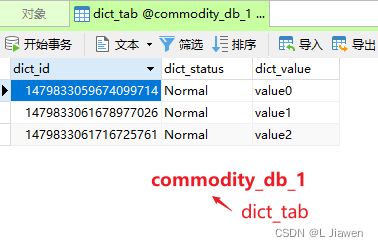
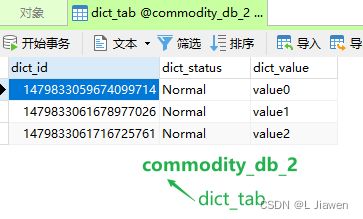
② 删除操作
测试方法:
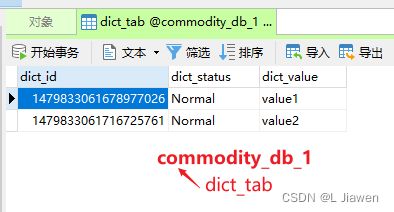
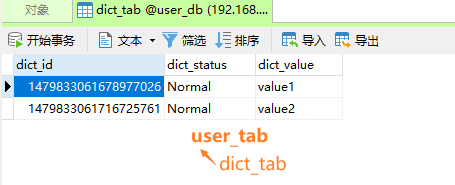
// 删除操作
@Test
public void deleteDictByBroadcast() {
dictMapper.deleteById(1479833059674099714L);
}
测试结果:
-
测试成功

-
数据库

2.7 主从复制 - 读写分离
2.7.1 概述
读写分离:
为了确保数据库产品的稳定性,很多数据库拥有双击热备功能。即,第一台数据库服务器,是对外提供增删改业务的生产服务器,第二胎数据库服务器,主要进行读操作。
原理:
让主数据库(master)处理事务性 增、删、改 操作,而从数据库(slave)处理 查 操作。
以MySQL 数据库服务器为例
原理图:


2.7.2 主从复制
主从复制,需要准备至少 两台MySQL 服务器(一主一从),主服务器开启 Binary Log 功能,并进行相关配置;主服务器每次对数据操作都会更新 Binary Log 日志文件。从服务器通过实时监控主服务器 更新 Binary Log。
※ 参数详解
MySQL主从配置 (一主一从)
2.7.3 读写分离
Sharding-JDBC 通过语句语义分析,实现读写分离过程。
Sharding-JDBC 原理:
- 通过 路由 将不同操作 (CRUD) 指向 不同的MySQL服务器(Master:增删改、Slave:查)。
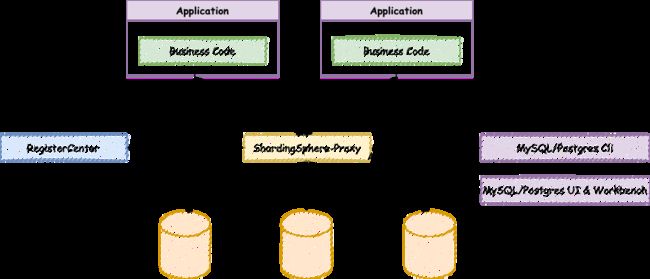
3. Sharding-Proxy
透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。
目前支持 MySQL 和 PostgreSQL(兼容 openGauss 等基于 PostgreSQL 的数据库)版本。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
3.1 安装
-
下载安装软件:

-
在Windows中直接两步解压 (7-zip),可能会出现lib目录下jar包名称不全问题:

Windows 解决方案:安装tar for windows(GnuWin32),并将bin目录 配置Path环境变量:
下载地址:http://gnuwin32.sourceforge.net/packages/gtar.htm


-
Linux系统
tar -xvf直接解压,这里建议在Linux 系统解压后,使用FTP工具传回Windows 即可。
-
解压压缩文件,完成配置后 启动bin目录
start.bat (win)/start.sh (linux)文件(JVM GC方式有变动,请使用 JER 1.8 版本):
3.2 配置规则
进入conf目录,修改server.yaml文件(去除注释 + 修改配置):
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
- !TRANSACTION
defaultType: XA
providerType: Atomikos
props:
max-connections-size-per-query: 1
kernel-executor-size: 16 # Infinite by default.
proxy-frontend-flush-threshold: 128 # The default value is 128.
proxy-opentracing-enabled: false
proxy-hint-enabled: false
sql-show: false
check-table-metadata-enabled: false
show-process-list-enabled: false
# Proxy backend query fetch size. A larger value may increase the memory usage of ShardingSphere Proxy.
# The default value is -1, which means set the minimum value for different JDBC drivers.
proxy-backend-query-fetch-size: -1
check-duplicate-table-enabled: false
sql-comment-parse-enabled: false
proxy-frontend-executor-size: 0 # Proxy frontend executor size. The default value is 0, which means let Netty decide.
# Available options of proxy backend executor suitable: OLAP(default), OLTP. The OLTP option may reduce time cost of writing packets to client, but it may increase the latency of SQL execution
# if client connections are more than proxy-frontend-netty-executor-size, especially executing slow SQL.
proxy-backend-executor-suitable: OLAP
proxy-frontend-max-connections: 0 # Less than or equal to 0 means no limitation.
sql-federation-enabled: false
进入conf目录,修改conf-sharding.yaml文件(去除注释 + 修改配置),并将MySQL驱动jar包复制到 lib 目录。
######################################################################################################
#
# If you want to connect to MySQL, you should manually copy MySQL driver to lib directory.
#
######################################################################################################
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_0?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
keyGenerateStrategy:
column: order_item_id
keyGeneratorName: snowflake
bindingTables:
- t_order,t_order_item
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
t_order_item_inline:
type: INLINE
props:
algorithm-expression: t_order_item_${order_id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
以上配置文件的修改与 Sharding JDBC 相类似。
3.3 启动服务
- 通过设定不同的配置,启动 Sharding-Proxy 操作 MySQL 数据库即可完成分库、分表操作。
- 在 MySQL Cli 中连接,创建数据表,向表中添加记录即可。